大规模细粒度分类和领域特定迁移学习Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning翻译
这次翻译的论文是CVPR2018的,关于细粒度分类和迁移学习的论文,论文下载地址为:链接: https://pan.baidu.com/s/1fzMbUA0fYi9b5ETeWZfP4w 提取码: 3yqa
摘要
从大规模数据集(比如ImageNet)上迁移的知识经过微调后,为领域特定细粒度视觉分类(FGVC)任务(比如识别鸟的种类,汽车品牌和型号)提供了有效的解决方法。在这个方案中,数据注释经常需要专业的领域知识,因此很难规范。在这个工作中,我们首先在大型FGVC上处理了一个问题。我们的方法在iNaturalist 2017大规模种类识别挑战上获得了第一名。我们的方法成功的核心是一种训练方法:使用更高的图片分辨率和解决训练集的长尾分布。接着我们通过从大规模到小规模数据(领域特定FGVC数据集)微调的迁移学习。我们提出了一种通过搬土距离来估计领域相似度的方法,并证明这个方法迁移学习通过在与目标领域相似的源领域预训练是有好处的。我们提议的迁移学习胜于ImageNet预训练,并且在多个常用的fgvc数据集上获得了优秀的结果。
1 引言
细粒度视觉分类(FGVC)旨在区分隶属的视觉分类,包括识别自然的类别:鸟,狗,植物的种类,或者人造类别比如汽车品牌和型号。一个成功的FGVC模型应该有能力区分类别的轻微不同,这展示了模型设计的强大挑战,也提供了观点给大量的应用,比如图像字幕,图像生成和机器教学。
视觉识别方面的卷积神经网络(CNNs)在FGVC上获得了显著的进步。总的来说,为了通过CNNs达到相当好的表现,一个需要做的事情是在大量的有监督数据集上进行网络训练。然而,实际带标签的细粒度数据集通常需要专家级别的领域知识因此很难。因此,常用的FGVC数据集通常较小,一般包含1万张已标签的训练图片。在这个方案中,一般采用微调在大型数据集上(比如ImageNet)已经预训练过的网络。
这个常见的体制提出了两个问题:1)在大型FGVC上达到好的结果的重要因素是什么?即使其它大型普通视觉数据集比如ImageNet包含了一些细粒度分类,它们的图片通常是有符号的网络图像,在中心包含具有相似尺寸的物体和简单的背景。大型FGVC数据集有有限的可用性,在大型非标记细粒度分类图像中,怎么设计模型依然是不发达的方面。2)如何有效地进行迁移学习,首先在大型数据集上训练网络,然后再领域特定细粒度数据集上进行微调?现代的FGVC方法压倒性的使用ImageNet预训练再进行微调。事实是,目标细粒度域是已知的,我们能做的比ImageNet更好吗?
这篇论文旨在回答上述的这两个问题,随着最近引入的大型细粒度数据集iNaturalist 2017(iNat)。INat包含5089种细粒度分类的675170张训练和验证图片。所有的图片具有不同的物体尺寸和背景,都是在自然环境下拍摄的。因此,iNat提供了研究能使在大型FGVC上训练CNNs结果好的重要因素的好机会。另外,随着iNat能使我们学习从大型数据集到小型细粒度域的知识迁移。
在这个工作中,我们首先提出了大型细粒度分类的一种训练方法,在iNat中达到了顶级的结果。不像ImageNet, iNat中的图片有更高的分辨率和广泛的目标尺寸。我们在3.1节展示了输入更高分辨率的图片,iNat的结果得到显著提升。我们在本文中讨论的另一个问题是长尾分布,即有些类别占有大多数的图片。为了解决这个问题,我们提出了一个简单但有效的方法。这个方法是从大量的训练集中学习好的特征,然后在更均匀分布的子集上微调来平衡网络在所有分类中的效果和转换学习的特征。我们实验的结果在3.2节展示,说明了我们能极好地提升数量不够的分类和达到更好的总体水平。
第二,我们学习怎么迁移从大型数据集的知识到小型细粒度域。数据集经常是在内容和样式方面存在偏差。在CUB200鸟类数据集上,iNat预训练网络结果比在ImageNet上预训练的更好;尽管在Stanford-Dogs数据集上,在ImageNet上预训练结果更好。这是因为在iNat上鸟的分类和ImageNet上狗的分类更具有视觉相似。鉴于此,我们提出了一个新颖的方法来计算源和目标领域间的视觉相似度,该方法是基于搬土距离的图像级的视觉相似度计算。通过在选择的子集上基于我们提出的域相似度微调训练的网络,我们在常用的细粒度数据集上实现了比在ImageNet预训练更好的迁移学习和优秀的结果。图1展示了提出的训练方法的大概。

图1 迁移学习方法的概述。给予感兴趣的目标领域,我们从源领域通过提出的领域相似度计算方法选取子集进行CNN预训练,然后再目标域上进行微调。
我们相信我们在大型FGVC上的学习和领域特定的迁移学习能对研究工作的相似问题提供有用的指导。
2 相关工作
细粒度视觉分类(FGVC)
最近FGVC的方法通常将有用的细粒度信息并入CNN并端到端的训练网络。二阶双线性特征交互被证明是非常有效的。这个想法后来被扩展到紧凑的双线性池,然后更高的顺序交互。为了捕捉视觉上微小的不同,通常使用视觉的注意力和深度度量学习。超越像素级别,我们也利用其它信息,包括片段,属性,人类交互和内容描述。为了解决FGVC训练数据的缺少,另外的网络图像可以收集作为原始数据集的增强。我们的方法不同于它们,是在已存在的大型数据集上预训练网络并迁移而不是收集新数据。
使用FGVC上的高分辨率图像已经变得很流行。ImageNet视觉识别也有相似的真,从原来的AlexNet224 × 224到最近新提出的NASNET的331 × 331。然而,先前的工作没有像我们在这篇论文做的一样,系统地在大型细粒度数据上学习图片分辨率的影响。
怎么处理长尾分布在现实世界数据中是个重要的问题。然而,这是还未探索的方面,因为常用的基准数据集是经过预处理以接近均匀分布的。Van Horn等人指出在有足够训练集的情况下,尾部类别的表现比头部类别的更差。我们提出了一个简单的两步的训练方法来处理长尾分布,在实践上结果很好。
迁移学习
在ImageNet上训练的卷积神经网络(CNNs)已经广泛使用于迁移学习,也直接作为特征提取器直接使用在预训练网络上,或者微调网络。由于使用预训练CNN来迁移学习获得了显著的成功,在理解迁移学习方面做出了大量的努力。特别的,一些先前的工作不精确地证明了迁移学习和领域相似性之间的联系。比如,两个随机分类之间的迁移学习比ImageNet上的自然/人造物体分类更简单;在所有可用类中手动添加512个其他相关类别,改进了Pascal VOC上常用的1000个ImageNet类;从ImageNet和Places的联合数据集迁移能在一系列视觉识别任务中造成更好的结果。Azizpour等人对与原始ImageNet分类任务有不同相似度的一系列迁移学习任务(图像分类被认为比实例检索更相似)进行了有用的研究。我们和他们的工作主要不同是有两部分:首先,我们提供了一个方法,一种量化源域和目标域之间相似性的方法,然后从源域中选择一个更相似的子集,以便更好地进行迁移学习。第二,都使用预训练CNNs作为特征提取,只训练最后一层或者再提取的特征上使用线性SVM,尽管我们微调了网络的所有层。
3 大型细粒度分类
在这一节,我们提出了我们的训练方法,该方法在iNaturalist2017上达到顶级的效果,特别是关注使用更高精度的图片分辨率和处理长尾分布。
3.1 图像分辨率的影响
当训练CNN时,为了便于网络设计和批量设计,输入的图片通常是预处理成一定大小的正方形,每个网络架构通常都有默认的输入大小。比如,AlexNet和VGGNet默认的输入大小为224 × 224,并且默认的输入大小不能轻易改变,因为卷积后面的全连接层需要固定大小的特征图。更多最近的网络包括ResNet和Inception是全卷积,卷积后有全局平均池化层。这个设计能使输入网络的图片为任意形状。不同分辨率的图片会导致在网络中产生不同下采样尺寸的特征图。
更高分辨率的输入图片通常包含更丰富的信息和对视觉识别重要的微小细节,特别是FGVC。因此,一般来说,更高分辨率的图片能有更好的结果。用于在ImageNet上优化的网络,用更高分辨率的输入图片已成为趋势:原来AlexNet224×224变为最近提出的NASNet331 × 331,如表1所展示。然而,ImageNet的大多数图片的分辨率为500 × 375,包含相似尺度的物体,限制了我们可以从更高分辨率图像中获取好处。我们探索了在iNat数据集上使用大量输入图片的分辨率从299 × 299到560 × 560的效果,说明更高的输入分辨率能很好地提升效果。

表1 不同网络的默认输入图片分辨率,现在模型图片的分辨率有越来越高的趋势。
3.2 长尾分布
真实世界的图片数据集是长尾的:一些分类有高度代表性和大多数的图片,但是大多数分类只能观察到很少的图像。这与流行的基准数据集中均匀的图像分布形成了鲜明的对比,比如ImageNet,COCO和CUB200。
iNaturalist数据集中类别的图片数据分布极不均匀,我们观察到表现不佳的未充分代表的尾翼类别。我们认为这主要是由两个原因造成的:1)训练集的缺少。iNat训练集中大约有1500中细粒度类别只有30张不到的图片。2)训练过程中出现极端类别不平衡:最大类别中图片数量和最小之间的比例未435。无需对训练图像进行任何重新采样或对损失进行重新加权,头部中有更多图片的类别将会影响尾部图片类别。由于第一个问题缺乏训练数据,我们几乎无能为力,我们提出了一个简单有效的方法处理类别不均衡问题。
提出的训练方法有两步:第一步,我们像往常一样在原始的不平衡数据集上训练网络。因所有类别中大量的训练数据,网络能学习好的特征代表。第二步,我们以较小的学习速率在有更多平衡数据的子集上微调网络。这个方法迁移学习的特征太慢,导致网络在所有类别上再平衡。图2分别显示iNat上我们第一步训练的训练集上的和第二步子集图片频率分布。5.2节的实验证明了提出的方案提升了整体的效果,特别是代表性不足的尾部类别。
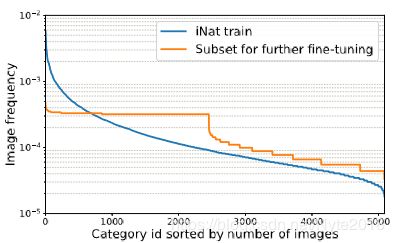
图2 第一阶段训练中使用的整个训练集中每个类别的图像频率分布以及第二阶段微调中使用的选定子集。
4 迁移学习
这一节描述了从大型数据集上训练的网络迁移学习到小型细粒度数据集。我们介绍一个方法来计算两个域之间的视觉相似度,然后显示怎么从给定目标域的源域中选定子集。
4.1 域相似度
假设我们有一个源域S和目标域T。我们定义两个图片s ∈ S和t ∈ T之间的距离为它们特征表示法的欧几里得距离:
![]()
g(·)表示一张图片的特征提取器。为了更好地捕捉图片的相似度,特征提取器g(·)需要能够以一般、无偏见的方式从图像中提取高级信息。因此,在我们的实验中,我们使用g(·)作为从大型JFT数据集上训练的ResNet-101倒数第二层的特征提取。
一般情况下,使用更多的图片能有更好的迁移学习效果。为了简单,在这个研究中我们忽视了域尺度(图片数量)的影响。具体的,我们对源和目标域中图片数量进行标准化。Chen等人的研究发现,迁移学习性能随训练数据量的增加呈对数增长。这表明,如果我们已经有了足够大的数据集,那么使用更多的训练数据所带来的迁移学习的效果将是微不足道的。因此,忽视域尺度是一个简化问题的合理假设。我们对域相似性的定义可以通过添加一个尺度因子来概括为考虑域尺度,但是我们发现忽略域尺度在实践中已经很有效。
在这个假设下,迁移学习可以看作从源域S中移动一些图片到目标域T。将一个图像移动到另一个图像所需的工作可以定义为它们在式一中的图像距离。两个域间的距离可以定义为整个工作所需要的最少的数量。这个域相似度的定义可以通过搬土距离(EMD)来计算。
为了使计算更容易处理,我们进一步进行了额外的简化,即通过图像特征的平均值来表示一个类别中的所有图像特征。从形式上来说,我们将源域表示为:
![]()
目标域为:
![]()
si表示S中的第i个目录,wsi表示那个类别中标准化的图片数量,T中的tj和wtj也是一样。m和n分别表示源域S和目标域T中的类别种数。因为我们标准化了图片数量,我们有:
![]()
g(Si)表示源域中类别i的图片特征的平均,目标域中的g(tj)也是同理。使用定义的符号,S和T之间的距离定义为搬土据集(EMD):
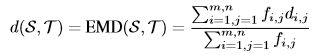
其中:
![]()
最佳流fi,j对应于求解EMD最佳问题的最少工作总量。最后,域相似度定义为:
![]()
其中,y在所有实验中都设为0.01。图3说明了通过EMD计算提出的域相似度。

图3:通过EMD计算提出的域相似度。源域和目标域中的类别分别用红色绿色圈表示。圈的大小表示那个类别中归一化图片的数量。蓝色箭头表示通过EMD解决从源到目标域的流。
4.2 源域选择
根据式2中定义的域相似度,我们能从源域中挑选和目标域更相似的子集。我们使用贪心选择算法来逐渐地包含源域中最相似的类别。在源域S中的每一个类别Si,我们通过式3中定义的sim({(si,1)},T )来计算与目标域的域相似度。前k个拥有最高域相似度的类别将会被选择。注意,虽然这种贪婪的选择方式不能保证从域相似性的角度来选择最优的K个子集,但我们发现这种简单的策略在实践中很有效。
5 实验
对于大型FGVC提出的训练方法在最近提出的iNaturalist2017数据集上进行评估。我们也评估了通过用ImageNet和iNat作为源域,7个细粒度分类数据集作为目标域的迁移学习的效果。5.1节介绍了实验设置,iNat上的实验结果和迁移学习在第3节和5.3节分别展示。
5.1 实验步骤
5.1.1 数据集
iNaturalist。iNatrualist2017数据集包含5089中自然界细粒度类别的675170张训练和验证图片。这些分类属于13种超分类包括Plantae(植物),Insecta(昆虫),Aves(鸟),Mammalia(哺乳动物)等。iNat数据集非常不平衡,每个类别的图像数量差异很大。比如,最大的超分类Plantae(植物)中有2101种类别和196613张图片。但是最小的超分类Protozoa只有4种类别和381张图片。我们将原始的训练集分割和90%的验证集作为我们的训练集(iNat train),其余10%的验证集作为我们的迷你验证集((iNat minival),总共产生665473个训练和9697个验证图像。
ImageNet。我们使用ILSVRC 2012的1000个分类划分为1281167张训练(ImageNet train)和50000张验证(ImageNet val)图片。
**细粒度视觉分类。**我们在7种细粒度视觉分类数据集上作为目标域来评估我们的迁移学习方法,并且这些类别覆盖了大量的FGVC任务,包括自然界的分类比如花,鸟,人造类别(飞机)。表2总结了类别的数量和划分的原始训练集验证集的图片数量。

表2 我们使用7种细粒度视觉分类数据集来验证提出的迁移学习方法。
5.1.2 网络构架
我们使用了三种网络构架:ResNet,Inception,SENet。
残差网络(ResNet)。最初是由He等人介绍的,残差连接的网络极大地减少了最优化的困难,并能训练更深的网络。通过使用身份映射作为残差模块之间的跳跃连接的预激活,Resnet后来得到了改进。我们使用有50,101,152层的ResNets的最新版本。
Inception。Inception模块首先由GoogleNet的Szegedy等人提出,该网络模型在参数和计算方面特别有效果,能达到最优的性能。Inception模块又通过批量归一化,因子分解卷积和残差连接得到了进一步优化。我们使用Inception-v3,Inception-v4和Inception-ResNet-v2作为我们实验的Inception网络模型代表。
SE-Net.最近由Hu等人提出,SE-Net在ILSVRC 2017上达到了最好的效果,通过空间平均池化挤压特征图的响应,然后学习重新缩放特征图的每个通道。由于这个设计很简单,SE-Net通常在现代网络种被使用来在不增加额外开销的情况下提高性能。我们使用Inceptionv3 SE和Inception-ResNet-v2作为基础。
对于所有的网络架构,我们严格遵守它们的原始设计但是最后的线性分类层要与我们数据集的类别数量匹配。
5.1.3 工具
我们在多个NVIDIA Tesla K80 GPUs上使用开源的Tensorflow异步实行和训练所有的模型。在训练过程中,将输入图像从原始图像中随机裁剪出来,并通过比例和纵横比增大,重新调整为目标输入尺寸。我们使用动量为0.9,批大小为32的RMSProp优化器来训练所有网络。初始的学习速率为0.045,每2个周期后指数衰减0.94,与比例和纵横比一样。通过迁移学习的微调后,初始的学习效率降低到0.0045,每4个周期后指数衰减0.94。我们也使用Inceptionv3的标签平滑。在总结过程中,原始图像被中心裁剪并重新调整为目标输入大小。
5.2 大型细粒度视觉识别
为了验证大型细粒度分类的学习方法,我们对iNaturalist 2017数据集进行了大量的实验。为了达到更好的效果,我们对ImageNet预训练网络进行了微调。如果从头开始训练iNat,top-5的错误率≈ 1%更差。
我们使用3种不同的输入分辨率(299, 448 和560)训练Inception-v3。图片分辨率的影响在表3展现。我们可以从表中看出,在iNat上使用更高分辨率的输入图片能达到更好的效果。

表3 使用Inception-v3输入不同的输入大小在iNat minival上的Top-5误差率。更高的输入大小能有更好的效果。
为了解决长尾分布,我们提出的微调方法的评估在图4表示。在更平衡的子集上用小的学习速率(我们的实验为10的-6次)进行微调能获得更好的性能。表4展示了通过微调头和尾部的类别的性能进步。头部分类大于等于100张训练图片的top-1和top-5的提升分别为1.95%和0.92%;但是尾部分类小于100张训练图片的top-1和top-5的提升分别为5.74%和2.71%。这些结果证明提出的微调方法极大地提升了未被充分代表的尾部分类的性能。

图4 在iNat minival的更平衡的子集上微调前和微调后的Top-5的误差率。这个简单的方法提升了长尾iNat数据集的性能
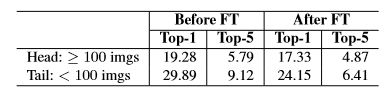
表4. iNat minival上Inception-v4 560的top-1和top-5的错误率。提出的微调方法极大的提升了未被充分代表的尾部分类的性能。
表5呈现了我们在iNaturalist 2017挑战赛中获奖的详细表现分析。使用更高精度的图片分辨率和在更平衡的子集上进一步微调是我们成功的关键。
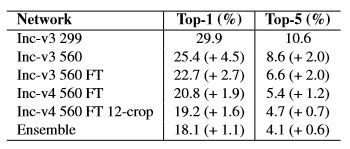
表5.在iNat minival提升的性能。括号内的数字表示与前一行中的模型相比有所改进。FT表示使用提出的微调来处理长尾分布。整体包括两个模型:Inc-v4 560 FT 和Inc-ResNet-v2 560 FT 12-crop.
5.3 域相似度和迁移学习
我们通过在源域上从头开始预训练网络,并在目标域上微调,以此在细粒度视觉分类上评估提出的迁移学习方法。除了在ImageNet和iNat上分别进行训练后,我们还在一个组合的Imagenet+INAT数据集上训练网络,该数据集包含来自6089个类别的1946640个图像图像(来自ImageNet的1000个和来自iNat的5089个)。我们对所有网络使用299 × 299的输入大小。表6显示在ImageNet val和iNat minival上评估的预训练性能。值得注意的是,在组合的IMAGENET+INAT数据集上训练的单个网络与单独训练的两个模型相比,具有竞争性的性能。总的来说,在Inception和Inception SE的情况下,联合训练优于单个训练,而Resnet的情况则更糟。

表6 在不同源域上预训练的性能。在组合ImageNet + iNat数据集上训练的网络(具有6089个类)在ImageNet 和 iNat上都达到了与在每个数据集上分别训练的网络相比的竞争力。∗表示该模型是在ImageNet验证集的非黑名单子集上评估的,该验证集可能稍微提高性能。
基于在4.2节提出的域选择方法,我们从联合的ImageNet + iNat数据集上挑选了以下两个子集:通过包含7个fgvc数据集的前200个imagenet+inat类别来选择的子集A,移除重复的分类会使源域包含832个分类;通过增加585个最相似的类别来挑选B,其中包括CUB200, NABirds的400种分类,Stanford Dogs的前100种分类,Stanford Cars和Aircraft的前50种分类。图6显示了通过我们提出的域相似度计算所有FGVC数据集上ImageNet + iNat前10个最相似的类别。很明显,CUB200, Flowers-102 和 NABirds上,最相似的类别来自iNat,而对于Stanford Dogs, Stanford Cars, Aircraft 和Food101,最相似的类别来自ImageNet。这表明ImageNet和iNat有很强的数据集偏差。

图6 这个例子展示了对每个FGVC数据集的联合ImageNet + iNat上前10个最相似的类别,是通过我们提出的域相似度计算的。左边一列代表7个FGVC目标域,每个都是从数据集中随机挑取的。每一行展示了每一种特定的FGVC目标域的ImageNet + iNat中前10个最相似的的类别。我们展示了从那个类中随机挑取的一张图片。ImageNet分类用蓝色标记,而iNat分类用红色标记。
表7说明了通过在细粒度数据集上微调Inception-v3的迁移学习效果。我们可以看到所有的ImageNet和iNat都有很高的偏差,在目标域上会达到非常不同的迁移学习效果。有趣的是,当我们迁移在ImageNet + iNat联合数据集上训练的网络时,性能在ImageNet 和iNat单独预训练的效果之间,这说明我们不能通过简单地使用大型联合的源数据而使在目标域上达到好的性能。

表7 通过微调在不同源域上预训练的Inception-v3 299在7 FGVC数据集上的迁移学习性能。每一行代表在特定的源域上预训练的网络,每一列表示在目标细粒度数据集上通过微调不同的网络的top-1图像分类准确率。每个fgvc数据集的相对良好和较差的性能分别用绿色和红色标记。基于域相似性的两个子集在所有fgvc数据集上都取得了良好的性能。
我们在图5进一步展示了迁移学习性能和我们提出的域相似度的关系。我们发现当从更相似的源域中微调时,迁移学习的性能更好,除了在Food101上,当源域相似度改变时,迁移学习的性能依然一样。我们相信这是因为在Food101上训练的图片数量太多(每个类别750张训练图片)。因此,目标域包含足够的数据,因此迁移学习几乎没有帮助。在这种情况下,我们忽略域规模的假设不再有效。

图5. 源域和目标域之间迁移学习性能与域相似性的关系。每一条线代表目标FGVC数据集,每一个标记代表源域。通过在更相似的源域上微调预训练的网络,可以达到更好的迁移学习效果。基于我们的域相似度挑选的两个子集在所有FGVC数据集上达到了良好的性能。
从表7和图5我们能观察到,在所有FGVC数据集上,B子集达到了很好的性能,在CUB200和NABirds上大大超过了ImageNet的预训练。在表8,我们将我们的方法和现存的FGVC方法进行了比较。结果表明,所提出的迁移学习方法在常用的fgvc数据集上具有最先进的性能。请注意,由于我们对域相似性的定义是快速计算的,因此我们可以轻松探索选择源域的不同方法。迁移学习性能可以直接根据域相似性进行评估,而无需进行任何预训练和微调。在我们的工作之前,在FGVC任务上为了达到好的性能的唯一选择是在ImageNet上微调设计更好的模型或者通过收集更多的图片数据增强。然而,我们的工作提供了一个新的方向,即使用更相似的源域对网络进行预训练。我们表明,在源域中选择适当的子集,能够通过简单地微调现成网络的优化匹配或超过这些性能增益。

表8.和现在最先进的FGVC方法相比。作为惯例,我们使用相同的448 × 448输入大小。由于我们还没找到最近提出的应用于Flowers-102和NABirds的FGVC方法,我们只对5个数据集的其余部分进行比较。我们提出的迁移学习方法在所有FGVC数据集上都能达到顶级的性能,特别是在CUB200和NABirds上。
6 结论
在这个工作中,我们提出了一个训练方案,通过使用高分辨率的输入图像和微调来处理长尾分布,从而在大规模iNaturalist数据集上获得最佳性能。我们进一步提出了一个新颖的方法即通过搬土距离来捕捉域相似度,然后在更相似的域上进行微调使迁移学习达到更好的效果。在未来,我们计划研究除了域相似度外,迁移学习其它重要的因素。
致谢。这项工作部分得到了谷歌重点研究奖的支持。我们要感谢谷歌的同事们提供的有益的讨论。