Java深入理解集合框架List
前言
Java集合框架主要包含Collection和Map两大类,其中Collection类包含List、Set、Queue,List接口包含ArrayList、LinkedList、Vector、Stack,Set接口包含HashSet、TreeSet、SortedSet,而Map接口则主要包括HashMap、HashTable、TreeMap,总结起来类似结构如下:
- Collection
- List
- Arraylist
- LinkedList
- Vector
- Stack
- Set
- HashSet
- TreeSet
- SortedSet
- Queue
- List
- Map
- HashMap
- HashTable
- TreeMap
再借用网上的图片:
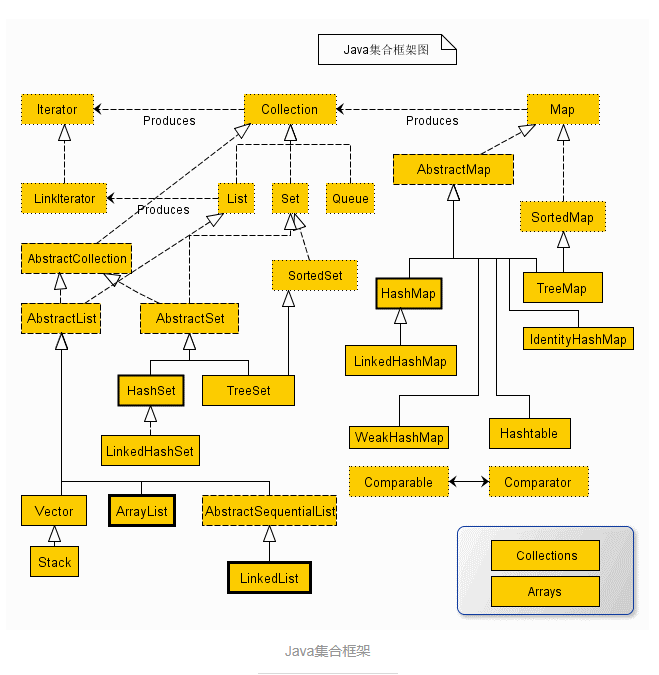
这篇文章先讲解List接口,后续会依次介绍Set Map Queue
List
ArrayList
主要方法
ArrayList通过add get添加和拿到数据,通过remove clear删除数据,同时内部可通过迭代器iterator和listIterator完成对数据的查询
构造函数
首先我们分析一下源码的构造函数
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData; // non-private to simplify nested class access
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}ArrayList有3个构造函数,我们可以选择不传参数,或者传入List的大小,或者直接传入一个Collection,ArrayList内部维护一个数组Object[] elementData来保存数据(如果我们此时并没有像List里面添加数据,此时内部数组大小为1,一旦我们向里面增加数据,数据会立马扩容变成初始容量10的数组),数组初始大小为DEFAULT_CAPACITY = 10,当我们在构造方法时传入数组大小时,ArrayList会根据我们传入的数值来new数组,如果传入Collection,直接将Collection转换为数组然后复制给elementData.
扩容机制与查询操作
之前提到了,ArrayList的默认大小是10,那当我们一直不停的向Arraylist添加数据时,Arraylist是如何扩容的呢?
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
当我们调用add向ArrayList中添加数据时,会首先调用ensureCapacityInternal,此时如果我们new这个对象的时候调用无参的构造函数或者传入了数组大小的构造,那么此时size=0,否则的话size为传入的Colleation的大小。
ensureExplicitCapacity会调用grow进行扩容操作,在grow()中,会比较minCapacity和newCapacity,通过
int newCapacity = oldCapacity + (oldCapacity >> 1);
我们发现新大小都是在原有大小上增加原有大小的一半,然后通过Arrays.copyOf这个函数拷贝原始数据到新数组上,至此数组扩充完成。
我们回过头来看什么时候会进行扩容操作?
在ensureExplicitCapacity方法中
if (minCapacity - elementData.length > 0)
grow(minCapacity);通过minCapacity与内部数据数组大小进行比较,来决定是否进行扩容操作,下面分几种情况来讲解
- 通过无参构造初始函数初始化,并且未扩容,此时内部数组的大小为0,
minCapacity为初始值10,在第一次添加数据时,if (minCapacity - elementData.length > 0)为true,会执行grow操作,然后执行赋值操作,那么此时size大小为1,新数组的大小为10,后续size代表了数组中实际数据的数量。在第一次扩容完成后,minCapacity为数组中实际数据的大小加1. - 构造器参数为int数值,且未进行过扩容操作时,此时
minCapacity为0,size为实际数据的大小, - 构造器参数为Collection,且未进行过扩容操作时,
minCapacity为数组大小加1。
通过对上述3种情况分析,不难发现数组扩容操作只会在以下情况时发生:
1. 刚通过无参构造器初始化,然后向List增加数据
2. 向List增加数据,内部实际数据的大小已经等于内部数据数组的大小时
对Arraylist进行get数据时,由于内部是数组,因此速度非常快
迭代器Iterator
ArrayList有一个内部类private class Itr implements Iterator,迭代器操作通过这个内部类来实现
public Iterator iterator() {
return new Itr();
}
内部类的主要成员变量如下:
//ArrayList的内部数组大小
protected int limit = ArrayList.this.size;
//下一个元素的索引
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
//这个主要用于判断在迭代器操作过程中,外部是否更改了ArrayList,
int expectedModCount = modCount;特别注意:如果在使用迭代器获取数据时,如果外部更改了ArrayList的数据,会抛出ConcurrentModificationException,这个主要是通过expectedMode来判断实现的
@SuppressWarnings("unchecked")
public E next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
int i = cursor;
if (i >= limit)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}比如我们初始化迭代器时,会执行int expectedModCount = modCount;,而我们每次在改变ArrayList时,modCount都会加1,因此比如当我们在使用迭代器进行next操作时,如果外部改变了ArrayList,那么modCount会变化,这时候检测到expectedModCount和modCount不一致,就会throw new ConcurrentModificationException()
多线程情况
在多线程下对ArrayList操作并不安全,因为ArrayList没有做同步机制,如果我们想让ArrayList同步,需要手动操作,比如在new ArrayList时,按如下方式建立:
List stringList = Collections.synchronizedList(new ArrayList<>()); 但是使用这种方式不能保证迭代器在多线程下正常工作
LinkedList
主要方法
LinkedList与ArrayList类似通过add get添加和拿到数据,通过remove clear删除数据,同时内部只能通过迭代器listIterator完成对数据的查询
构造函数
transient Node first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node last;
private static class Node<E> {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} LinkedList内部通过双向链表来保存数据,链表的初始大小为0,first指的是链表的第一个节点,last代表链表的最后一个节点
节点对象为Node对象,item保存我们要添加的对象数据,prev指向链表的上一个节点,next指向链表的下一个节点。
扩容机制与查询
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
} 当我们向LinkedList里面添加数据时,首先通过初始化一个新节点,在初始化新节点时,会将链表的last节点赋值给新节点的prev,同时新节点的next为null,表示新节点是最后一个节点,同时,这里如果l为null,表示当前链表一个节点都没有,那么需要对first节点赋值,在添加完第一个节点后,后续添加元素的话,依次对链表尾增加节点就OK
对LinkedList进行查询操作时,需要挨个遍历链表,速度相对ArrayList慢
多线程情况
LinkedList与ArrayList一样,在多线程下操作是不安全的,
Vector
主要方法
LinkedList与ArrayList类似,内部维护一个数组用来保存数据,通过add get添加和拿到数据,通过remove clear删除数据,同时内部只能通过迭代器iterator和listIterator完成对数据的查询
构造函数
protected Object[] elementData;//内部数组
protected int elementCount;//元素数量
protected int capacityIncrement;//扩容时增加大小
public Vector() {
this(10);
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
public Vector(Collection c) {
elementData = c.toArray();
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
Vector有四种构造函数,内部数组默认大小为0,与ArrayList不同的是,Vector可以在构造函数中传入capacityIncrement,后续扩容时会根据这个数值来扩展大小
扩容机制与查询
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//根据capacityIncrement的值,为0就扩大一倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}这里我们主要看grow函数,与ArrayList不同,如果我们在构造函数中传入了capacityIncrement,那么在扩容时,我们就会扩大capacityIncrement,否则的话扩大一倍
多线程情况
由于LinkedList的add get方法都加了synchronized关键字,因此在多线程下是同步的,但是迭代器在多线程下依旧不安全
Stack
Stack继承Vector,然后以栈的形式向外暴露接口
public E push(E item) {
addElement(item);
return item;
}
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
public boolean empty() {
return size() == 0;
}比较
| 类别 | ArrayList | LinkedList | Vector | Stack |
|---|---|---|---|---|
| 内部实现 | 内部通过数组保存数据 | 内部通过双向链表,节点保存数据 | 内部通过数组 | 内部通过数组 |
| 初始大小 | 10 | 0 | 10 | 10 |
| 扩容机制 | 增加原始大小的一半 | 依次在链表尾增加节点 | 在构造器初始化时,可以选择传入每次扩容的大小,如果传入,那么每次扩容时的大小为传入的数值,否则扩大一倍 | 与Vector一致 |
| 多线程 | 不同步 | 不同步 | 同步 | 同步 |
| 插入速度 | 较慢,因为扩容时要新建数组,并拷贝原始数据 | 较快,直接增加节点 | 单线程下与ArrayList一致,多线程下较慢,因为有同步操作 | 与Vector一致 |
| 查询速度 | 较快 | 较慢,需要挨个遍历链表 | 较快 | 与Vector一致 |