Python面试系列之--时间复杂度与O(1), O(n), O(logn), O(nlogn) 的区别
时间复杂度常用[大O符号]
在计算机科学中,时间复杂性,又称时间复杂度,算法的时间复杂度是一个函数,它定性描述该算法的运行时间。这是一个代表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和首项系数。使用这种方式时,时间复杂度可被称为是渐近的,亦即考察输入值大小趋近无穷时的情况。
-
中文名
时间复杂性
-
外文名
time complexity
-
简 介
不同算法解决
-
算法复杂度
时间复杂度和空间复杂度
目录
- 简介
- 算法复杂度
- 常数时间
- 对数时间
- 幂对数时间
- 次线性时间
- 线性时间
- 线性对数时间
- 多项式时间
- 超越多项式时间
- 准多项式时间
- 次指数时间
- 第一定义
- 第二定义
- 指数时间
- 双重指数时间
简介
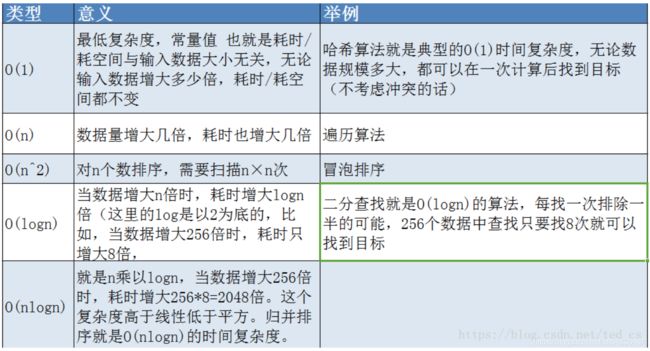
为了计算时间复杂度,我们通常会估计算法的操作单元数量,每个单元运行的时间都是相同的。因此,总运行时间和算法的操作单元数量最多相差一个常量系数。
相同大小的不同输入值仍可能造成算法的运行时间不同,因此我们通常使用算法的最坏情况复杂度,记为T*(*n*),定义为任何大小的输入n所需的最大运行时间。另一种较少使用的方法是平均情况复杂度,通常有特别指定才会使用。时间复杂度可以用函数T*(n) 的自然特性加以分类,举例来说,有着T(n) =O(n) 的算法被称作“线性时间算法”;而T(n) =O(M^n) 和M= O(T(n)) ,其中M≥n> 1 的算法被称作“指数时间算法”。
一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f (n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为O(n2)。
时间频度
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。 [1]
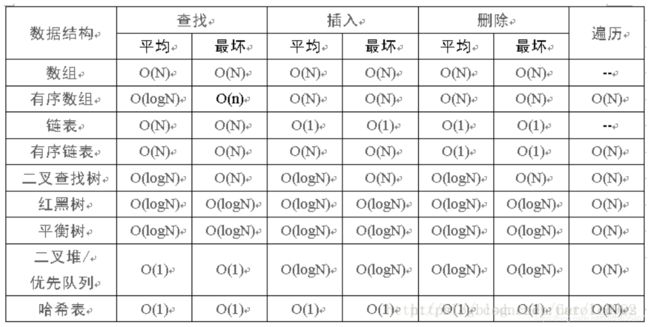
算法复杂度
算法复杂度分为时间复杂度和空间复杂度。其作用: 时间复杂度是指执行算法所需要的计算工作量;而空间复杂度是指执行这个算法所需要的内存空间。(算法的复杂性体运行该算法时的计算机所需资源的多少上,计算机资源最重要的是时间和空间(即寄存器)资源,因此复杂度分为时间和空间复杂度。)
常数时间
若对于一个算法,
的上界与输入大小无关,则称其具有常数时间,记作
时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称
时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
虽然被称为“常数时间”,运行时间本身并不必须与问题规模无关,但它的上界必须是与问题规模无关的确定值。举例,“如果a > b则交换a、b的值”这项操作,尽管具体时间会取决于条件“a > b”是否满足,但它依然是常数时间,因为存在一个常量t使得所需时间总不超过t。
以下是一个常数时间的代码片段:
int` `index = 5;``int` `item = list[index];``if` `(condition ``true``) then`` ``perform some operation that runs in constant ``time``else`` ``perform some other operation that runs in constant ``time``for` `i = 1 to 100`` ``for` `j = 1 to 200`` ``perform some operation that runs in constant ``time
如果
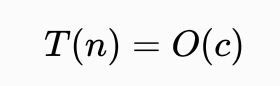
,其中
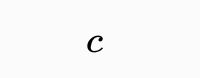
是一个常数,这记法等价于标准记法
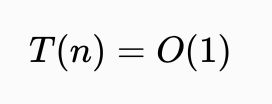
对数时间
若算法的T(n) =O(log*n*),则称其具有对数时间。由于计算机使用二进制的记数系统,对数常常以2为底(即log2n,有时写作lgn)。然而,由对数的换底公式,logan和logbn只有一个常数因子不同,这个因子在大O记法中被丢弃。因此记作O(logn),而不论对数的底是多少,是对数时间算法的标准记法。
常见的具有对数时间的算法有二叉树的相关操作和二分搜索。
对数时间的算法是非常有效的,因为每增加一个输入,其所需要的额外计算时间会变小。
递归地将字符串砍半并且输出是这个类别函数的一个简单例子。它需要O(log n)的时间因为每次输出之前我们都将字符串砍半。 这意味着,如果我们想增加输出的次数,我们需要将字符串长度加倍。
// 递归输出一个字符串的右半部分``var ``right` `= function(str)``{`` ``var length = str.length;`` ` ` ``// 辅助函数`` ``var help = function(index)`` ``{`` ` ` ``// 递归情况:输出右半部分`` ``if(index < length){`` ` ` ``// 输出从index到数组末尾的部分`` ``console.``log``(str.substring(index, length));`` ` ` ``// 递归调用:调用辅助函数,将右半部分作为参数传入`` ``help(Math.ceil((length + index)/2));`` ``}`` ` ` ``// 基本情况:什么也不做`` ``}`` ``help(0);``}
幂对数时间
对于某个常数k,若算法的T(n) = O((logn)),则称其具有幂对数时间。例如,矩阵链排序可以通过一个PRAM模型.被在幂对数时间内解决。
次线性时间
对于一个算法,若其匹配T(n) = o(n),则其时间复杂度为次线性时间(sub-linear time或sublinear time)。实际上除了匹配以上定义的算法,其他一些算法也拥有次线性时间的时间复杂度。例如有O(n)葛罗佛搜索算法。
常见的非合次线性时间算法都采用了诸如平行处理(就像NC1matrix行列式计算那样)、非古典处理(如同葛罗佛搜索那样),又或者选择性地对有保证的输入结构作出假设(如幂对数时间的二分搜索)。不过,一些情况,例如在头 log(n) 比特中每个字符串有一个比特作为索引的字符串组就可能依赖于输入的每个比特,但又匹配次线性时间的条件。
“次线性时间算法”通常指那些不匹配前一段的描述的算法。它们通常运行于传统计算机架构系列并且不容许任何对输入的事先假设。但是它们可以是随机化算法,而且必须是真随机算法除了特殊情况。 [2]
线性时间
如果一个算法的时间复杂度为O(n),则称这个算法具有线性时间,或**O(*n*)**时间。非正式地说,这意味着对于足够大的输入,运行时间增加的大小与输入成线性关系。例如,一个计算列表所有元素的和的程序,需要的时间与列表的长度成正比。这个描述是稍微不准确的,因为运行时间可能显著偏离一个精确的比例,尤其是对于较小的n。
线性对数时间
若一个算法时间复杂度T(n) = O(nlog n),则称这个算法具有线性对数时间。因此,从其表达式我们也可以看到,线性对数时间增长得比线性时间要快,但是对于任何含有n,且n的幂指数大于1的多项式时间来说,线性对数时间却增长得慢。
多项式时间
复杂度类
从多项式时间的概念出发,在计算复杂度理论中可以得到一些复杂度类。以下是一些重要的例子。
- P:包含可以使用确定型图灵机在多项式时间内解决的决定性问题。
- NP:包含可以使用非确定型图灵机在多项式时间内解决的决定性问题。
- ZPP:包含可以使用概率图灵机在多项式时间内零错误解决的决定性问题。
- RP:包含可以使用概率图灵机在多项式时间内解决的决定性问题,但它给出的两种答案中(是或否)只有一种答案是一定正确的,另一种则有几率不正确。
- BPP:包含可以使用概率图灵机在多项式时间内解决的决定性问题,它给出的答案有错误的概率在某个小于0.5的常数之内。
- BQP:包含可以使用量子图灵机在多项式时间内解决的决定性问题,它给出的答案有错误的概率在某个小于0.5的常数之内。
在机器模型可变的情况下,P在确定性机器上是最小的时间复杂度类。例如,将单带图灵机换成多带图灵机可以使算法运行速度以二次阶提升,但所有具有多项式时间的算法依然会以多项式时间运行。一种特定的抽象机器会有自己特定的复杂度类分类。
超越多项式时间
如果一个算法的时间T(n) 没有任何多项式上界,则称这个算法具有超越多项式(superpolynomial)时间。在这种情况下,对于所有常量c我们都有T(n) = ω(n),其中n是输入参数,通常是输入的数据量(比特数)。指数时间显然属于超越多项式时间,但是有些算法仅仅是很弱的超越多项式算法。例如,Adleman-Pomerance-Rumely 质数测试对于n比特的输入需要运行n时间;对于足够大的n,这时间比任何多项式都快;但是输入要大得不切实际,时间才能真正超过低级的多项式。
准多项式时间
准多项式时间算法是运算慢于多项式时间的算法,但不会像指数时间那么慢。对一些固定的
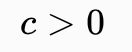
,准多项式时间算法的最坏情况运行时间是
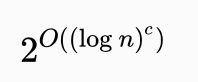
。如果准多项式时间算法定义中的常量“c”等于1,则得到多项式时间算法;如果小于1,则得到一个次线性时间算法。
次指数时间
术语次指数时间用于表示某些算法的运算时间可能比任何多项式增长得快,但仍明显小于指数。在这种状况下,具有次指数时间算法的问题比那些仅具有指数算法的问题更容易处理。“次指数”的确切定义并没有得到普遍的认同,我们列出了以下两个最广泛使用的。
第一定义
如果一个问题解决的运算时间的对数值比任何多项式增长得慢,则可以称其为次指数时间。更准确地说,如果对于每个 ε> 0,存在一个能于时间 O(2) 内解决问题的算法,则该问题为次指数时间。所有这些问题的集合是复杂性SUBEXP,可以按照DTIME的方式定义如下。

第二定义
一些作者将次指数时间定义为 2的运算时间。该定义允许比次指数时间的第一个定义更多的运算时间。这种次指数时间算法的一个例子,是用于整数因式分解的最著名古典算法——普通数域筛选法,其运算时间约为
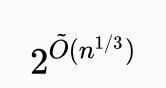
,其中输入的长度为n。另一个例子是图形同构问题的最著名算法,其运算时间为
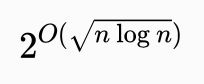
指数时间
若T(n) 是以 2为上界,其中 poly(n) 是n的多项式,则算法被称为指数时间。更正规的讲法是:若T(n) 对某些常量k是由 O(2) 所界定,则算法被称为指数时间。在确定性图灵机上认定为指数时间算法的问题,形成称为**EXP**的复杂性级别。

有时侯,指数时间用来指称具有T(n) = 2的算法,其中指数最多为n的线性函数。这引起复杂性档次**E**。

双重指数时间
若T(n) 是以 2为上界,其中 poly(n) 是n的多项式,则算法被称为双重指数时间。这种算法属于复杂性档次2-EXPTIME。
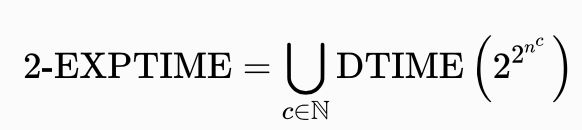
众所周知的双重指数时间算法包括:
- 预膨胀算术的决策程序
- 计算葛洛拿基底(在最差状况)
- 实封闭体的量词消去至少耗费双重指数时间,而且可以在这样的时间内完成。