VR开发入门:3D图像的处理过程
在进行第一个VR应用开发之前,我们来看看几个重要的概念:
搭建场景:创建一个可视化、可交互、脚本驱动的虚拟现实环境。
立体渲染:用两个相机渲染场景分别表示用户的左右眼,然后通过Oculus Rift头显的透镜,这两幅图片被重合在一起,从而形成清晰且具有深度视觉的场景。
头动追踪:通过捕获Oculus Rift头显的位置和转向来改变虚拟世界中相机的位置和转向。
我们需要编写大量3D操作的代码来表现我们的想法,可以直接通过OpenGL和DirectX来渲染3D视图,但是这样做太浪费时间了,而且也超出了本书的范畴。我们unity3D游戏引擎来做这件事,Unity用于快速构建VR内容非常合适,最主要的是它非常容易掌握。
在深入研究Unity之前,我们来简单了解一下基本的3D图形技术。如果你对3D图形编程已经非常熟悉了,这部分内容可以直接跳过。
3D图形学基础定义
在继续之前,我们来看看3D图形学的定义,下面是维基百科给出的定义(摘自:http://en.wikipedia.org/wiki/3D_computer_graphics):3D computer graphics (in contrast to 2D computer graphics) are graphics that use a three-dimensional representation of geometric data (often Cartesian) that is stored in the computer for the purposes of performing calculations and rendering 2D images. Such images may be stored for viewing later or displayed in real-time.
上面的定义主要有3个部分:(1)所有的数据都以三维坐标系方式表示。(2)它们最终都会画(渲染)在一张二维图上,其中VR会分成左右眼画在两张图上。(3)图像都是实时渲染的,当一些动画或者用户操作引起了3D数据的改变,它们所渲染出来的图像会实时更新,这种更新频率必须让人眼无法察觉。以上三点中最后一点是建立可交互应用的关键。事实上,3D图形渲染技术如此重要,以至于它已经创造了几十亿美元的市场,许多大公司都在一心专注做3D实时渲染的技术,比如NVIDIA、ATI、Qualcomm等。
一、三维坐标系统
如果你熟悉二维坐标系,如Windows桌面应用或者IOS手机应用采用的坐标系,你一定知道x、y轴。二维坐标可以表示子窗体或者UI控件摆放的位置,当调用绘图API是可以定义画笔和画刷的绘制点。与二维坐标类似,三维坐标系统只是多了一个z轴,这个方向用来描述深度信息(一个物体距离屏幕的远近),如果你已经了解二维坐标系的概念,那么转换到三维坐标系就很简单了。
图3-1是本书采用的坐标系示意图,它的x轴水平,方向为左到右,y轴竖直,方向为下到上,z轴穿过屏幕,方向为里到外,并且,这三个轴都相互垂直。有些三维坐标系的z轴是竖直的,而y轴是穿过屏幕。

图3-1
unity3d采用的坐标系就是上图所示这种,只不过它的z轴方向是外向里。我们图中显示的是右手坐标系,而且Unity3D中的是左手坐标系,需要注意的是OpengGL通常也是采用的右手坐标系。
二、网格、多边形、顶点
绘制3D图形有许多方法,用的最多的是用网格绘制。一个网格由一个或多个多边形组成,这些多边形的顶点都是三维空间中的点,它们具有x、y、z三个坐标值。网格中通常采用三角形和四边形,这些基本面片可以围成网格,从而形成了模型。
图3-2中就是一个三维网格,黑色的线条就是四边形的边,这些四边形围出了一个人脸的形状。当然,这些黑色的线条在最终渲染的图形中是不可见的。网格的节点坐标仅仅表示了模型的外形,网格表面的颜色、光照用另外的属性表示,这些我们在后面会介绍。

图3-2
三、材质、贴图、光照
除了x、y、z坐标以外,网格的表面采用另外的属性表示。表面属性可以非常简单地采用单色,也可以采用复杂的方法,比如它的反光效果怎么样或者它看起来是否有光泽。网格表面还可以采用一个或多个位图,一个我们叫贴图,多个我们叫图集。贴图可以是文字效果(例如T恤上面的图案),也可以是复杂的粗糙效果或彩虹效果。大多数的图形系统会将网格的表面属性统一用材质来表示,而材质最终表现出来的效果会受环境中的光照影响。
图3-2中的模型使用的材质颜色是深紫色,表面光照效果表现的是受到了左侧的光照,这点我们可以通过右侧的阴暗部分看出来。
四、转换矩阵
模型网格的三维空间位置都是由它们的顶点坐标决定的,如果每次想要移动一下模型位置都要依次改变每个网格的顶点坐标,这将一件非常头疼的事,要是遇上需要显示动画效果那就更糟了。为了解决这个问题,大部分的三维系统都会提供转换操作,这个操作原理是整体移动网格,这样网格与世界坐标就有一个相对转换,而不需要去改变每一个顶点的坐标值。其中,转换操作包括:移动、旋转、缩放,这些操作都是针对网格整体相对世界坐标系的,而不是特定的每一个顶点。
图3-3中展示了转换操作,图中有三个立方体,每一个立方体都是由一个立方体网格组成,它们都包含相同的顶点,在我们进行移动、旋转、缩放操作的时候不需要改变这些顶点的坐标值,而是给立方体网格赋予一个转换操作。左边红色的立方体向右移动了4个单位(进行了[-4,0,0]操作),然后又相对x和y轴进行了旋转(这里注意一下,我们这里角度的单位是弧度,即一弧度等于360度除以2*PI)。右边蓝色的立方体向右移动了4个单位,然后对三个方向都放大了1.5倍,中间绿色立方体就是最初始位置。
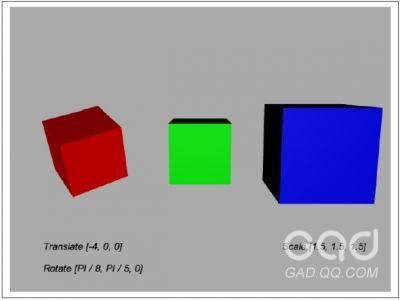
图3-3
我们用一个矩阵来代表转换操作,这个矩阵中保存着一个数组,通过这个数组进行一些数学计算就可以得到转换以后的顶点坐标值。大部分的转换矩阵用4*4的数组表示,这个数组包含4行4列一共16个数。图3-4就是一个4*4数组的示意图,其中m12、m13、m14用来操作移动,m0、m5、m10用来操作缩放,m1和m2、m4和m6、m8和m9分别用来操作相对x、y、z轴的旋转,转换矩阵乘以顶点坐标就是转换之后的坐标。
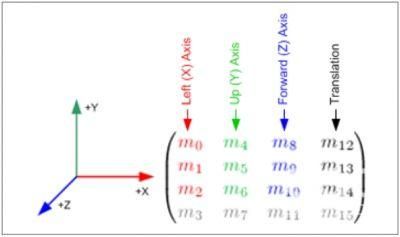
图3-4
如果你同我一样是个线性代数极客,我这么讲你肯定听得懂,如果你不熟悉线性代数也没关系,unity3D以及其它工具中已经将这些操作都封装好了,我们只需要正确调用它们的API即可,但是了解一下这些操作的底层计算过程总还是好的。
五、相机、透视图、视口、投影
渲染好的场景都需要一个可以供用户查看的视图,我们通常在3D场景中用相机来提供这种需求。相机相对场景有位置和方向,就像我们生活中的相机一样,它也提供透视图查看方式,这种方式可以有近大远小的效果。相机最终会将三维的场景渲染成一幅幅二维的图片,我们就可以通过它的视口进行观察。
相机处理计算时主要涉及到两个矩阵,第一个是线性变换矩阵(之前章节我们称为转换矩阵),它负责定义场景物体的位置和朝向,第二个是投影矩阵,它负责将三维场景物体投影到二维视口中。当然具体的细节需要太多数学理论,所以unity3D都将这些已经封装好了,我们开发人员只需要简单的“瞄准、发射”。
图3-5中描述的是相机核心概念视口和投影,在图中左下角那只大眼睛就代表我们的相机所处的位置,红色的x轴代表相机的朝向,两个蓝色的方块就是被观察的物体,绿色和红色的矩形分别代表近切面和远切面(两个切面之间的物体才可以被看见,而这之间的区域我们称为可视平截椎),近切面就是我们的视口,投影在视口上的图像就是我们真正看见的图像。
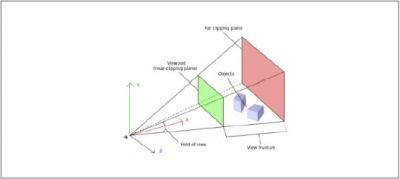
图3-5
相机非常强大,它可以让观察者非常真实地观察一个三维场景,此外,它还为动画场景提供了强大的支持,通过移动相机就可以像拍电影一样创建一个动态的叙事的场景,当然,对于VR来说需要我们不能随意移动相机,如果要移动相机我们需要多方面考量,最好做到让用户完全控制相机,这样用户会有一种身临其境的感觉。
六、立体渲染
在虚拟现实中,三维图像渲染是一个大问题,然而现在又碰到了如何处理相机这个难题,相机本身就需要处理变换矩阵和投影矩阵,可恶的是,VR中我们还需要处理两次(每 只眼睛处理一次)。不过境况并没有那么糟糕,我们有几种处理相机的方法,下面来介绍一个最简单的方法:
创建一个主相机:应用程序控制唯一一个主相机,所有的逻辑动画等等都只针对主相机,这样,我们在处理相机与其他物体交互的时候就变得简单统一,此外需要注意主相机不参与真正的渲染。主相机还有一个好处,就是可以在双立体视图和传统单一视图之间切换。
用两个相机渲染:除了主相机,VR程序需要外加两个相机,用来真正处理渲染。这两个相机需要与主相机的位置和朝向保持一致,只是有一点不同,就是它们分别要向左向右偏移一点点,用来模拟我们的瞳距。
渲染至两个视口:VR应用分别创建的左右眼的渲染相机,它们的视口宽度都是屏幕宽度的一半,高度都为屏幕高度。每个相机处理图形的时候都用了特殊的投影矩阵,这个投影矩阵可以处理反畸变问题(Oculus SDK中提供了这个算法)。
至此,我们已经简单的了解了VR的图像处理过程,这里讲的非常简单,如果要深入那么每一个点都可以用一整本书来介绍。随着你的程序变得越来越庞大,你需要处理大量的底层问题,对于这些问题最好交个游戏引擎来做,当然,你要是非常NB,你可以自己写一个引擎,但是如果你跟我一样希望集中精力做应用层的事情,那么最好还是使用一个现成的引擎。目前市面上有许多很好的引擎,其中包括下节要介绍的unity3d游戏引擎。
相关阅读:如何用Unity和Cardboard做一款VR游戏