内核启动的C语言阶段——start_kernel函数
以下内容源于朱有鹏嵌入式课程的学习,如有侵权,请告知删除。
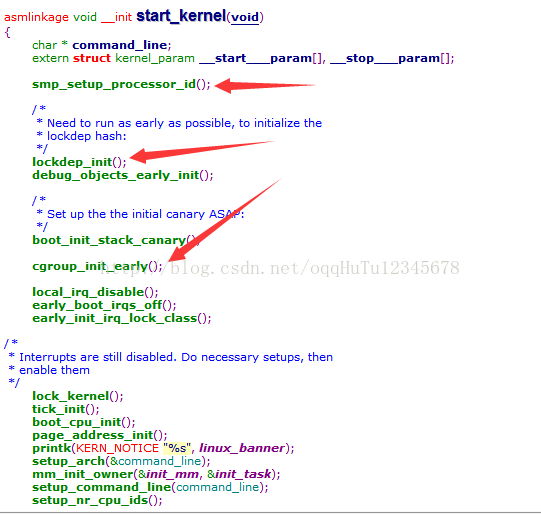
start_kernel函数位于kernel/init/main.c,完成以下内容:
(1)打印一些输出信息。
(2)内核工作所需的模块的初始化被依次调用(譬如内存管理、调度系统、异常处理……)。
- 重点了解setup_arch做的2件事情:机器码架构的查找并且执行架构相关的硬件的初始化,uboot给内核的传参cmdline。
- 重点了解内核启动后的稳定状态。
一、内核的解压缩、版本信息打印
1、零碎内容
(2)lockdep。锁定依赖,是一个内核调试模块,处理内核自旋锁死锁问题相关的;
(3)cgroup。control group,内核提供的一种来处理进程组的技术。
2、解压缩
实际是在head.S中调用了下面的函数


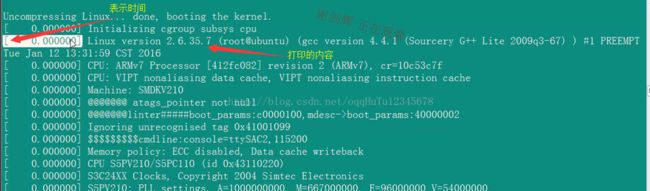
3、打印内核版本信息

(1)printk函数是内核中用来向console打印信息的,类似于应用层编程中的printf。
- 内核编程时不能使用标准库函数,因此不能使用printf,其实printk就是内核自己实现的一个printf。
(2)printk函数的用法和printf几乎一样,不同之处在于可以在参数最前面用一个宏来定义消息输出的级别。
- 因为linux代码量太多,里面的printk打印信息太多。如果所有的printk都能打印出来而不加任何限制,则最终内核启动后得到海量的输出信息。
- linux内核给每一个printk添加一个打印级别。级别定义0-7(注意编程的时候要用相应的宏定义,不要直接用数字)分别代表8种输出的重要性级别,0表示最重要,7表示最不重要。根据自己的消息的重要性去设置打印级别。
- linux的控制台有一个消息过滤显示机制,控制台实际只会显示级别比我的控制台定义的级别高的消息。譬如说控制台的消息显示级别设置为4,那么只有printk中消息级别为0-3(也可能是0-4)的才可以显示看见。
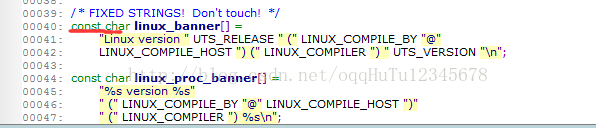
(3)linux_banner的内容解析
- UTS_RELEASE,可以在编译后的kernel目录下,使用grep "UTS_RELEASE" * -nR指令搜索。同理可以查找其他字符的出处。
二、内核对架构信息的处理
1、setup_arch函数简介
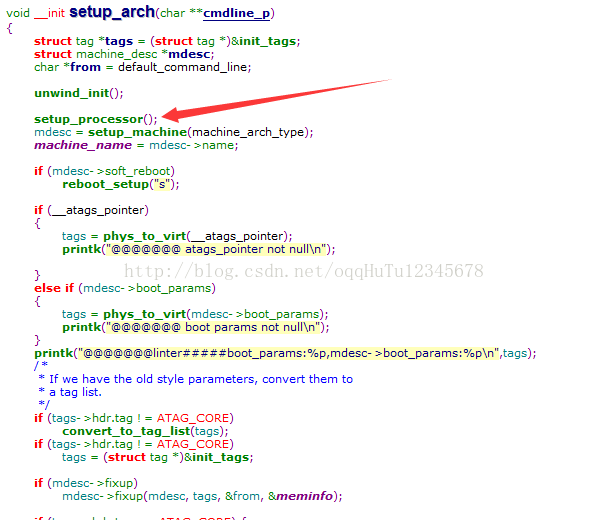
(1)此函数是CPU架构相关的一些创建过程。
(2)此函数用来确定当前内核对应的硬件平台(arch、machine)。
- linux内核会支持一种CPU的运行,而CPU+开发板就确定了一个硬件平台。经过配置的内核可以在此平台上运行。
- 机器码是硬件平台的一个固定的编码,用来表征这个平台。
(3)当前内核支持的机器码、硬件平台相关的一些定义,都在此函数中处理。
2、setup_arch函数内部的setup_processor函数
(1)此函数用来查找CPU信息,可以结合串口打印的信息来分析。



3、setup_arch函数内部的setup_machine函数

(1)传参是机器码编号
- machine_arch_type符号在include/generated/mach-types.h的32039-32050行定义,经过分析后确定这个传参值就是2456。
(2)函数的作用
- 通过传入的机器码编号,找到对应这个机器码的machine_desc描述符,并且返回这个描述符的指针。
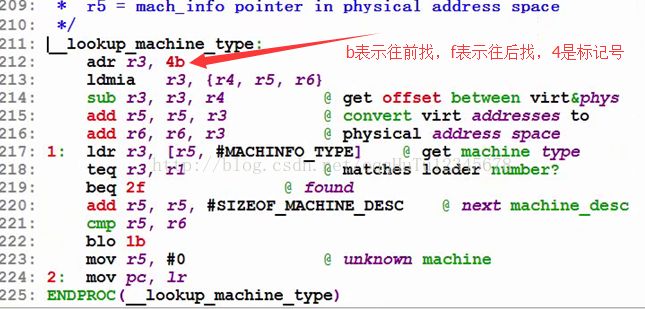
(3)真正干活的函数是lookup_machine_type
- 此函数在head-common.S中,分析得知真正干活的函数是__lookup_machine_type。
(4)__lookup_machine_type函数的工作原理
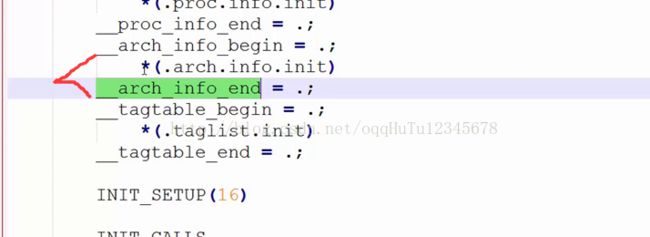
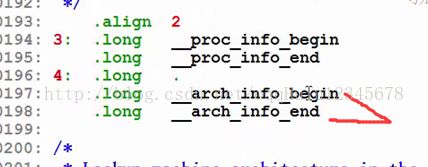
- 内核在建立时,把各种CPU架构的信息组织成若干machine_desc结构体实例,然后设置段属性.arch.info.init,链接的时候,这些描述符就会被连接在一起。
- __lookup_machine_type函数到描述符所在处,依次遍历各个描述符,比对看机器码哪个相同。
链接脚本截图:
_lookup_machine_type函数截图:
三、内核对bootargs的处理

1、setup_arch函数进行基本的cmdline处理


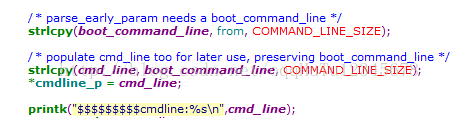

(1)cmdline,指uboot给kernel传参时传递的命令行启动参数,即uboot的bootargs。

(2)有几个相关的变量需要注意
- default_command_line是默认的命令行参数,实际是一个全局变量字符数组。
- CONFIG_CMDLINE,在.config文件中定义(可以在make menuconfig中去更改设置),它表示内核的默认的命令行参数。
![]()
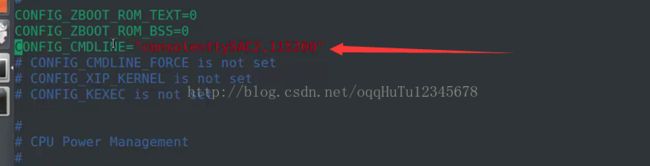
(3)内核对cmdline的处理思路
- 内核中维护一个默认的cmdline(即.config中所配置的那个),uboot也可以通过tag给kernel再传递一个cmdline。
- 如果uboot给内核传cmdline成功,则内核会优先使用uboot所传递的;如果uboot没有给内核传cmdline或者传参失败,则内核会使用默认的cmdline。
- 内核为什么要这样设计?因为希望内核是灵活的,可以通过传参对内核进行配置。
- 这个处理思路在setup_arch函数中实现。
2、setup_command_line函数
处理和命令行参数cmdline有关的任务。
3、parse_early_param函数、parse_args函数
(1)解析cmdline传参和其他传参
- 即,将cmdline的细节设置信息给解析出来。
- 譬如cmdline:console=ttySAC2,115200 root=/dev/mmcblk0p2 rw init=/linuxrc rootfstype=ext3,则解析出的内容就是就是一个字符串数组。
- 数组中依次存放了一个设置项目信息。
(2)只是进行解析,并没有去处理
- 只是把长字符串解析成短字符串,最多和内核里控制这个相应功能的变量挂钩了,但是并没有去执行。
- 执行的代码在各自模块初始化的代码部分。
四、start_kernel杂碎的函数
(1)start_kernel函数中调用了很多的xx_init函数,全都是内核工作需要的模块的初始化函数。
- trap_init设置异常向量表
- mm_init内存管理模块初始化
- sched_init内核调度系统初始化
- early_irq_init&init_IRQ中断初始化
- console_init控制台初始化
(2)这些初始化之后,内核就具备了基本的工作条件。
- 如果把内核比喻成一个复杂机器,那么start_kernel函数就是把这个机器的众多零部件组装在一起形成这个机器,让其具有可以工作的基本条件。
五、start_kernel末尾的rest_init函数
1、rest_init函数
此函数之前内核的基本组装已经完成,剩下的一些工作放在一个单独的函数中,叫rest_init。
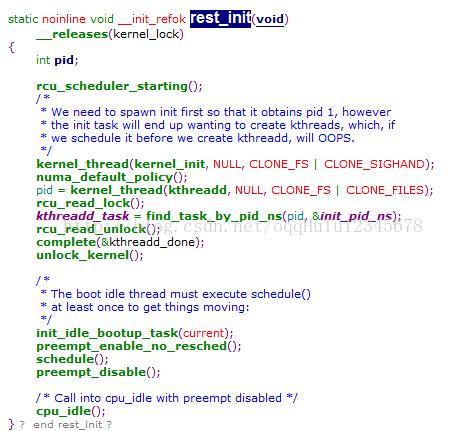
(1)rest_init中调用kernel_thread函数,启动了2个内核线程,分别是:kernel_init和kthreadd。
(2)调用schedule函数开启内核的调度系统,从此linux系统开始转起来。
(3)rest_init最终调用cpu_idle函数结束整个内核的启动,即linux内核最终结束于cpu_idle函数。
(4)linux内核最终的状态
- linux内核最终结束于cpu_idle函数,此函数里面是死循环。
- 调度系统负责考评系统中所有的进程。只要有哪个需要被运行,调度系统就会终止cpu_idle死循环进程(空闲进程)转而去执行有意义的干活的进程。

2、什么是内核线程?
- 一个运行的程序就是一个进程,这个程序和别的程序是分开的,这个程序可以被内核单独调用执行或者暂停。
- 应用层运行一个程序就构成一个用户进程/线程;
- 内核中运行一个函数(函数其实就是一个程序)就构成一个内核进程/线程。
- 因此kernel_thead函数运行一个函数,就是把这个函数变成一个内核线程,可以被内核调度系统去调度,即去调度器注册,将来调度的时候会进行考虑。
3、进程0、进程1、进程2
(1)截至目前为止,我们一共涉及到3个内核进程/线程。操作系统用数字来表示/记录一个进程/线程,此数字就被称为这个进程的进程号。这个号码是从0开始分配的。
- 进程0:idle进程,叫空闲进程,也就是死循环。
- 进程1:kernel_init函数就是进程1,这个进程被称为init进程。
- 进程2:kthreadd函数就是进程2,这个进程是linux内核的守护进程。这个进程是用来保证linux内核自己本身能正常工作的。
(2)在linux命令行下,使用ps命令可以查看当前linux系统中运行的进程情况。
(3)在ubuntu下ps -aux可以看到当前系统运行的所有进程,可以看出进程号是从1开始的。
- 为什么不从0开始,因为进程0不是一个用户进程(查询不到),而属于内核进程。
学习方法
(1)学习思路
- 抓大放小,不深究;
- 感兴趣可以就某个话题去网上搜索资料学习;
- 重点局部深入分析;
(2)具体学习方法
- 顺着代码执行路径抓全,这是我们的学习主线;
- 对照内核启动的打印信息进行分析。
(3)几条学习线路
- 分析uboot给kernel传参的影响和实现;
- 硬件初始化与驱动加载;
- 内核启动后的结局与归宿。