Soot 静态分析框架(六)数据流指向分析
1. 数据流指向分析
1.1 指向分析
指向分析,给定一个变量的函数,计算其可能的类型,指向信息,指向分析可以帮助其它的分析。
1.2 Soot的指向分析框架
soot提供了PointsToAnalysis ,PointsToSet接口。任何一个指向的分析都应该实现这两个接口。
PointsToAnalysis 方法reachingObjects(Local l),该方法可以返回指向参数l 的对象集合PointsToSet,通过PointsToSet可以用来获取与其他PointsToSets的非空交集,同时可以获取这些对象所有可能的运行时的类型。这些方法对于实现别名分析,以及虚方法的分配很有用。通过使用Scene.v().getPointsToAnalysis()获取框架使用的PointsToAnalysis
soot提供了三种points-to 接口的实现
- CHA(简单版本,全面,不够精确) 构造出来的不准确但全面的指向信息是有一定的价值的。常用的是建立一个不准确的call graph,来作为精确call graph构造的起点
- SPARK
- Paddle
SPARK和Paddle提供了精确的分析,代价是复杂的设置,以及速度的损失。
1.3 Spark 实现
下面主要介绍Spark的实现
1.3.1 Spark分析的参数
Spark的相关分析能够在soot.jimple.spark.* 包中找到。指向分析的相关参数可以通过配置options来实现
| Options.v().set_whole_program(true); Options.v().setPhaseOption("cg.spark", "on"); Options.v().setPhaseOption("cg.spark", "verbose:true"); Options.v().setPhaseOption("cg.spark", "enabled:true"); Options.v().setPhaseOption("cg.spark", "propagator:worklist"); Options.v().setPhaseOption("cg.spark", "simple-edges-bidirectional:false"); Options.v().setPhaseOption("cg.spark", "son-fly-cg:true"); Options.v().setPhaseOption("cg.spark", "double-set-old:hybrid"); Options.v().setPhaseOption("cg.spark", "double-set-new:hybrid"); Options.v().setPhaseOption("cg.spark", "set-impl:double"); Options.v().setPhaseOption("cg.spark", "simple-edges-bidirectional:false"); |
可以看到上述的参数,Spark的分析过程是在CG Pack中,而Spark的分析本质上就是一个Transform,关于Pack和Transform相关的请参考前面的章节
入口就是SparkTransformer
1.3.2 Spark 中的OnflyCallGraph
在SparkTransformer中internalTransform函数中,使用了
ContextInsensitiveBuilder来构建PAG 就是指针指向图
|
protected void internalTransform(String phaseName, Map SparkOptions opts = new SparkOptions(options); final String output_dir = SourceLocator.v().getOutputDir();
// Build pointer assignment graph ContextInsensitiveBuilder b = new ContextInsensitiveBuilder(); if (opts.pre_jimplify()) { b.preJimplify(); } if (opts.force_gc()) { doGC(); } Date startBuild = new Date(); final PAG pag = b.setup(opts); b.build(); Date endBuild = new Date(); reportTime("Pointer Assignment Graph", startBuild, endBuild); …. |
当你设置了on-fly-cg为true, Spark会使用更详细的On-fly-call-graph来分析,如果没有设置,会使用CHA 近似的Call-graph进行分析

On-fly-cg 和在前面提到的CallGraph并不相同,OnFlyCallGraph里面包含了CallGraph,在构建OnFlyCallGraph的时候会首先构建CallGraph实体, 通过OnFlyCallGraphBuilder去构建CallGraph, 如果没有设置参数On-fly-call-graph,会使用CallGraphBuilder去构建CallGrph,从代码来看CallGraphBuilder也是通过OnFlyCallGraphBuilder去构建CallGraph,
OnFlyCallGraph可以直接获取到callgraph。获取callgraph 的目的主要是为了获取Edge.
1.3.3 Spark 的MethodPAG
MethodPAG全称就是分析函数内部的指针,和Sootmethod不同的是这里只是分析函数内部的指针操作,用于构建PAG 的Edge的关系。
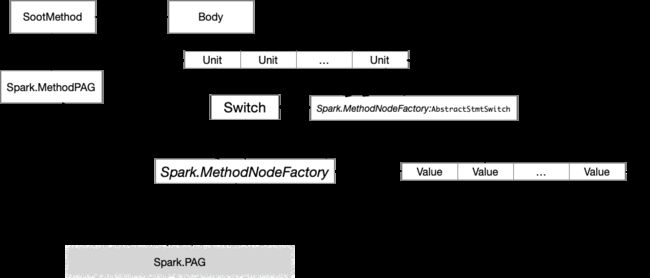
MethodPAG 通过SootMethod获取到Jimple的Body里的Unit链,进行每个Unit的分析, 在前面的分析中Unit里面包含着Value,如何融合到分析过程中?因为Unit 也就是Stmt的类型非常多,如果要分析的化需要对每个Stmt进行分析,为了逻辑的简单方便,Unit,Value都提供了Apply的方法,而操作的对象就是Switch,只要直接实现switch的接口,在switch里面实现每个stmt的case就可以直接实现逻辑。
也就是MethodNodeFactory和MethodFactory:abstractStmtSwitch分别实现了switch的方法用来实现对Unit, Value的解析
1.3.4 Spark 的Node
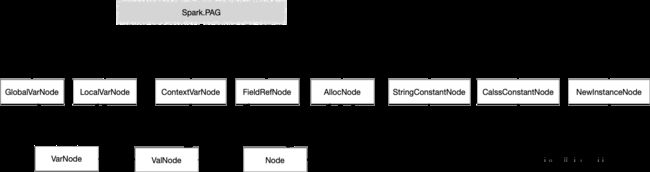
Spark中的PAG里面的每个参数就是Node,通过Node里面去封装Soot里的Value, 我们可以看到这里有很多的Node类型,VarNode,ValNode比较容易理解在类似scala里定义的var是可以修改的,而val是不可以修改的。
GlobalVarNode: 常量,静态Field引用 比如:常见的String常量本身就是一个GlobalVarNode
LocalVarNode: 函数内部变量
ContextVarNode: SootMethod 的Context,Spark是上下文不敏感的为Null
FieldRefNode: 引用的field,里面的base指向被引用的Node
AllocNode: new 初始化的节点
StringConstantNode:String的常量
ClassConstantNode: Class.forName 的Class名字
NewInstanceNode: Class.newInstance的对象,但不包含Constract的newinstance
1.3.5 Spark的 TypeManager
Spark里会同步构建Type和Node之间的关系

关于Type文件前面的部分里已经介绍,通过LargeNumberedMap构建Type和Node的关系,为了更快的链接Node,并没有构建node的collection的关系,而只是使用了Bit位来标识Node,而Type,Node都会构建存在一个唯一的Number,LargeNumberedMap只是一个数组关系,type的number就是数组的下标,Node的number是BitVector的bit位,number的生成Node,Type都一样,通过ArrayNumberer来add的时候生成,实际上就是数组的lastnumber。
1.3.6 Spark PKG中的edge
PKG分成了几种关系的edge
- store: field的赋值,例如FieldRefNode (to) = VarNode(from)
- load: 获取field的值,例如VarNode(to) = FieldRefNode(from)
- alloc: 初始化的对象,例如:VarNode(to) = AllocNode(from)
- newInstance: Class.newInstance的对象,例如:VarNode(to) = NewInstanceNode(from)
- assignInstance: Class.newInstance的对象赋值,例如:VarNode(to) = NewInstanceNode(from)
- simple: 函数内部赋值,例如:VarNode(to) = VarNode (from)
每一个关系都以Map保存from与多个to 的关系

为了逆向分析,同时也保存了 to 与多个from的关系,思路是一样的,反过来构建多个反向关系的Map