PyTorch分布式训练简明教程
AI编辑:我是小将
神经网络训练加速的最简单方法是使用GPU,对弈神经网络中常规操作(矩阵乘法和加法)GPU运算速度要倍超于CPU。随着模型或数据集越来越大,一个GPU很快就会变得不足。例如,BERT和GPT-2等大型语言模型是在数百个GPU上训练的。对于多GPU训练,需要一种在不同GPU之间对模型和数据进行切分和调度的方法。
PyTorch是非常流行的深度学习框架,它在主流框架中对于灵活性和易用性的平衡最好。Pytorch有两种方法可以在多个GPU上切分模型和数据:nn.DataParallel和nn.distributedataparallel。DataParallel更易于使用(只需简单包装单GPU模型)。然而,由于它使用一个进程来计算模型权重,然后在每个批处理期间将分发到每个GPU,因此通信很快成为一个瓶颈,GPU利用率通常很低。而且,nn.DataParallel要求所有的GPU都在同一个节点上(不支持分布式),而且不能使用Apex进行混合精度训练。nn.DataParallel和nn.distributedataparallel的主要差异可以总结为以下几点(译者注):
DistributedDataParallel支持模型并行,而DataParallel并不支持,这意味如果模型太大单卡显存不足时只能使用前者;DataParallel是单进程多线程的,只用于单卡情况,而DistributedDataParallel是多进程的,适用于单机和多机情况,真正实现分布式训练;DistributedDataParallel的训练更高效,因为每个进程都是独立的Python解释器,避免GIL问题,而且通信成本低其训练速度更快,基本上DataParallel已经被弃用;必须要说明的是
DistributedDataParallel中每个进程都有独立的优化器,执行自己的更新过程,但是梯度通过通信传递到每个进程,所有执行的内容是相同的;
总的来说,Pytorch文档是相当完备和清晰的,尤其是在1.0x版本后。但是关于DistributedDataParallel的介绍却较少,主要的文档有以下三个:
Writing Distributed Applications with PyTorch:主要介绍分布式API,分布式配置,不同通信机制以及内部机制,但是说实话大部分人不太同意看懂,而且很少会直接用这些;
Getting Started with Distributed Data Parallel:简单介绍了如何使用
DistributedDataParallel,但是用例并不清晰完整;ImageNet training in PyTorch:比较完整的使用实例,但是仅有代码,缺少详细说明;(
apex也提供了一个类似的训练用例Mixed Precision ImageNet Training in PyTorch)(advanced) PyTorch 1.0 Distributed Trainer with Amazon AWS:如何在亚马逊云上进行分布式训练,但是估计很多人用不到。
这篇教程将通过一个MNISI例子讲述如何使用PyTorch的分布式训练,这里将一段段代码进行解释,而且也包括任何使用apex进行混合精度训练。
DistributedDataParallel内部机制
DistributedDataParallel通过多进程在多个GPUs间复制模型,每个GPU都由一个进程控制(当然可以让每个进程控制多个GPU,但这显然比每个进程有一个GPU要慢;也可以多个进程在一个GPU上运行)。GPU可以都在同一个节点上,也可以分布在多个节点上。每个进程都执行相同的任务,并且每个进程都与所有其他进程通信。进程或者说GPU之间只传递梯度,这样网络通信就不再是瓶颈。
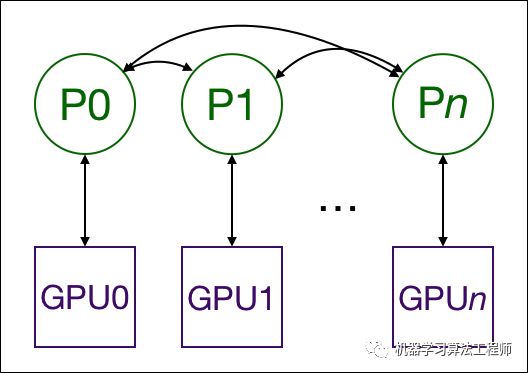
在训练过程中,每个进程从磁盘加载batch数据,并将它们传递到其GPU。每一个GPU都有自己的前向过程,然后梯度在各个GPUs间进行All-Reduce。每一层的梯度不依赖于前一层,所以梯度的All-Reduce和后向过程同时计算,以进一步缓解网络瓶颈。在后向过程的最后,每个节点都得到了平均梯度,这样模型参数保持同步。
这都要求多个进程(可能在多个节点上)同步并通信。Pytorch通过distributed.init_process_group函数来实现这一点。他需要知道进程0位置以便所有进程都可以同步,以及预期的进程总数。每个进程都需要知道进程总数及其在进程中的顺序,以及使用哪个GPU。通常将进程总数称为world_size.Pytorch提供了nn.utils.data.DistributedSampler来为各个进程切分数据,以保证训练数据不重叠。
实例讲解
这里通过一个MNIST实例来讲解,我们先将其改成分布式训练,然后增加混合精度训练。
普通单卡训练
首先,导入所需要的库:
import os
from datetime import datetime
import argparse
import torch.multiprocessing as mp
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
from apex.parallel import DistributedDataParallel as DDP
from apex import amp
然后我们定义一个简单的CNN模型处理MNIST数据:
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
主函数main()接受参数,执行训练:
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int,
help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int,
help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int, metavar='N',
help='number of total epochs to run')
args = parser.parse_args()
train(0, args)
其中训练部分主函数为:
def train(gpu, args):
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0,
pin_memory=True)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0 and gpu == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(
epoch + 1,
args.epochs,
i + 1,
total_step,
loss.item())
)
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
通过启动主函数来开始训练:
if __name__ == '__main__':
main()
你可能注意到有些参数是多余的,但是对后面的分布式训练是有用的。我们通过执行以下语句就可以在单机单卡上训练:
python src/mnist.py -n 1 -g 1 -nr 0
分布式训练
使用多进程进行分布式训练,我们需要为每个GPU启动一个进程。每个进程需要知道自己运行在哪个GPU上,以及自身在所有进程中的序号。对于多节点,我们需要在每个节点启动脚本。
首先,我们要配置基本的参数:
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1,
type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int,
help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int,
help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int,
metavar='N',
help='number of total epochs to run')
args = parser.parse_args()
#########################################################
args.world_size = args.gpus * args.nodes #
os.environ['MASTER_ADDR'] = '10.57.23.164' #
os.environ['MASTER_PORT'] = '8888' #
mp.spawn(train, nprocs=args.gpus, args=(args,)) #
#########################################################
其中args.nodes是节点总数,而args.gpus是每个节点的GPU总数(每个节点GPU数是一样的),而args.nr 是当前节点在所有节点的序号。节点总数乘以每个节点的GPU数可以得到world_size,也即进程总数。所有的进程需要知道进程0的IP地址以及端口,这样所有进程可以在开始时同步,一般情况下称进程0是master进程,比如我们会在进程0中打印信息或者保存模型。PyTorch提供了mp.spawn来在一个节点启动该节点所有进程,每个进程运行train(i, args),其中i从0到args.gpus - 1。
同样,我们要修改训练函数:
def train(gpu, args):
############################################################
rank = args.nr * args.gpus + gpu
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=args.world_size,
rank=rank
)
############################################################
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
###############################################################
# Wrap the model
model = nn.parallel.DistributedDataParallel(model,
device_ids=[gpu])
###############################################################
# Data loading code
train_dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=transforms.ToTensor(),
download=True
)
################################################################
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=args.world_size,
rank=rank
)
################################################################
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
##############################
shuffle=False, #
##############################
num_workers=0,
pin_memory=True,
#############################
sampler=train_sampler) #
#############################
...
这里我们首先计算出当前进程序号:rank = args.nr * args.gpus + gpu,然后就是通过dist.init_process_group初始化分布式环境,其中backend参数指定通信后端,包括mpi, gloo, nccl,这里选择nccl,这是Nvidia提供的官方多卡通信框架,相对比较高效。mpi也是高性能计算常用的通信协议,不过你需要自己安装MPI实现框架,比如OpenMPI。gloo倒是内置通信后端,但是不够高效。init_method指的是如何初始化,以完成刚开始的进程同步;这里我们设置的是env://,指的是环境变量初始化方式,需要在环境变量中配置4个参数:MASTER_PORT,MASTER_ADDR,WORLD_SIZE,RANK,前面两个参数我们已经配置,后面两个参数也可以通过dist.init_process_group函数中world_size和rank参数配置。其它的初始化方式还包括共享文件系统以及TCP,比如init_method='tcp://10.1.1.20:23456',其实也是要提供master的IP地址和端口。注意这个调用是阻塞的,必须等待所有进程来同步,如果任何一个进程出错,就会失败。
对于模型侧,我们只需要用DistributedDataParallel包装一下原来的model即可,在背后它会支持梯度的All-Reduce操作。对于数据侧,我们nn.utils.data.DistributedSampler来给各个进程切分数据,只需要在dataloader中使用这个sampler就好,值得注意的一点是你要训练循环过程的每个epoch开始时调用train_sampler.set_epoch(epoch),(主要是为了保证每个epoch的划分是不同的)其它的训练代码都保持不变。
最后就可以执行代码了,比如我们是4节点,每个节点是8卡,那么需要在4个节点分别执行:
python src/mnist-distributed.py -n 4 -g 8 -nr i
要注意的是,此时的有效batch_size其实是batch_size_per_gpu * world_size,对于有BN的模型还可以采用同步BN获取更好的效果:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
上述讲述的是分布式训练过程,其实同样适用于评估或者测试过程,比如我们把数据划分到不同的进程中进行预测,这样可以加速预测过程。实现代码和上述过程完全一样,不过我们想计算某个指标,那就需要从各个进程的统计结果进行All-Reduce,因为每个进程仅是计算的部分数据的内容。比如我们要计算分类准确度,我们可以统计每个进程的数据总数total和分类正确的数量count,然后进行聚合。这里要提的一点,当用dist.init_process_group初始化分布式环境时,其实就是建立一个默认的分布式进程组(distributed process group),这个group同时会初始化Pytorch的torch.distributed包。这样我们可以直接用torch.distributed的API就可以进行分布式基本操作了,下面是具体实现:
# define tensor on GPU, count and total is the result at each GPU
t = torch.tensor([count, total], dtype=torch.float64, device='cuda')
dist.barrier() # synchronizes all processes
dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result.
t = t.tolist()
all_count = int(t[0])
all_total = int(t[1])
acc = all_count / all_total
混合精度训练(采用apex)
混合精度训练(混合FP32和FP16训练)可以适用更大的batch_size,而且可以利用NVIDIA Tensor Cores加速计算。采用NVIDIA的apex进行混合精度训练非常简单,只需要修改部分代码:
rank = args.nr * args.gpus + gpu
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=args.world_size,
rank=rank)
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Wrap the model
##############################################################
model, optimizer = amp.initialize(model, optimizer,
opt_level='O2')
model = DDP(model)
##############################################################
# Data loading code
...
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
##############################################################
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
##############################################################
optimizer.step()
...
其实就两处变化,首先是采用amp.initialize来包装model和optimizer以支持混合精度训练,其中opt_level指的是优化级别,如果为O0或者O3不是真正的混合精度,但是可以用来确定模型效果和速度的baseline,而O1和O2是混合精度的两种设置,可以选择某个进行混合精度训练。另外一处是在进行根据梯度更新参数前,要先通过amp.scale_loss对梯度进行scale以防止梯度下溢(underflowing)。此外,你还可以用apex.parallel.DistributedDataParallel替换nn.DistributedDataParallel。
题外话
我觉得PyTorch官方的分布式实现已经比较完善,而且性能和效果都不错,可以替代的方案是horovod,不仅支持PyTorch还支持TensorFlow和MXNet框架,实现起来也是比较容易的,速度方面应该不相上下。
参考
Distributed data parallel training in Pytorch https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html (大部分内容来自此处)
torch.distributed https://pytorch.org/docs/stable/distributed.html
AI编辑:我是小将
推荐阅读
堪比Focal Loss!解决目标检测中样本不平衡的无采样方法
超越BN和GN!谷歌提出新的归一化层:FRN
这份Kaggle Grandmaster的图像分类训练技巧,你知道多少?
TensorFlow 2.2.0-rc0,这次更新让人惊奇!
2020年,我终于决定入门GCN
另辟蹊径!斯坦福大学提出边界框回归任务新Loss:GIoU
人人必须要知道的语义分割模型:DeepLabv3+
机器学习算法工程师
一个用心的公众号