04 graphx 从源节点到其他节点的路径 scala & java 版本
前言
呵呵 最近刚好有一些需要使用到 图的相关计算
然后 需求是 需要计算图中 源点 到 目标节点 的所有路径
另外本文会提供一个 scala 版本的测试用例, 以及 一个 java 版本的测试用例(写的有点惨)
环境如下 : spark2.4.5 + scala2.11 + jdk8
java 版本的代码基于 : spark-graphx_2.12 2.4.6
另外 java 版本的代码, 会遇到各种问题, 这里也会 介绍一下(写出来也是很不美观, 可读性也不太好)
本文的图的样例 基于 03 graphx 从 SSSP 来看 pregel 的图
测试用例
package com.hx.test01
import org.apache.spark.graphx.{Edge, EdgeDirection, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.control.Breaks._
/**
* Test4AllPaths
*
* @author Jerry.X.He <[email protected]>
* @version 1.0
* @date 2020/6/18 20:53
*/
object Test4AllPaths {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Test02SSSP")
val sc = new SparkContext(conf)
val sourceId: VertexId = 0 // The ultimate source
// 创造一个边的RDD, 包含各种关系
val edges: RDD[Edge[Double]] = sc.parallelize(Array(
Edge(3L, 7L, 1.0d),
Edge(5L, 3L, 1.0d),
Edge(2L, 5L, 1.0d),
Edge(5L, 7L, 1.0d),
Edge(0L, 3L, 1.0d),
Edge(3L, 2L, 1.0d),
Edge(7L, 9L, 1.0d),
Edge(0L, 5L, 1.0d)
))
// 创造一个点的 RDD
val vertexes: RDD[(VertexId, (Double, Seq[Seq[VertexId]]))] = edges
.flatMap(edge => Array(edge.srcId, edge.dstId))
.distinct()
.map(id =>
if (id == sourceId) (id, (0, Seq[Seq[VertexId]](Seq[VertexId](sourceId))))
else (id, (Double.PositiveInfinity, Seq[Seq[VertexId]]()))
)
val defaultVertex = (-1.0d, Seq[Seq[VertexId]]())
// A graph with edge attributes containing distances
val initialGraph: Graph[(Double, Seq[Seq[VertexId]]), Double] = Graph(vertexes, edges, defaultVertex)
println(" edges as follow : ")
initialGraph.edges.foreach(println)
val sssp = initialGraph.pregel((Double.PositiveInfinity, Seq[Seq[VertexId]]()), Int.MaxValue, EdgeDirection.Out)(
// Vertex Program
(id, dist, newDist) => (Math.min(dist._1, newDist._1), dist._2.union(newDist._2).distinct),
// Send Message
triplet => {
// if is `Double.PositiveInfinity`, return
if (triplet.srcAttr._1 > Double.MaxValue - 1) {
Iterator.empty
// if is edge to self, return
} else if (triplet.srcId == triplet.dstId) {
Iterator.empty
} else {
val paths = triplet.srcAttr._2
val isSourceNode = paths.forall(_.size == 1)
val allExists = paths.forall(_.contains(triplet.dstId))
val containCircle = paths.foldLeft(false)((result, path) => result || (path.contains(triplet.srcId) && path.contains(triplet.dstId)))
// 如果不是源节点, 并且 存在cycle 或者 目标节点在所有路径都存在, return
if (!isSourceNode && (allExists || containCircle)) {
// if(triplet.srcAttr._1 > 100) {
Iterator.empty
// 当前所有路径 + 目标节点, 传递消息给 目标节点
} else {
var newSeqList = Seq[Seq[VertexId]]()
triplet.srcAttr._2.foreach(seq => {
if (!(seq.contains(triplet.srcId) && seq.contains(triplet.dstId))) {
newSeqList = newSeqList :+ (if (seq.contains(triplet.dstId)) seq else seq :+ triplet.dstId)
}
})
Iterator((triplet.dstId, (triplet.srcAttr._1 + triplet.attr, newSeqList)))
}
}
},
//Merge Message
(a, b) => (Math.min(a._1, b._1), (a._2.union(b._2).distinct)))
println(sssp.vertices.collect().foreach(entry => {
println(s" vertex : ${entry._1}, sssp : ${entry._2._1}, pathLength : ${entry._2._2.size}, paths : ${entry._2._2} ")
}))
printMaxPathLength(sssp)
}
/**
* 打印到各个节点路径中, 最长的路径对应的节点 以及 路径长度
*
* @param sssp sssp
* @return void
* @author Jerry.X.He
* @date 2020/6/19 21:26
* @since 1.0
*/
def printMaxPathLength(sssp: Graph[(Double, Seq[Seq[VertexId]]), Double]): Unit = {
var maxLength = 0
var pair: (VertexId, Int) = null
for (entry <- sssp.vertices.collect()) {
val pathList = entry._2._2
breakable {
if (pathList.isEmpty) {
break
}
val maxPath = pathList.sortBy(_.size).reverse.head
if (maxPath.size > maxLength) {
maxLength = maxPath.size
pair = (entry._1, maxLength)
}
}
}
println(pair)
}
}
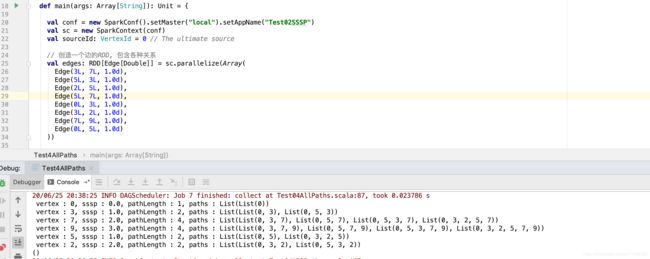
执行结果如下图, 统计了 0 到其他节点的 所有的路径, 以及最短路径长度
java 版本
package com.hx.test06;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.graphx.Edge;
import org.apache.spark.graphx.EdgeDirection;
import org.apache.spark.graphx.EdgeTriplet;
import org.apache.spark.graphx.Graph;
import org.apache.spark.rdd.RDD;
import org.apache.spark.storage.StorageLevel;
import scala.Function1;
import scala.Function2;
import scala.Function3;
import scala.Tuple2;
import scala.collection.Iterator;
import scala.collection.mutable.ArrayStack;
import scala.reflect.ClassTag;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* Test27AllPaths
*
* @author Jerry.X.He <[email protected]>
* @version 1.0
* @date 2020-06-20 11:29
*/
public class Test27AllPaths {
// Test27AllPaths
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("Test27AllPaths");
SparkContext sc = new SparkContext(conf);
// Graph graph = GraphGenerators.rmatGraph(sc, 10, 20);
Long sourceId = 0L;
ArrayStack> edges = new ArrayStack<>();
edges.push(new Edge(3L, 7L, 1.0d));
edges.push(new Edge(5L, 3L, 1.0d));
edges.push(new Edge(2L, 5L, 1.0d));
edges.push(new Edge(5L, 7L, 1.0d));
edges.push(new Edge(0L, 3L, 1.0d));
edges.push(new Edge(3L, 2L, 1.0d));
edges.push(new Edge(7L, 9L, 1.0d));
edges.push(new Edge(0L, 5L, 1.0d));
Set vertexSet = new HashSet<>();
edges.foreach(edge -> {
vertexSet.add(edge.srcId());
vertexSet.add(edge.dstId());
return null;
});
ArrayStack>>>> vertexAndInfoList = new ArrayStack<>();
for (Long vertexId : vertexSet) {
Tuple2 vertexInfo = new Tuple2(Double.MAX_VALUE, new ArrayList<>());
if (vertexId.equals(sourceId)) {
List> sourcePathList = new ArrayList<>();
List 可以看到, 代码 非常之 ...(难以言说)
测试结果如下

java 版本遇到的一些问题
1. 为什么 vprog, sendMsg, mergeMsg 要写成单独的类

Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:416)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:406)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:163)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2326)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$1(RDD.scala:820)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.mapPartitions(RDD.scala:819)
at org.apache.spark.graphx.impl.VertexRDDImpl.mapVertexPartitions(VertexRDDImpl.scala:96)
at org.apache.spark.graphx.impl.GraphImpl.mapVertices(GraphImpl.scala:130)
at org.apache.spark.graphx.Pregel$.apply(Pregel.scala:130)
at org.apache.spark.graphx.GraphOps.pregel(GraphOps.scala:370)
at com.hx.test06.Test27AllPaths.main(Test27AllPaths.java:79)
Caused by: java.io.NotSerializableException: com.hx.test06.Test27AllPaths$$Lambda$583/2086477093
Serialization stack:
- object not serializable (class: com.hx.test06.Test27AllPaths$$Lambda$583/2086477093, value: com.hx.test06.Test27AllPaths$$Lambda$583/2086477093@7980cf2c)
- element of array (index: 0)
- array (class [Ljava.lang.Object;, size 2)
- field (class: java.lang.invoke.SerializedLambda, name: capturedArgs, type: class [Ljava.lang.Object;)
- object (class java.lang.invoke.SerializedLambda, SerializedLambda[capturingClass=class org.apache.spark.graphx.Pregel$, functionalInterfaceMethod=scala/Function2.apply:(Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object;, implementation=invokeStatic org/apache/spark/graphx/Pregel$.$anonfun$apply$2$adapted:(Lscala/Function3;Ljava/lang/Object;Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object;, instantiatedMethodType=(Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object;, numCaptured=2])
- writeReplace data (class: java.lang.invoke.SerializedLambda)
- object (class org.apache.spark.graphx.Pregel$$$Lambda$587/1753113235, org.apache.spark.graphx.Pregel$$$Lambda$587/1753113235@2b6a0ea9)
- element of array (index: 1)
- array (class [Ljava.lang.Object;, size 3)
- field (class: java.lang.invoke.SerializedLambda, name: capturedArgs, type: class [Ljava.lang.Object;)
- object (class java.lang.invoke.SerializedLambda, SerializedLambda[capturingClass=class org.apache.spark.graphx.impl.GraphImpl, functionalInterfaceMethod=scala/Function1.apply:(Ljava/lang/Object;)Ljava/lang/Object;, implementation=invokeStatic org/apache/spark/graphx/impl/GraphImpl.$anonfun$mapVertices$1:(Lorg/apache/spark/graphx/impl/GraphImpl;Lscala/Function2;Lscala/reflect/ClassTag;Lorg/apache/spark/graphx/impl/ShippableVertexPartition;)Lorg/apache/spark/graphx/impl/ShippableVertexPartition;, instantiatedMethodType=(Lorg/apache/spark/graphx/impl/ShippableVertexPartition;)Lorg/apache/spark/graphx/impl/ShippableVertexPartition;, numCaptured=3])
- writeReplace data (class: java.lang.invoke.SerializedLambda)
- object (class org.apache.spark.graphx.impl.GraphImpl$$Lambda$588/1784551034, org.apache.spark.graphx.impl.GraphImpl$$Lambda$588/1784551034@5d94a2dc)
- element of array (index: 0)
- array (class [Ljava.lang.Object;, size 1)
- field (class: java.lang.invoke.SerializedLambda, name: capturedArgs, type: class [Ljava.lang.Object;)
- object (class java.lang.invoke.SerializedLambda, SerializedLambda[capturingClass=class org.apache.spark.graphx.impl.VertexRDDImpl, functionalInterfaceMethod=scala/Function1.apply:(Ljava/lang/Object;)Ljava/lang/Object;, implementation=invokeStatic org/apache/spark/graphx/impl/VertexRDDImpl.$anonfun$mapVertexPartitions$1:(Lscala/Function1;Lscala/collection/Iterator;)Lscala/collection/Iterator;, instantiatedMethodType=(Lscala/collection/Iterator;)Lscala/collection/Iterator;, numCaptured=1])
- writeReplace data (class: java.lang.invoke.SerializedLambda)
- object (class org.apache.spark.graphx.impl.VertexRDDImpl$$Lambda$589/1625321341, org.apache.spark.graphx.impl.VertexRDDImpl$$Lambda$589/1625321341@5a917723)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:41)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:46)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:100)
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:413)
... 13 more
2. 假设 lambda 直接弄成 null 会有什么效果

3. 三个函数 直接弄成 null 会有什么效果
可以看到, 任务序列化这边通过了, 在执行任务的时候 NPE(显而易见)

java版本在 scala2.11 会遇到什么问题
1. foreach 报错问题
Error:(52, 10) java: no suitable method found for foreach((edge)->{ [...]ll; })
method scala.collection.AbstractIterable.foreach(scala.Function1,U>) is not applicable
(cannot infer type-variable(s) U
(argument mismatch; scala.Function1 is not a functional interface
multiple non-overriding abstract methods found in interface scala.Function1))
method scala.collection.mutable.ArrayStack.foreach(scala.Function1,U>) is not applicable
(cannot infer type-variable(s) U
(argument mismatch; scala.Function1 is not a functional interface
multiple non-overriding abstract methods found in interface scala.Function1)) 
使用其他的数据结构 来替换
2. ClassTag.apply 找不到
Error:(71, 119) java: cannot find symbol
symbol: method apply(java.lang.Class)
location: interface scala.reflect.ClassTag 使用 ClassManifestFactory 的相关 api 来替换
3. Iterator 问题

Error:(149, 35) java: cannot find symbol
symbol: method empty()
location: interface scala.collection.Iterator
Error:(152, 35) java: cannot find symbol
symbol: method empty()
location: interface scala.collection.Iterator
Error:(160, 37) java: cannot find symbol
symbol: method empty()
location: interface scala.collection.Iterator
Error:(179, 26) java: cannot find symbol
symbol: method apply(scala.collection.mutable.ArrayStack)
location: interface scala.collection.Iterator这个可以自己实现 迭代器, 临时解决
/**
* NoneIterator
*
* @author Jerry.X.He
* @version 1.0
* @date 2020-06-22 15:01
*/
private static class NoneIterator extends AbstractIterator {
@Override
public boolean hasNext() {
return false;
}
@Override
public T next() {
return null;
}
}
/**
* SingleIterator
*
* @author Jerry.X.He
* @version 1.0
* @date 2020-06-22 15:06
*/
private static class SingleIterator extends AbstractIterator {
// hasNext
private boolean hasNext = true;
private T elem;
public SingleIterator(T elem) {
this.elem = elem;
}
@Override
public boolean hasNext() {
return hasNext;
}
@Override
public T next() {
if (hasNext) {
hasNext = false;
return elem;
}
return null;
}
}
4. is not abstract and does not override abstract method tupled() in scala.Function3
Error:(121, 18) java: com.hx.test06.Test27AllPaths.VProg is not abstract and does not override abstract method tupled() in scala.Function3
Error:(144, 18) java: com.hx.test06.Test27AllPaths.SendMessage is not abstract and does not override abstract method apply$mcVJ$sp(long) in scala.Function1
Error:(193, 18) java: com.hx.test06.Test27AllPaths.MergeMessage is not abstract and does not override abstract method apply$mcVJJ$sp(long,long) in scala.Function2tupled 这个还能实现
apply$mcVJ$sp, apply$mcVJJ$sp 这两个就麻烦了, 搞不定
更新于 2020.07.04 - 通过可到达来计算
呵呵 最近思考了一下, 上面的代码 在存在环状图的场景下面存在漏洞
重新思考了一下 处理方式, 假设 source -> target 之间有 N 条路径, 那么我们将 所有的边反转一下, 同理 target -> source 的这 N 条路径依然是可行
从源节点 开始 可到达的所有的顶点 和 从目标节点开始可到达的所有的顶点取交集, 然后 根据顶点结果 抽取原始图的子图 作为结果
呵呵 不是搞算法的, 此方式 仅供参考(可到达计算的开销, 也比上面传播路径的开销小得多)
参考代码如下
package com.hx.test01
import org.apache.spark.graphx.{Edge, EdgeDirection, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Test06AllPaths
*
* @author Jerry.X.He <[email protected]>
* @version 1.0
* @date 2020/7/1 12:05
*/
object Test06AllPaths {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("Test02SSSP")
val sc = new SparkContext(conf)
val sourceId: VertexId = 0L // The ultimate source
val targetId: VertexId = 9L
// 创造一个边的RDD, 包含各种关系
val edges: RDD[Edge[Double]] = sc.parallelize(Array(
Edge(3L, 7L, 1.0d),
Edge(5L, 3L, 1.0d),
Edge(2L, 5L, 1.0d),
Edge(5L, 7L, 1.0d),
Edge(0L, 3L, 1.0d),
Edge(3L, 2L, 1.0d),
Edge(7L, 9L, 1.0d),
Edge(0L, 5L, 1.0d)
))
// positive
val availableVertexFromSourceId = reachableEdgeList(edges, sourceId)
// negative
val reversedEdges: RDD[Edge[Double]] = edges.map(edge => new Edge[Double](edge.dstId, edge.srcId, edge.attr))
val availableVertexFromTargetId = reachableEdgeList(reversedEdges, targetId)
val availableVertexes = availableVertexFromTargetId.filter(availableVertexFromSourceId.contains).distinct
val availableEdges = edges.filter(edge =>
availableVertexes.contains(edge.srcId)
&& availableVertexes.contains(edge.dstId)
).collect()
availableEdges.foreach(println)
}
/**
* 给定一个图, 一个源节点, 输出可到达的节点
*
* @param edges edges
* @param sourceId sourceId
*/
def reachableEdgeList(edges: RDD[Edge[Double]], sourceId: VertexId): Array[VertexId] = {
// 创造一个点的 RDD
val vertexes: RDD[(VertexId, Double)] = edges
.flatMap(edge => Array(edge.srcId, edge.dstId))
.distinct()
.map(id => if (id == sourceId) (id, 0) else (id, Double.PositiveInfinity))
val defaultVertex = Double.PositiveInfinity
// A graph with edge attributes containing distances
val graph: Graph[Double, Double] = Graph(vertexes, edges, defaultVertex)
// Initialize the graph such that all vertices except the root have distance infinity.
val initialGraph: Graph[Double, Double] = graph.mapVertices((id, _) =>
if (id == sourceId) 0.0
else Double.PositiveInfinity)
println(" edges as follow : ")
initialGraph.edges.foreach(println)
val sssp = initialGraph.pregel(Double.PositiveInfinity, Int.MaxValue, EdgeDirection.Out)(
// Vertex Program
(id, dist, newDist) => Math.min(dist, newDist),
// Send Message
triplet => {
if (triplet.srcAttr == Double.PositiveInfinity) {
Iterator.empty
} else if (triplet.dstAttr != Double.PositiveInfinity) {
Iterator.empty
} else if (triplet.srcId == triplet.dstId) {
Iterator.empty
} else {
Iterator((triplet.dstId, 0.0))
}
},
//Merge Message
(a, b) => Math.min(a, b))
sssp.vertices.filter(entry => entry._2 != Double.PositiveInfinity).map(entry => entry._1).collect()
}
}
参考
03 graphx 从 SSSP 来看 pregel