Sqoop的简单使用案例
Sqoop的简单使用案例
- 一、导入数据
- 1.1 RDBM 到HDFS
- 1.1.1 全部导入
- 1.1.2 查询导入
- 1.1.3 导入指定列
- 1.1.4 使用 sqoop 关键字筛选查询导入数据
- 1.1.5增量导入数据
- 1.1.6动态增量导入
- 1.2RDBM到HIVE
- 1.2.1全量导入hive
- 1.2.2 增量导入hive
- 1.3 RDBM到Hbase
- 二、导出数据
- 2.1hive 到myql
- 2.2 hdfs 到 mysql
- 2.3 hbase 到mysql
- 三、脚本
- 3.1 创建.opt 文件
- 3.2编写脚本
- 3.3运行脚本
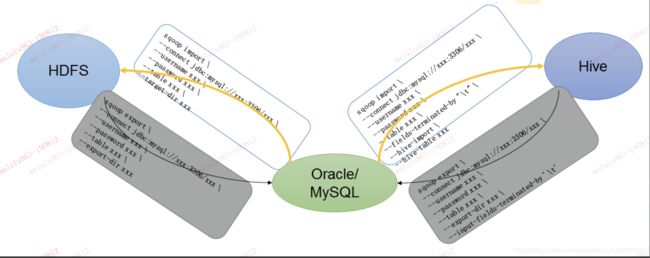
一、导入数据
1.1 RDBM 到HDFS
1.1.1 全部导入
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root1 --password root1 --table test001 --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t"
1.1.2 查询导入
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root1 --password root1 --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "t" --query 'select * from test001 where id >2 and $CONDITIONS;'
提示: must contain ‘$CONDITIONS’ in WHERE clause.
如果 query后使用的是双引号,则 $CONDITIONS前必须加转移符 ,防止 shell识别为自己的变量
1.1.3 导入指定列
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root1 --password root1--table test001 --columns id --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t"
提示: columns 中如果涉及到多列,用逗号分隔时不要添加空格
1.1.4 使用 sqoop 关键字筛选查询导入数据
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test001 --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t" --where "id=3"
1.1.5增量导入数据
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test001 --target-dir /user/company --num-mappers 1 --fields-terminated-by "\t" --incremental append --check-column id --last-value "5"
//第二种 lastmodified
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test002 --target-dir /user/company1 --num-mappers 1 --fields-terminated-by "\t" --incremental lastmodified --check-column insert_time --last-value "2019-08-13 14:38:08"
1.1.6动态增量导入
./sqoop job --create incr_001 -- import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test001 --target-dir /user/company2 --num-mappers 1 --fields-terminated-by "\t" --incremental append --check-column id --last-value "5"
./sqoop job --exec incr_001
./sqoop job --exec incr_001
提示: 对应的值保存在对应的 用户目录下面的.sqoop 文件里面,如下图:
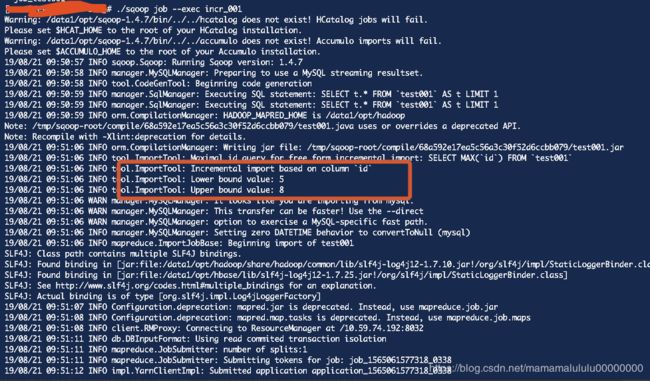
对应的 $[Home]/.sqoop 目录下面的文件内容如下:


1.2RDBM到HIVE
Hive 创建一张表:
create table h_test001(
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
1.2.1全量导入hive
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test001 --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t" --hive-import --hive-database warehouse --hive-table h_test001
这个 一般是 分为两步,第一步将数据导入到HDFS 里面,第二步是将导入到HDFS里面的数据导入到HIVE里面.
如果没有指定目录,默认的临时目录是 /user/用户/
1.2.2 增量导入hive
错误例子:
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test001 --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t" --hive-import --hive-database warehouse --hive-table h_test001 --incremental append --check-column id --last-value "5"
–append and --delete-target-dir can not be used together.(append 和 delete-target-dir 不能同时使用)
修改如下:
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test001 --target-dir /user/company --num-mappers 1 --fields-terminated-by "\t" --hive-import --hive-database warehouse --hive-table h_test001 --incremental append --check-column id --last-value "5"
另外一种:lastmodified —错误例子
//创建带有时间的表结构
CREATE TABLE `test002` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
insert_time TIMESTAMP default CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
//插入数据
insert into test002(name)values('zhangsan'),('lisi'),('wangwu'),
('jack');
//创建Hive 对应的表结构
create table h_test003(
id int,
name string,
insert_time string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
//增量导入
./sqoop import --connect jdbc:mysql://10.59.74.192:3306/test --username root --password root --table test002 --target-dir /user/company --num-mappers 1 --fields-terminated-by "\t" --hive-import --hive-database warehouse --hive-table h_test003 --incremental lastmodified --check-column insert_time --last-value "2019-08-13 14:38:08"

1.3 RDBM到Hbase
./sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table test001 --num-mappers 1 --hbase-table "hbase_company" --hbase-row-key "id" --column-family "info" --columns "id,name" --split-by id

相关参数如下:
| 选项 | 含义说明 |
|---|---|
| –append | 将数据追加到HDFS上一个已存在的数据集上 |
| –as-avrodatafile | 将数据导入到Avro数据文件 |
| –as-sequencefile | 将数据导入到SequenceFile |
| –as-textfile | 将数据导入到普通文本文件(默认) |
| –boundary-query | 边界查询,用于创建分片(InputSplit) |
| –columns |
从表中导出指定的一组列的数据 |
| –delete-target-dir | 如果指定目录存在,则先删除掉 |
| –direct | 使用直接导入模式(优化导入速度) |
| –direct-split-size | 分割输入stream的字节大小(在直接导入模式下) |
| –fetch-size | 从数据库中批量读取记录数 |
| -inline-lob-limit | 设置内联的LOB对象的大小 |
| -m,–num-mappers | 使用n个map任务并行导入数据 |
| -e,–query | 导入数据所使用的查询语句 |
| –split-by | 指定按照哪个列去分割数据 |
| –table | 导入的源表表名 |
| –target-dir | 导入HDFS的目标路径 |
| –warehouse-dir | HDFS存放表的根路径 |
| –where | 指定导出时所使用的查询条件 |
| -z,–compress | 启用压缩 |
| –compression-codec | 指定Hadoop的codec方式(默认gzip) |
| –null-string | string类型的字段,当Value是NULL,替换成指定的字符 |
| –null-non-string | 非string类型的字段,当Value是NULL,替换成指定字符 |
二、导出数据
2.1hive 到myql
/sqoop export --connect jdbc:mysql://localhost:3306/test --username root --password root --table test005 --num-mappers 1 --export-dir /user/hive/warehouse/warehouse.db/h_test001 --input-fields-terminated-by "\t"
Mysql中如果表不存在,不会自动创建
2.2 hdfs 到 mysql
./sqoop export --connect jdbc:mysql://licalhost:3306/test --username root --password root --table test004 --num-mappers 1 --export-dir /user/company1/ --input-fields-terminated-by "\t"
2.3 hbase 到mysql
hbase 不能直接导出到关系型数据库,需要通过hive 的中间作用来完成.
1.创建HIVE 外表关联 hbase 对应的表.
2.将外表同步到对应的 管理表(内表).
3.利用sqoop 同步到关系型数据库.
| 选项 | 含义说明 |
|---|---|
| –validate | 启用数据副本验证功能,仅支持单表拷贝,可以指定验证使用的实现类 |
| –validation-threshold | 指定验证门限所使用的类 |
| –direct | 使用直接导出模式(优化速度) |
| –export-dir | 导出的HDFS源路径 |
| -m,–num-mappers | 使用n个map任务并行导出 |
| –table | 导出的目标表名称 |
| –call | 导出数据调用的指定存储过程名 |
| –update-key | 更新参考的列名称,多个列名使用逗号分隔 |
| –update-mode | 指定更新策略,包括:updateonly(默认)、allowinsert |
| –input-null-string | 使用指定字符串,替换字符串类型值为null的列 |
| –input-null-non-string | 使用指定字符串,替换非字符串类型值为null的列 |
| –staging-table | 在数据导出到数据库之前,数据临时存放的表名 |
| –clear-staging-table | 清除工作区中临时存放的数据 |
| –batch | 使用批量模式导出 |
三、脚本
3.1 创建.opt 文件
mkdir opt
touch opt/job_test1.opt
3.2编写脚本
export
--connect
jdbc:mysql://localhost:3306/test
--username
root
--password
root
--table
test005
--num-mappers
1
--export-dir
/user/hive/warehouse/warehouse.db/h_test001
--input-fields-terminated-by
"\t"
3.3运行脚本
./sqoop --options-file ../opt/job_test1.opt