【李宏毅机器学习笔记】 24、集成学习(Ensemble)
【李宏毅机器学习笔记】1、回归问题(Regression)
【李宏毅机器学习笔记】2、error产生自哪里?
【李宏毅机器学习笔记】3、gradient descent
【李宏毅机器学习笔记】4、Classification
【李宏毅机器学习笔记】5、Logistic Regression
【李宏毅机器学习笔记】6、简短介绍Deep Learning
【李宏毅机器学习笔记】7、反向传播(Backpropagation)
【李宏毅机器学习笔记】8、Tips for Training DNN
【李宏毅机器学习笔记】9、Convolutional Neural Network(CNN)
【李宏毅机器学习笔记】10、Why deep?(待填坑)
【李宏毅机器学习笔记】11、 Semi-supervised
【李宏毅机器学习笔记】 12、Unsupervised Learning - Linear Methods
【李宏毅机器学习笔记】 13、Unsupervised Learning - Word Embedding(待填坑)
【李宏毅机器学习笔记】 14、Unsupervised Learning - Neighbor Embedding(待填坑)
【李宏毅机器学习笔记】 15、Unsupervised Learning - Auto-encoder(待填坑)
【李宏毅机器学习笔记】 16、Unsupervised Learning - Deep Generative Model(待填坑)
【李宏毅机器学习笔记】 17、迁移学习(Transfer Learning)
【李宏毅机器学习笔记】 18、支持向量机(Support Vector Machine,SVM)
【李宏毅机器学习笔记】 19、Structured Learning - Introduction(待填坑)
【李宏毅机器学习笔记】 20、Structured Learning - Linear Model(待填坑)
【李宏毅机器学习笔记】 21、Structured Learning - Structured SVM(待填坑)
【李宏毅机器学习笔记】 22、Structured Learning - Sequence Labeling(待填坑)
【李宏毅机器学习笔记】 23、循环神经网络(Recurrent Neural Network,RNN)
【李宏毅机器学习笔记】 24、集成学习(Ensemble)
------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av10590361?p=38
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
-------------------------------------------------------------------------------------------------------
Ensemble
Framework of Ensemble

Ensemble就是让几个模型(这几个模型通常各自的作用比较不同。)一起合作完成一个任务,那毋庸置疑,最后效果肯定会好过只有一个模型的。
接下来就看下有哪些方法可以使几个模型Ensemble。
Bagging
Review: Bias v.s. Variance

上图是第二篇笔记说过的:
- 模型越复杂(越高次),方差会变得越大,bias会变得越小。error会先下降然后再上升(因为发生过拟合)

上图是假设在不同的世界预测神奇宝贝的CP值。
使用复杂的model,最后预测结果的variance比较大。但是可以把不同模型的输出做平均,得到新的模型的输出![]() 。这时的预测值就会和实际值比较接近。
。这时的预测值就会和实际值比较接近。
Bagging做的事情就和这个类似。
Bagging
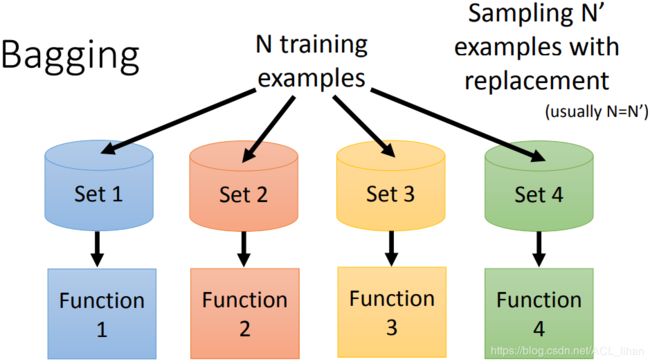
- 通过有放回的取样的方法将训练集分为4个不同的训练集
- 以这4个数据集训练出4个不同的模型。
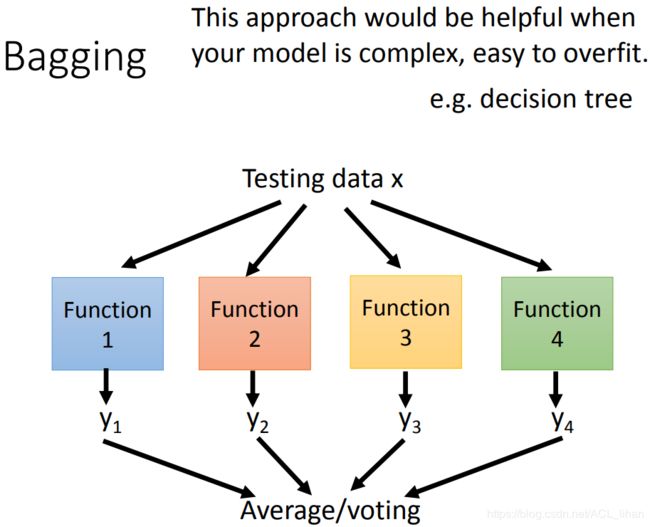
- 在上一步训练出4个模型之后,将testing data输入到这4个模型中
- 4个模型得出4个结果
- 如果是回归问题,那就将这4个结果取平均,就得到最终的结果;如果是分类问题,就进行投票,看看那一个类别是最多classifier投票给它的,就选这个类别作为最终的分类结果。
model容易发生过拟合的情况下,就可以使用Bagging。比如下面的决策树(Decision Tree)就容易发生过拟合。
决策树(Decision Tree)

假设 x 有两个维度,以这两个维度来判断 x 属于哪一类。
这棵树和图像如上图,很容易看懂。
在训练的时候要调整的有:
- 每个节点有多少分叉
- 分叉的标准
- 什么时候停止分叉
- 可能会问的问题
下面是一个分类初音的例子。
Experiment: Function of Miku
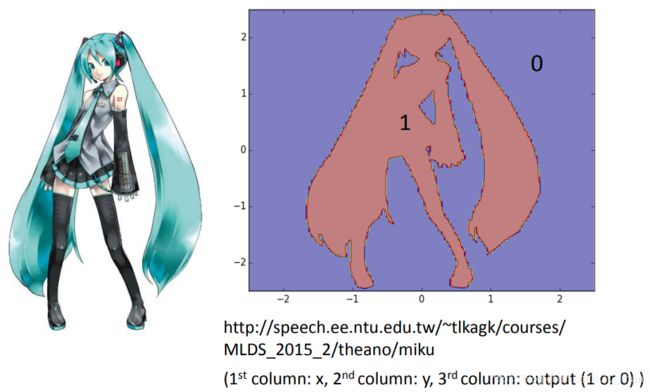
红色区域是class 1,蓝色区域是class 2 。
下面看不同深度的决策树的分类效果。

可以看到,随着决策树深度的加深,分类效果越来越好。
事实上,只要决策树一直加深下去,没有它分类不了的结果1(即 0% 的error)。
但是注意,这里说的 0% 的error是在training data的结果,所以决策树是比较容易过拟合的方法。
所以,需要用上刚才说的Bagging,来缓解过拟合。
Bagging+决策树 = Random Forest。
Random Forest

- 在Random Forest 使用bagging,只是做重采样的话,训练出来的几棵树还是比较像的。所以在每次分裂节点时随机限制哪些feature可用哪些feature不可用,避免各棵树长得太像。 将这些树集合起来就是随机森林。
- 之前做验证的时候是把数据切成两份,一份用于训练,一份用于验证。而这里使用bagging的话,就可以用Out-of-bag(OOB),这样就不用把数据切成两份。如上图,f1,f2,f3,f4代表不同的四棵树,x1,x2,x3,x4代表4份数据。做bagging的时候,每棵树只用其中的部分数据(比如f1只用都x1,x2的数据)所以就可以用类似
 这样的组合来做验证。然后取平均就得到估测的error值。
这样的组合来做验证。然后取平均就得到估测的error值。

上图是决策树和随机森林的结果对比。
随机森林由于有做平均,所以它的结果会比较平滑(即比较有泛化性)。
Boosting

上面的Bagging方法是应用在太强的model上,防止它发生过拟合。
而Boosting则是应用在太弱的model上,使它的拟合能力更强。

它的框架是这样:
- 先训练一个分类器
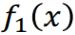
- 找一个分类器
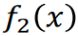 来弥补 的不足。要求 和 不能太像,这样才能起到互补的作用。
来弥补 的不足。要求 和 不能太像,这样才能起到互补的作用。 - 继续找一个分类器
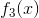 和互补
和互补 - 一直找下去……
最后将这些分类器合起来,就形成一个很强的分类器。
注意:这个过程一定要按顺序做下去,要先找到![]() ,再找
,再找![]() …… 不能平行地训练模型。
…… 不能平行地训练模型。

既然要训练不同的分类器,就需要用不同的training data。
- 像刚才bagging那样重采样就可以产生不同的data set
- 给每个data加上权重(刚才的取样,重复取样2次的话权重就是2),但这个方法不限于整数,它可以使用小数。而实际中,要实现给data加权重,只需要改变Loss Function
Idea of Adaboost

既然要使![]() 和
和 ![]() 两个分类器互补,那就要找到一个新的data set,
两个分类器互补,那就要找到一个新的data set,![]() 在这个data set上分类效果很差。然后以这个新的data set去训练
在这个data set上分类效果很差。然后以这个新的data set去训练 ![]() ,就能起到两个分类器互补的结果。
,就能起到两个分类器互补的结果。
实验中可以这样实现:
- 先训练一个分类器 ,使得它的error rate低于0.5。
- 用新的data set的weight
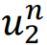 代替刚才的data set的weight
代替刚才的data set的weight  (此时就相当于新的training data)。这些新的training data要使分类器 的error rate等于0.5 (由于这里是二分类问题,error rate等于0.5就相当于 分类结果和乱选没区别)。
(此时就相当于新的training data)。这些新的training data要使分类器 的error rate等于0.5 (由于这里是二分类问题,error rate等于0.5就相当于 分类结果和乱选没区别)。 - 以这些新的training data去训练和 互补的新的分类器 。
下面是具体的例子。

- 一开始所有data的weight都是1,以这些training data去训练,得出 ,此时error rate为0.25
- 修改这些data的weight,让 分类正确的 data 的 weight 变小,让 分类错误的 data 的 weight 变大。
- 以这些修改过weight的data去训练,得出和 互补的分类器 。
接下来看下怎么重新给data设置weight。
Re-weighting Training Data

- 如果 分类错误,weight就乘上
 变大。
变大。 - 如果 分类正确,weight就除以
 变小。
变小。
接下来看下怎么确定 ![]() 的值。
的值。


上面2图就是推导过程,没有涉及复杂的数学,如果需要详细的讲解可以看下视频。
反正推导得出结论是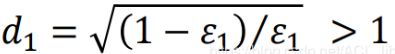 ,即
,即 ![]() 一定会大于1 。
一定会大于1 。
Algorithm for AdaBoost

上图就是AdaBoost的算法示意图。
由于这里的问题是二分类(结果为+1或-1),所以红框中的内容可以简写为 ![]() 。
。
现在我们有了很多的分类器,如何把它们合起来呢?

如上图,有两种方法。
- 由于
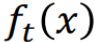 的结果只有+1和-1,所以可以直接把所有分类器的output累加起来,看大于1的结果多还是小于1的结果多,然后选择结果多的那个作为最后的输出。
的结果只有+1和-1,所以可以直接把所有分类器的output累加起来,看大于1的结果多还是小于1的结果多,然后选择结果多的那个作为最后的输出。 - 根据分类器的分类好坏,给予不同的weight
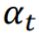 。如果error rate为0.1,则说明分类比较准, 给得比较大。如果error rate为0.4,则说明分类比较不准, 给得比较小。
。如果error rate为0.1,则说明分类比较准, 给得比较大。如果error rate为0.4,则说明分类比较不准, 给得比较小。
下面举个例子,可以看看AdaBoost的威力。
Toy Example
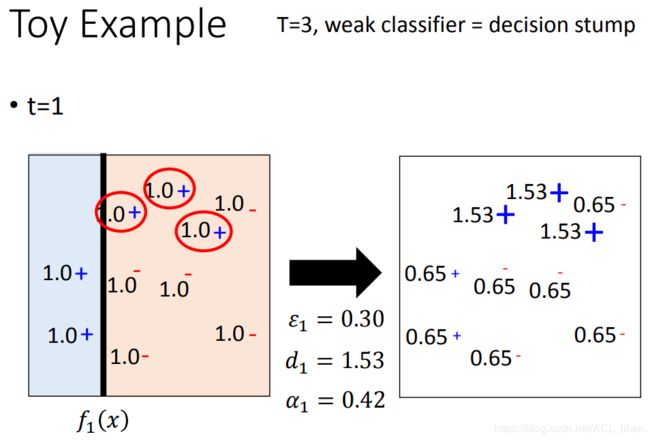
这里用的分类器是decision stump,一个很弱的模型,不认识它没事,反正就知道它只是切一刀就行。
- 如上图,一开始data的weight都是1,然后decision stump就往这个空间切一刀。
- 此时
 ,
,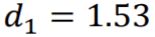 ,
,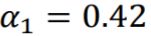 。
。 - 重新赋予data的weight,如上图右边
同上。
同上。

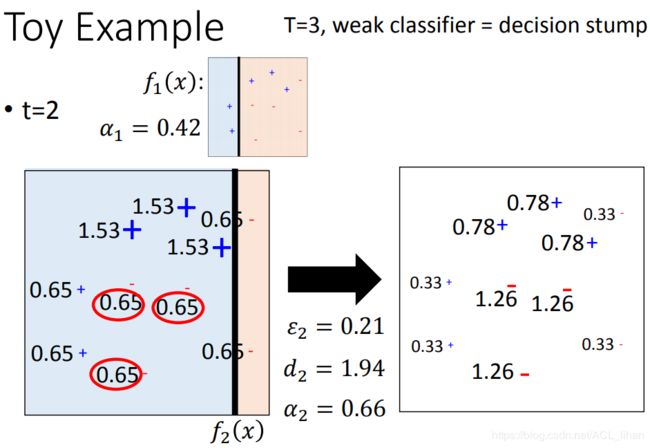
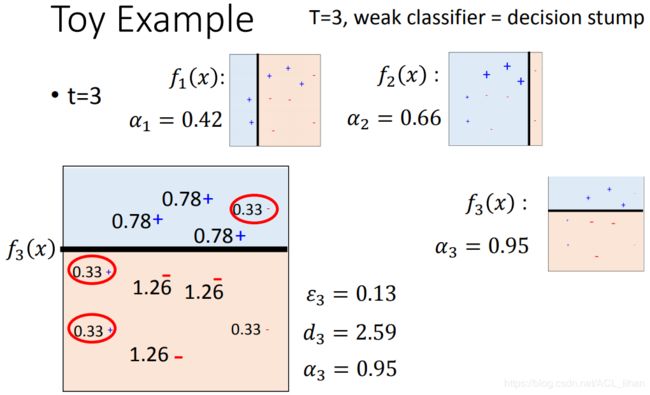
现在训练出三个模型了,也有它们各自的权重了,来进行最后的分类了。
由于有三条线,把空间切成6块。以右上角那一块为例子。
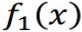 认为这一块是红色的,
认为这一块是红色的, 认为这一块也是红色,而
认为这一块也是红色,而 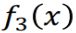 认为这一块是蓝色的。
认为这一块是蓝色的。- 意见不合,那算一下weight, 的weight为0.42, 的weight为0.66,加起来超过 的0.95,
- 所以最后判定这一块,是属于红色的。
其他区域的分类过程也同理。