pytorch实战|手写数字的识别
1.实验结果
随机从测试集导入20张手写数字的灰度图片,训练好的神经网络的识别结果如下图所示。
20张图片全部识别正确,只把训练集的数据迭代训练1遍,在整个测试集上训练的正确率就可以达到97.7%啦 。
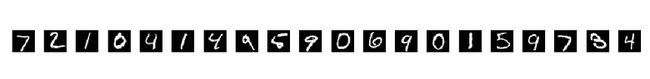

2.实验过程
2.1 准备
数据集 :使用mnist数据集(122MB),训练集包含6万张 28×28像素点的灰度图片和6万个对应的标签label,测试集包含1万张28×28像素点的灰度图片和1万个对应的label。灰度图就是每一个像素点都是由0-255来描述黑色浓度的图片。
数据集由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局的工作人员。简单来说就是一些这东西。下载地址

2.2 搭建、训练、测试和保存网络
# 1.导入库
import torch
import torch.nn as nn # neural network神经网络包(核心)
import torch.nn.functional as F # F中包含激活函数
import torch.utils.data as Data # Data是批训练的模块
import torchvision # 包含计算机视觉的相关图片库
import matplotlib.pyplot as plt # 绘图工具
# 2.超参数
EPOCH = 1 # 所有数据迭代训练的次数
BATCH_SIZE = 50 # 一批训练50个图片
LR = 0.001 # 学习率
DOWNLOAD_MNIST = False # 第一次设置成True下载MINST数据集
CESHI = 2000 # 取测试集的前2000个图片测试
# 3.数据下载和预处理
# 3.1 使用torchvision去网站下载MNIST数据集
train_data = torchvision.datasets.MNIST(
root='./mnist', # 在当前路径新建mnist文件夹保存数据集
train=True, # True提取训练数据train_data,Fasle提取测试数据test_data
transform=torchvision.transforms.ToTensor(), # 把原始数据改变成tensor数据形式(0,1)
download=DOWNLOAD_MNIST # 是否下载MNIST
)
test_data = torchvision.datasets.MNIST(
root='./mnist',
train=False
)
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:CESHI]/255
test_y = test_data.targets[:CESHI] # 取前2000个图片测试
# 3.2查看训练集
# print(train_data.data.size()) # 训练集图片的数目 [60000, 28, 28]
# print(train_data.targets.size()) # 训练集标签的数目 [60000]
# print(test_data.data.size()) # 测试集图片的数目 [10000, 28, 28]
# print(test_data.targets.size()) # 测试集标签的数目 [10000]
# plt.imshow(train_data.data[0].numpy(), cmap='gray') # 看看第一张图片的样子
# plt.title('%i' % train_data.targets[0]) # 把图片的标签当作标题
# plt.show()
# 3.3设置批训练数据
train_loader = Data.DataLoader(
dataset=train_data, # 数据集
batch_size=BATCH_SIZE, # 一批训练数据的个数
shuffle=True, # 下次训练是否打乱数据顺序
num_workers=2 # 多线程,使用双进程提取数据
)
# 4.建立CNN网络
class CNN(nn.Module):
# 4.1 设置神经网络属性,定义各层信息
def __init__(self):
super(CNN, self).__init__() #继承Module的固定格式
# 建立卷积层1
self.conv1 = nn.Sequential(
nn.Conv2d( # 卷积层
in_channels=1, # 输入图片的高度(灰度图1,彩色图3)
out_channels=16, # 输出图片的高度(提取feature的个数)
kernel_size=5, # 过滤器的单次扫描面积5×5
stride=1, # 步长
padding=2 # 在输入图片周围补0,补全图片的边缘像素点
), # 图片大小(1,28,28)->(16,28,28)
nn.ReLU(), # 激活函数
nn.MaxPool2d( # 池化层
kernel_size=2 # 压缩长和宽,取2×2像素区域的最大值作为该区域值
) # 图片大小(16,28,28)->(16,14,14)
)
# 建立卷积层2
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2), # 图片大小(16,14,14)->(32,14,14)
nn.ReLU(),
nn.MaxPool2d(2) # 图片大小(32,14,14)->(32,7,7)
)
# 建立输出层
self.out = nn.Linear(32*7*7, 10)
# 4.2 前向传播过程
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x) # (batch,32,7,7)
x = x.view(x.size(0), -1) # (batch,32*7*7) 将三维数据展平成二维数据
output = self.out(x)
return output
# 定义网络
cnn = CNN()
# 5.优化器
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # 优化网络的所有参数
loss_func = nn.CrossEntropyLoss() # 误差计算函数
# 6.训练
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
output = cnn(x)
loss = loss_func(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 可视化训练过程
if step % 50 == 0:
test_output = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.squeeze()
accuracy = (pred_y == test_y).sum().item() / CESHI
print('Epoch:', epoch,
'|loss:', loss.data.numpy(),
'|accuracy:', accuracy)
# 7.测试
test_output = cnn(test_x[:10]) # 取前测试集的10图片测试
pred_y = torch.max(test_output, 1)[1].data.squeeze()
print('真实值:', test_y[:10].numpy()) # 真实值
print('预测值:', pred_y.numpy()) # 预测值
# 把前10张图片打印出来
plt.figure(1, figsize=(10, 3))
for i in range(1, 11):
plt.subplot(1, 10, i)
plt.imshow(test_data.data[i-1].numpy(), cmap='gray')
plt.axis('off') # 去除图片的坐标轴
plt.xticks([]) # 去除x轴刻度
plt.yticks([]) # 去除y轴刻度
plt.show()
# 保存训练好的网络
torch.save(cnn.state_dict(), 'cnn_params.pkl')
2.3 直接调用训练好的网络
新建python文件,直接调用上面保存好的网络,在处理新图片的时候,就不需要重新训练了。
# 1.导入包
import torch
import torch.nn as nn # neural network神经网络包
import torch.nn.functional as F # F中包含激活函数
import torch.utils.data as Data # Data是批训练的模块
import torchvision # 包含计算机视觉的相关图片库
import matplotlib.pyplot as plt # 绘图工具
# 2.加载测试集
test_data = torchvision.datasets.MNIST(
root='./mnist',
train=False
)
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:2000]/255
test_y = test_data.targets[:2000] # 取前2000个图片测试
# 3.调用网络
# 因为使用torch.save(cnn.state_dict(), 'cnn_params.pkl')只保存了cnn网络的参数
# 所以在调用前需要搭建和cnn一样的网络(class内容直接copy过来就OK)
class CNN(nn.Module):
# 设置神经网络属性,定义各层信息
def __init__(self):
super(CNN, self).__init__() #继承Module的固定格式
# 建立卷积层1
self.conv1 = nn.Sequential(
nn.Conv2d( # 卷积层
in_channels=1, # 输入图片的高度(灰度图1,彩色图3)
out_channels=16, # 输出图片的高度(提取feature的个数)
kernel_size=5, # 过滤器的单次扫描面积5×5
stride=1, # 步长
padding=2 # 在输入图片周围补0,补全图片的边缘像素点
), # 图片大小(1,28,28)->(16,28,28)
nn.ReLU(), # 激活函数
nn.MaxPool2d( # 池化层
kernel_size=2 # 压缩长和宽,取2×2像素区域的最大值作为该区域值
) # 图片大小(16,28,28)->(16,14,14)
)
# 建立卷积层2
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2), # 图片大小(16,14,14)->(32,14,14)
nn.ReLU(),
nn.MaxPool2d(2) # 图片大小(32,14,14)->(32,7,7)
)
# 建立输出层
self.out = nn.Linear(32*7*7, 10)
# 前向传播过程
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x) # (batch,32,7,7)
x = x.view(x.size(0), -1) # (batch,32*7*7) 将三维数据展平成二维数据
output = self.out(x)
return output
cnn1 = CNN()
cnn1.load_state_dict(torch.load('cnn_params.pkl'))
print(cnn1)
# 4.取测试集前20张图片测试
test_output = cnn1(test_x[:20])
pred_y = torch.max(test_output, 1)[1].data.squeeze()
print('真实值:', test_y[:20].numpy())
print('预测值:', pred_y.numpy())
plt.figure(1, figsize=(10, 3))
for i in range(1, 21):
plt.subplot(1, 20, i)
plt.imshow(test_data.data[i-1].numpy(), cmap='gray')
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.show()