进行时间序列分类实践--python实战
介绍
你是否想要分类时间序列类型的数据?时间序列数据分类的实现真的有可能吗?即使分类了又可能有什么用呢?这些可能是您阅读本文标题时必须具备的一些基本问题。这是普遍存在的–当我第一次遇到这个概念时,我也有完全相同的想法!
我们大多数人的时间序列数据主要涉及生产预测的交易方面。无论是预测产品的需求还是销售额,航空公司的乘客数量或特定股票的收盘价,我们都习惯于利用久经考验的时间序列技术来预测需求。
但随着生成的数据量呈指数增长,我们有了更多的机会去尝试新想法和算法。使用复杂的时间序列数据集仍然是一个利基(有前途的)领域,扩展你包含新的想法的技能以总是很有帮助的。
这就是我在文章中的目的,向您介绍时间序列分类的新概念。我们将首先了解这个主题的含义以及它在行业中的应用。但是我们不会停留在理论部分 - 我们将通过处理时间序列数据集并执行二进制时间序列分类来解决问题。边做边学 - 这将有助于您以实际的方式理解这个概念。
如果您之前没有处理过时间序列问题,我强烈建议您先从一些基本预测开始。您可以通过以下文章了解初学者:
全面的初学者指南,用于创建时间序列预测(使用Python中的代码)
目录
- 时间序列分类简介
- 心电图信号
- 图像数据
- 传感器
- 设置问题陈述
- 阅读和理解数据
- 预处理
- 建立我们的时间序列分类模型
时间序列分类简介
时间序列分类实际上已经存在了一段时间。但到目前为止,它主要限于研究实验室,而不是行业应用。但是有很多研究正在进行,正在创建新的数据集并提出了许多新的算法。当我第一次看到这个时间序列分类概念时,我最初的想法是 - 我们如何对时间序列进行分类以及时间序列分类数据是什么样的?我相信你一定想知道同样的事情。
可以想象,时间序列分类数据与常规分类问题不同,因为属性具有有序序列。让我们来看看一些时间序列分类用例,以了解这种差异。
1)对ECG / EEG信号进行分类
心电图或心电图记录心脏的电活动,广泛用于诊断各种心脏问题。使用外部电极捕获这些ECG信号。
例如,考虑以下信号样本,它代表一个心跳的电活动。左侧的图像表示正常心跳,而与其相邻的图像表示心肌梗塞。
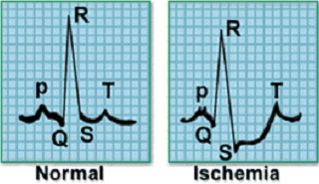
从电极捕获的数据将是时间序列形式,并且信号可以分类为不同的类别。我们还可以对记录大脑电活动的脑电信号进行分类。
2)图像分类
图像也可以是顺序的时间相关格式。请考虑以下情形:
根据天气条件,土壤肥力,水的可用性和其他外部因素,农作物在特定的田地中生长。该字段的图片每天拍摄5年,并标记在该字段上种植的作物的名称。你能明白我的意思么?数据集中的图像是在固定的时间间隔之后拍摄的,并且具有定义的序列,这可能是对图像进行分类的重要因素。
3)分类运动传感器数据
传感器生成高频数据,可以识别其范围内物体的移动。通过设置多个无线传感器并观察传感器中信号强度的变化,我们可以识别物体的运动方向。
您还可以考虑哪些其他应用程序可以应用时间序列分类?请在文章下方的评论部分告诉我。
设置问题陈述
我们将致力于“ 室内用户运动预测 ”问题。在该挑战中,多个运动传感器被放置在不同的房间中,并且目标是基于从这些运动传感器捕获的频率数据来识别个体是否已经移动穿过房间。
两个房间有四个运动传感器(A1,A2,A3,A4)。请看下面的图像,其中说明了传感器在每个房间中的位置。这两个房间布置了3对不同的房间(group1,group2,group3)。
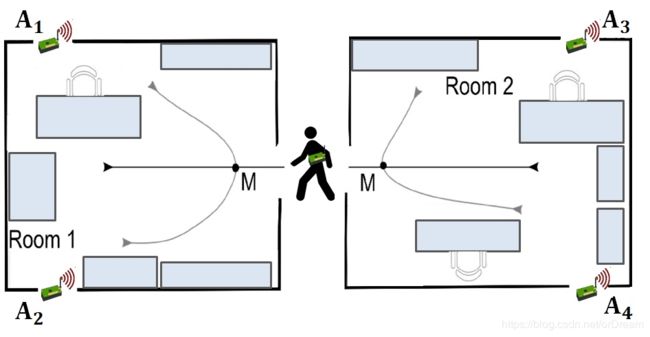
一个人可以沿着上图中所示的六个预定义路径中的任何一个移动。如果一个人走在路径2,3,4或6,他会在房间内移动。另一方面,如果一个人沿着路径1或路径5行进,我们可以说该人已经在房间之间移动。
传感器读数可用于识别人在给定时间点的位置。当人在房间或房间内移动时,传感器中的读数会发生变化。此更改可用于标识人员的路径。
现在问题陈述已经清楚了,现在是时候开始编码了!在下一节中,我们将查看问题的数据集,这有助于消除您在此声明中可能存在的任何遗留问题。您可以从以下链接下载数据集:室内用户移动预测。
阅读和理解数据
我们的数据集包含316个文件:
- 314 MovementAAL csv文件,包含放置在环境中的运动传感器的读数
- 一个目标包含每个MovementAAL文件的目标变量csv文件
- 一个Group Data csv文件,用于标识哪个MovementAAL文件属于哪个安装组
- 该路径包含该对象所采取的方法csv文件
我们来看看数据集。我们将从导入必要的库开始。
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
from os import listdir
from keras.preprocessing import sequence
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.optimizers import Adam
from keras.models import load_model
from keras.callbacks import ModelCheckpoint
在加载所有文件之前,让我们快速了解一下我们要处理的数据。从移动数据中读取前两个文件:
df1 = pd.read_csv('/ MovementAAL / dataset / MovementAAL_RSS_1.csv')
df2 = pd.read_csv('/ MovementAAL / dataset / MovementAAL_RSS_2.csv')
df1.head()

df2.head()

df1.shape, df2.shape
((27, 4), (26, 4))
这些文件包含来自四个传感器的标准化数据 - A1,A2,A3,A4。csv文件的长度(行数)不同,因为对应于每个csv的数据的持续时间不同。为简化起见,我们假设每秒都会收集传感器数据。第一次读数持续27秒(所以27行),而另一次读数持续26秒(所以26行)。
在构建模型之前,我们必须处理这种不同的长度。现在,我们将使用以下代码块读取传感器中的值并将其存储在列表中:
path = 'MovementAAL/dataset/MovementAAL_RSS_'
sequences = list()
for i in range(1,315):
file_path = path + str(i) + '.csv'
print(file_path)
df = pd.read_csv(file_path, header=0)
values = df.values
sequences.append(values)
targets = pd.read_csv('MovementAAL/dataset/MovementAAL_target.csv')
targets = targets.values[:,1]
我们现在有一个列表’序列 ‘,其中包含来自运动传感器的数据和’目标’,其中包含csv文件的标签。当我们打印序列[0]时,我们从第一个csv文件中获取传感器的值:
sequences[0]
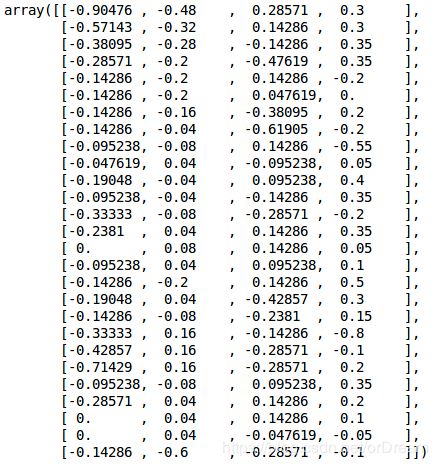
如前所述,数据集是在三对不同的房间中收集的 - 因此有三组。此信息可用于将数据集划分为训练集,测试集和验证集。我们现在将加载DatasetGroup csv文件:
groups = pd.read_csv('MovementAAL/groups/MovementAAL_DatasetGroup.csv', header=0)
groups = groups.values[:,1]
我们将取前两组数据用于培训,取第三组数据用于测试。
预处理步骤
由于时间序列数据的长度不同,我们无法直接在此数据集上构建模型。那么我们怎样才能决定一个系列的理想长度呢?我们可以通过多种方式处理它,这里有一些想法(我很乐意在评论部分听到您的建议):
- 用零填充较短的序列以使所有序列的长度相等。在这种情况下,我们将向模型提供不正确的数据
- 找到系列的最大长度,并使用最后一行中的数据填充序列
- 确定数据集中序列的最小长度,并将所有其他序列截断为该长度。但是,这将导致数据的巨大损失
- 取所有长度的平均值,截断较长的系列,并填充比平均长度短的系列
让我们找出最小,最大和平均长度:
len_sequences = []
for one_seq in sequences:
len_sequences.append(len(one_seq))
pd.Series(len_sequences).describe()
count 314.000000 # 计算非na /null观察值的数量。
mean 42.028662 # 平均值。
std 16.185303 # 观测值的标准差。(n-1 哦)
min 19.000000 # 最小值。
25% 26.000000 # 第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
50% 41.000000 # 第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
75% 56.000000 # 第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
max 129.000000 # 对象中值的最大值。
dtype: float64
对于 四分位数 不是太了解?我敢开始也不是很了解,这里有详细解释
大多数文件的长度在40到60之间。只有3个文件的长度超过100个。因此,采用最小或最大长度没有多大意义。第90个四分位数为60,这被视为数据序列的长度。我们来编代码:
#Padding the sequence with the values in last row to max length
to_pad = 129
new_seq = []
for one_seq in sequences:
len_one_seq = len(one_seq)
last_val = one_seq[-1]
n = to_pad - len_one_seq
to_concat = np.repeat(one_seq[-1], n).reshape(4, n).transpose()
new_one_seq = np.concatenate([one_seq, to_concat])
new_seq.append(new_one_seq)
final_seq = np.stack(new_seq)
#truncate the sequence to length 60
from keras.preprocessing import sequence
seq_len = 60
final_seq=sequence.pad_sequences(final_seq, maxlen=seq_len, padding='post', dtype='float', truncating='post')
现在已准备好数据集,我们将根据组将其分开。准备训练,验证和测试集:
train = [final_seq[i] for i in range(len(groups)) if (groups[i]==2)]
validation = [final_seq[i] for i in range(len(groups)) if groups[i]==1]
test = [final_seq[i] for i in range(len(groups)) if groups[i]==3]
train_target = [targets[i] for i in range(len(groups)) if (groups[i]==2)]
validation_target = [targets[i] for i in range(len(groups)) if groups[i]==1]
test_target = [targets[i] for i in range(len(groups)) if groups[i]==3]
train = np.array(train)
validation = np.array(validation)
test = np.array(test)
train_target = np.array(train_target)
train_target = (train_target+1)/2
validation_target = np.array(validation_target)
validation_target = (validation_target+1)/2
test_target = np.array(test_target)
test_target = (test_target+1)/2
建立时间序列分类模型
我们准备了用于LSTM(长短期记忆)模型的数据。我们处理了可变长度序列并创建了训练,验证和测试集。让我们构建一个单层LSTM网络。
注意:您可以在这个精彩解释的教程中熟悉LSTM 。我会建议你先完成它,因为它可以帮助你理解下面代码的工作原理。
model = Sequential()
model.add(LSTM(256, input_shape=(seq_len, 4)))
model.add(Dense(1, activation='sigmoid'))
model.summary()
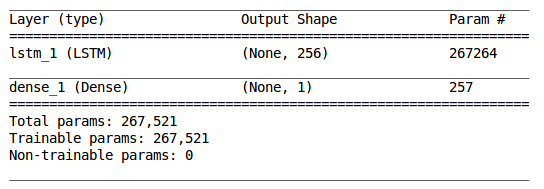
我们现在将训练模型并监控验证的准确性:
adam = Adam(lr=0.001)
chk = ModelCheckpoint('best_model.pkl', monitor='val_acc', save_best_only=True, mode='max', verbose=1)
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy'])
model.fit(train, train_target, epochs=200, batch_size=128, callbacks=[chk], validation_data=(validation,validation_target))
#loading the model and checking accuracy on the test data
model = load_model('best_model.pkl')
from sklearn.metrics import accuracy_score
test_preds = model.predict_classes(test)
accuracy_score(test_target, test_preds)
我的准确度得分为0.78846153846153844。这是一个非常有希望的开始,但我们肯定可以通过使用超参数,改变学习速度和/或时代数来改善LSTM模型的性能。
这将我们带到本教程的结尾。写下来的想法是以实用的方式向您介绍时间序列谱中的一个全新世界。
就个人而言,我发现预处理步骤是我们所涉及的所有部分中最复杂的部分。然而,它也是最重要的一个(否则整个时间序列数据将会失败!)。在处理此类挑战时,向模型提供正确的数据同样重要。
这是一个非常酷的时间序列分类资源,我提到并发现最有帮助的:
- 关于“通过油藏计算预测异构室内环境中用户移动”的论文
- Paper on “Predicting User Movements in Heterogeneous Indoor Environments by Reservoir Computing”
附:关于此文章一些小问题的解答
Q:
a)文章读完了,但是你在文中的目标是什么?
b)在这种情况下,准确度0.78意味着什么?
A:
a) 本文实例的目标是用于识别此人是否从一个房间移动到另一个房间或是否在同一房间内移动。
b) 在对某些数据进行训练之后,我们使用相同的方法模型对未知的数据进行预测,准确度为78%。
Q: 如何预测未来几天数据中将出现的时间序列模式?
A:按模式分类来看,您可以使用简单的arima模型进行预测,然后进行分解以获得趋势和季节性。
Q:有关图像数据的时间序列分类的任何出版物?
A:可以参考:http://www.timeseriesclassification.com/