06.模型创建步骤与nn.Module;模型容器与AlexNet构建
文章目录
- 内容概要
- 网络模型创建步骤
- nn.Module属性
- nn.Module总结
- 模型容器(Containers)
- 容器之Sequential
- 容器之ModuleList
- 容器之ModuleLDict
- 容器总结
- AlexNet构建
- AlexNet简介
- 代码分析
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
内容概要
本节第一部分介绍网络模型的基本类nn.Module,nn.Module是所有网络层的基本类,它拥有8个有序字典,用于管理模型属性,本节课中将要学习如何构建一个Module。
然后通过网络结构和计算图两个角度去观察搭建一个网络模型需要两个步骤:第一步,搭建子模块;第二步,拼接子模块。
本节第二部分介绍搭建网络模型常用的容器,如Sequential,ModuleList, ModuleDict,然后学习pytorch提供的Alexnet网络模型结构加深对模型容器的认识。
网络模型创建步骤
先回顾机器学习模型训练步骤:

前面讲的是数据模块,这节课讲的是模型模块
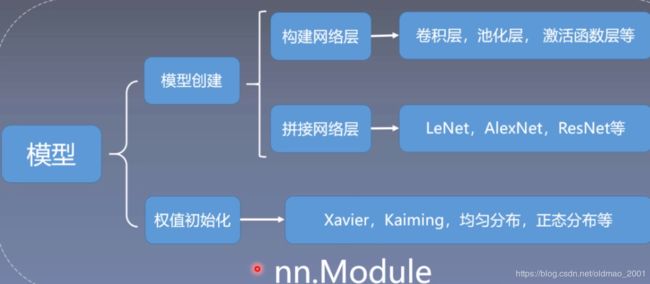
下面来学习创建模型,先回顾之前人民币二分类中创建的模型,就是LeNet,其结构如下:
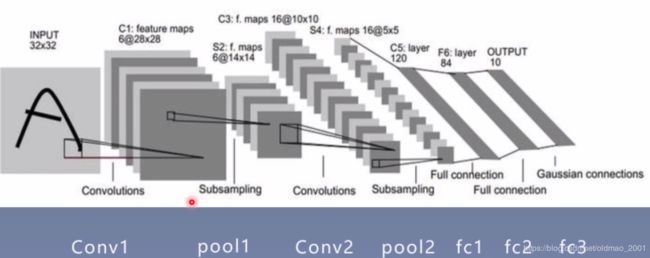
在Pytorch中LeNet是一个module的概念,LeNet中的那些卷积层,池化层也是module的概念。他们都属于nn.Module这个类,也就是说一个module可以包含多个子module。
下面是一个LeNet的计算图,图中有两个重要的概念,一个是节点(张量或者是数据,就是图中的方块或者长方体),一个是边(运算,就是图中的箭头)。可以把整个LeNet看做是一个运算(就是两个粉色之间的东西),它的输入是32323的张量,经过一系列复杂的运算之后,输出长度为10的向量。
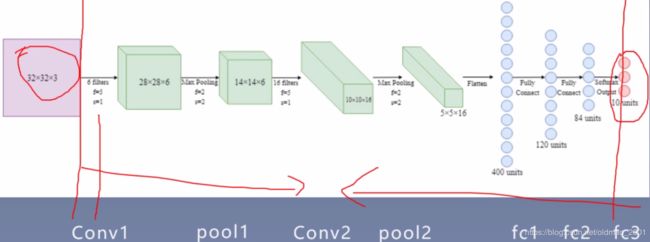
模型构建两要素
构建子模块:就是构造卷积层,池化层等等。在__init__()函数中
拼接子模块:将子模块按照一定的拓扑规则连接起来。在forward()函数中
构建子模块代码示例:
def init (self, classes):
self. conv1=nn.conv2d(3,6,5)
self. conv2=nn.cofiv2d(6,16,5)
self. fc1=nn.Linear(16*5*5,120)
self. fc2=nn.Linear(120,84)
self. fc3=nn.Linear(84, classes)
拼接子模块代码示例(前向传播)
def forward(self,x):
out=F.relu(self. convl(x))
out: out=F.max_pool2d(out,2)
out=F.relu(self. conv2(out))
out=F.max_pool2d(out,2)
out=out.view(out. size(0),-1)
out=F.relu(self. fcl(out)) out=F. relu(self. fc2(out))
out=self.fc3(out)
return out
nn.Module属性
先来看看torch.nn整体的框架
| nn.Parameter | 张量子类,表示可学习参数,如weight,bias | |
|---|---|---|
| torch.nn | nn.Module | 所有网络层基类,管理网络属性 |
| nn.functional | 函数具体实现,如卷积,池化,激活函数等 | |
| nn.init | 参数初始化方法 |
这里只关注nn.Module:
·parameters:存储管理nn.Parameter类(包括权值、偏置等)
·modules:存储管理nn.Module类(管理各种子模块,卷积层、池化层)
·buffers:存储管理缓冲属性,如BN层中的running_mean
·***_hooks:存储管理钩子函数(有五个)
下面是八个有序字典的初始化代码,具体位置是在module.py中的def _construct(self):方法中
self._parameters=OrderedDict()
self._buffers=OrderedDict()
self._backward hooks=OrderedDict()
self._forward hooks=OrderedDict()
self._forward_pre_hooks=OrderedDict() self._state_dict_hooks =OrderedDict()
self._load_state_dict_pre_hooks=OrderedDict()
self._modules=OrderedDict()
nn.Module总结
·一个module可以包含多个子module
·一个module相当于一个运算,必须实现forward()函数
·每个module都有8个字典管理它的属性
模型容器(Containers)
nn.Sequetial:按顺序包装多个网络层
nn.ModuleList:像python的ist一样包装多个网络层
nn.ModuleDict:像python的dict一样包装多个网络层
容器之Sequential
nn.Sequential是nn.module的容器,用于按顺序包装一组网络层,例如:对于LeNet来说,可以分成两个Sequential,分别是特征提取和分类。

注意示例代码中的forward要比之前的要简洁
class LeNetSequential(nn.Module):
def __init__(self, classes):
super(LeNetSequential, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes),)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
上面定义的各个层的命名都是序号,在多个层的时候不是很方便调试或者阅读,可以在创建Sequential的时候用OrderedDict指定层的名字,具体做法如下:
class LeNetSequentialOrderDict(nn.Module):
def __init__(self, classes):
super(LeNetSequentialOrderDict, self).__init__()
self.features = nn.Sequential(OrderedDict({
'conv1': nn.Conv2d(3, 6, 5),
'relu1': nn.ReLU(inplace=True),
'pool1': nn.MaxPool2d(kernel_size=2, stride=2),
'conv2': nn.Conv2d(6, 16, 5),
'relu2': nn.ReLU(inplace=True),
'pool2': nn.MaxPool2d(kernel_size=2, stride=2),
}))
self.classifier = nn.Sequential(OrderedDict({
'fc1': nn.Linear(16*5*5, 120),
'relu3': nn.ReLU(),
'fc2': nn.Linear(120, 84),
'relu4': nn.ReLU(inplace=True),
'fc3': nn.Linear(84, classes),
}))
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
小结:
·顺序性:各网络层之间严格按照顺序构建
·自带forward():自带的forward里,通过for循环依次执行前向传播运算
容器之ModuleList
nn.ModuleList是nn.module的容器,用于包装一组网络层,以迭代方式调用网络层
主要方法:
·append():在ModuleList后面添加网络层
·extend():拼接两个ModuleList
·insert():指定在ModuleList中位置插入网络层
下面例子是创建一个20层的FC网络模型
class ModuleList(nn.Module):
def __init__(self):
super(ModuleList, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])
def forward(self, x):
for i, linear in enumerate(self.linears):
x = linear(x)
return x
容器之ModuleLDict
nn.ModuleDict是nn.module的容器,用于包装一组网络层,以索引方式调用网络层主要方法:
·clear():清空ModuleDict
·items():返回可迭代的键值对(key-value pairs)
·keys():返回字典的键(key)
·values():回字典的值(value)
·pop():返回一对键值,并从字典中删除
其实和python中的dict用法差不多。
class ModuleDict(nn.Module):
def __init__(self):
super(ModuleDict, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict({
'relu': nn.ReLU(),
'prelu': nn.PReLU()
})
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
net = ModuleDict()
fake_img = torch.randn((4, 10, 32, 32))
output = net(fake_img, 'conv', 'relu')
print(output)
容器总结
·nn.Sequential:顺序性,各网络层之间严格按顺序执行,常用于block构建
·nn.ModuleList:迭代性,常用于大量重复网构建,通过for循环实现重复构建
·nn.ModuleDict:索引性,常用于可选择的网络层
AlexNet构建
AlexNet简介
2012年以高出第二名10多个百分点的准确率获得lmageNet分类任务冠军,开创了卷积神经网络的新时代
AlexNet特点如下:
1.采用ReLU:替换饱和激活函数,减轻梯度消失
2.采用LRN(Local Response Normalization):对数据归一化,减轻梯度消失(后来被BN代替了)
3.Dropout:提高全连接层的鲁棒性,增加网络的泛化能力
4.Data Augmentation:TenCrop,色彩修改
参考文献:《ImageNet Classification with Deep Convolutional Neural Networks》
代码分析

在pytorch中按ctrl,单击下面代码中的AlexNet,可以跳到pytorch的AlexNet实现。
alexnet = torchvision.models.AlexNet()
特征提取Sequential

分类器Sequential
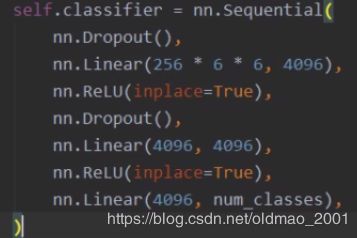
前向传播
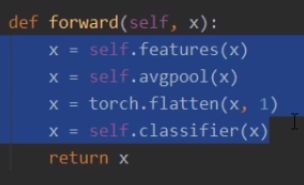
pytorch自带的深度学习结构:
附加上明同学的思维导图:
