elasticsearch运维实战之2 - 系统性能调优
elasticsearch性能调优
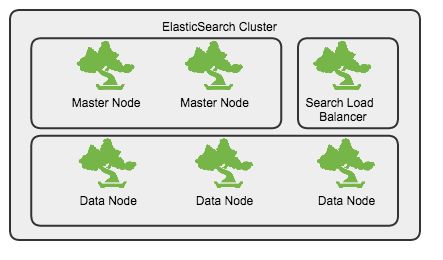
集群规划
- 独立的master节点,不存储数据, 数量不少于2
- 数据节点(Data Node)
- 查询节点(Query Node),起到负载均衡的作用
Linux系统参数配置
文件句柄
Linux中,每个进程默认打开的最大文件句柄数是1000,对于服务器进程来说,显然太小,通过修改/etc/security/limits.conf来增大打开最大句柄数
* - nofile 65535
虚拟内存设置
max_map_count定义了进程能拥有的最多内存区域
sysctl -w vm.max_map_count=262144
修改/etc/elasticsearch/elasticsearch.yml
bootstrap.mlockall: true
修改/etc/security/limits.conf, 在limits.conf中添加如下内容
* soft memlock unlimited
* hard memlock unlimited
memlock 最大锁定内存地址空间, 要使limits.conf文件配置生效,必须要确保pam_limits.so文件被加入到启动文件中。
确保/etc/pam.d/login文件中有如下内容
session required /lib/security/pam_limits.so
验证是否生效
curl localhost:9200/_nodes/stats/process?pretty
磁盘缓存相关参数
vm.dirty_background_ratio 这个参数指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入外存;
vm.dirty_ratio
-
该参数则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存);在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
-
把该参数适当调小,原理通(1)类似。如果cached的脏数据所占比例(这里是占MemTotal的比例)超过这个设置,系统会停止所有的应用层的IO写操作,等待刷完数据后恢复IO。所以万一触发了系统的这个操作,对于用户来说影响非常大的。
sysctl -w vm.dirty_ratio=10
sysctl -w vm.dirty_background_ratio=5
为了将设置永久保存,将上述配置项写入/etc/sysctl.conf文件中
vm.dirty_ratio = 10
vm.dirty_background_ratio = 5
swap调优
swap空间是一块磁盘空间,操作系统使用这块空间保存从内存中换出的操作系统不常用page数据,这样可以分配出更多的内存做page cache。这样通常会提升系统的吞吐量和IO性能,但同样会产生很多问题。页面频繁换入换出会产生IO读写、操作系统中断,这些都很影响系统的性能。这个值越大操作系统就会更加积极的使用swap空间。
调节swappniess方法如下
sudo sh -c 'echo "0">/proc/sys/vm/swappiness'
io sched
如果集群中使用的是SSD磁盘,那么可以将默认的io sched由cfq设置为noop
sudo sh -c 'echo "noop">/sys/block/sda/queue/scheduler'
JVM参数设置
在/etc/sysconfig/elasticsearch中设置最大堆内存,该值不应超过32G
ES_HEAP_SIZE=32g
ES_JAVA_OPTS="-Xms32g"
MAX_LOCKED_MEMORY=unlimited
MAX_OPEN_FILES=65535
indice参数调优
以创建demo_logs模板为例,说明可以调优的参数及其数值设定原因。
PUT _template/demo_logs
{
"order": 6,
"template": "demo-*",
"settings": {
"index.merge.policy.segments_per_tier": "25",
"index.mapping._source.compress": "true",
"index.mapping._all.enabled": "false",
"index.warmer.enabled": "false",
"index.merge.policy.min_merge_size": "10mb",
"index.refresh_interval": "60s",
"index.number_of_shards": "7",
"index.translog.durability": "async",
"index.store.type": "mmapfs",
"index.merge.policy.floor_segment": "100mb",
"index.merge.scheduler.max_thread_count": "1",
"index.translog.translog.flush_threshold_size": "1g",
"index.merge.policy.merge_factor": "15",
"index.translog.translog.flush_threshold_period": "100m",
"index.translog.sync_interval": "5s",
"index.number_of_replicas": "1",
"index.indices.store.throttle.max_bytes_per_sec": "50mb",
"index.routing.allocation.total_shards_per_node": "2",
"index.translog.flush_threshold_ops": "1000000"
},
"mappings": {
"_default_": {
"dynamic_templates": [
{
"string_template": {
"mapping": {
"index": "not_analyzed",
"ignore_above": "10915",
"type": "string"
},
"match_mapping_type": "string"
}
},
{
"level_fields": {
"mapping": {
"index": "no",
"type": "string"
},
"match": "Level*Exception*"
}
}
]
}
}
"aliases": {}
}
replica数目
为了让创建的es index在每台datanode上均匀分布,同一个datanode上同一个index的shard数目不应超过3个。
计算公式: (number_of_shard * (1+number_of_replicas)) < 3*number_of_datanodes
每台机器上分配的shard数目
"index.routing.allocation.total_shards_per_node": "2",
refresh时间间隔
默认的刷新时间间隔是1s,对于写入量很大的场景,这样的配置会导致写入吞吐量很低,适当提高刷新间隔,可以提升写入量,代价就是让新写入的数据在60s之后可以被搜索,新数据可见的及时性有所下降。
"index.refresh_interval": "60s"
translog
降低数据flush到磁盘的频率。如果对数据丢失有一定的容忍,可以打开async模式。
"index.translog.flush_threshold_ops": "1000000",
"index.translog.durability": "async",
merge相关参数
"index.merge.policy.floor_segment": "100mb",
"index.merge.scheduler.max_thread_count": "1",
"index.merge.policy.min_merge_size": "10mb"
mapping设置
对于不参与搜索的字段(fields), 将其index方法设置为no, 如果对分词没有需求,对参与搜索的字段,其index方法设置为not_analyzed
多使用dynamic_template
集群参数调优
{
"persistent": {
"cluster": {
"routing": {
"allocation": {
"enable": "new_primaries",
"cluster_concurrent_rebalance": "8",
"allow_rebalance": "indices_primaries_active",
"node_concurrent_recoveries": "8"
}
}
},
"indices": {
"breaker": {
"fielddata": {
"limit": "30%"
},
"request": {
"limit": "30%"
}
},
"recovery": {
"concurrent_streams": "10",
"max_bytes_per_sec": "200mb"
}
}
},
"transient": {
"indices": {
"store": {
"throttle": {
"type": "merge",
"max_bytes_per_sec": "50mb"
}
},
"recovery": {
"concurrent_streams": "8"
}
},
"threadpool": {
"bulk": {
"type": "fixed"
"queue_size": "1000",
"size": "30"
},
"index": {
"type": "fixed",
"queue_size": "1200",
"size": "30"
}
},
"cluster": {
"routing": {
"allocation": {
"enable": "all",
"cluster_concurrent_rebalance": "8",
"node_concurrent_recoveries": "15"
}
}
}
}
}
避免shard的频繁rebalance,将allocation的类型设置为new_primaries, 将默认并行rebalance由2设置为更大的一些的值
避免每次更新mapping, 针对2.x以下的版本
"indices.cluster.send_refresh_mapping": false
调整threadpool, size不要超过core数目,否则线程之间的context switching会消耗掉大量的cpu时间,导致load过高。 如果没有把握,那就不要去调整。
定期清理cache
为避免fields data占用大量的jvm内存,可以通过定期清理的方式来释放缓存的数据。释放的内容包括field data, filter cache, query cache
curl -XPOST "localhost:9200/_cache/clear"
其它
- marvel: 安装marvel插件,多观察系统资源占用情况,包括内存,cpu
- 日志: 对es的运行日志要经常查看,检查index配置是否合理,以及入库数据是否存在异常