信息论 Information Theory 自学心得
在 tensrflow 的学习教程中肯定就会谈到,如何设置误差函数,最常见的就是交叉熵,文档中给了一篇学习资料,讲了交叉熵设计的学科——信息论,看了英文文档后有所感悟,特此记录。
前半部分我还是习惯概述所学习的文章的内容,后半部分才是自己的总结,如果有幸有其他的同学看到我的文章,若发现有什么不对的地方希望可以评论一起探讨一下。文档的地址是http://colah.github.io/posts/2015-09-Visual-Information/。
首先就是概率论的东西,主要是条件概率,事件之间的独立性。
第二点谈到了一个例子,例如我们日常讨论的对象有四个,苹果 apple,香蕉 banana,猫 cat,狗 dog。在暂不考虑其他更多对象的时候,我们可以用一些更简洁的内容或者说符号来描述上述四个对象,也就是编码 encode,用简单的二进制来指代我们的苹果香蕉猫狗(CSDN的表格一直都不会用真的是菜耶我......)。
我们用 00 指代苹果,01 指代香蕉,10 指代猫,11 指代狗子。在日常的对话中,我们假设一个情境,用代码传递需要什么对象的陪伴,无论是食物还是生物,都足以慰藉我们。如果我们对于这四个对象的偏好是一样的,即我们需要他们的概率是一样的,那么平均下来我们在传递信息时每个对象需要占一个两字节的编码。可能有人会说,那为什么不可以用 0 来指代苹果然后 1 来指代香蕉,10 指代猫,11 指代狗,这样子可以让传递每个信息所需要的平均字节更少。但需要考虑到,我们在传递信息的时候是连续的 0 和 1 的组合,如果你允许有单个字节所能指代的对象出现,那么当你读的二进制信息是 10 的时候就无法区分它的含义是 香蕉 + 苹果 还是猫。
如果我们对这四个对象的偏好不一,他们被需要表达的次数即出现的概率有高有低,具体而言,我们很需要苹果,有50%的概率,香蕉同为食物就是25%,喵星人和汪星人各占12.5%,我们能不能让苹果这个出现概率比较高的对象用 1 位的二进制码 0 表示呢,以企图减少平均字节数。那么同时根据上面歧义的说法,自然就不能用 1 来表示出现概率次高的香蕉 banana,甚至接下来的三个都不能用 0 开头了,因为此时在传递的信息中若是开头为 0 会出现歧义。那么用 1 开头,11 来代表可以吗?假设可以,那么10 代表喵星人,111 代表汪星人,如果编码后的内容开头出现 1110 就会出现 111 + 0 以及 11 + 10 两种解释,自然就不行了。此时可以隐约意识到一点,就是编码解析的过程一旦错误后面就发生连锁反应全部解析错误,也在提醒我们可能要考虑如何添加预防措施。那么用 10 来代表香蕉,110 代表喵星人,111 代表汪星人,就不会出现有歧义的情况。从另一个角度讲,一个象征某物的编码后的代码,它的前缀,不会是这个编码系统中其他的代码,否则我们在解码的时候就会出现问题。例如看最长的三个字节的猫 110,第一位是 1 没有含义,前两位 11也没有含义,更长的代码以此类推,这个性质在固定长度的编码方式中也是存在的,我们称之为 prefix property 前缀性质。此时我们计算传递一个对象所需要的平均字节 0.5*1+0.25*2+0.125*3*2 =1.75 位,可以看到有所减少了。
从上一段中我们可以看出,对于可变长度的编码方式,就是我们不用将每个对象都编码成相同长度的代码,例如最高长度为 3 时,在不引起歧义的前提下,同时也希望可以尽量少地节省编码时的传递一个对象的平均字节数,是可以包含四个不同对象的,而不是 2 的立方 8 个。那么最高长度为 2,就是 0 和 1,跟最高长度是 1 没有区别。是什么在确定不同的最大长度时我们所能编码的对象数呢?
首先我们知道,在定义一个代码为某个具体事物的抽象象征时,为了防止出现歧义,我们是需要否定掉一些可能的代码空间的,这是需要付出的代价。否则,贪心然后把所有的代码都赋予含义只会在解读的时候遇到困难。所需要付出的代价与我们定义代码的长度有关,例如我们想拥有一个长度为 0 的代码来代表某物,长度为 0 意味着我们不能够拥有任何一个代码段;若长度为 1,例如用 0 来代表苹果,后面就不能再赋予含义给以 0 作为前缀的代码;若长度为 2 个单位,10 代表香蕉,我们就不能赋予含义给更多的以 10 作为前缀 prefix 的代码。虽然这样子说有点过于局限,失去了可能的以 10 作为前缀的编码空间,转化成百分数就是每想要得到一个单位的代码时就要付出 25% 的可能编码空间作为代价。也就是,当我们编码的长度为 N 时,严格来说,是约定某个长度为 N 的代码段是有含义时,每个单位长度的代码所需要付出的代价——潜在编码空间——为 ![]() 。
。
在有了编码时的损失函数之后,我们来想一下另外一个优劣的参考指标:
平均编码长度 =  代码出现频率 * 代码长度
代码出现频率 * 代码长度
大致就得到了我们的编码思路,把出现频率高的事物用短的代码,出现频率低的事物用长的代码,这样子可以得到较小的平均编码长度,节省我们在传输信息时消耗的资源。很自然的,可以联想到如果把这块完整的编码空间当成 1,按照出现概率就可以刚好把这块空间等比例地进行分配,例如 50%出现概率的就分配为长度为 1,25%出现概率的就分配为长度为 2,以此类推。对于更复杂的不可以经过以 2 为底的对数计算得到整数的一些百分数,我们也暂时用忽略我们允许的编码长度必须是整数的这个条件,先从理论上分析为什么要按比例分配呢。
以最简单的两个事物为例,分别称之为 A 和 B,发生的概率为 P(A) 和 P(B)。我们考虑分配长度给它们,假设说长度不用是整数,可以是小数;然后损失的比例跟长度的关系上面也求了。文档中让我看不明白的就是他在此处的说明,突然就说按比例是最优的了,其实后续也有证明说的确是个最优比例,但是假设之后再来验证还是感觉有点不太好,而且用的一个比较的指标是代码的出现频率与所赋予长度对应的损失比率的比值,似乎没有太明确的意义呢。具体的说法就是,我们可以假定以损失函数的值与代码出现频率相同时的那个长度作为我们选定的长度,就你以此作为基准来选长度,自然就会满足以出现频率和损失比率比值为 1 的最优情况了。
花了一个晚上看文档里面的内容,觉得不能让自己满意,还是想自己证明一下。
假设已知的两个事物的使用概率分别为 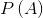 ,
,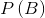 ,选择的长度为
,选择的长度为 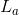 和
和 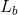 ,对应的损失比率为
,对应的损失比率为 ![]() 和
和 ![]() ,而平均代码长度为
,而平均代码长度为 ![]() ;以相同的概念可以引进平均损失比率的概念,数值为
;以相同的概念可以引进平均损失比率的概念,数值为 ![]() 。可以看到,我们希望上述两个平均数都尽量小,但是它们之间是冲突的,一个变小另一个就会变大。另外有个问题,就是这两个长度之间有没有约束关系呢?如果可以知晓该约束关系就可以解出最优解了。仔细想,如果这两个指标对我们的参考权重是相同的,我们选择长度时考虑因为概率的影响吧,毕竟考虑的自变量也就只有一个即两个出现概率;进而我们可以确定,A 和 B 用的是相同的一个映射函数来寻找最优的长度,而显然的当 50% 的出现概率时就二者都是一位数,长度为 1 是最优的考虑,也就是
。可以看到,我们希望上述两个平均数都尽量小,但是它们之间是冲突的,一个变小另一个就会变大。另外有个问题,就是这两个长度之间有没有约束关系呢?如果可以知晓该约束关系就可以解出最优解了。仔细想,如果这两个指标对我们的参考权重是相同的,我们选择长度时考虑因为概率的影响吧,毕竟考虑的自变量也就只有一个即两个出现概率;进而我们可以确定,A 和 B 用的是相同的一个映射函数来寻找最优的长度,而显然的当 50% 的出现概率时就二者都是一位数,长度为 1 是最优的考虑,也就是 ![]() ,一个合适的函数就是以 2 为底的对数函数(不过还是觉得很苍白的说明)。
,一个合适的函数就是以 2 为底的对数函数(不过还是觉得很苍白的说明)。
又仔细看了文档中的图片,有点想法。如果我们平等的看代当我们选择某个长度的代码来使用时,这个选择对于总的平均代码长度的贡献即为代码的长度与出现频率的乘积:
![]()
每当 有一个细微的变化 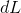 时,变化量为
时,变化量为 ![]() 。而我们的损失比率在细微的变化下对应的变化量也是可以近似看成一个矩形,即
。而我们的损失比率在细微的变化下对应的变化量也是可以近似看成一个矩形,即 ![]() ,负号表示当 增大时损失比率是减小的。当二者的系数相同时,就是处于一个极值点,这里就是很经典的极值点的定义的应用了。那么所以!我们就可以让我们的损失比率对应我们的出现概率,就可以求出长度,这就是最优的选择了!
,负号表示当 增大时损失比率是减小的。当二者的系数相同时,就是处于一个极值点,这里就是很经典的极值点的定义的应用了。那么所以!我们就可以让我们的损失比率对应我们的出现概率,就可以求出长度,这就是最优的选择了!
综上所述,已经可以比较严谨的证明了选取的代码长度和概率之间的关系是可靠的。那么有了计算公式,我们就可以计算,在已知的概率分布情况下,最小的平均代码长度:
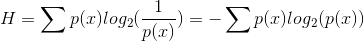
上述的 H 称之为概率 p 的熵 entropy。他所代表的是由于不确定性所以在弄清楚的过程中所需要付出的代价,如果一个件事情我们已知结果,就没有必要进行信息交互来了解真相;如果一件事未知,那么就意味着有概率分布,那么就有对应的可计算的信息熵。另外 H 也有一个是极小值的性质,所以 H,也可以理解成一件未知但有确定概率分布的事情的复杂程度。
回到之前那个实际例子,就是用编码来替代四个具体对象:猫,狗,苹果和香蕉。我们在使用频率为,苹果 50%,香蕉 25%,猫猫狗狗各 12.5% 的情况下,选择了最优的编码就是用 0 来代替苹果,10 代替香蕉,然后 110 和 111 分别代表猫和狗。那么如果我们现在换了一个人来使用这套代码,他的使用频率与原有的使用者不一致,他的使用频率是 50% 猫,25% 狗,剩下的苹果和香蕉就各占了 12.5%。那么这种情况下他的平均编码长度,是 3 * 0.5 + 3 * 0.25 + 0.125 * 2 + 0.125 * 1 = 2.625,远远大于最优的 1.75 甚至大于固定长度的编码方式。究其原因就是因为各个优化的编码长度并不是针对这个新的使用者的使用习惯来优化的,所以我们可以从这个失误中看出,这种某个使用概率与另一个概率对应的最优编码长度之间的乘积和,可以用来表示两个概率之间的差距大小。我们称之为 cross entropy 交叉熵:
![]()
但是要注意到,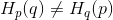 ,不具有对易性。所以更详细的说法,因为一方加了对数运算变得对这个乘积和的影响更小了一些,应该说是企图让新的概率分布
,不具有对易性。所以更详细的说法,因为一方加了对数运算变得对这个乘积和的影响更小了一些,应该说是企图让新的概率分布 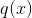 去匹配原本
去匹配原本 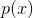 的优化方案,终于呼应到了我们在深度学习中谈到的为什么要使用交叉熵来作为损失函数的原因了,因为原本我们就是想要用我们计算出来的模型来推算客观存在但暂不知晓的概率分布,所以我们拥有的数据集是 ,推算出来的模型是 。
的优化方案,终于呼应到了我们在深度学习中谈到的为什么要使用交叉熵来作为损失函数的原因了,因为原本我们就是想要用我们计算出来的模型来推算客观存在但暂不知晓的概率分布,所以我们拥有的数据集是 ,推算出来的模型是 。
剩下的文档还有一小部分,但想及已经偏离主线比较久了,原本想着一个晚上就可以把文章总结完,没想到花了两天的时间。接下来还要继续 Machine Learning 的学习,但有空再来把这篇文章的坑填了。