Python爬虫实战:淘宝购物车
参考文档:
https://blog.csdn.net/qq_42196922/article/details/85337709
https://www.cnblogs.com/TianFang/p/9059978.html
环境:Python3.6
IDE:PyCharm
浏览器:Chrome/73.0.3683.75
爬虫技术更新太快了,之前很多方法都失效了,查了很久资料,存储部分,方便自查使用,若有侵权,请及时联系删除,谢谢!
一、根据cookie登陆获取信息
该方法简单,但时效很短,原来一个cookie可以一两天使用,现在估计也就半小时吧
方法:
在已登陆的浏览器中从开发者工具中找到该页面的实时cookie,以Chrome浏览器为例:
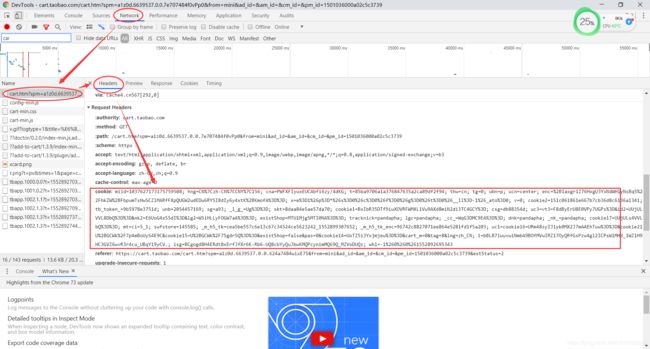
复制此处的cookie,然后在代码中替换cookie值即可
import requests
import re
from pandas import DataFrame
url='https://cart.taobao.com/cart.htm?spm=a21bo.2017.1997525049.1.5af911d9eMYuVO&from=mini&pm_id=1501036000a02c5c3739'
#头部信息
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'cookie':'miid=1037627173175759508; hng=CN%7Czh-CN%7CCNY%7C156; cna=PWFXFIyuxEUCAbfi6zy/4dKG; t=85ba9706a1a376847635a2ca89df2f94; thw=cn; tg=0; ubn=p; ucn=center; enc=%2B1axgr1Z76HxgU3YxNdWHlyNsBq5%2F%2FhkZW%2BFbpumTsHwSCZlMARfFXpQUGW2udEDu6RY5I8dIy6y4xtK%2BKmofA%3D%3D; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; _m_h5_tk=190b7279ca028eb45ac4d7d8b5494cd2_1552886731048; _m_h5_tk_enc=f784ba38d5fb562485e7271157e4ec8d; v=0; cookie2=151c061861e667b7cb36d8c6136a1341; _tb_token_=9b5978e3751d; unb=2054457169; sg=a93; _l_g_=Ug%3D%3D; skt=8daa84e5ae57da70; cookie1=BxIbR35DTf9iuXOVRFWMXL1Vu9AXd8miN2di3TC4GCY%3D; csg=db88354d; uc3=vt3=F8dByErU8E0VPy7UGPs%3D&id2=UUjULs4VVL8DbQ%3D%3D&nk2=E6UoG4xS5dI%3D&lg2=W5iHLLyFOGW7aA%3D%3D; existShop=MTU1Mjg5MTI0NA%3D%3D; tracknick=pandapha; lgc=pandapha; _cc_=WqG3DMC9EA%3D%3D; dnk=pandapha; _nk_=pandapha; cookie17=UUjULs4VVL8DbQ%3D%3D; mt=ci=5_1; uc1=cookie16=UtASsssmPlP%2Ff1IHDsDaPRu%2BPw%3D%3D&cookie21=VFC%2FuZ9aiKCaj7AzMHh1&cookie15=Vq8l%2BKCLz3%2F65A%3D%3D&existShop=false&pas=0&cookie14=UoTZ5i3Yxj8VaA%3D%3D&cart_m=0&tag=8&lng=zh_CN; swfstore=145585; l=bBLB7lwuvwiNmTBkBOCMCuIRZ17OQIRAguPRw4mXi_5wv6L1SXbOl6b25Fp6Vj5R_WLp4orbVwy9-etks; isg=BJCQTj6C-Jx7WaQcBep3FpYSYd4i8bzEiT6aOophQuu-xTBvM2toMu__mc2AFSx7; whl=-1%260%260%261552891252421'
}
#请求
r=requests.get(url,headers=headers)
#改变编码
r.encoding='gbk'
file=open('C:/Users/Shinelon/Desktop/Taobao.txt','w',encoding='utf-8') #定义文件
file.write(r.text) #写入文件
file.close()
df=DataFrame(columns=['书名']) #定义数据结构
t=re.findall(r'"skuStatus":0,"title":"(.*?)"',r.text)
df['书名']=t
print(df)
df.to_csv('书名.csv')
二、模拟登陆,获取信息
该方法较之前方法复杂得多,但可以实现自动化,具体原理请参考如何解决selenium被检测,实现淘宝登陆
import asyncio
import time, random
from pyppeteer.launcher import launch # 控制模拟浏览器用
from retrying import retry # 设置重试次数用的
import re
async def main(username, pwd, url): # 定义main协程函数,
# 以下使用await 可以针对耗时的操作进行挂起
browser = await launch({'headless': False, 'args': ['--no-sandbox'], }) # 启动pyppeteer 属于内存中实现交互的模拟器
page = await browser.newPage() # 启动个新的浏览器页面
await page.setUserAgent(
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36')
await page.goto(url) # 访问登录页面
# 替换淘宝在检测浏览时采集的一些参数。
# 就是在浏览器运行的时候,始终让window.navigator.webdriver=false
# navigator是windiw对象的一个属性,同时修改plugins,languages,navigator 且让
await page.evaluate(
'''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''') # 以下为插入中间js,将淘宝会为了检测浏览器而调用的js修改其结果。
await page.evaluate('''() =>{ window.navigator.chrome = { runtime: {}, }; }''')
await page.evaluate('''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }''')
await page.evaluate('''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }''')
# 使用type选定页面元素,并修改其数值,用于输入账号密码,修改的速度仿人类操作,因为有个输入速度的检测机制
# 因为 pyppeteer 框架需要转换为js操作,而js和python的类型定义不同,所以写法与参数要用字典,类型导入
await page.click('#J_Quick2Static')#点击账号密码登陆模块
await page.type('.J_UserName', username, {'delay': input_time_random() - 50})
await page.type('#J_StandardPwd input', pwd, {'delay': input_time_random()})
# await page.screenshot({'path': './headless-test-result.png'}) # 截图测试
time.sleep(2)
# 检测页面是否有滑块。原理是检测页面元素。
slider = await page.Jeval('#nocaptcha', 'node => node.style') # 是否有滑块
print('slider:',slider)
if slider:
print('当前页面出现滑块')
# await page.screenshot({'path': './headless-login-slide.png'}) # 截图测试
flag, page = await mouse_slide(page=page) # js拉动滑块过去。
if flag:
await page.keyboard.press('Enter') # 确保内容输入完毕,少数页面会自动完成按钮点击
print("print enter", flag)
await page.evaluate('''document.getElementById("J_SubmitStatic").click()''') # 如果无法通过回车键完成点击,就调用js模拟点击登录按钮。
time.sleep(2)
# cookies_list = await page.cookies()
# print(cookies_list)
await get_cookie(page) # 导出cookie 完成登陆后就可以拿着cookie玩各种各样的事情了。
await get_books(page)
else:
print("")
await page.keyboard.press('Enter')
print("print enter")
await page.evaluate('''document.getElementById("J_SubmitStatic").click()''')
await page.waitFor(20)
await page.waitForNavigation()
try:
global error # 检测是否是账号密码错误
print("error_1:", error)
error = await page.Jeval('.error', 'node => node.textContent')
print("error_2:", error)
except Exception as e:
error = None
finally:
if error:
print('确保账户安全重新入输入')
# 程序退出。
loop.close()
else:
print(page.url)
await get_cookie(page)
time.sleep(1000)
# 获取登录后cookie
async def get_cookie(page):
# res = await page.content()
cookies_list = await page.cookies()
cookies = ''
for cookie in cookies_list:
str_cookie = '{0}={1};'
str_cookie = str_cookie.format(cookie.get('name'), cookie.get('value'))
cookies += str_cookie
print('print cookies',cookies)
return cookies
#获取登陆后的content
async def get_books(page):
# res = await page.content()
conten_list = await page.content()
str=re.findall(r'"skuStatus":0,"title":"(.*?)"',"".join(conten_list))
file = open('C:/Users/Shinelon/Desktop/Taobao.txt', 'w+', encoding='utf-8')
print('That is ok')
print(str)
file.write("".join(str))
file.close()
# cookies = ''
# for cookie in cookies_list:
# str_cookie = '{0}={1};'
# str_cookie = str_cookie.format(cookie.get('name'), cookie.get('value'))
# cookies += str_cookie
# print('print cookies',conten_list)
return conten_list
def retry_if_result_none(result):
return result is None
@retry(retry_on_result=retry_if_result_none, )
async def mouse_slide(page=None):
await asyncio.sleep(2)
try:
# 鼠标移动到滑块,按下,滑动到头(然后延时处理),松开按键
await page.hover('#nc_1_n1z') # 不同场景的验证码模块能名字不同。
await page.mouse.down()
await page.mouse.move(2000, 0, {'delay': random.randint(1000, 2000)})
await page.mouse.up()
except Exception as e:
print(e, ':验证失败')
return None, page
else:
await asyncio.sleep(2)
# 判断是否通过
slider_again = await page.Jeval('.nc-lang-cnt', 'node => node.textContent')
if slider_again != '验证通过':
return None, page
else:
# await page.screenshot({'path': './headless-slide-result.png'}) # 截图测试
print('验证通过')
return 1, page
def input_time_random():
return random.randint(100, 151)
if __name__ == '__main__':
username = 'username' # 淘宝用户名
pwd = 'password' # 密码
url = 'https://cart.taobao.com/cart.htm?spm=a1z02.1.1997525049.1.3372782dc0fDWE&from=mini&pm_id=1501036000a02c5c3739'
loop = asyncio.get_event_loop() # 协程,开启个无限循环的程序流程,把一些函数注册到事件循环上。当满足事件发生的时候,调用相应的协程函数。
loop.run_until_complete(main(username, pwd, url)) # 将协程注册到事件循环,并启动事件循环
若要添加点击、填写等人为操作,可自行编写代码实现,附上page对象的使用方法:使用Puppeteer进行数据抓取(二)——Page对象