CNN搭建端到端的验证码识别系统
卷积神经网络验证码识别
深度学习大行其道的一个重要原因,是算力的提升,技术的进步允许我们每个人都自由地使用个人PC训练强大的神经网络。神经网络的强大能力有效地辅助了我们开发各类新式软件,举个例子,原本的一整套语音识别系统,需要一个pipeline的多种算法协同工作才能发挥作用。我们要先预处理语音,过滤噪声和背景;然后把语音分割成一个一个音节;然后使用HMM等模型识别语音。而如果使用深度学习的方法,我们只需要把语音信号丢入一个LSTM,使用端到端的训练方法,就能得到一个效果更好的语音识别系统。
这种端到端的设计理念震撼了每个曾经致力于传统CV算法和NLP算法的研究者,今天的图像和自然语言处理领域,深度学习神经网络已经占据了重要的地位。这里我们做一个非常简单的例子,来实现一个验证码的识别系统。
数据集速览与任务目标
我们使用的验证码数据集是一种有噪声的5位数字+字母验证码数据集,共1k余张有标签图片。


虽然对人类来说,辨识出这些字符比较容易,但是对机器来说还是有些困难的。对机器而言最困难的一步,就是分割字符;如果字符之间无粘连,我们或许可以靠连通域搜索完成图片分割。而这里的图片总有一条额外的线条连接各字符,让我们无法顺利完成分割。除此之外,有些字符被实施了虚化的效果,这也让这些字符对机器而言是更加难以理解的。
综上,使用传统的pipeline(滤波去噪-二值化-分割-识别)完成字符识别是相当困难的。但是如果我们用神经网络做这个事情,任务将不那么困难。
我们将搭建一个CNN,它的输入就是我们上面的这些图片,输出将是5*(10+26)=180的向量,表示5个字符,分别为0~9,a ~z的几率。
模型与损失函数
这里使用简单的8层卷积ResNet架构,不了解ResNet是什么的同学可以自行搜索。
class CNN(nn.Module):
def conv_block(self, in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(out_channels),
nn.Conv2d(in_channels=out_channels,out_channels=out_channels,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
)
def upsample_block(self, in_channels,out_channels):
return nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=1)
def __init__(self, residual = True):
super().__init__()
# 1*64*200
self.conv1 = self.conv_block(1,32)
self.upsample1 = self.upsample_block(1,32)
# 32*32*100
self.conv2 = self.conv_block(32,64)
self.upsample2 = self.upsample_block(32,64)
# 64*16*50
self.conv3 = self.conv_block(64,128)
self.upsample3 = self.upsample_block(64,128)
# 128*8*25
self.conv4 = self.conv_block(128,256)
self.upsample4 = self.upsample_block(128,256)
# 256*4*12
self.maxpool = nn.MaxPool2d(kernel_size = 2)
self.avgpool = nn.AvgPool2d(kernel_size = 2)
self.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256*4*12,ALL_CHAR_SET_LEN*MAX_CAPTCHA)
)
self.residual = residual
def forward(self,x):
if self.residual:
x = self.maxpool(self.conv1(x)+self.upsample1(x))
x = self.maxpool(self.conv2(x)+self.upsample2(x))
x = self.avgpool(self.conv3(x)+self.upsample3(x))
x = self.avgpool(self.conv4(x)+self.upsample4(x))
else:
x = self.maxpool(self.conv1(x))
x = self.maxpool(self.conv2(x))
x = self.maxpool(self.conv3(x))
x = self.maxpool(self.conv4(x))
x = x.reshape(x.size(0),-1)
x = self.fc(x)
return x
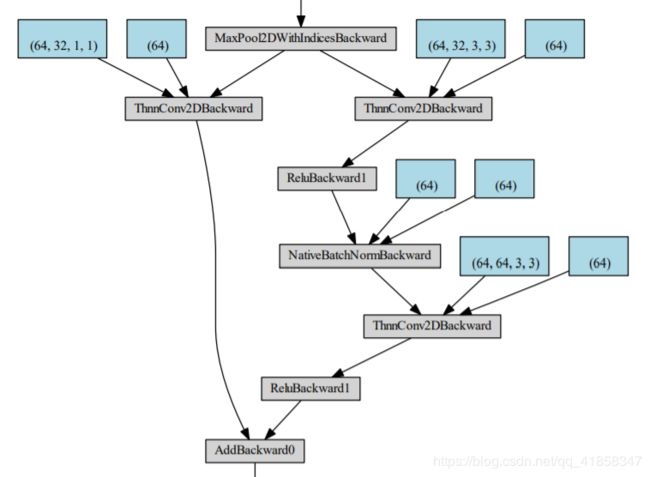
其中一个residual block的可视化如下;可以看见,输入residual block的数据会分成两条路,一条经过卷积,另一条进行跨越连接,直接和后面的输出相加。
损失函数的设计实际上不唯一,我们可以对上面的5个字符分别call crossentropyloss,也可以用一种更加通用的多分类损失函数,MLSM Loss
你也可以运行下面的代码简单观察数据在模型中的运算流程
model = CNN(residual = True)
from torchsummary import summary
summary(model, (1,64,200), batch_size=5, device='cpu')
训练
在家没有显卡用,这个实验是用colab做的。尽管这个resnet只有8层,但是想train到一个很低的loss还是需要一些额外的训练技巧。我们使用学习率衰减的Adam优化器训练
def train(model, train_loader, loss_func, optimizer, device):
model.train()
total_loss = 0
for i, (images, targets, _) in enumerate(train_loader):
images = images.to(device)
targets = targets.to(device)
outputs = model(images)
loss = loss_func(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if (i + 1) % 5 == 0:
print ("Step [{}/{}] Train Loss: {:.4f}"
.format(i+1, len(train_loader), loss.item()))
return total_loss / len(train_loader)
def decode(label_oh):
captcha = ""
for i in range(MAX_CAPTCHA):
s = ALL_CHAR_SET_LEN*i
e = s+ALL_CHAR_SET_LEN
ch_onehot = label_oh[s:e]
idx = torch.argmax(ch_onehot).item()
captcha += ALL_CHAR_SET[idx]
return captcha
def evaluate(model, test_loader, device):
model.eval()
Tr = 0.
Tot = len(test_loader)
for step, (img, label_oh, label) in enumerate(test_loader):
img = img.to(device)
pred = model(img)[0]
s = decode(pred)
Tr += int(label[0]==s)
print("accuracy: %.3f%%"%(Tr/Tot*100))
def update_lr(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def fit(model, num_epochs, optimizer, device):
loss_func = nn.MultiLabelSoftMarginLoss()
model.to(device)
loss_func.to(device)
for epoch in range(num_epochs):
if epoch==20:
update_lr(optimizer, 0.0005)
if epoch==40:
update_lr(optimizer, 0.00001)
print('Epoch {}/{}:'.format(epoch + 1, num_epochs))
loss = train(model, train_loader, loss_func, optimizer, device)
evaluate(model, test_loader, device)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
fit(model, num_epochs=60, optimizer=optimizer, device=device)
可以观察到的是,训练的末期将能得到85%以上的测试集正确率。
结果
import matplotlib.pyplot as plt
%matplotlib inline
model.eval()
Tr = 0.
Tot = len(test_loader)
for step, (img, label_oh, label) in enumerate(test_loader):
img = img.to(device)
pred = model(img)[0]
s = decode(pred)
plt.imshow(img[0,0].cpu().detach().numpy(),cmap = plt.cm.gray)
plt.show()
print('Prediction:',s)
print('Label:',label[0])
观察测试集上的预测情况,效果如下图


尽管偶然会有出错,但是仍然有着相当稳定的准确率。如果需要更好的表现,或许你需要考虑更好的卷积网络架构(比如直接拿ResNet18做fine tune),或者使用专业的OCR模型CRNN,甚至你可以先用一个滑动窗口神经网络模型或FCN语义分割模型做字符级别的分割,再搭建字符级的CNN识别字符,我认为这都是可行的,等待你尝试。
如果需要数据集和源代码可以私信本人