SpringBoot-Mybatis 源码解析
说明
该文章说的是在SpringBoot中Mybatis是如何加载,并且加载后的原理是怎么样的,主要以Mybatis的源码加载为主,由于是Spring管理的Mybatis所以在这里先说一下Spring中的几个类
Spring 中的类(接口)
BeanDefinition(接口) : Bean是高级的实例,BeanDefinition是高级的class。
BeanDefinitionRegistry(接口) : 该类的作用主要是向注册表中注册 BeanDefinition 实例,完成 注册的过程。
实现类DefaultListableBeanFactory(实现类) 的 registerBeanDefinition 添加一系列判断并向 beanDefinitionMap(key:bean的名字,value: BeanDefinition) 中添加数据
BeanFactoryPostProcessor(接口) : 该接口主要是 在SpringBoot扫描了(加载)所有bean之后,在所有的bean实例化之前可以进行一些操作
BeanDefinitionRegistryPostProcessor(接口):在bean实例化之前进行一些操作,在bean定义之后所以可以从这里得到一个猜测:
当看到这里的时候,可能不太明白在这块先说这几个类意义在哪,具体的意义一会看代码的时候就体会到了,接下来再来看一张图:
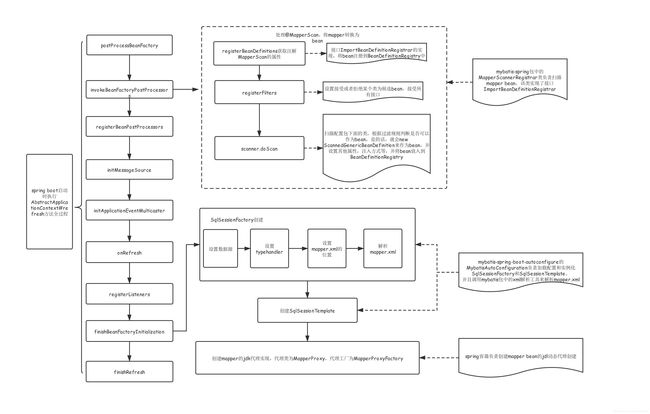
该图描述的是SpringBoot从启动过程中开始实例化Mybatis所需要的一些环境的大致过程,接下来的代码也是根据这个流程走的
在这里给出一个猜测:bean的加载过程: 加载,注册,实例化
加载:Spring扫描所有标有注解的类
注册:把bean注册到beanDefinitionMap中
实例化:IOC容器实例化完成
再给出一个猜测: 如果上面成立的话,当我们要加入Mybatis所包含的bean时,是不是把mybatis中的bean在实例化之前注册到beanDefinitionMap中就可以了
这个时候就需要 BeanFactoryPostProcessor,BeanDefinitionRegistryPostProcessor 了
Spring初始化Mybatis入口
AbstractApplicationContext
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
// 会调用所有 factory processor 注册到context中
//但是对于mybatis来说: 就是把Mybaits中的bean注册到context中
//注意此时bean还没有被实例化
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
invokeBeanFactoryPostProcessors方法执行过程:
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
//调用工厂的后置处理器
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
// Detect a LoadTimeWeaver and prepare for weaving, if found in the meantime
// (e.g. through an @Bean method registered by ConfigurationClassPostProcessor)
if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
调用后置处理器处理过程,在这里需要关注的方法为:invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry)
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List beanFactoryPostProcessors) {
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
Set processedBeans = new HashSet<>();
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List regularPostProcessors = new LinkedList<>();
List registryProcessors = new LinkedList<>();
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
List currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
//对于mybatis来说把bean在实例化之前注册到beanDefinitionMap中
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// Now, invoke the postProcessBeanFactory callback of all processors handled so far.
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
List priorityOrderedPostProcessors = new ArrayList<>();
List orderedPostProcessorNames = new ArrayList<>();
List nonOrderedPostProcessorNames = new ArrayList<>();
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
List orderedPostProcessors = new ArrayList<>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// Finally, invoke all other BeanFactoryPostProcessors.
List nonOrderedPostProcessors = new ArrayList<>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
beanFactory.clearMetadataCache();
}
invokeBeanDefinitionRegistryPostProcessors 处理过程
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection postProcessors, BeanDefinitionRegistry registry) {
for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
// 进行注册
postProcessor.postProcessBeanDefinitionRegistry(registry);
}
}
之后就是 MapperScannerRegistrar的注册过程,在这里着重看一下:这个方法大致可以理解为把用@MapperScan扫描到的包注册到Spring中,之后Spring在实例化IOC的时候会一并实例化的
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
AnnotationAttributes annoAttrs = AnnotationAttributes.fromMap(importingClassMetadata.getAnnotationAttributes(MapperScan.class.getName()));
ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry);
// this check is needed in Spring 3.1
if (resourceLoader != null) {
scanner.setResourceLoader(resourceLoader);
}
Class annotationClass = annoAttrs.getClass("annotationClass");
if (!Annotation.class.equals(annotationClass)) {
scanner.setAnnotationClass(annotationClass);
}
Class markerInterface = annoAttrs.getClass("markerInterface");
if (!Class.class.equals(markerInterface)) {
scanner.setMarkerInterface(markerInterface);
}
Class generatorClass = annoAttrs.getClass("nameGenerator");
if (!BeanNameGenerator.class.equals(generatorClass)) {
scanner.setBeanNameGenerator(BeanUtils.instantiateClass(generatorClass));
}
Class mapperFactoryBeanClass = annoAttrs.getClass("factoryBean");
if (!MapperFactoryBean.class.equals(mapperFactoryBeanClass)) {
scanner.setMapperFactoryBean(BeanUtils.instantiateClass(mapperFactoryBeanClass));
}
scanner.setSqlSessionTemplateBeanName(annoAttrs.getString("sqlSessionTemplateRef"));
scanner.setSqlSessionFactoryBeanName(annoAttrs.getString("sqlSessionFactoryRef"));
List basePackages = new ArrayList();
for (String pkg : annoAttrs.getStringArray("value")) {
if (StringUtils.hasText(pkg)) {
basePackages.add(pkg);
}
}
for (String pkg : annoAttrs.getStringArray("basePackages")) {
if (StringUtils.hasText(pkg)) {
basePackages.add(pkg);
}
}
for (Class clazz : annoAttrs.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
scanner.registerFilters();
scanner.doScan(StringUtils.toStringArray(basePackages));
}
注意代码中的:
AnnotationAttributes annoAttrs = AnnotationAttributes.fromMap(importingClassMetadata.getAnnotationAttributes(MapperScan.class.getName()));
其实看到这里应该明白为什么用mybatis的bean为什么要用@MapperScan这个注解了
因此,在spring启动过程中,实现了接口ImportBeanDefinitionRegistrar的类会被调用其方法registerBeanDefinitions来注册额外的bean到BeanDefinitionRegistry中,这里就可以根据自己的需求,使用定制的注解来实例bean。
也就是说自己可以自定义一个类实现ImportBeanDefinitionRegistrar,然后通过自定义的bean来实例化bean了
重点来了
**接下来回头来看看AbstractApplicationContext.reresh()方法中的 finishBeanFactoryInitialization(beanFactory) 方法的操作
该方法主要是
- 实例化SqlSessionFatory
- 实例化SqlSessionTeamplate
- 完成Mapper对应的实例化,绑定jdk动态代理**
Mybatis中类,接口的关系,以及作用
接口:SqlSession(线程不安全,不是单例),SqlSessionFatory(单例,线程安全)
SqlSession 的实现是对数据库的增删改查
从SqlSessionFatory中获取SqlSession ,
类: SqlSessionTeamplate 实现 SqlSession 接口 从而实现了对数据库的一套增删改查的方法
DefaultSqlSessionFactory: 实现了SqlSessionFatory接口,从而获取对应的SqlSession
SqlSessionFactoryBuilder : 主要是用来获取SqlSessionFatory
还需要关心几个类:
Configuration(类) 中的两个属性:
mapperRegistry 该属性中存放了所有的Dao
mappedStatements:是一个Map
key :存放的是Dao中所有的方法
value:放入的是一个MapperStatement(类)
MappedStatement这里类中存放了 对应mapper文件是那个,对应的mapper中的方法是那个,对应的参数类型是啥,等等
通过mappedStatements可以看到就可以把Dao中方法和Mapper中对应的方法关联起来了。
MyBatis源码实现
先执行SqlSessionFactoryBuilder类中的build方法
//因为SpringBoot不是使用的配置文件的形式,所以执行的这个方法
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
之后执行DefaultSqlSessionFactory类中的方法,来创建SesssionFatory
public DefaultSqlSessionFactory(Configuration configuration) {
this.configuration = configuration;
}
在之后初始化SqlSessionTemplate类
public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
notNull(sqlSessionFactory, "Property 'sqlSessionFactory' is required");
notNull(executorType, "Property 'executorType' is required");
this.sqlSessionFactory = sqlSessionFactory;
this.executorType = executorType;
this.exceptionTranslator = exceptionTranslator;
//会为每一个Dao都创建一个MapperProxy
this.sqlSessionProxy = (SqlSession) newProxyInstance(
SqlSessionFactory.class.getClassLoader(),
new Class[] { SqlSession.class },
new SqlSessionInterceptor());
}
到这里其实从SpringBoot加载Mybatis源码的过程就可以说是完事,更细节的问题,在这里就不讨论了
面试可能问到的问题
- Mybaits 的一级缓存和二级缓存是怎样的?
答:先给出结论: Mybatis中有一级缓存和二级缓存,默认情况下一级缓存是开启的,而且是不能关闭的。一级缓存 是指 SqlSession 级别的缓存,当在同一个 SqlSession 中进行相同的 SQL 语句查询时,第二次以 后的查询不会从数据库查询,而是直接从缓存中获取,一级缓存最多缓存1024条SQL。
二级缓存 是指可以跨 SqlSession 的缓存。是 mapper 级别的缓存,对于 mapper 级别的缓存不同的 sqlsession是可以共享的。
对上面话的解释:
关于对一级缓存的解释:当用户发出一个读(查询)的操作的时候,会首先从判断methodCache中有没有这个方法对应的方法,如果没有的话,就从数据库中查询,并且把查询的结果放入到methodcache中去,当第二次查询的时候去判断methodCache
中有没有相同的方法,此时methodcache应该已经存在,所以可以直接从methodcache中取出结果,返回给前端。当然,当进行写(新增,修改,删除)的操作时,会清除相应的methodcache中的结果。
一级缓存默认开启:
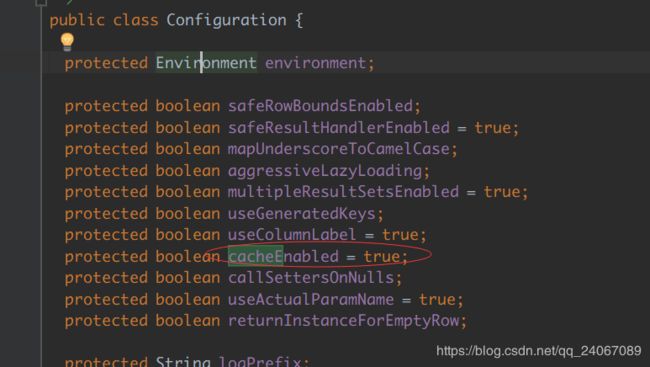
关于一级缓存的源码解释:
首先看下MapperProxy类
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 这里的cachedMapperMethod 就是判断缓存中有没有此查询
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}
cachedMapperMethod 方法
methodCache 是一个Map key: Method ;value:MapperMethod
private MapperMethod cachedMapperMethod(Method method) {
MapperMethod mapperMethod = methodCache.get(method);
//如果没有从methodCache中取到值的话,那么从数据库取值,并放入到methodCache中
if (mapperMethod == null) {
//从数据库中取值
mapperMethod = new MapperMethod(mapperInterface, method, sqlSession.getConfiguration());
//放入到methodCache中
methodCache.put(method, mapperMethod);
}
return mapperMethod;
}
二级缓存开关
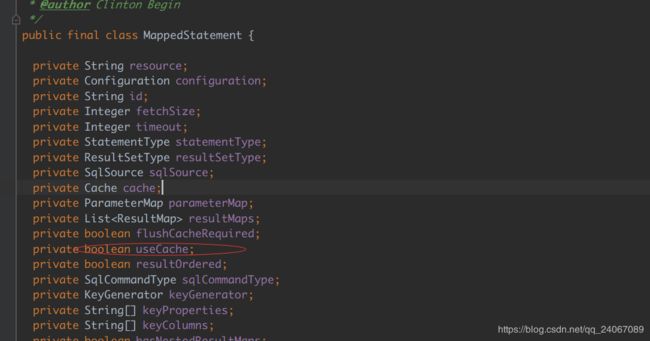
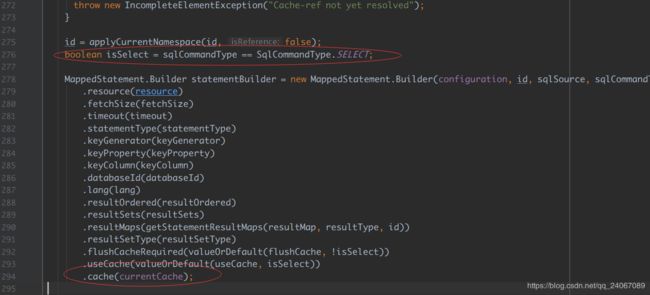
关于二级缓存的解释:
当启动spring的时候加载MapperBuilderAssistant 为所有select语句开启缓存得到一个默认值,当userCache为空的时候,就使用select比较出来的默认值,userCache默认应该是false(因为当没有配置的时候boolean类型的值默认为false),当userCahe被配置了之后那么就用配置的就行了
private T valueOrDefault(T value, T defaultValue) {
return value == null ? defaultValue : value;
}
二级缓存的范围是mapper级别(mapper同一个命名空间),mapper以命名空间为单位创建缓 存数据结构,结构是map。mybatis的二级缓存是通过CacheExecutor实现的。CacheExecutor其实是 Executor 的代理对象。所有的查询操作,在 CacheExecutor 中都会先匹配缓存中是否存 在,不存在则查询数据库。
key:MapperID+offset+limit+Sql+所有的入参
-
Mybatis中$和#的区别?
首先给出结论:mybatis对于#{}中的值都会加上双引号 即("") 对于 ${}中的的变量不会加上双引号
#{}可以防止sql注入, ${}不能防止sql注入
一般能用#{} 别使用 ${} -
Mybatis的底层实现原理是怎样的?
-
Mybatis中resutMap和resutType的区别?