基于python的pixiv爬虫
python有很多种写法,用到的库也多种多样,这里用Pixiv的插画月排行榜做一下试验。
比较简单的有利用selenium模拟浏览器行为,但它会启动浏览器驱动,但是这样会额外耗费资源启动浏览器,而且打开新的窗口比较烦,虽然可以用PhantomJS替代(PhantomJS是将网页内容读进内存,不会打开新窗口)。但是Pixiv的排行有图片延迟加载,一个笨办法是用js控制滚动条,但是这样太不优雅了(本来打开新窗口就不优雅。。),所以我们用另一种方法。
主要用到的库:urllib、urllib2、cookielib、json、beautifulsoup4等
首先分析网站pixiv插画月排行,利用Chrome的开发者模式可以分析网站请求:F12(打开JS控制台)-Network-Clear-拖动网站滚动条,在XHR可以发现请求

这就是pixiv排行刷新的数据请求了,很容易看懂,请求的是插画月排行第2页json类型的数据。我们可以打开看看:
可以发现里面有排行图片的当前排名、插画id、插画名、插画缩略图链接、画师id、昵称等。
但是这里没有原图链接,其实p站的插画链接可以直接用www.pixiv.net/member_illust.php?mode=medium&illust_id= + 插画id访问。
我们随便打开一个上述插画页面,查看网页源代码,发现当试图访问原图片的时候,如果没有登录会转到登录页面,我们先登录看一下原图链接的标签:class = “original-image”,data-src里就是原图链接。
如果是漫画需要修改上述链接的medium为manga,源码的标签为data-filter=“manga-image”,原图链接仍然是data-src里的内容。
这基本上就是所有的分析内容(然而下面还有坑)。
我们把问题理一下:
1.获取插画的单独页面
2.解决登陆问题
3.获取原图链接
4.优化下载速度(可选)
————————————————————————————————————————————
准备工作:
需要的变量:
class PixivSpider:
def __init__(self):
self.imgs = []#存储图片的id、rank
self.__html = "http://www.pixiv.net/ranking.php?mode=monthly&content=illust"#要访问的月排行网址
self.__originalLink = "http://www.pixiv.net/member_illust.php?mode=medium&illust_id="#链接到原图网页的网址
self.__opener = None#打开网站的opener
self.q = Queue.Queue()#为了提高下载速度,需要用到多线程,这个用于线程间通信,主要用于显示下载进度,可选1.获取插画的单独页面:
def __MakeJsonUrl(self, page):
return self.__html + "&p=" + str(page) + "&format=json"
def __GetJsonData(self, html):
data = json.loads(urllib.urlopen(html).read())
if data is None:
return None
else:
for info in data["contents"]:
img = {}
img["id"] = info["illust_id"]
img["rank"] = info["rank"]
self.imgs.append(img)
for i in range(1, 7, 1):
self.__GetJsonData(self.__MakeJsonUrl(i))直接访问json请求页面,获取id和rank
2.解决登陆问题:
首先我们访问登录页面随便输入一个账号密码看一下post:
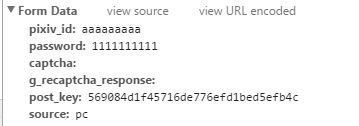
这个就是cookie的格式了,post_key可以查看源代码看到,每次访问这个页面会随机收到一个。
这个是改版后的样子,现在登录好像还要利用www.secure.pixiv.net/login.php,但是找到另一个接口,这样登录比较简单:
def __loginRequest(self):
cookie = cookielib.MozillaCookieJar("cookie.txt")
self.__opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
header = {
"Accept-Language": "zh-CN,zh;q=0.8",
'Referer': 'https://www.pixiv.net/login.php?return_to=0',
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
loginInfo = urllib.urlencode({
'mode': 'login',
'pass': 'password',#用户密码
'pixiv_id': 'username',#用户p站id或者邮箱
})
loginUrl = "https://www.pixiv.net/login.php"
request = urllib2.Request(loginUrl, data=loginInfo, headers=header)
self.__opener.open(request)
cookie.save(ignore_discard = True, ignore_expires = True)实际上现在改版后登录www.pixiv.net/login.php会被转到accounts.pixiv.net/login.php,但是这个入口还没有被封。。可以接着用
3.获取原图下载链接:
for img in self.imgs:
id = img["id"]
referer = self.__originalLink + str(id)
data = self.__opener.open(referer).read()
soup = BeautifulSoup(data, "lxml")
tags = soup.find_all("img", attrs={"class": "original-image"})#用xpath定位标签
if len(tags) > 0:
src = tags[0].attrs['data-src']#原图链接
file = open("img/" + "#" + str(img["rank"]).zfill(3) + src[-4 : len(src)], 'wb')
file.write(self.__DownloadRequest(referer, src))#下面说这个坑
file.close()
else:
data = self.__opener.open(self.__originalLink.replace("medium", "manga", 1) + str(id)).read()
soup = BeautifulSoup(data, "lxml")
tags = soup.find_all("img", attrs={"data-filter": "manga-image"})
for tag in tags:
idx = "_" + str(int(tag.attrs['data-index']) + 1)
src = tag.attrs['data-src']#原图链接
file = open("img/" + "#" + str(img["rank"]).zfill(3) + idx + src[-4 : len(src)], 'wb')
file.write(self.__DownloadRequest(referer, src))
file.close()发现当我们获取原图链接后依然无法访问页面(403错误),这是因为网站还验证用户了是从哪个页面转来的,抓包可以看到referer。
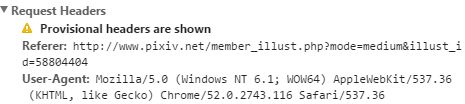
显然这个referer就是插画的单独链接,在访问的时候header里加入这个就可以了。
def __DownloadRequest(self, refererUrl, originalUrl):
header = {
"Accept-Language": "zh-CN,zh;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
header['referer'] = refererUrl
request = urllib2.Request(originalUrl, headers=header)
return self.__opener.open(request).read()到此为止就可以完成图片的下载了。
4.优化下载速度:
网络资源可能不能得到充分利用,如我在实验室是100m独享,但是下载速度只有可怜的130k/s,可以利用多线程优化:
class MyThread(threading.Thread):
def __init__(self, filename, referer, src, opener, q, idx, total):
threading.Thread.__init__(self)
self.filename = filename
self.referer = referer
self.src = src
self.opener = opener
self.q = q
self.total = total
self.idx = idx
def run(self):
header = {
"Accept-Language": "zh-CN,zh;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
header['referer'] = self.referer
request = urllib2.Request(self.src, headers=header)
data = self.opener.open(request).read()
file = open(self.filename, "wb")
file.write(data)
file.close()
self.q.put(self.idx)
print "Finished: ", self.idx, "/", self.total下载部分的代码改一下:
if len(tags) > 0:
src = tags[0].attrs['data-src']
mt = self.MyThread("img/" + "#" + str(img["rank"]).zfill(3) + src[-4 : len(src)], referer, src, self.__opener, self.q, count, total)
mt.start()
else:
data = self.__opener.open(self.__originalLink.replace("medium", "manga", 1) + str(id)).read()
soup = BeautifulSoup(data, "lxml")
tags = soup.find_all("img", attrs={"data-filter": "manga-image"})
for tag in tags:
idx = "_" + str(int(tag.attrs['data-index']) + 1)
src = tag.attrs['data-src']
mt = self.MyThread("img/" + "#" + str(img["rank"]).zfill(3) + idx + src[-4 : len(src)], referer,
src, self.__opener, self.q, count, total)
mt.start()
count += 1这样就可以实现多线程下载,虽然速度提升到了1.3m/s左右,但是依然没有实现网络资源的充分利用。
最后贴一下全部代码:代码中有一些测试用和本机用的无关代码,其中主进程结束后线程不会关闭,时间测量会有误差,total是第n个排名不是第n张图,因为漫画有多张图,写的比较乱。。。
import os, json, urllib, urllib2, cookielib, threading, Queue
from bs4 import BeautifulSoup
from datetime import datetime
from PIL import Image
class PixivSpider:
def __init__(self):
self.imgs = []
self.__html = "http://www.pixiv.net/ranking.php?mode=monthly&content=illust"
self.__originalLink = "http://www.pixiv.net/member_illust.php?mode=medium&illust_id="
self.__opener = None
self.q = Queue.Queue()
def CreateDir(self, path = "img/"):
if not os.path.exists(path): os.makedirs(path)
def __MakeJsonUrl(self, page):
return self.__html + "&p=" + str(page) + "&format=json"
def __GetJsonData(self, html):
data = json.loads(urllib.urlopen(html).read())
if data is None:
return None
else:
for info in data["contents"]:
img = {}
img["id"] = info["illust_id"]
img["rank"] = info["rank"]
self.imgs.append(img)
#print img["id"], '\t', img["rank"]
def __loginRequest(self):
cookie = cookielib.MozillaCookieJar("cookie.txt")
self.__opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
header = {
"Accept-Language": "zh-CN,zh;q=0.8",
'Referer': 'https://www.pixiv.net/login.php?return_to=0',
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
loginInfo = urllib.urlencode({
'mode': 'login',
'pass': 'password',
'pixiv_id': 'username',
})
loginUrl = "https://www.pixiv.net/login.php"
request = urllib2.Request(loginUrl, data=loginInfo, headers=header)
self.__opener.open(request)
cookie.save(ignore_discard = True, ignore_expires = True)
def __DownloadRequest(self, refererUrl, originalUrl):
header = {
"Accept-Language": "zh-CN,zh;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
header['referer'] = refererUrl
request = urllib2.Request(originalUrl, headers=header)
return self.__opener.open(request).read()
class MyThread(threading.Thread):
def __init__(self, filename, referer, src, opener, q, idx, total):
threading.Thread.__init__(self)
self.filename = filename
self.referer = referer
self.src = src
self.opener = opener
self.q = q
self.total = total
self.idx = idx
def run(self):
header = {
"Accept-Language": "zh-CN,zh;q=0.8",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36"
}
header['referer'] = self.referer
request = urllib2.Request(self.src, headers=header)
data = self.opener.open(request).read()
file = open(self.filename, "wb")
file.write(data)
file.close()
self.q.put(self.idx)
print "Finished: ", self.idx, "/", self.total
def GetImages(self):
self.CreateDir()
for i in range(1, 7, 1):
self.__GetJsonData(self.__MakeJsonUrl(i))
self.__loginRequest()
total = len(self.imgs)
t1 = datetime.now()
print t1
count = 1
for img in self.imgs:
id = img["id"]
referer = self.__originalLink + str(id)
data = self.__opener.open(referer).read()
soup = BeautifulSoup(data, "lxml")
tags = soup.find_all("img", attrs={"class": "original-image"})
if len(tags) > 0:
src = tags[0].attrs['data-src']
#print "#" + str(img["rank"]), src
# file = open(self.__fatherPath + "#" + str(img["rank"]).zfill(3) + src[-4 : len(src)], 'wb')
# file.write(self.__DownloadRequest(referer, src))
# file.close()
mt = self.MyThread("img/" + "#" + str(img["rank"]).zfill(3) + src[-4 : len(src)], referer, src, self.__opener, self.q, count, total)
mt.start()
else:
data = self.__opener.open(self.__originalLink.replace("medium", "manga", 1) + str(id)).read()
soup = BeautifulSoup(data, "lxml")
tags = soup.find_all("img", attrs={"data-filter": "manga-image"})
for tag in tags:
idx = "_" + str(int(tag.attrs['data-index']) + 1)
src = tag.attrs['data-src']
#print "#" + str(img["rank"]) + idx, src
# file = open(self.__fatherPath + "#" + str(img["rank"]).zfill(3) + idx + src[-4 : len(src)], 'wb')
# file.write(self.__DownloadRequest(referer, src))
# file.close()
mt = self.MyThread("img/" + "#" + str(img["rank"]).zfill(3) + idx + src[-4 : len(src)], referer,
src, self.__opener, self.q, count, total)
mt.start()
count += 1
t2 = datetime.now()
check = self.q.get()
#while check < total:
# check = max(check, self.q.get())
print t2, '\t', (t2.hour * 3600 + t2.second + t2.minute * 60) - (t1.second + t1.minute * 60 + t1.hour * 3600), 'second(s) passed'
def MakeHtml(self):
htmlFile = open("img/" + "!.html", "wb")
htmlFile.writelines("\r\n\r\nPixiv \r\n\r\n\r\n")
htmlFile.writelines("")
for i in os.listdir("img/"):
if i[-4:len(i)] in [".png", ".jpg", ".bmp"]:
filename = i
imgSize = Image.open("img/" + filename).size
width, height = imgSize
filename = filename.replace("#", "%23")
#htmlFile.writelines(""%("./" + filename))
htmlFile.writelines(" \r\n"
%("./" + filename, width * 1.0 / height * 200, 200, width, height))
#htmlFile.writelines("\r\n")
htmlFile.writelines("\r\n")
htmlFile.close()
#########################################################################
pSpider = PixivSpider()
pSpider.GetImages()
pSpider.MakeHtml()
\r\n"
%("./" + filename, width * 1.0 / height * 200, 200, width, height))
#htmlFile.writelines("\r\n")
htmlFile.writelines("\r\n")
htmlFile.close()
#########################################################################
pSpider = PixivSpider()
pSpider.GetImages()
pSpider.MakeHtml()最后写了个简单的html浏览图片:
这样python能及格了吧。。。