TSM: Temporal Shift Module for Efficient Video Understanding
行为识别:TSM: Temporal Shift Module for Efficient Video Understanding 论文笔记
abstract:
TSM (Temporal Shift Module) shifts part of the channels along the temporal dimension,从而促进相邻帧之间的信息交换
introduction:
视频识别和图像识别的最大差异:temporal modeling
动机:时间信息在行为识别中重要。但当前 1)3D cnn对时空信息联合建模,在 edge devices部署模型 expensive; 2)双流网络,在low-level抽取时间特征 expensive;由此我们提出一个新的角度,Temporal Shift Module (TSM),shifts part of the channels along the temporal dimension,从而促进相邻帧之间的信息交换
视频标示为:N*C*T*H*W,传统2dcnn 在时间尺度T上独立运行,没有对时序建模。而TSM在时间维度上shift the channel,both forward and backward。
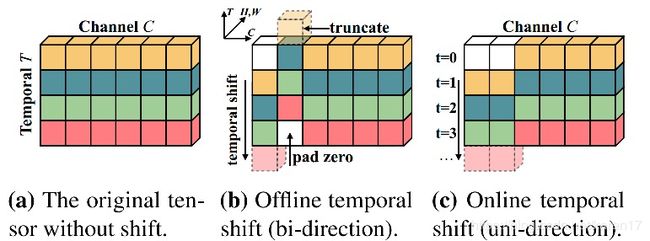
如上图(b)所示,周围frames的信息在时间维度shift之后会和当前frame特征混合。
我们在时间维度,shift ±1,并fold the multiply-accumulate from time dimension to channel dimension(将乘积和累加从时间维度累加到channel维度)
目前在image 中使用的shift strategy 有两个问题:1)虽然shift操作带来的计算cost非常小,但additional cost of data movement is non-negligible 2)不准确,shift too many channels带来性能下降。所以我们:1)采取temporal partial shift strategy(部分时间维度偏移策略),只shift一小部分channel,有效减少了data movement cost。 2)将Temporal Shift Module 引入residual branch(残差部分),保留当前帧的普通activation。
temporal shift module
主要探究两个问题:1)shift多大比例的channel维度 2)shift in place还是将其添加到resnet分支中。
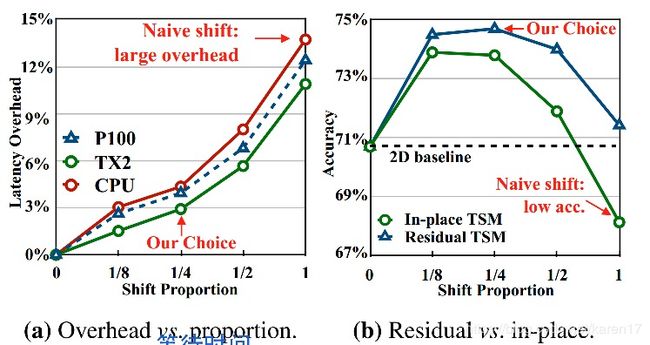
问题 1) moudle design:backbone:resnet50,8 frame input(no shift,2d baseline),partial shift( 1/8, 1/4,1/2) and all shift,计算运行时间。
问题 2)shift in place 或是TSM放在residual block 中的残差分支,结构如下图所示:
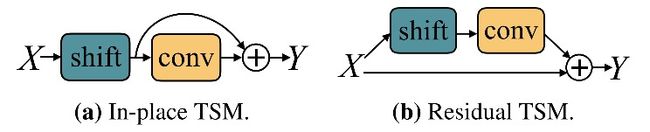
shift选取比例和in-place&residual 在kinetics上结果:最终实验选取比例为1/4并选择residual shift
experiment
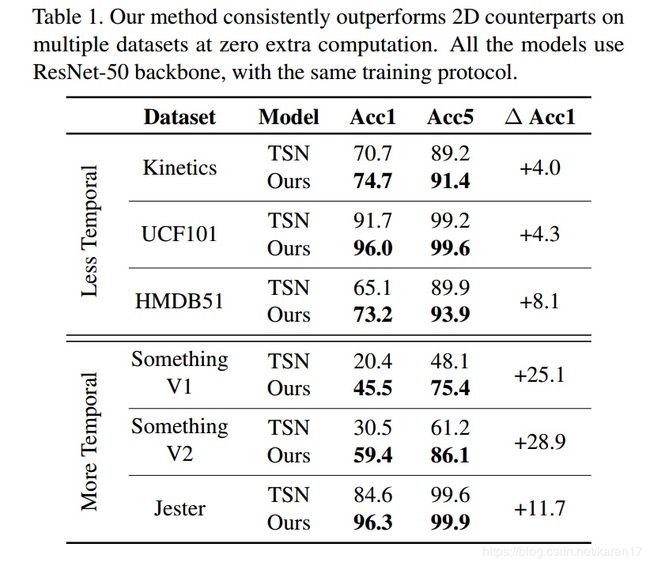
训练:先在kinetiecs上预训练,再fine-tuned到其他大型数据集上,Something-Something, UCF101 and HMDB51.
RGB部分结果,选取TSN 作为2d CNN的baseline
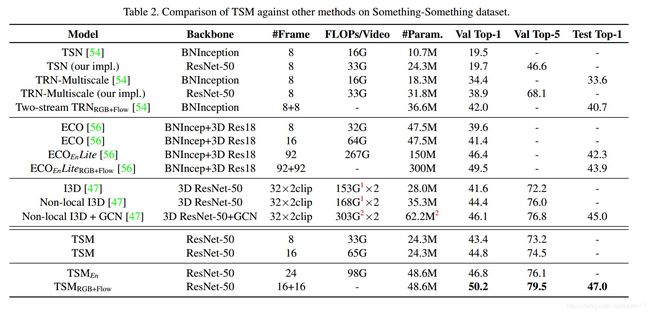
在Something-Something(双流)上与当前state-of-the-art比较
个人总结:
1)看过代码发现TSM的实现还比较简单,基于基本框架resnet-50, 对每个block的conv1中的特征进行temperol shift操作。只改动1/4的channel维度(在前0:1/8的channel维度进行时间维度后移,1/8:1/4的channel维度进行时间维度前移),所以原始特征很大程度保留了。
# shape of x: [N, T, C, H, W]
out = torch.zeros_like(x)
fold = c // fold_div
out[:, :-1, :fold] = x[:, 1:, :fold] # shift left
out[:, 1:, fold: 2 * fold] = x[:, :-1, fold: 2 * fold] # shift right
out[:, :, 2 * fold:] = x[:, :, 2 * fold:] # not shift
return out2)但作者只在kinetics对比了shift带来的效果,其他几个数据集并未贴出实验结果。感觉很难说明是TSM本身带来了性能的提升,还是kinetics预训练参数选取的好。