java基础之Hash详解
文章目录
- 1. Hash散列表
- 1.1 开放寻址法:在ThreadLocalMap中采用的就是(线性探测法是开放寻址的一种)
- 1.2 链地址法:在jdk源码中HashMap采用的这种方式
- 1.3 再hash函数
- 1.4 建立公共溢出区
- 总结如下
- 2.HashMap数据结构详解
- 2.1 java1.7及以前 HasMap会产生死锁,java1.8及以后不会有死锁
- 2.2.3 测试HashMap死锁:jdk1.7
- HashMap数据丢失问题在1.7和18都有这个问题
- 3 hashMap源码分析
- 3.1 JDK7 HashMap 源码分析
- 3.2 JDK8 HashMap 源码分析
- 3.3 JDK8中使用Node对象维护数据结构而不是Entry了
- 3.4 当发生hash碰撞的图解
- 3.5 put方法源码解析
- 3.5.1 putVal()方法源码解析
- 3.5.2 resize(); 扩容的方法源码解析
- 4 ConcurrentHashMap源码分析
- 4.1 jdk7 ConcurrentHashMap源码分析
- 核心源代码:
- ConcurrentHashMap 的put()方法源代码解析
- Segment 的put的方法
- 4.2 jdk8 ConcurrentHashMap源码分析
- 4.2.1 存储数据的结构 Node及 TreeNode
- 核心源代码
- put() 方法源码解析
- helpTransfer ()方法
1. Hash散列表
散列表英文就是HashTable,也就是我们常说的哈希表,散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来;
我们几乎无法找到一个完美的无法冲突的散列函数,即使找到了付出的时间成本和计算成本也是很大的,所以针对散列问题,我们需要其他途径来解决;
什么是最好的hash函数:hash冲突要少,数据量的大小,初始化的大小,扩容
解决Hash冲突经典的三种方法:
1.1 开放寻址法:在ThreadLocalMap中采用的就是(线性探测法是开放寻址的一种)
11通过hash函数(这里使用的是对10取模)11对应 [1] ,22取模后发现位置已经存在数据就会继续完后一个位置直到找到一个空的位置,同理23也是这样;查找的关键就是采用同一个哈希函数,通过哈希函数定位到对应的位置如果有且是要找的数据就返回否则继续向后查找直到位置元素为空代表数据不存在;
但是这种方式对删除的支持不是很友好:删除时是对数据标记-1代表已删除;当查询这个数据后返回空
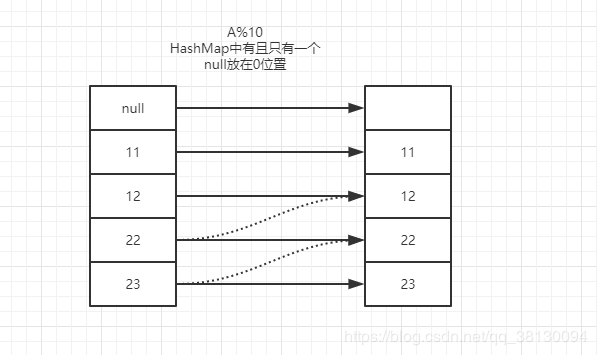
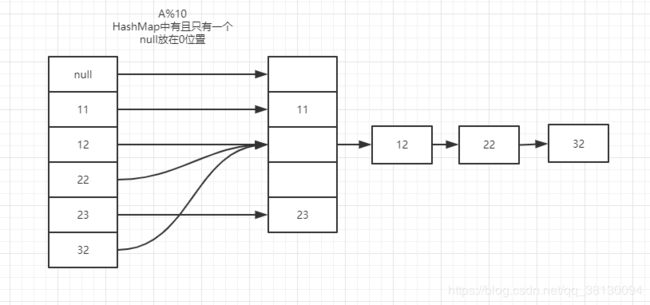
1.2 链地址法:在jdk源码中HashMap采用的这种方式
1.3 再hash函数
再hash法,就是算hashcode的方法不止一个,一个要是算出来重复,再用另一个算法去算。反正很多,直到不重复为止。本人了解不多,就不在赘述了
1.4 建立公共溢出区
此种方法不是很了解
总结如下
1.开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
2.再哈希法
3.链地址法(Java hashmap就是这么做的)
4. 建立公共溢出区
2.HashMap数据结构详解
HashMap的设计思路:
- 必须要高效:即插入,删除,查找必须要快
- 内存:不能占用太多的内存,考虑使用其他结构如:B+Tree
- Hash函数
- 扩容:最耗时的,考虑初始化大小
- hash冲突如何解决
2.1 java1.7及以前 HasMap会产生死锁,java1.8及以后不会有死锁
1.7基础数据模型:数组+链表
死锁原因:HashMap在多线程的场景下,扩容期间存在节点位置互换指针引用的问题有可能导致死锁;
put时:数据丢失
*1.7中HashMap的put时扩容的源码:*
/**
*使用容量更大。当此映射中的键数达到其阈值。
*如果当前容量是最大容量,则此方法不调整贴图大小,但将“阈值”设置为Integer.MAX_VALUE。
*@param new capacity新容量,必须是2的幂;
*必须大于当前容量,除非当前
*容量是最大容量(在这种情况下为值
*与此无关)
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
//进行数据拷贝操作的方法
transfer(newTable, rehash);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* 将当前表中的所有条目传输到newTable
* 把数组原来的数据拷贝到扩容后的数组;这里是线程不安全的--在并发执行的情况下会出现问题
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//遍历旧的数组表
for (Entry<K,V> e : table) {
//当前节点不为空
while(null != e) {
//当前节点指向的下一个节点
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//扩容后计算hash,来放到对应的位置
int i = indexFor(e.hash, newCapacity);
//让next节点指向新table的i位置;也就是此行代码会出现循环引用的情况而导致死锁
e.next = newTable[i];
newTable[i] = e;
e = next;
//这三行代码,会让原来链表的数据首尾颠倒,猜测是作者方便进行操作,一个while循环使用三行简单几行代码便把链表遍历完成了数组的扩容
}
}
}
2.2.3 测试HashMap死锁:jdk1.7
public class MapDeadLock{
final static Map<Integer,Integer> map = new HashMap<Integer, Integer>(2);
//使用AtomicInteger 尽量让key值分散开
private static AtomicInteger atomicInteger = new AtomicInteger();
public static void main(String[] args) {
//100个线程进行put操作
for(int i=0;i<100;i++){
new Thread(new Runnable() {
@Override
public void run() {
while(atomicInteger.get()<=100000){
map.put(atomicInteger.get(),atomicInteger.get());
}
//System.out.println(map.size());
}
}).start();
}
System.out.println(map.size());
}
HashMap数据丢失问题在1.7和18都有这个问题
public class HashMapDataLost {
public static void main(String[] args) {
final Map<String, String> map = new HashMap<String, String>();
//线程一
new Thread() {
public void run() {
for (int i = 0; i < 1000; i++) {
map.put(String.valueOf(i), String.valueOf(i));
}
}
}.start();
//线程二
new Thread(){
public void run() {
for(int j=1000;j<2000;j++){
map.put(String.valueOf(j), String.valueOf(j));
}
}
}.start();
try {
Thread.currentThread().sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("map.size"+map.size());
//输出
for(int i=0;i<2000;i++){
System.out.println("第:"+i+"元素,值:"+map.get(String.valueOf(i)));
}
}
}
3 hashMap源码分析
3.1 JDK7 HashMap 源码分析

JDK7中的HashMap是一个数组,然后数组中每个元素是一个单向链表,每个元素都是一个Entry对象
Entry代码如下:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; // 成员变量
V value; //存储的值
Entry<K,V> next; // 指向下一个节点
final int hash;
// 构造函数。 初始化操作,输入参数包括哈希值(h), 键(k), 值(v), 下一节点(n)
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
3.2 JDK8 HashMap 源码分析
基础数据模型:数组+链表+红黑树
- 数组:采用一段连续的内存空间来存储数据,对于指定下标的查找,时间复杂度为O(1),通过给定的值查找需要遍历整个数组逐一对比查找则时间复杂度为O(n)
- 链表:对于链表的新增,删除等操作,仅需要处理结点间引用即可,时间复杂度为O(1)而查找链表逐一对比,复杂度为O(n)
- 哈希表:相比数组和链表结构,在哈希表中进行添加删除查找操作,性能非常高,不考虑哈希冲突的情况下,仅需要一次计算定位即可,时间复杂度为O(1)接下来我们就
- 红黑树:一种弱平衡二叉树,插入,删除比平衡二叉树要快(查询效率相对慢一些)平均复杂度均为O(logn)
1:初始化容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
2:hashMap最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
3:增长因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
4:是否转换为红黑树的阈值
static final int TREEIFY_THRESHOLD = 8;
5:为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;
3.3 JDK8中使用Node对象维护数据结构而不是Entry了
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
3.4 当发生hash碰撞的图解

3.5 put方法源码解析
/**
*将指定值与此映射中的指定键相关联。如果映射先前包含密钥的映射,则值被替换。
*与指定值关联的@param密钥
*@param value要与指定键关联的值
*@返回与键相关的上一个值,或
*如果没有键的映射,则为空。
*(Anull返回也可以指示映射
*以前与键关联的null)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
put方法中调用hash(),而hash()方法调用的是可以的hashcode()方法;在jdk8中。实现优化了高位运算的算法,通过hashCode()的高位异或低16位实现的;这个函数是从速度,效率,质量来考虑的,
3.5.1 putVal()方法源码解析
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//1:如果table为空则创建table数组;这行代码也代表了
//HashMap的table数组是延迟初始哈的;即在调用put的时候才进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
//resize:扩容的方法
n = (tab = resize()).length;
//2:计算键值对应该在table中存放index的位置,如果index位置为空
if ((p = tab[i = (n - 1) & hash]) == null)
//创建一个新节点
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//4:如果index位置不为空而且可以相等/equals相等,则覆盖原来的值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
//判断现在的数据结构是否是红黑树,如果是则直接插入
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//5:如果index位置不为空,key值为空,而且此时数据结构不是红黑树
//遍历这个链表
for (int binCount = 0; ; ++binCount) {
//链表的尾节点为空
if ((e = p.next) == null) {
//将尾节点的next属性执向到新节点
p.next = newNode(hash, key, value, null);
//判断链表的长度如果大于8则转换为红黑树进行处理
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key如果存在直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果超过了最大容量(CAPACITY*DEFAULT_LOAD_FACTOR)就扩容
if (++size > threshold)
resize();//扩容的方法
afterNodeInsertion(evict);
return null;
}
插入元素过程 (建议去看看源码)
- 如果table为空则创建table数组;这行代码也代表了,HashMap的table数组是延迟初始哈的;即在调用put的时候才进行初始化
- 计算键值对应该在table中存放index的位置,如果index位置为空
- 创建一个新节点
- 如果index位置不为空而且可以相等/equals相等,则覆盖原来的值
- 判断现在的数据结构是否是红黑树,如果是则直接插入
- 如果index位置不为空,key值为空,而且此时数据结构不是红黑树
- 遍历这个链表,遍历到链表的尾节点为空时;判断链表的长度如果大于8则转换为红黑树进行处理
- 在treeifyBin(tab, hash);方法中如果当前数组长度小于64就行进行扩容(小于64时使用红黑树没有意义)否则进行红黑树的转变
- 如果超过了最大容量(CAPACITY*DEFAULT_LOAD_FACTOR)就扩容
3.5.2 resize(); 扩容的方法源码解析
扩容方法:在向HashMap一直添加元素的时候,当达到最大容量(数组的大小乘以增长因子size>=CAPACITY*DEFAULT_LOAD_FACTOR)对象就需要扩大数组的长度;而当使用remove()方法删除时也会涉及到数组的缩容
final Node<K,V>[] resize() {
//lod指向到新的hash桶
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
//oldCap大于0 代表hash桶数组不为空
if (oldCap > 0) {
//如果大于最大容量了,就设置为整数的最大值的阈值;
//hashMap的容量是有限制的
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//如果当前hash桶数组的长度再扩容的时候仍然小于最大容量
//并且oldCap 大于初始容量16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//double threshold 双倍扩容阈值
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//新建hash桶数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//将新数组的值复制给旧的
table = newTab;
//如果就的不为空,就把旧的Node复制到新的hash桶数组
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果就的hash桶数组j位置不为空则把值赋值给e
if ((e = oldTab[j]) != null) {
//将就的j位置值赋值null,方便gc
oldTab[j] = null;
//如果e的next节点为空
if (e.next == null)
//直接使用e节点的hash值和新的存储数量计算新的存储位置
newTab[e.hash & (newCap - 1)] = e;
//如果e是红黑树类型;就添加到红黑树中
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
//将node节点的next赋值给next
next = e.next;
//如果节点e的hash值与原有旧的hash桶数组长度计算为0
if ((e.hash & oldCap) == 0) {
if (loTail == null)
//将e节点赋值给loHead
loHead = e;
else
//否则将值赋值给loTail.next
loTail.next = e;
loTail = e;
}
else {//如果节点e的hash值与原有旧的hash桶数组长度计算不为0
//hiTail为null
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
//循环直到e为空跳出
} while ((e = next) != null);
if (loTail != null) {
//将loTail.next赋值null
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
//将hiHead赋值给新的hash桶数组
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
在jdk8中HashMap扩容的时候不在像jdk7中 重新计算hash,只需要判断与掩码计算新增的那个bit是否为0还是1;如果是0代表索引没变;如果是1索引就变成 原有索引值+oldCap;红色线代表计算0后索引位置没有变;黑色线代表1索引就变成 原有索引值+oldCap
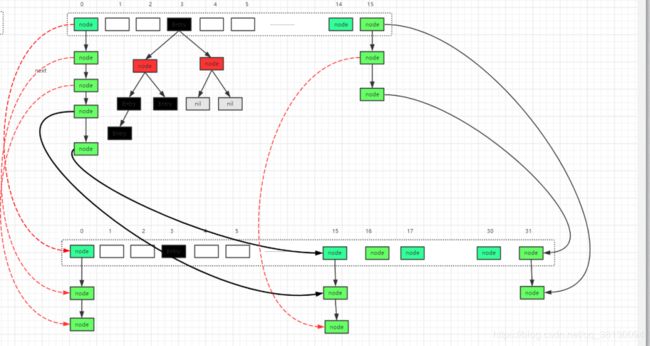
4 ConcurrentHashMap源码分析
4.1 jdk7 ConcurrentHashMap源码分析
jdk1.7和jdk8实现是不一样的,
- HashMap是线程非安全,在以前使用hashTable实现线程安全的,但是HashTable是通过在方法上加Synchronized关键字,相当与说有读写线程都在使用了同一把锁,从而无法实现较高的并发;
HashTable与ConncurrentHashMap根本的区别就是:两者的并发的度不同(锁粒度不同) - 使用Collections工具的synchronizedMap实现线程安全
public class Collections {
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
//使用对象锁进行加锁
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {synchronized (mutex) {return m.size();}}
public boolean isEmpty() { synchronized (mutex) {return m.isEmpty();}}
public boolean containsKey(Object key) {synchronized (mutex) {return m.containsKey(key);}}
public boolean containsValue(Object value) {synchronized (mutex) {return m.containsValue(value);} }
public V get(Object key) { synchronized (mutex) {return m.get(key);}}
public V put(K key, V value) {synchronized (mutex) {return m.put(key, value);}}
public V remove(Object key) { synchronized (mutex) {return m.remove(key);} }
public void putAll(Map<? extends K, ? extends V> map) { synchronized (mutex) {m.putAll(map);}}
public void clear() {synchronized (mutex) {m.clear();}}
}
核心源代码:
ConcurrentHashMap可以做到在读取数据的时候不加锁,并且内部结构可以让其在进行写操作的时候将锁的粒度保持尽量小,不用对整个ConcurrentHashMap加锁;
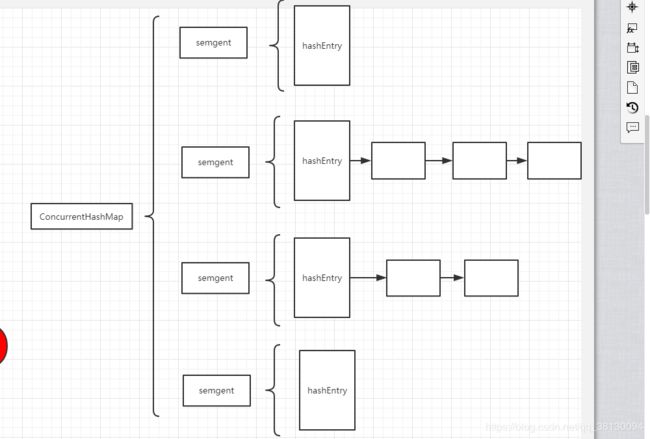
ConcurrentHashMap比hashMap多了一次hash的过程,第一次定位到segment,第二次hash定位到HashEntry,然后链表搜索节点;通过对segment加锁即可其他无锁从而提高并发读写效率
Segment继承了ReentrantLock 从而
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//volatile 修饰内存可见性
transient volatile HashEntry<K,V>[] table;
transient int count;
/**
* The total number of mutative operations in this segment.
* Even though this may overflows 32 bits, it provides
* sufficient accuracy for stability checks in CHM isEmpty()
* and size() methods. Accessed only either within locks or
* among other volatile reads that maintain visibility.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always (int)(capacity *
* loadFactor).)
*/
transient int threshold;
}
构造器:
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//判断最大容量
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
//
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
//初始化sement数组
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
ConcurrentHashMap 的put()方法源代码解析
@SuppressWarnings("unchecked")
public V put(K key, V value) {
Segment<K,V> s;
//velue不能为空
if (value == null)
throw new NullPointerException();
//计算hash函数
int hash = hash(key);
//
int j = (hash >>> segmentShift) & segmentMask;
//获取的segment为null
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
//更急计算的hash值放入值
return s.put(key, hash, value, false);
}
Segment 的put的方法
这是真正放入数据的方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
4.2 jdk8 ConcurrentHashMap源码分析
哈希桶数组
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node<K,V>[] table;
/**
* The next table to use; non-null only while resizing.
*/
private transient volatile Node<K,V>[] nextTable;
4.2.1 存储数据的结构 Node及 TreeNode
内部类Node用于存储数据:只允许数据查找,而不允许数据查找
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
//node节点是不允许更新的,他是通过上述的构造器更新的
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
TreeNode继承自Node但是数据结构已经转变为二叉树结构,他是红黑树的存储结构,当链表的数据节点大于8时会转变成红黑树,也就是通过TreeNode存储结构代替Node来转换的成红黑树的
/**
* Nodes for use in TreeBins
*/
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next,
TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
}
TreeBin : 虽然有treeNode的对象,但是 是通过treeBin 来操作treeNode的
TreeBin(TreeNode<K,V> b) {
super(TREEBIN, null, null, null);
this.first = b;
TreeNode<K,V> r = null;
}
核心源代码
ForwardingNode的作用就是支持扩容操作;将已处理的节点和空节点置为ForwardingNode,并发处理多个线程进ForwardingNode就表示已经遍历过了
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
}
put() 方法源码解析
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//key值不能为null,否则会抛出异常
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
//遍历table
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//这里就是上面构造器方法没有进行初始化,在这里进行判断
//为null就调用initTable进行初始化属于延迟加载
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//CAS插入
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果在扩容,就对齐进行帮助扩容
//helpTransfer() 核心方法 多线程协同,多用心看
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
//判断到这后代表以上条件都不满足,那就要进行加锁操作
//代表存在hash冲突,锁住链表或者红黑树(锁住链表的头结点或红黑书树的根节点)
V oldVal = null;
//通过synchronized 锁住
synchronized (f) {
if (tabAt(tab, i) == f) {
//节点为链表结构
if (fh >= 0) {
binCount = 1;
//链表常规操作
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
//判断这个值是否需要覆盖
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//插入链表的尾部
if ((e = e.next) == null) {
//成为新的尾部节点
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//红黑树结构
//通过红黑树构造调整
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//如果链表的长度大于8就会进行红黑树转换
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//是否需要扩容
addCount(1L, binCount);
return null;
}
put的过程:
- 如果没有初始化就调用initTable()方法进行初始化过程
- 如果没有hash冲突就直接CAS插入
- 如果还在进行扩容操作就进行扩容
- 如果存在Hash冲突,就加锁来保证线程安全(区别链表和红黑树的结构)
- 最后一个如果该链表的数量大于阈值8;就要先转换为红黑树的结构,breadk再循环一次
- 如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
helpTransfer ()方法
helpTransfer 就是帮助 转移 (帮助从旧的table的元素复制到新的table中)
体现了和hashmap 的不同当ConcurrentHashMap正在扩容的时候其他线程是不能插入元素的; 多线程并发的情况下提升扩容的效率
在扩容的时候其他线程是无法插入新元素的
//帮助从旧的table的元素复制到新的table中
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
多线程协同工作