用pytorch学习github写了个picture caption的AI项目的经验总结
目录
1 整个项目的架构
1.1 文件名和文件作用
1.2 创建项目的整体思路
2 各部分文件的经验总结
2.1 主函数 main.py
2.1.1 命令行参数 argparse.ArgumentParser
2.1.2 main.py文件的一般逻辑
2.1.3 可用的gpu环境部署
2.1.4 main函数 承载主要逻辑
2.1.5 train函数 训练
2.1.6 validate函数 验证
2.1.7 if __name__ == '__main__': main函数功能逻辑之外的其余背景部署
2.2 模型model.py
2.3 预处理prepro.py
2.4 数据加载data_loader.py
2.5 工具utils.py
2.6 验证集数据集创建
2.7 其他一般性的经验总结
2.7.1 注释
2.7.2 nohup
1 整个项目的架构
1.1 文件名和文件作用
| main.py | 主函数 |
| model.py | 模型 |
| prepro.py | 预处理 |
| data_loader.py | 数据集加载辅助 |
| flickr8k_dataloader.py | 针对flickr8k的数据集加载辅助 |
| compute_mean_val.py | 计算数据集图片的均值、标准差 |
| utils.py | 工具类 |
| make_val_dataset.py | 创建验证数据集 |
1.2 创建项目的整体思路
- 首先书写main.py文件,在主函数文件中理清思路和头绪(遇到未写的变量时,假装已经定义,做好标记,跳过具体内容,继续余下书写代码,以梳理整体思路并通过标记让main.py文件和接下来要写的辅助文件逻辑一致)。
- 在书写main.py过程中,就会发现需要的模型文件、工具类和预处理等辅助文件,并从整体上理解了所需要的功能和接口。
- 书写预处理prepro.py文件,根据main.py中相关部分所需要的模型输入接口,对数据进行预处理。
- 书写模型model.py文件,根据预处理后的数据格式,和相关算法理论(比如阅读到的paper或者自己构思的idea),用pytorch搭建model,遇到需要数据加载类时,同main.py文件,做好标记,跳过具体内容,继续余下书写代码。
- 书写data_loader.py文件,根据基本书写好的model.py文件中模型对输入data的要求,基于pytorch的数据加载类torch.utils.data.DataLoader,构造自己的数据加载类。
- 书写其他的工具类utils.py文件,根据已经书写好的主函数文件,预处理文件,数据加载文件,模型文件中的所需要的具有普适性的一般功能(尤其是暂时跳过尚未书写的),将其归纳进入工具类文件。
- 书写创建验证集数据集的make_val_dataset.py文件,一般就是基于训练数据从里面选出一些数据,最好让选择出来的数据不再参与训练过程,以保证验证过程的客观公正。
2 各部分文件的经验总结
2.1 主函数 main.py
2.1.1 命令行参数 argparse.ArgumentParser
首先就是命令行参数的构建,定义如下
import argparse
parser = argparse.ArgumentParser() # 命令行参数解析器
parser.add_argument(
'--model_path', # 命令行参数名
type=str, # 类型
default='./models/', # 默认值
help='path for saving trained models') # 提示
# 创建其他命令行参数...
args = parser.parse_args() # 获取命令行参数
print(args) # 打印查看命令行参数建议
- 将其写在全局,这样方便全局引用。
- 一定要用argparse.ArgumentParser()构造命令行参数,规范简介而且功能一目了然
调用时
model_path=args.model_path再调用model_path即可。
当然,如果后面不再使用这一变量,可以直接使用args.model_path。
2.1.2 main.py文件的一般逻辑
- 调用包
- 可用的gpu环境部署
- main函数 承载主要逻辑
- train函数 训练
- validate函数 验证
if __name__ == '__main__': main函数功能逻辑之外的其余背景部署
2.1.3 可用的gpu环境部署
当gpu可用时,一般而言只有一块gpu,由多块时指定某一块x就写作cuda:x即可;gpu不可用就为cpu模式。
device = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')使用时,将变量、模型或计算转移至gpu上:
imgs = imgs.to(device) # 图片部署至gpu
decoder = decoder.to(device) # 解码器部署至gpu
criterion = nn.CrossEntropyLoss().to(device) # 计算部署至gpu
2.1.4 main函数 承载主要逻辑
一 预加载
一般需要加载些东西,比如字典、模型什么的
# 加载字典包装
with open(args.vocab_path, 'rb') as f:
vocab = pickle.load(f)使用到pickle模块
import pickle
二 预定义变量
在训练之前,需要预先创建一些变量。当然这时就得分之前是否训练过了。
a 如果之前训练过,则需要加载之前保存的checkpoint(一般是个用torch保存的字典)。
保存的例子(一般放在工具utils.py中,作为一个单独的函数),例如
def save_checkpoint(data_name, epoch, epochs_since_improvement, encoder,
decoder, encoder_optimizer, decoder_optimizer, bleu4,
is_best):
"""
Saves model checkpoint.
:param data_name: base name of processed dataset
:param epoch: epoch number
:param epochs_since_improvement: number of epochs since last improvement in BLEU-4 score
:param encoder: encoder model
:param decoder: decoder model
:param encoder_optimizer: optimizer to update encoder's weights, if fine-tuning
:param decoder_optimizer: optimizer to update decoder's weights
:param bleu4: validation BLEU-4 score for this epoch
:param is_best: is this checkpoint the best so far?
"""
state = {
'epoch': epoch,
'epochs_since_improvement': epochs_since_improvement,
'bleu-4': bleu4,
'encoder': encoder,
'decoder': decoder,
'encoder_optimizer': encoder_optimizer,
'decoder_optimizer': decoder_optimizer
}
filename = 'checkpoint_' + data_name + '.pth.tar'
torch.save(state, filename)
# 如果这个 checkpoint 是目前为止最好的,存储一个副本,这样它就不会被更差的 checkpoint 覆盖
if is_best:
torch.save(state, 'BEST_' + filename)
加载时,用torch.load,之后就得到一个字典类型的变量,用访问字典键值对的方式读取即可
checkpoint = torch.load(args.checkpoint)
start_epoch = checkpoint['epoch'] + 1
epochs_since_improvement = checkpoint['epochs_since_improvement']
best_bleu4 = checkpoint['bleu-4']
decoder = checkpoint['decoder']
decoder_optimizer = checkpoint['decoder_optimizer']
encoder = checkpoint['encoder']
encoder_optimizer = checkpoint['encoder_optimizer']
if fine_tune_encoder is True and encoder_optimizer is None:
encoder.fine_tune(fine_tune_encoder) # 微调器微调
encoder_optimizer = torch.optim.Adam(
params=filter(lambda p: p.requires_grad, encoder.parameters()),
lr=args.encoder_lr) # 编码器优化器b 如果之前没有训练过,则需要预定义新变量
decoder = AttnDecoderRNN(
attention_dim=args.attention_dim,
embed_dim=args.embed_dim,
decoder_dim=args.decoder_dim,
vocab_size=len(vocab),
dropout=args.dropout) # 解码器
decoder_optimizer = torch.optim.Adam(
params=filter(lambda p: p.requires_grad, decoder.parameters()),
lr=args.decoder_lr) # 解码器优化器
encoder = EncoderCNN() # 编码器
encoder.fine_tune(args.fine_tune_encoder) # 编码器微调
encoder_optimizer = torch.optim.Adam(
params=filter(lambda p: p.requires_grad, encoder.parameters()),
lr=args.encoder_lr) if args.fine_tune_encoder else None # 编码器优化器
best_bleu4 = args.best_bleu4可以看到,这里普遍使用了lambda表达式和filter函数,优化器选用的是常用而鲁棒的Adam。
三 损失函数
然后定义损失函数,例如使用交叉熵
criterion = nn.CrossEntropyLoss().to(device)这里用到了包
import torch.nn as nn
四 数据集加载器
如前文所述,一般就是利用torch.utils.data.DataLoader,构造自己的dataloader。如
flickr = DataLoader(
root=root, json=json, vocab=vocab, rank=rank, transform=transform)
data_loader = torch.utils.data.DataLoader(
dataset=flickr,
batch_size=batch_size,
shuffle=shuffle, # 打乱
num_workers=num_workers, # 用于数据加载的子进程数
collate_fn=collate_fn)其中,参数dataset是继承torch.utils.data.Dataset类的数据集子类
继承torch.utils.data.Dataset类,需要实现两个方法
- __getitem__(self, index)(支持范围从0到len(self)独占的整数索引,即给出索引数字下标返回数据对象)
-
__len__(self) 返回总数据量的长度
具体实现如下:
class DataLoader(data.Dataset):
def __init__(self, root, json, vocab, rank, transform=None):
self.root = root
self.flickr = flickr8k(
ann_text_location=json, imgs_location=root, ann_rank=rank)
self.vocab = vocab
self.rank = rank
self.transform = transform
# 支持范围从0到len(self)独占的整数索引
def __getitem__(self, index):
flickr = self.flickr
vocab = self.vocab
# ann:annotation
caption = flickr.anns[index]['caption']
img_id = flickr.anns[index]['image_id']
path = flickr.loadImg(img_id)
image = Image.open(path).convert('RGB')
if self.transform is not None:
image = self.transform(image)
tokens = nltk.tokenize.word_tokenize(str(caption).lower()) # 分词
caption = []
caption.append(vocab(''))
caption.extend([vocab(token) for token in tokens])
caption.append(vocab(''))
target = torch.Tensor(caption)
return image, target
def __len__(self):
return len(self.flickr.anns)
参数collate_fn是自定义的数据批量获取的方法,即每次训练返回的batch
def collate_fn(data):
data.sort(key=lambda x: len(x[1]), reverse=True)
images, captions = zip(*data)
images = torch.stack(images, 0) # 将张量序列沿新维度串联起来
lengths = [len(cap) for cap in captions]
targets = torch.zeros(len(captions), max(lengths)).long()
for i, cap in enumerate(captions):
end = lengths[i]
targets[i, :end] = cap[:end]
return images, targets, lengths这里每次就返回一些图片、对应的captions和captions的长度。
有了这些,封装成我们自己的数据加载器get_loader,返回一个DataLoader对象用于数据加载
def get_loader(root, json, vocab, transform, batch_size, rank, shuffle,
num_workers):
flickr = DataLoader(
root=root, json=json, vocab=vocab, rank=rank, transform=transform)
# 数据加载 flickr 数据集
# 每次迭代返回 (images, captions, lengths)
# images: tensor of shape (batch_size, 3, 224, 224).
# captions: tensor of shape (batch_size, padded_length).
# lengths: 表示每个标题有效长度的列表. length is (batch_size).
data_loader = torch.utils.data.DataLoader(
dataset=flickr,
batch_size=batch_size,
shuffle=shuffle,
num_workers=num_workers,
collate_fn=collate_fn) # 合并一个示例列表以形成一个 mini-batch
return data_loader然后就可以顺理成章的创建我们的DataLoader了
train_loader = get_loader(
args.image_dir,
args.caption_path,
vocab,
transform,
args.batch_size,
args.rank,
shuffle=True,
num_workers=args.num_workers) # 训练数据集加载器
val_loader = get_loader(
args.image_dir_val,
args.caption_path_val,
vocab,
transform,
args.batch_size,
args.rank,
shuffle=True,
num_workers=args.num_workers) # 验证数据集加载器
五 训练及验证的迭代过程
一般就使用for循环定义最大训练上限(当然也可以在train和validate函数中分别定义训练次数),然后每轮训练再验证,并打印中间信息,最后保存最终模型即可。
但考虑到训练会发生过拟合或多次训练未见效果提升的情况,所以可以考虑
1 设置自上次训练以来,未提升历史最佳效果的训练次数上限,达到后自动退出循环,以免浪费时间。
if args.epochs_since_improvement == 20: # 自上次优化以来 20次迭代仍不见优化则退出
break
# 训练
# 验证
is_best = recent_bleu4 > best_bleu4 # 判断当前是否表现得最好
best_bleu4 = max(recent_bleu4, best_bleu4) # 记录最优bleu4值
if not is_best: # 仍未实现优化
args.epochs_since_improvement += 1
print("\nEpoch since last improvement: %d\n" %
(args.epochs_since_improvement, )) # 打印自上次优化以来的目前的epoch数目
else: # 当前迭代实现了优化
args.epochs_since_improvement = 0 # epochs_since_improvement 计数清零
2 在训练过程中,当训练次数达到一定数量仍未见效果提升,但未达到1提到的退出上限,可以考虑降低学习率
if args.epochs_since_improvement > 0 and args.epochs_since_improvement % 8 == 0:
adjust_learning_rate(decoder_optimizer, 0.8) # 将解码器学习率降低一个特定的因子
if args.fine_tune_encoder:
adjust_learning_rate(encoder_optimizer,
0.8) # 将编码器学习率降低一个特定的因子
六 保存模型
最后,保存中间模型,一般最后就剩两个模型,最终的模型和历史最佳模型。
save_checkpoint(args.data_name, epoch, args.epochs_since_improvement,
encoder, decoder, encoder_optimizer, decoder_optimizer,
recent_bleu4, is_best) # 保存模型检查点save_checkpoint函数自定义如下
def save_checkpoint(data_name, epoch, epochs_since_improvement, encoder,
decoder, encoder_optimizer, decoder_optimizer, bleu4,
is_best):
"""
Saves model checkpoint.
:param data_name: base name of processed dataset
:param epoch: epoch number
:param epochs_since_improvement: number of epochs since last improvement in BLEU-4 score
:param encoder: encoder model
:param decoder: decoder model
:param encoder_optimizer: optimizer to update encoder's weights, if fine-tuning
:param decoder_optimizer: optimizer to update decoder's weights
:param bleu4: validation BLEU-4 score for this epoch
:param is_best: is this checkpoint the best so far?
"""
state = {
'epoch': epoch,
'epochs_since_improvement': epochs_since_improvement,
'bleu-4': bleu4,
'encoder': encoder,
'decoder': decoder,
'encoder_optimizer': encoder_optimizer,
'decoder_optimizer': decoder_optimizer
}
filename = 'checkpoint_' + data_name + '.pth.tar'
torch.save(state, filename)
# 如果这个 checkpoint 是目前为止最好的,存储一个副本,这样它就不会被更差的 checkpoint 覆盖
if is_best:
torch.save(state, 'BEST_' + filename)
2.1.5 train函数 训练
def train(train_loader, encoder, decoder, criterion, encoder_optimizer,
decoder_optimizer, epoch)先把编码器、解码器设置为训练模式
decoder.train() # 将解码器模块设置为训练模式
encoder.train() # 将编码器模块设置为训练模式下面的几个变量用到了utils工具类文件的AverageMeter类,这是用来跟踪度量的最新值val、平均值avg、和sum和计数count的辅助类
# AverageMeter 跟踪度量的最新值val、平均值avg、和sum和计数count
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top5accs = AverageMeter()utils中AverageMeter类定义如下
class AverageMeter(object):
"""
跟踪度量的最新值、平均值、和与计数
"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
然后就是从之前定义得DataLoader中获取数据
for i, (imgs, caps, caplens) in enumerate(train_loader):之后的逻辑大体上就是
- 将数据转移到gpu上
- 预测结果
- 计算loss
- 添加正则化到loss
- 优化器清除梯度
- 反向传播
- 优化器推进一步(step)
- 返回给定输入张量沿给定维度的5个最大元素
- 到一定迭代次数后打印当前信息
train函数完整参考如下
# 训练
def train(train_loader, encoder, decoder, criterion, encoder_optimizer,
decoder_optimizer, epoch):
decoder.train() # 将解码器模块设置为训练模式
encoder.train() # 将编码器模块设置为训练模式
# AverageMeter 跟踪度量的最新值val、平均值avg、和sum和计数count
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top5accs = AverageMeter()
start = time.time() # 开始时间计时
for i, (imgs, caps, caplens) in enumerate(train_loader):
data_time.update(time.time() - start)
# 部署图片和标题至gpu
imgs = imgs.to(device)
caps = caps.to(device)
imgs = encoder(imgs) # 编码器训练
scores, decode_lengths, alphas = decoder(imgs, caplens) # 解码器
scores = pack_padded_sequence(
scores, decode_lengths, batch_first=True) # 包一个包含可变长度的填充序列的张量
targets = caps[:, 1:]
targets = pack_padded_sequence(
targets, decode_lengths, batch_first=True)
scores = scores.data
targets = targets.data
loss = criterion(scores, targets) # 根据自定义标准计算损失值
loss += args.alpha_c * ((1. - alphas.sum(dim=1))**2).mean() # 加上正则化项
decoder_optimizer.zero_grad() # 清除解码器所有梯度
if encoder_optimizer is not None:
encoder_optimizer.zero_grad() # 清除编码器所有梯度
loss.backward() # 损失值反向传播
if args.grad_clip is not None:
clip_gradient(decoder_optimizer,
args.grad_clip) # 在反向传播过程中计算剪辑梯度,以避免梯度爆炸
if encoder_optimizer is not None:
clip_gradient(encoder_optimizer, args.grad_clip)
decoder_optimizer.step() # 解码器优化器前进一步
if encoder_optimizer is not None:
encoder_optimizer.step() # 编码器优化器前进一步
top5 = accuracy(scores, targets, 5) # 返回给定输入张量沿给定维度的5个最大元素
losses.update(loss.item(), sum(decode_lengths))
top5accs.update(top5, sum(decode_lengths))
batch_time.update(time.time() - start)
start = time.time()
# 到了打印一波日志的时候
if i % args.log_step == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Batch Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data Load Time {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Top-5 Accuracy {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch,
i,
len(train_loader),
batch_time=batch_time,
data_time=data_time,
loss=losses,
top5=top5accs))
2.1.6 validate函数 验证
验证函数与之类似,就是多了计算BLEU-4分数以评估模型
关键代码
from nltk.translate.bleu_score import corpus_bleu
# 计算 BLEU-4 得分
bleu4 = corpus_bleu(references, hypotheses)validate函数完整代码
# 验证集上效果计算
def validate(val_loader, encoder, decoder, criterion):
"""
Performs one epoch's validation.
:param val_loader: DataLoader for validation data.
:param encoder: encoder model
:param decoder: decoder model
:param criterion: loss layer
:return: BLEU-4 score
"""
decoder.eval() # 将模块设置为评估模式 (no dropout or batchnorm)
if encoder is not None:
encoder.eval()
batch_time = AverageMeter()
losses = AverageMeter()
top5accs = AverageMeter()
start = time.time()
references = list() # 计算BLEU-4分数的参考(真实标题)
hypotheses = list() # 假设(预测)
# 每轮batch迭代
for i, (imgs, caps, caplens) in enumerate(val_loader):
# 迁移至gpu
imgs = imgs.to(device)
caps = caps.to(device)
# 前向传播
if encoder is not None:
imgs = encoder(imgs)
scores, decode_lengths, alphas = decoder(imgs, caplens)
# 因为我们是从开始解码的,所以目标都是之后的单词,一直到
targets = caps[:, 1:]
# 删除我们没有解码的时间步长,或者是pad
# pack_padded_sequence 是完成这个目的的一个简单的技巧
scores_copy = scores.clone()
scores = pack_padded_sequence(scores, decode_lengths, batch_first=True)
targets = pack_padded_sequence(
targets, decode_lengths, batch_first=True)
scores = scores.data
targets = targets.data
loss = criterion(scores, targets) # 计算损失
# 加入 doubly stochastic attention 正则化
loss += args.alpha_c * ((1. - alphas.sum(dim=1))**2).mean()
# 跟踪指标
losses.update(loss.item(), sum(decode_lengths))
top5 = accuracy(scores, targets, 5)
top5accs.update(top5, sum(decode_lengths))
batch_time.update(time.time() - start)
start = time.time()
if i % args.log_step == 0:
print('Validation: [{0}/{1}]\t'
'Batch Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Top-5 Accuracy {top5.val:.3f} ({top5.avg:.3f})\t'.format(
i,
len(val_loader),
batch_time=batch_time,
loss=losses,
top5=top5accs))
# 存储每个图像的引用(真实标题)和假设(预测)
# 如果对于n幅图像,我们有n个假设,参考文献a, b, c…
# 对于每个图像,我们需要
# references= [[ref1a, ref1b, ref1c], [ref2a, ref2b, ref2c],…
# hypotheses= [hyp1, hyp2, …]
# References
# caps = caps[sort_ind] # 因为图像是在解码器中排序的
for j in range(caps.shape[0]):
img_caps = caps[j].tolist()
img_captions = list(
map(
lambda c: [
w for w in img_caps if w not in
{vocab.__call__(''),
vocab.__call__('')}
], img_caps)) # 去除 and 填充
references.append(img_captions)
# Hypotheses
_, preds = torch.max(scores_copy, dim=2)
preds = preds.tolist()
temp_preds = list()
for j, p in enumerate(preds):
temp_preds.append(preds[j][:decode_lengths[j]]) # 移除结尾的填充
preds = temp_preds
hypotheses.extend(preds)
assert len(references) == len(hypotheses)
# 计算 BLEU-4 得分
bleu4 = corpus_bleu(references, hypotheses)
print(
'\n * LOSS - {loss.avg:.3f}, TOP-5 ACCURACY - {top5.avg:.3f}, BLEU-4 - {bleu}\n'
.format(loss=losses, top5=top5accs, bleu=bleu4))
return bleu4
2.1.7 if __name__ == '__main__': main函数功能逻辑之外的其余背景部署
可以在这里修改一下进程名字,这样在多人共用服务器是可以互相看见,以免误伤2333
if __name__ == '__main__':
setproctitle.setproctitle("张晋豪的python caption flickr8k")
main(args)
2.2 模型model.py
这里就是pytorch定义神经网络的地方了。一般来说,最简单的,就直接继承nn.Module父类,重写forward方法即可。forward方法用于每次数据获取(输入参数)和预测输出(return)。
当然,还可以定义其他的辅助方法,如fine_tune微调等。
具体例子如下:
CNN编码器定义如下:
class EncoderCNN(nn.Module):
def __init__(self, encoded_image_size=14):
super(EncoderCNN, self).__init__()
resnet = models.resnet101(pretrained=True)
# children 返回直接子模块上的迭代器
modules = list(resnet.children())[:-2]
self.resnet = nn.Sequential(*modules)
self.adaptive_pool = nn.AdaptiveAvgPool2d((encoded_image_size,
encoded_image_size))
self.fine_tune()
def forward(self, images):
out = self.resnet(images)
out = self.adaptive_pool(out)
out = out.permute(0, 2, 3, 1) # 转换数组轴
return out
def fine_tune(self, fine_tune=True):
for p in self.resnet.parameters():
p.requires_grad = False
for c in list(self.resnet.children())[5:]:
for p in c.parameters():
p.requires_grad = fine_tuneattention解码器定义如下:
class AttnDecoderRNN(nn.Module):
def __init__(self,
attention_dim,
embed_dim,
decoder_dim,
vocab_size,
encoder_dim=2048,
dropout=0.5):
super(AttnDecoderRNN, self).__init__()
self.encoder_dim = encoder_dim
self.attention_dim = attention_dim
self.embed_dim = embed_dim
self.decoder_dim = decoder_dim
self.vocab_size = vocab_size
self.dropout = dropout
self.attention = Attention(encoder_dim, decoder_dim, attention_dim)
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.dropout = nn.Dropout(p=self.dropout)
self.decode_step = nn.LSTMCell(
embed_dim + encoder_dim, decoder_dim, bias=True)
self.init_h = nn.Linear(encoder_dim, decoder_dim)
self.init_c = nn.Linear(encoder_dim, decoder_dim)
self.f_beta = nn.Linear(
decoder_dim,
encoder_dim) # linear layer to create a sigmoid-activated gate
self.sigmoid = nn.Sigmoid()
self.fc = nn.Linear(decoder_dim, vocab_size)
self.init_weights()
def init_weights(self):
self.embedding.weight.data.uniform_(-0.1, 0.1)
self.fc.bias.data.fill_(0)
self.fc.weight.data.uniform_(-0.1, 0.1)
def load_pretrained_embeddings(self, embeddings):
# Parameter
# 在参数优化的时候可以进行优化 所以经过类型转换这个self.v变成了模型的一部分
# 成为了模型中根据训练可以改动的参数了
# 使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化
self.embedding.weight = nn.Parameter(embeddings)
def fine_tune_embeddings(self, fine_tune=True):
for p in self.embedding.parameters():
p.requires_grad = fine_tune
def init_hidden_state(self, encoder_out):
mean_encoder_out = encoder_out.mean(dim=1)
h = self.init_h(mean_encoder_out)
c = self.init_c(mean_encoder_out)
return h, c
def forward(self, encoder_out, encoded_captions, caption_lengths):
"""
:return: scores for vocabulary, sorted encoded captions, decode lengths, weights
"""
batch_size = encoder_out.size(0)
encoder_dim = encoder_out.size(-1)
vocab_size = self.vocab_size
encoder_out = encoder_out.view(batch_size, -1,
encoder_dim) # view pytorch的reshape
num_pixels = encoder_out.size(1)
embeddings = self.embedding(encoded_captions)
h, c = self.init_hidden_state(encoder_out)
decode_lengths = [c - 1 for c in caption_lengths]
predictions = torch.zeros(batch_size, max(decode_lengths),
vocab_size).to(device)
alphas = torch.zeros(batch_size, max(decode_lengths),
num_pixels).to(device)
# 一个batch为一个整体预测集合
# 每个caption一个单词一个单词的预测
# 当短的预测完成时,就开始预测剩下的长的
# 在dataloader处已经排序了, 从头到尾caption长度逐渐减少
for t in range(max(decode_lengths)):
batch_size_t = sum([l > t for l in decode_lengths])
attention_weighted_encoding, alpha = self.attention(
encoder_out[:batch_size_t], h[:batch_size_t])
gate = self.sigmoid(self.f_beta(h[:batch_size_t]))
attention_weighted_encoding = gate * attention_weighted_encoding
h, c = self.decode_step(
torch.cat([
embeddings[:batch_size_t, t, :],
attention_weighted_encoding
],
dim=1), (h[:batch_size_t], c[:batch_size_t]))
preds = self.fc(self.dropout(h))
predictions[:batch_size_t, t, :] = preds
alphas[:batch_size_t, t, :] = alpha
return predictions, encoded_captions, decode_lengths, alphasattention辅助类定义如下:
class Attention(nn.Module):
def __init__(self, encoder_dim, decoder_dim, attention_dim):
super(Attention, self).__init__()
self.encoder_att = nn.Linear(encoder_dim, attention_dim)
self.decoder_att = nn.Linear(decoder_dim, attention_dim)
self.full_att = nn.Linear(attention_dim, 1)
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
def forward(self, encoder_out, decoder_hidden):
att1 = self.encoder_att(encoder_out)
att2 = self.decoder_att(decoder_hidden)
# unsqueeze(arg) 在第arg维增加一个维度值为1的维度
# squeeze(arg) 第arg维的维度值为1,则去掉该维度
att = self.full_att(self.relu(att1 + att2.unsqueeze(1))).squeeze(2)
alpha = self.softmax(att)
attention_weighted_encoding = (encoder_out * alpha.unsqueeze(2)).sum(
dim=1)
return attention_weighted_encoding, alpha
2.3 预处理prepro.py
预处理部分一般依据任务类型而定,例如nlp的话主要是搭建字典,而cv主要是将图片进行resize、降噪、标准化等等。
而这个picture_caption的项目就决定了要同时做nlp和cv的预处理工作。
一 nlp 搭建字典的部分
from flickr8k_dataloader import flickr8k
class Vocabulary(object):
"""Simple vocabulary wrapper."""
def __init__(self):
self.word2idx = {}
self.idx2word = {}
self.idx = 0
def add_word(self, word):
if not word in self.word2idx:
self.word2idx[word] = self.idx
self.idx2word[self.idx] = word
self.idx += 1
def __call__(self, word):
if not word in self.word2idx:
return self.word2idx['']
return self.word2idx[word]
def __len__(self):
return len(self.word2idx)
def build_vocab(json, threshold):
"""Build a simple vocabulary wrapper."""
flickr = flickr8k(ann_text_location=json)
counter = Counter()
anns_length = len(flickr.anns)
for id in range(anns_length):
caption = str(flickr.anns[id]['caption'])
tokens = nltk.tokenize.word_tokenize(caption.lower())
counter.update(tokens)
if id % 1000 == 0:
print("[%d/%d] Tokenized the captions." % (id, anns_length))
# 如果当词频低于 'threshold', 就会被抛弃
words = [word for word, cnt in counter.items() if cnt >= threshold]
# 创建一个并添加一些特殊的 token
vocab = Vocabulary()
vocab.add_word('')
vocab.add_word('')
vocab.add_word('')
vocab.add_word('')
# 将单词添加到字典中
for i, word in enumerate(words):
vocab.add_word(word)
return vocab 这里用到了我的 flickr8k_dataloader.py 中的辅助类 flickr8k
flickr8k_dataloader.py 完整文件如下
# coding=utf-8
'''
读取flickr8k数据集
'''
import re
import os
class flickr8k():
def __init__(
self,
ann_text_location='/mnt/disk2/flickr8k/Flickr8k_text/Flickr8k.lemma.token.txt',
imgs_location='/mnt/disk2/flickr8k/Flickr8k_Dataset/Flickr8k_Dataset/',
ann_rank=4):
'''
读取flickr8k数据集的辅助类
:param ann_text_location: annotation文件所在的位置
:param imgs_location: 图片文件夹所在位置
:param ann_rank: 选取第几个等级的annotation
'''
self.ann_text_location = ann_text_location
self.ann_rank = ann_rank
self.imgs_location = imgs_location
self.anns = self.read_anns()
def read_anns(self):
'''
读取图片id(不含.jpg)和annotation
:returns: anns 一个list 每个元素为一个dict: {'image_id': image_id, 'annotation': image_annotation}
'''
anns = []
with open(self.ann_text_location, 'r') as raw_ann_text:
ann_text_lines = raw_ann_text.readlines()
match_re = r'(.*).jpg#' + str(self.ann_rank) + '\s+(.*)'
for line in ann_text_lines:
matchObj = re.match(match_re, line)
if matchObj:
image_id = matchObj.group(1)
image_annotation = matchObj.group(2)
image = {'image_id': image_id, 'caption': image_annotation}
anns.append(image)
return anns
def loadImg(self, img_id):
'''
返回一张图片的完整路径
:param imgid: 图片的id(不含.jpg)
:param return: img_path 图片的完整路径
:returns: img_path 图片完整路径
'''
img_path = os.path.join(self.imgs_location, img_id + '.jpg')
return img_path
# 测试
# if __name__ == "__main__":
# f = flickr8k()
# print('f.anns[0] ', f.anns[0])
# print('len(f.anns)', len(f.anns))
# id = f.anns[0]['image_id']
# path = f.loadImg(id)
# print('path', path)
二 cv 调整图片的部分
from PIL import Image
def resize_image(image):
width, height = image.size
# 图片 resize 后以长和宽两者中较短的长度为基准
# 长的边取基准长度的中心部分进行截取 最后形成方形
if width > height:
left = (width - height) / 2
right = width - left
top = 0
bottom = height
else:
top = (height - width) / 2
bottom = height - top
left = 0
right = width
image = image.crop((left, top, right, bottom))
image = image.resize([224, 224], Image.ANTIALIAS) # ANTIALIAS 高质量
return image
三 两个配套的主函数(构造字典、resize图片并保存)
def main(args):
vocab = build_vocab(json=args.caption_path, threshold=args.threshold)
vocab_path = args.vocab_path
with open(vocab_path, 'wb') as f:
pickle.dump(vocab, f)
print("Total vocabulary size: %d" % len(vocab))
print("Saved the vocabulary wrapper to '%s'" % vocab_path)
folder = '/mnt/disk2/flickr8k/Flickr8k_Dataset/Flickr8k_Dataset/'
resized_folder = '/mnt/disk2/flickr8k/Flickr8k_Dataset/Flickr8k_Dataset_resized/'
if not os.path.exists(resized_folder):
os.makedirs(resized_folder)
print('Start resizing images.')
image_files = os.listdir(folder)
num_images = len(image_files)
for i, image_file in enumerate(image_files):
with open(os.path.join(folder, image_file), 'rb') as f:
with Image.open(f) as image:
image = resize_image(image) # resize 图片
image.save(
os.path.join(resized_folder, image_file),
image.format) # 保存resize之后的图片
if i % 100 == 0:
print('Resized images: %d/%d' % (i, num_images))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--caption_path',
type=str,
default='/mnt/disk2/flickr8k/Flickr8k_text/Flickr8k.lemma.token.txt',
help='path for train annotation file')
parser.add_argument(
'--vocab_path',
type=str,
default='/mnt/disk2/flickr8k/Flickr8k_Dataset/vocab.pkl',
help='path for saving vocabulary wrapper')
parser.add_argument(
'--threshold',
type=int,
default=1,
help='minimum word count threshold')
args = parser.parse_args()
main(args)
2.4 数据加载data_loader.py
在2.1.4 main函数 承载主要逻辑的第四部分讲数据集搭建时已经完整介绍,故不再赘述,贴完整代码如下
# coding=utf-8
import os
import nltk
import torch
import torch.utils.data as data
from PIL import Image
from flickr8k_dataloader import flickr8k
class DataLoader(data.Dataset):
def __init__(self, root, json, vocab, rank, transform=None):
self.root = root
self.flickr = flickr8k(
ann_text_location=json, imgs_location=root, ann_rank=rank)
self.vocab = vocab
self.rank = rank
self.transform = transform
# 支持范围从0到len(self)独占的整数索引
def __getitem__(self, index):
flickr = self.flickr
vocab = self.vocab
# ann:annotation
caption = flickr.anns[index]['caption']
img_id = flickr.anns[index]['image_id']
path = flickr.loadImg(img_id)
image = Image.open(path).convert('RGB')
if self.transform is not None:
image = self.transform(image)
tokens = nltk.tokenize.word_tokenize(str(caption).lower()) # 分词
caption = []
caption.append(vocab(''))
caption.extend([vocab(token) for token in tokens])
caption.append(vocab(''))
target = torch.Tensor(caption)
return image, target
def __len__(self):
return len(self.flickr.anns)
def collate_fn(data):
data.sort(key=lambda x: len(x[1]), reverse=True)
images, captions = zip(*data)
images = torch.stack(images, 0) # 将张量序列沿新维度串联起来
lengths = [len(cap) for cap in captions]
targets = torch.zeros(len(captions), max(lengths)).long()
for i, cap in enumerate(captions):
end = lengths[i]
targets[i, :end] = cap[:end]
return images, targets, lengths
def get_loader(root, json, vocab, transform, batch_size, rank, shuffle,
num_workers):
flickr = DataLoader(
root=root, json=json, vocab=vocab, rank=rank, transform=transform)
# 数据加载 flickr 数据集
# 每次迭代返回 (images, captions, lengths)
# images: tensor of shape (batch_size, 3, 224, 224).
# captions: tensor of shape (batch_size, padded_length).
# lengths: 表示每个标题有效长度的列表. length is (batch_size).
data_loader = torch.utils.data.DataLoader(
dataset=flickr,
batch_size=batch_size,
shuffle=shuffle,
num_workers=num_workers,
collate_fn=collate_fn) # 合并一个示例列表以形成一个 mini-batch
return data_loader
2.5 工具utils.py
这里主要是一些小工具,之前文字和代码已经提到 clip_gradient(在反向传播过程中计算剪辑梯度, 以避免梯度爆炸) 、save_checkpoint(保存中间模型)、AverageMeter(辅助类,跟踪度量的最新值、平均值、和与计数)、adjust_learning_rate(将学习率降低一个特定的因子)和accuracy(从预测和真实的标签, 计算top-k精度)。注释格式写得挺好的,直接看吧。
# coding=utf-8
import numpy as np
import torch
def init_embedding(embeddings):
"""
用均匀分布填补embedding tensor
:param embeddings: embedding tensor
"""
bias = np.sqrt(3.0 / embeddings.size(1))
torch.nn.init.uniform_(embeddings, -bias, bias)
def load_embeddings(emb_file, word_map):
"""
为指定的 word map 创建一个 embedding tensor, 用于加载到模型中
:param emb_file: file containing embeddings (stored in GloVe format)
:param word_map: word map
:return: embeddings(顺序与 word map 中的单词相同, 即 embeddings 的维度) emb_dim(embedding 维度)
"""
# 找到 embedding 维数
with open(emb_file, 'r') as f:
emb_dim = len(f.readline().split(' ')) - 1
vocab = set(word_map.keys())
# 创建 tensor 来保存 embeddings, initialize
embeddings = torch.FloatTensor(len(vocab), emb_dim)
init_embedding(embeddings)
# 读取 embedding 文件
print("\nLoading embeddings...")
for line in open(emb_file, 'r'):
line = line.split(' ')
emb_word = line[0]
# 处理词向量
# 去掉空格 再把字符串转换为 float 类型
embedding = list(
map(lambda t: float(t),
filter(lambda n: n and not n.isspace(), line[1:])))
# 忽略不在 train_vocab 中的单词
if emb_word not in vocab:
continue
# 将 embedding 中的单词和词向量记录在 embeddings 中
embeddings[word_map[emb_word]] = torch.FloatTensor(embedding)
return embeddings, emb_dim
def clip_gradient(optimizer, grad_clip):
"""
在反向传播过程中计算剪辑梯度, 以避免梯度爆炸
:param optimizer: optimizer with the gradients to be clipped
:param grad_clip: clip value
"""
for group in optimizer.param_groups:
for param in group['params']:
if param.grad is not None:
# 将输入的所有元素钳入范围[min, max]并返回一个结果张量
# 本身在其中的就不变 超出的分别用 min 和 max 代替
param.grad.data.clamp_(-grad_clip, grad_clip)
def save_checkpoint(data_name, epoch, epochs_since_improvement, encoder,
decoder, encoder_optimizer, decoder_optimizer, bleu4,
is_best):
"""
Saves model checkpoint.
:param data_name: base name of processed dataset
:param epoch: epoch number
:param epochs_since_improvement: number of epochs since last improvement in BLEU-4 score
:param encoder: encoder model
:param decoder: decoder model
:param encoder_optimizer: optimizer to update encoder's weights, if fine-tuning
:param decoder_optimizer: optimizer to update decoder's weights
:param bleu4: validation BLEU-4 score for this epoch
:param is_best: is this checkpoint the best so far?
"""
state = {
'epoch': epoch,
'epochs_since_improvement': epochs_since_improvement,
'bleu-4': bleu4,
'encoder': encoder,
'decoder': decoder,
'encoder_optimizer': encoder_optimizer,
'decoder_optimizer': decoder_optimizer
}
filename = 'checkpoint_' + data_name + '.pth.tar'
torch.save(state, filename)
# 如果这个 checkpoint 是目前为止最好的,存储一个副本,这样它就不会被更差的 checkpoint 覆盖
if is_best:
torch.save(state, 'BEST_' + filename)
class AverageMeter(object):
"""
跟踪度量的最新值、平均值、和与计数
"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def adjust_learning_rate(optimizer, shrink_factor):
"""
将学习率降低一个特定的因子
:param optimizer: optimizer whose learning rate must be shrunk.
:param shrink_factor: factor in interval (0, 1) to multiply learning rate with.
"""
print("\nDECAYING learning rate.")
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * shrink_factor
print(
"The new learning rate is %f\n" % (optimizer.param_groups[0]['lr'], ))
def accuracy(scores, targets, k):
"""
从预测和真实的标签, 计算top-k精度
:param scores: scores from the model
:param targets: true labels
:param k: k in top-k accuracy
:return: top-k accuracy
"""
batch_size = targets.size(0)
_, ind = scores.topk(k, 1, True, True)
correct = ind.eq(targets.view(-1, 1).expand_as(ind))
correct_total = correct.view(-1).float().sum() # 0D tensor
return correct_total.item() * (100.0 / batch_size)
2.6 验证集数据集创建
主要是将原始的flickr8k中找些图片出来当验证集,这里我有个小逻辑错误(之前一个版本),那就是训练集包含了这些2333以后做项目的时候一定要将验证数据集和训练数据集分开啊,哈哈哈。(现在的代码已经修正了)
顺便要处理下annotation文件,用了个小正则,把图片id和caption抓了出来。
import re
import numpy as np
import os
import random
ann_text_location = '/mnt/disk2/flickr8k/Flickr8k_text/Flickr8k.lemma.token.txt'
val_text_folder = '/mnt/disk1/zjhao/show_attend_and_tell_pytorch_flickr8/val/'
ann_text_val_location = os.path.join(val_text_folder,
'Flickr8k_val.lemma.token.txt')
ann_text_train_location = os.path.join(val_text_folder,
'Flickr8k_train.lemma.token.txt')
pictures_img_resized_folder = '/mnt/disk2/flickr8k/Flickr8k_Dataset/Flickr8k_Dataset_resized/'
pictures_img_resized_val_folder = '/mnt/disk2/flickr8k/Flickr8k_Dataset/Flickr8k_Dataset_val_resized'
pictures_img_resized_train_folder = '/mnt/disk2/flickr8k/Flickr8k_Dataset/Flickr8k_Dataset_train_resized'
picture_rank = 5
item = 0
val_rate = 0.1
pictures_captions = []
picture_captions = []
with open(ann_text_location, 'r') as raw_ann_text:
ann_text_lines = raw_ann_text.readlines()
total = int(len(ann_text_lines) / picture_rank)
val_total = int(total * val_rate)
train_total = total - val_total
val_random = random.sample(range(total), val_total)
if not os.path.exists(val_text_folder):
os.makedirs(val_text_folder)
if not os.path.exists(pictures_img_resized_val_folder):
os.makedirs(pictures_img_resized_val_folder)
if not os.path.exists(pictures_img_resized_train_folder):
os.makedirs(pictures_img_resized_train_folder)
for doc_path in os.listdir(pictures_img_resized_val_folder):
if not os.path.isdir(doc_path):
os.remove(os.path.join(pictures_img_resized_val_folder, doc_path))
# val
with open(ann_text_val_location, 'w+') as val_ann_text:
count = 0
for val_id in val_random:
for line in ann_text_lines[val_id * 5:val_id * 5 + 5]:
val_ann_text.write(line)
match_line = ann_text_lines[val_id * 5]
match_re = r'(.*).jpg#[0-9]\s+.*'
matchObj = re.match(match_re, match_line)
try:
img_full_path = os.path.join(pictures_img_resized_folder,
matchObj.group(1) + '.jpg')
img_full_path_copy = os.path.join(pictures_img_resized_val_folder,
matchObj.group(1) + '.jpg')
except:
pass
os.system('cp %s %s' % (img_full_path, img_full_path_copy))
count += 1
print('%d/%d' % (count, val_total))
d = lambda x, y: [i for i in x if i not in y] # 集合 x-y
all_sample = list(range(total))
train_random = d(all_sample, val_random)
# train
with open(ann_text_train_location, 'w+') as train_ann_text:
count = 0
for train_id in train_random:
for line in ann_text_lines[train_id * 5:train_id * 5 + 5]:
train_ann_text.write(line)
match_line = ann_text_lines[train_id * 5]
match_re = r'(.*).jpg#[0-9]\s+.*'
matchObj = re.match(match_re, match_line)
try:
img_full_path = os.path.join(pictures_img_resized_folder,
matchObj.group(1) + '.jpg')
img_full_path_copy = os.path.join(
pictures_img_resized_train_folder,
matchObj.group(1) + '.jpg')
except:
pass
os.system('cp %s %s' % (img_full_path, img_full_path_copy))
count += 1
print('%d/%d' % (count, train_total))
2.7 其他一般性的经验总结
2.7.1 注释
注释要写好真的是太关键了,当然不只是用#这样的事情。主要是函数的注释,要在函数名下用'''xxx'''(单引号双引号均可)这样的长字符串写明函数功能,输入,输出等具体信息,这样既可以理清思路,也可以在vscode提示里一目了然,举例如下:

注释格式即为
def 函数名(参数):
'''
函数功能
:param 参数名1: 参数意义、格式
:param 参数名2: 参数意义、格式
:returns: 返回对象、格式
'''
# 开始写函数这样,在vscode里的提示就会看到这样(将鼠标放在其他引用这个函数的地方)
PS 参数就别管了,我只是为了展示一个效果2333
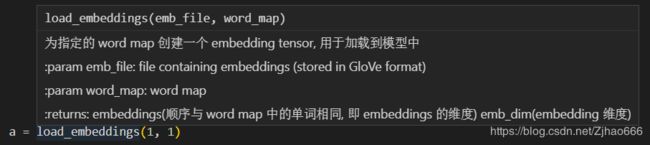
就非常的清楚明晰。
2.7.2 nohup
这个主要是可以退出xshell连接后让服务器的python继续执行,我就不用一直开着电脑等待了。
具体操作就是
nohup python python文件名.py > 要保存输出信息的文件 2>&1 &
例如
nohup python main.py > nohup.log 2>&1 &
命令解析
nohup 不挂断地运行命令
第一个> 标准输出重定向至nohup.log
2>&1 标准出错(2)重定向至标准输出(1),之前重定向了标准输出,所以出错信息和输出信息都可以在nohup.log里看到了。
& 在后台运行
然后运行命令,就可以退出xshell,回头看看nohup.log文件可以了。
正常结果(开头部分)如下(如果看到有报错就说明已经出错停掉了2333):
PS. pytorch让我快乐!!!!