【利用python进行数据分析】数据聚合与分组运算
在将数据集准备好了之后,通常的任务是计算分组统计或生成透视表。
pandas提供了groupby功能,可以自然地对数据集进行切片、切块和摘要。
在本章中,我们将会学到:
1根据一个或多个键(函数、数组或DataFrame列名)拆分pandas对象
2.计算分组摘要统计,如计数、平均值,标准差
3.对DataFrame的列应用各种各样的函数
4.计算透视表或交叉表
5.执行分位数分析以及其他分组分析
groupby技术——“split-apply-combine”(拆分-应用-合并)
分组键可以使用:
1.列表或数组
2.表示DataFrame某个列名的值
3.字典或Series,会与待分组轴的值进行一一对应
4.函数,用于处理轴索引或索引中的各个标签

如果按key1分组,可以:


如果一次传入多个分组的数组,那么会根据分组数最多的结果显示,并与其他分组相对应:

可以使用unstack方法,将多重索引展开:

分组键也可以是任意长度适当的数组:

也可以是DataFrame的列名:

如果某一列不是数值数据,会从结果中排除这一列的聚合结果。
groupby有size方法,可以返回含有分组大小的Series:

对分组进行迭代:

其中,name将被赋值索引,groupby被赋值分组后的数值

一个有用的运算:将df.groupby('key1')对象做成字典。

选取一个或一组列

只对data1和data2进行分组聚合。
通过字典或Series进行分组:

创建字典:
![]()
将字典传入groupby即可作为分组键

Series也有同样的功能,如果将Series作为索引,则pandas会检查Series以确保索引和分组轴是对齐的。

通过函数进行分组
如果想根据索引的长度进行分组,可以只传入获取长度的函数len:
将函数跟数组、列表、字典、Series混用也可以。

根据索引级别分组
层次化索引数据集能够根据索引级别进行聚合,只需要通过level关键字传入级别编号或名称即可:
hier_df.groupby(level='cty',axis=1).count()
数据聚合
GroupBy会高效地对Series进行切片,然后对各片调用piece.quantile(0.9),最后将这些结果组装成最终结果。
如果要使用自己对聚合函数,只需传入agg方法即可:

有些非聚合函数如describe也可以使用:


----自定义聚合函数将比python自身优化后的函数要慢很多---

如果传入的是优化函数和自定函数吗,那么还是要调用agg方法:
![]()
如果传入一组函数,那么得到的DataFrame会自动以相应的函数命名:

但并非一定要接受Groupby自动提供的列名。如果传入的是由(name,function)元组组成的列表,则各元组的第一个元素会被用于DataFrame的列名。
对于DataFrame,可以定义不同的列应用一组函数,也可以对不同的列应用不同的函数。
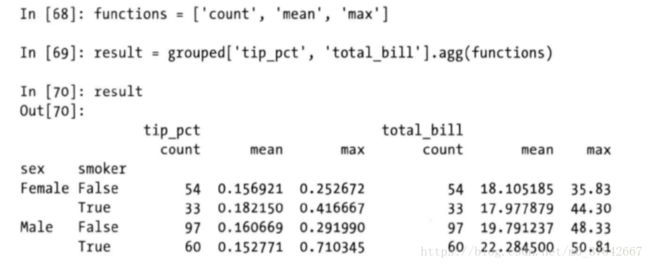

如果想要对不同的列应用不同的函数,具体的办法是向agg传入一个从列名映射到函数的字典:

transform函数:
transform函数会将一个函数应用到各个分组,然后将结果放置到适当的位置。如果各分组产生的是标量值,那么该值将被广播出去。

apply:一般性的“拆分-应用-合并”
transform函数和aggregate函数一样有着严格的条件:传入的函数只能产生两种结果,要么是一个可以广播的标量值(比如np.mean),要么产生一个相同大小的结果数组。
最一般化的groupby方法是apply。apply会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起。apply函数的威力取决于编码者的创造力,因为它只负责将函数在DataFrame的各个片段上调用,然后结果由pandas.concat组装到一起,最后返回一个pandas对象或标量值。
如果不需要将分组标志作为最后结果的索引,将group_keys=False传入groupby即可禁止该效果。
分位数和桶分析
透视表和交叉表
透视表是对各种电子表格程序和其他数据分析软件中一种常用的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上对分组键将数据分配到各个矩形区域中。

现在用法改了,rows改为index,cols改为columns