task_seq2seq_autotitle_csl代码解读
task_seq2seq_autotitle_csl.py代码解读
此文档是对bert4keras工具中seq2seq任务的示例代码的一个解读,尽可能看的细致是为了以后修改起来更加顺手。有些代码和操作的理解可能还会有一些错误,正在不断的完善当中。
0.主要部分
从主函数入口可以了解该程序主要包括以下三个部分:
evaluator = Evaluate()
train_generator = data_generator(train_data, batch_size)
model.fit_generator(train_generator.forfit(),steps_per_epoch=len(train_generator),
epochs=epochs, callbacks=[evaluator])
其中evaluator使用来评估模型和保存模型参数的; data_generator是用来生成训练数据的,将文本数据转换成对应的token_id,方便模型计算; model.fit_generator() 使用了使用训练数据训练模型。
所以,改程序可以概括为三个主要部分: 数据预处理,模型搭建与参数加载,训练模型并且评估模型。
1.数据预处理阶段
在执行data_generator() 之前,还需要做以下准备。通过load_data()将文本数据读取到列表中,并且加载bert模型文件中的中文字表,在调用Tokenizer()函数,返回tokenizer对象,为了下一步将输入文本转换为token:
# 加载数据集
train_data = load_data("train.data")
valid_data = load_data("valid.data")
test_data = load_data("test.data")
# 加载并精简词表,建立分词器
token_dict, keep_tokens = load_vocab(
dict_path=dict_path,
simplified=True,
startwith=['[PAD]', '[UNK]', '[CLS]', '[SEP]'],
)
# 转换为token
tokenizer = Tokenizer(token_dict, do_lower_case=True)
接下来开始执行data_generator(),传入参数为train_data和batch_size:
class data_generator(DataGenerator):
"""数据生成器"""
def __iter__(self, random=False):
idxs = list(range(len(self.data)))
if random:
np.random.shuffle(idxs)
batch_token_ids, batch_segment_ids = [], []
for i in idxs:
title, content = self.data[i]
# 将数据转换成ID,将content和title转换成同一个token_ids
token_ids, segment_ids = tokenizer.encode(content,title,max_length=maxlen)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
if len(batch_token_ids) == self.batch_size or i == idxs[-1]:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
yield [batch_token_ids, batch_segment_ids], None
batch_token_ids, batch_segment_ids = [], []
将数据进行随机洗牌之后,调用tokenizer.encode()对数据进行转换,输入文本内容和标题内容,以及最大句子长度,这里要注意一个地方,本来读取的数据第一句是title,第二句是content,在调用tokenizer.encode()函数时,先输入的是content,其次才输入的title,转换完成之后返回token_ids和segment_ids,然后按照batch_size进行打包返回。这里最值得注意的地方是tokenizer.encode()中发生了什么?
def encode(self,first_text,second_text=None,max_length=None,first_length=None,
second_length=None):
"""输出文本对应token id和segment id如果传入first_length,则强行padding第一个句子到指定长度;同理,如果传入second_length,则强行padding第二个句子到指定长度。"""
if is_string(first_text):
first_tokens = self.tokenize(first_text)
else:
first_tokens = first_text
if second_text is None:
second_tokens = None
elif is_string(second_text):
second_tokens = self.tokenize(second_text, add_cls=False)
else:
second_tokens = second_text
if max_length is not None:
self.truncate_sequence(max_length, first_tokens, second_tokens, -2)
first_token_ids = self.tokens_to_ids(first_tokens)
if first_length is not None:
first_token_ids = first_token_ids[:first_length]
first_token_ids.extend([self._token_pad_id] *
(first_length - len(first_token_ids)))
first_segment_ids = [0] * len(first_token_ids)
if second_text is not None:
second_token_ids = self.tokens_to_ids(second_tokens)
if second_length is not None:
second_token_ids = second_token_ids[:second_length]
second_token_ids.extend([self._token_pad_id] *
(second_length - len(second_token_ids)))
second_segment_ids = [1] * len(second_token_ids)
first_token_ids.extend(second_token_ids)
first_segment_ids.extend(second_segment_ids)
return first_token_ids, first_segment_ids
前半部分都是对文本的token化和padding操作,由最后三句可以看到,程序将second_token_ids拼接到了first_token_ids后面,对应文本就是将训练数据的title拼接到了content之后,返回了first_token_ids,对于segment_ids,content部分的词标记为"0",title部分的词标记为"1",将title的segment_ids拼接到content的segment_ids之后,最后返回token_ids和segment_ids,所以segment_ids的数据就形如[0,0,0,0,1,1]。
接下来将数据按照batch_size打包到列表中,得到batch_token_ids和batch_segment_ids,至此,数据预处理部分执行完毕。
2.模型搭建与参数加载
2.1关于Bert针对seq2seq任务的代码修改部分
接下来对首先对bert模型进行加载,输入参数config_path表示bert模型参数的配置文件,checkpoint_path表示模型参数文件路径,application表示应用的任务类型。对于不同用途,要对bert模型进行不同的修改。
# 构建bert模型,并且加载模型参数
model = build_bert_model(
config_path,
checkpoint_path,
application='seq2seq',
keep_tokens=keep_tokens, # 只保留keep_tokens中的字,精简原字表
)
# 此行代码输出模型各层的参数状况
model.summary()
application='seq2seq’参数表示: 对于seq2seq任务模型加载的是继承自BertModel父类的Bert4Seq2seq子类,对于这个Bert4Seq2seq子类,仅仅实现了不同的compute_attention_mask() 函数。
def compute_attention_mask(self, layer_id, segment_ids):
"""为seq2seq采用特定的attention mask """
# segment_ids是2D张量 形如[[0, 0, 0, 0, 0, 1, 1, 1]] 这种,其中数值0,1表示词到底属于哪个句 子,0表示词属于content,1表示当前词输入title。
# 这个函数被调用12次 其中seq2seq_attention_mask()函数被调用一次创建了a_mask张量,剩下11次的数据 应该都是使用第一次创建的a_mask,并没有产生新的张量
# 这里的layer_id 表示的就是层数编号,在起初定义的时候,作者的想法是“定义每一层的Attention Mask, 来实现不同的功能”,但是在实际实现的时候,并没有用到层数编号这个参数。
# 源码文件bert.py中第 139 行 开始调用此函数,并返回attention_mask,其中输入的参数为 层数编号i 和 segment_ids(s_in)
if self.attention_mask is None:
def seq2seq_attention_mask(s):
# 这个函数被调用一次
import tensorflow as tf
# 得到句子长度(first_seq_length + second_seq_length)
seq_len = K.shape(s)[1]
with K.name_scope('attention_mask'):
# 生成数值为1的 4维张量
ones = K.ones((1, 1, seq_len, seq_len))
# 在这部操作以后,全为1的4为张量,变成了下三角为1 上三角为0的对角矩阵
a_mask = tf.linalg.band_part(ones, -1, 0)
# 将segment_ids变成 [batch_size, 1,1, seq_length] 形状的张量 数值大小不变
s_ex12 = K.expand_dims(K.expand_dims(s, 1), 2)
# 将segment_ids变成 [batch_size, 1,seq_length, 1] 形状的张量 数值大小不变
s_ex13 = K.expand_dims(K.expand_dims(s, 1), 3)
# 变成形状[batch_size, 1, seq_length, seq_length]的张量
a_mask = (1 - s_ex13) * (1 - s_ex12) + s_ex13 * a_mask
# a_mask 会进行0和1 反转,并且逐渐将整句都mask掉
return a_mask
# 经过Lambda()层转换输出
self.attention_mask = Lambda(seq2seq_attention_mask,
name='Attention-Mask')(segment_ids)
# attention_mask 是4D张量 [batch_size, 1, seq_length, seq_length]
return self.attention_mask
接下来演示一下**compute_attention_mask()**函数的执行效果, 输入为4x5的2D张量, 样例输入:
data = tf.constant([[1, 1, 1, 1, 1],
[0, 1, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 0, 1]], dtype=tf.float32)
segment_ids = Input(shape=(None,), name='Input-Segment', tensor=data)
经过**compute_attention_mask()**函数计算后得到 4x1x5x5的4D张量:
[[[1. 0. 0. 0. 0.]
[1. 1. 0. 0. 0.]
[1. 1. 1. 0. 0.]
[1. 1. 1. 1. 0.]
[1. 1. 1. 1. 1.]]]
[[[1. 0. 0. 0. 0.]
[1. 1. 0. 0. 0.]
[1. 1. 1. 0. 0.]
[1. 1. 1. 1. 0.]
[1. 1. 1. 1. 1.]]]
[[[1. 1. 0. 0. 0.]
[1. 1. 0. 0. 0.]
[1. 1. 1. 0. 0.]
[1. 1. 1. 1. 0.]
[1. 1. 1. 1. 1.]]]
[[[1. 1. 1. 1. 0.]
[1. 1. 1. 1. 0.]
[1. 1. 1. 1. 0.]
[1. 1. 1. 1. 0.]
[1. 1. 1. 1. 1.]]]]
可以看出来最后生成的attention_mask张量应该就是从第一个句子的末尾开始, 把逐词地将第二个句子进行逐词遮蔽。
2.2从模型的整体结构来看
虽然compute_attention_mask()函数被调用了12次, 但是都是作为每一层的输入添加到transformer层中的。

然而在使用summary()函数打印模型结构时,在模型整体结构作为输入层仅仅出现了一次,并且是映射成Embedding-Segment输入Bert模型中。 与原有的语言模型**(task_language_model.py)相比,在每一层中都添加了attention_mask**
与原有的语言模型**(task_language_model.py)相比,在每一层中都添加了attention_mask**
关于修改attention_mask的四个问题
那么从这里就引申出四个问题:
1.为什么在**(task_language_model.py)**的模型结构文件中没有显示attention_mask?
2.原版的Bert源码对attention_mask进行了什么操作?
3.task_seq2seq_autotitle_cls.py模型在加入了attention_mask之后,究竟进行了什么操作?
4.为什么针对seq2seq任务要进行这样的修改?
关于第一个问题的原因,先看一下**(task_language_model.py)**的模型结构:
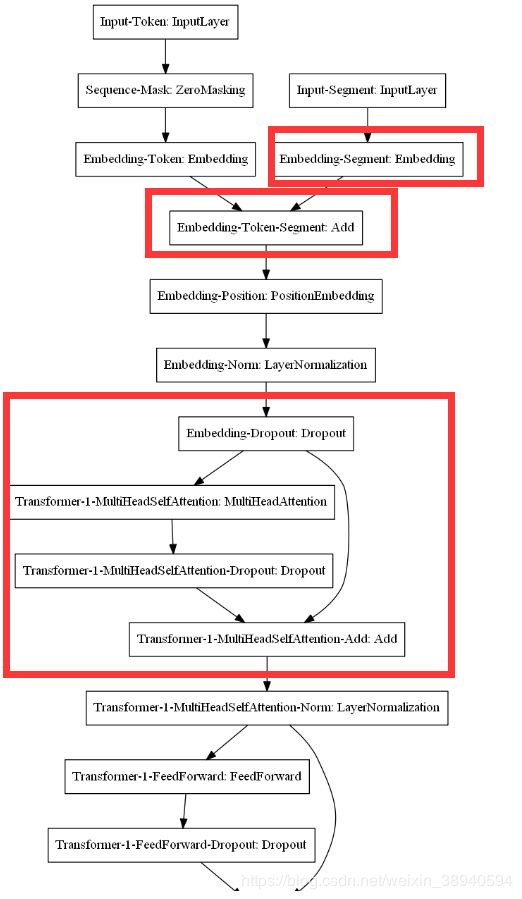 从这张图可以看出,除了上一层的输出,并没有其他数据信息输入到多头注意力层。虽然没有其他层的数据输入到多头注意层当中,但是这不代表这一层没有对attention_mask进行操作。在bert的谷歌源码中每一层都对attention_mask进行计算,只不过在原模型是作为参数(张量)在层与层之间进行传递的。还记得在compute_attention_mask()中曾经使用过这样一行代码吗?
从这张图可以看出,除了上一层的输出,并没有其他数据信息输入到多头注意力层。虽然没有其他层的数据输入到多头注意层当中,但是这不代表这一层没有对attention_mask进行操作。在bert的谷歌源码中每一层都对attention_mask进行计算,只不过在原模型是作为参数(张量)在层与层之间进行传递的。还记得在compute_attention_mask()中曾经使用过这样一行代码吗?
self.attention_mask = Lambda(
seq2seq_attention_mask,name='Attention-Mask')(segment_ids)
这里的Lambda层任务是对attention_mask进行重塑和转换,并没有引入新的训练参数,所以在原来的**(task_language_model.py)**文件中并没有对attention_mask张量进行什么操作,所以数据可以直接进行传递,在seq2seq任务中,需要对attention_mask进行重新的生成和重塑,这里使用Lambda层是方便这样的操作,因为引入了层一级的机构,所以会在模型结构图中有所体现。
关于第二个问题:原版的Bert源码对attention_mask进行了什么操作? 我们定位到Google原版的Bert源码中,在modeling文件中代码700行左右(由于我之前对源码加了很多注释,所以不确定哪一行),可以看到对attention_mask的操作,在算完注意力头的attention_scores之后,根据attention_mask,也就是遮蔽的位置计算attention_scores。在未经变换的attention_mask中:1表示露出位置,0表示遮蔽位置 ,在进行 adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0 操作后,露出位置变成了0,-10000表示遮蔽位置。接下来再把adder加到原来的attention_scores中。
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
if attention_mask is not None:
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_scores += adder
官方给出这么操作的解释是:由于是在进行柔性最大值(softmax)之前进行这写操作的,这样的效果跟完成删除的效果是相同的。实际上的目的就是把被被遮蔽的token的attention_socores删除调,以达到遮蔽的效果。由此可见,Mask Language Model在Bert的每一个attention层中都进行遮蔽了,而不是简单的对输入输出进行遮蔽。因此,第二个问题的答案可以概括为,源码对attention_mask的操作就是为了删除掉被遮蔽token的attention得分。
关于第三个问题,.task_seq2seq_autotitle_cls.py模型在加入了attention_mask之后,究竟进行了什么操作?task_seq2seq_autotitle_cls.py中为了使bert泛化更多的任务,对attention机制中的Q、V都进行了mask,我觉得这个是比较重要的一部分,应该可以都模型效果产生很大影响,而且在修改版本的keras版的bert中,可以使用相对位置编码来替代学习得到的position_embedding。
def call(self, inputs, q_mask=None, v_mask=None, a_mask=None):
"""实现多头注意力
q_mask: 对输入的query序列的mask。
主要是将输出结果的padding部分置0。
v_mask: 对输入的value序列的mask。
主要是防止attention读取到padding信息。
a_mask: 对attention矩阵的mask。
不同的attention mask对应不同的应用。
"""
对attention_mask的操作核心思想与Google原版的bert几乎一样,将被遮蔽的attention_score去掉。
a = a / self.key_size**0.5
a = sequence_masking(a, v_mask, 1, -1)
if a_mask is not None:
if is_string(a_mask):
ones = K.ones_like(a[:1, :1])
a_mask = (ones - tf.linalg.band_part(ones, -1, 0)) * 1e12
a = a - a_mask
else:
a = a - (1 - a_mask) * 1e12
a = K.softmax(a)
关于问题四:为什么针对seq2seq任务要进行这样的修改?由于原有的Bert的预训练任务是基于完形填空似的遮蔽语言模型任务,对于seq2seq任务这样的完型填空机制并不适用,更合适的mask机制,应该根据显示上文,而遮蔽下文,所以就有了compute_attention_mask()函数返回的逐词遮蔽的attention_mask,而且也属于连续遮蔽来预测下一个词,更加适合文本生成等任务。
2.3模型的输入输出设置
关于模型设定的输入输出部分,与语言模型(**task_language_model.py)**的设置原则基本一致。
task_seq2seq_autotitle_cls.py
# 交叉熵作为loss,并mask掉输入部分的预测
# 输入[cls] a, b, c [sep]的向量
y_in = model.input[0][:, 1:] # 目标tokens 真实值 a, b, c, [sep]
y_mask = model.input[1][:, 1:]
y = model.output[:, :-1] # 预测tokens,预测与目标错开一位 预测值 [cls] a, b, c
cross_entropy = K.sparse_categorical_crossentropy(y_in, y)
cross_entropy = K.sum(cross_entropy * y_mask) / K.sum(y_mask)
task_language_model.py
# 交叉熵作为loss,并mask掉输入部分的预测
y_true = model.input[0][:, 1:] # 目标tokens 与task_seq2seq_autotitle_cls.py一样
y_mask = model.get_layer('Embedding-Token').output_mask[:, 1:] # 目标mask 这里的mask应该从 layer中取的,取的也是从1开始到最后的位置
y_mask = K.cast(y_mask, K.floatx()) # 转为浮点型
y_pred = model.output[:, :-1]#预测tokens,预测与目标错开一位 与task_seq2seq_autotitle_cls一样
cross_entropy = K.sparse_categorical_crossentropy(y_true, y_pred)
cross_entropy = K.sum(cross_entropy * y_mask) / K.sum(y_mask)
在设置完模型的输入输出之后,配置模型训练参数和损失函数。
# 添加交叉熵作为损失函数
model.add_loss(cross_entropy)
# 设定Adam为参数优化器 compile()函数为了训练模型,可以配置模型各种参数
model.compile(optimizer=Adam(1e-5))
autotitle = AutoTitle(start_id=None,end_id=tokenizer._token_sep_id, maxlen=32)
至此模型配置工作基本完成
2.4 训练模型和评估模型
主函数中调用model.fit_generator()函数进行训练模型,利用data_generator()函数,生成训练数据并进行训练,生成器与模型并行执行以提高工作效率。
再看一次主函数中的代码:
evaluator = Evaluate()
train_generator = data_generator(train_data, batch_size)
model.fit_generator(train_generator.forfit(),steps_per_epoch=len(train_generator),
epochs=epochs, callbacks=[evaluator])
model.fit_generator()函数中的第一个参数为generator,表示生成器函数,train_generator.forfit()表示
是一个shape=[inputs,targets]的元组。steps_per_epoch 表示 每一个epoch的总步数,这里设置为训练数据元组的长度,epochs 就是迭代次数。
callbacks 表示回调函数,关于回调函数的具体解释,官方给出了如下解释:
A callback is a set of functions to be applied at given stages of the training procedure. You can use callbacks to get a view on internal states and statistics of the model during training. You can pass a list of callbacks (as the keyword argument
callbacks) to the.fit()method of theSequentialorModelclasses. The relevant methods of the callbacks will then be called at each stage of the training.
看起来很不容理解,那怎么办,那就直接看回传入的回调函数都执行了那些内容;
class Evaluate(keras.callbacks.Callback):
# 继承自keras回调函数类
def __init__(self):
# Rouge()函数表示(Recall Oriented Understudy for Gisting Evaluation)是评估自动文摘以 及机器翻译的一组指标。说白了就是文本生成的一种评价指标,特指自动文摘评测
self.rouge = Rouge()
# 计算BLUE值的一种平滑方法
self.smooth = SmoothingFunction().method1
def on_epoch_end(self, epoch, logs=None):
model.save_weights('./best_model.weights') # 保存模型
print('valid_data:', self.evaluate(valid_data)) # 评测模型
def evaluate(self, data, topk=1):
total = 0
rouge_1, rouge_2, rouge_l, bleu = 0, 0, 0, 0
for title, content in tqdm(data):
total += 1
title = ' '.join(title)
# 调用autotitle.generate(content, topk)函数,看到这你就会发现 上面有一段代码还没有解 读,就是在配置完成模型参数之后的一行代码,这段代码的作用就是根据输入的文本,返回预测的文 本内容,然后接下来的程序根据预测的文本内容计算各种评价指标得分。
pred_title = ' '.join(autotitle.generate(content, topk))
if pred_title.strip():
scores = self.rouge.get_scores(hyps=pred_title, refs=title)
rouge_1 += scores[0]['rouge-1']['f']
rouge_2 += scores[0]['rouge-2']['f']
rouge_l += scores[0]['rouge-l']['f']
bleu += sentence_bleu(references=[title.split(' ')],
hypothesis=pred_title.split(' '),
smoothing_function=self.smooth)
rouge_1 /= total
rouge_2 /= total
rouge_l /= total
bleu /= total
return {'rouge-1': rouge_1,'rouge-2': rouge_2, 'rouge-l': rouge_l,'bleu': bleu,}
所以,到这里你就知道,在训练过程中加入回调函数是干什么用的了,目的就是为了在模型训练的过程中,观察模型的训练效果,以及各种评价指标得分,比如Rouge和BLUE。每执行一次epoch,回调函数就执行一次,所以,本程序中evaluate()回调函数执行了20次。
接下来程序会自动使用Adam优化算法对参数进行求解。具体模型求解过程,这里就不介绍了。
到这为止,整个计算过程包括两部分,一个是data_generator(),这个上面已经详细介绍过,另一个是上面提到的autotitle.generate()函数。autotitle是AutoTitle()类的一个实例化。接下来就是深入研究AutoTitle()类,此类的父类是AutoRegressiveDecode(),通用自回归生成模型解码基类,其中包括两种包含beam search和random sample两种生成策略。AutoTitle调用关系如下提所示:
 首先这里有一个问题,这里面为什么evaluate()函数被调用20次,AutoTitle:generate()被调用了200次,原因是generate()被调用的次数 = epochs * len(data) ,我运行程序的时候训练数据只有 10 条,所以 20 * 10 =200次。
首先这里有一个问题,这里面为什么evaluate()函数被调用20次,AutoTitle:generate()被调用了200次,原因是generate()被调用的次数 = epochs * len(data) ,我运行程序的时候训练数据只有 10 条,所以 20 * 10 =200次。
但是predict() 函数为什么被调用了6400次,这里的函数调用时候有一个maxlen参数,这个参数运行时候被设置为32,循环执行的时候就是 200 * 32 = 6400。函数调用代码如下:
autotitle = AutoTitle(start_id=None,end_id=tokenizer._token_sep_id, maxlen=32)
接下来是generate() 函数和predict()函数:其中token_ids 就是一系列token_id的集合 [2, 710, 1792, 5496, 1367, 5402, 1663] ,在预测阶段segment_ids 都为0 [0, 0, 0, 0, 0, 0, 0] ,将token_ids和segment_ids打包成一个列表传入beam_search中。
class AutoTitle(AutoRegressiveDecoder):
@AutoRegressiveDecoder.set_rtype('probas')
def predict(self, inputs, output_ids, step):
token_ids, segment_ids = inputs
token_ids = np.concatenate([token_ids, output_ids], 1)
segment_ids = np.concatenate([segment_ids, np.ones_like(output_ids)], 1)
# model.predict()最终会返回一个3D张量,shape=[batch_size, seq_length, vocab_size]
# 这里的vocab_size = 13584
# model.predict()[:, -1]返回的形状是 shape = [batch_size, vocab_size], 输入的-1 表示最后一个词对应的预测输出
# 举例说明 加入最后模型返回的预测结果是这样的张量[[[1.7, 3.5, 1.8, 1.8, 4.0],
# [2.7, 9.86, 2.5, 5.5, 1.6],
# [8.5, 1.17, 1.5, 1.7, 3.4]]]
# 最后得到就是 [[8.5, 1.17, 1.5, 1.7, 3.4]] 而且在取完最后一行之后 还进行了取对数操作, 把很小的概率值都变成了 便于比较的负整数
return model.predict([token_ids, segment_ids])[:, -1]
def generate(self, text, topk=1):
max_c_len = maxlen - self.maxlen
# token_ids 就是一系列token_id的集合 [2, 710, 1792, 5496, 1367, 5402, 1663]
# 在预测阶段segment_ids 都为0 [0, 0, 0, 0, 0, 0, 0]
token_ids, segment_ids = tokenizer.encode(text, max_length=max_c_len)
# 将token_ids和segment_ids打包成一个列表传入beam_search中
output_ids = self.beam_search([token_ids, segment_ids], topk) # 基于beam search
return tokenizer.decode(output_ids)
由此可以看出,本程序最核心的函数就是beam_search() 函数,具体的beam_search的工作原理。参考知乎专栏:Seq2Seq中的beam search算法。
关于beam_search的解读
假设beam width设置为3 , 比如我们输入句子:你将是杜兰德号的驾驶人。
句子的 token_ids:[2, 770, 2097, 3119, 3234, 963, 2446, 1282, 4536, 7628, 7622, 680, 409, 3],其中2和3都是占位符。
句子的segments_ids:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
执行以下代码,将token_ids和segments_ids打包输入模型
inputs = [np.array([i]) for i in inputs]
此使inputs变成了:
[array([[2, 770, 2097, 3119, 3234, 963, 2446, 1282, 4536, 7628, 7622,680, 409, 3]]), array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])]
接下来执行代码:
output_ids, output_scores = self.first_output_ids, np.zeros(1)
其中output_ids为一个空的列表,由于没有设置第一个应该输出的token,所以未空,output_scores表示只有一个零元素的列表 [0.]
接下来开始执行循环,循环次数为最大句子长度maxlen:
for step in range(self.maxlen):
循环中第一行,要调用模型开始预测,执行代码如下:
scores = self.predict(inputs, output_ids, step, 'logits') # 计算当前得分
我们继续追踪,看看predict()中都进行了什么操作:
def predict(self, inputs, output_ids, step):
token_ids, segment_ids = inputs
token_ids = np.concatenate([token_ids, output_ids], 1)
segment_ids = np.concatenate([segment_ids, np.ones_like(output_ids)], 1)
# predict返回值是数值,表示样本属于每一个类别的概率
return model.predict([token_ids, segment_ids])[:, -1]
首先将得到已经被打包inputs的解包回 token_ids和segment_ids,还记得在生成代码的最初吗,刚刚将两个张量打包完,这里确实为方便书写和程序的封装,虽然看着麻烦了一点。这里执行了concatenate操作就是为了将预测得到的output_ids继续拼接到token_ids后面,作为模型输入,送到模型中继续预测下一个token。同样segment_ids也需要对segment进行延长,这里需要注意,原来的segment_ids都是0值,在拼接了预测得到连都token之后,segment_ids后面接的是1值。
接下来调用model.predict([token_ids, segment_ids])[:, -1] 得到预测输出,并且取输出的最后一行,这样原来的预测输出的shape=[1,14,13584],其中14等于句子长度12 加上两个占位符。取模型输出的最后一行张量,也就是最后一个词的预测输出,然后对预测的概率值进行取对数操作,将数值转换成负整数得到:
[[-27.630606 -6.658234 -21.368036 ... -26.930357 -27.602684 -27.622435]]
此使的shape = [1,13584],这就是scores的形状。预测数据如上所示。
现在可以继续回到循环的主题:
scores = self.predict(inputs, output_ids, step, 'logits') # 计算当前得分
if step == 0: # 第1步预测后将输入重复topk次
inputs = [np.repeat(i, topk, axis=0) for i in inputs]
当执行步数为第0步的时候,需要将inputs[token_ids, segments_ids]扩展成**3(beam width)**倍,这里的inputs 在此时变成了这样:
[array([[ 2, 770, 2097, 3119, 3234, 963, 2446, 1282, 4536, 7628, 7622,
680, 409, 3],
[ 2, 770, 2097, 3119, 3234, 963, 2446, 1282, 4536, 7628, 7622,
680, 409, 3],
[ 2, 770, 2097, 3119, 3234, 963, 2446, 1282, 4536, 7628, 7622,
680, 409, 3]]),
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])]
接下来开始执行这句:
scores = output_scores.reshape((-1, 1)) + scores # 综合累积得分
output_scores 初始为 [0.] ,scores就是就是模型的预测得分,每执行一次都会取最后一个词的模型预测输出。因此第零步的scores得分为:(与第一个预测词的得分完全一样)
[[-27.6306057 -6.65823412 -21.36803627 ... -26.93035698 -27.60268402 -27.62243462]]
接下来开始执行:
indices = scores.argpartition(-topk, axis=None)[-topk:] # 仅保留topk
indices_1 = indices // scores.shape[1] # 行索引
indices_2 = (indices % scores.shape[1]).reshape((-1, 1)) # 列索引
output_ids = np.concatenate([output_ids[indices_1], indices_2], 1) # 更新输出
其中indices保存得分最大的三个token的ID,所以indices = [3234 2798 770],这三个ID对应的分别是[杜,指,你],三个中文汉字。从这里可以看预测还是很准的。我们输入的第一个字就是”你“,预测的也是”你“,接下来的三行代码是为了将预测得到的三个token存储到output_ids中,output_ids=[[3234],[2798],[ 770]]
此使的output_ids已经是一个2D的tensor。
接下来开始执行:
output_scores = np.take_along_axis(scores, indices, axis=None) # 更新得分
best_one = output_scores.argmax() # 得分最大的那个
此使的output_scores已经由原来的整个词表得分,变成了现在分数最高的三个token的得分,output_scores=[-5.34703016 -4.34406328 -0.0301327 ],best_one表示得分最高的那个token下标,此时best_one=2
接下来开始进入到判断环节:end_id=3表示的是[SEP]句子终止符,当识别到[SEP]时,停止生成句子。
if indices_2[best_one, 0] == self.end_id: # 如果已经终止 返回best_one列的第0个元素
return output_ids[best_one] # 直接输出
else: # 否则,只保留未完成部分
flag = (indices_2[:, 0] != self.end_id) # 标记未完成序列
if not flag.all(): # 如果有已完成的
inputs = [i[flag] for i in inputs] # 扔掉已完成序列
output_ids = output_ids[flag] # 将output_ids重新赋值
output_scores = output_scores[flag] # 扔掉已完成序列
topk = flag.sum() # topk相应变化
到这里模型便可以生成第一个字,现在已经得到了”你“这个token,接下来执行第二次生成。此时要把上一次循环生成的”你“添加到输入序列,这次要把生成的topK个候选词分别拼接到最原始输入的句子后面,所以现在的模型输入如下所示:
[array([[2, 770, 2097, 3119, 3234,963, 2446, 1282, 4536, 7628, 7622,680,409,3,3234], [2,770, 2097, 3119, 3234, 963, 2446, 1282, 4536, 7628, 7622,680,409,3,2798], [2,770, 2097, 3119, 3234, 963, 2446, 1282, 4536, 7628, 7622,680,409,3,770]], dtype=int64),
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]], dtype=int64)]
这里可以看到第一次生成的三个token已经添加到了[SEP](3)的后面。所以这次模型预测返回的tensor的shape=[3, 15, 13584)],取最有一个token的输出预测得分scores:
[[-27.631021 -27.610153 -27.631021 ... -27.631021 -27.631021 -27.631021 ]
[-27.011091 -5.1853814 -19.943907 ... -22.983522 -27.11865 -27.588339 ]
[-27.631021 -19.464876 -27.63091 ... -27.630976 -27.631021 -27.631021 ]]
与之前计算得到的output_scores=[-5.34703016 -4.34406328 -0.0301327 ],相加得到新的scores:
[[-32.97805166 -32.95718336 -32.97805166 ... -32.97805166 -32.97805166 -32.97805166]
[-31.35515451 -9.52944469 -24.28797007 ... -27.3275857 -31.46271372 -31.93240213]
[-27.6611542 -19.49500887 -27.66104357 ... -27.66110842 -27.6611542 -27.6611542 ]]
然后返回每一行的概率最大的token_id,indices_2=[[3119] [963] [ 2097]],对应汉字【是,兰,将】
此时的output_ids保存了三组候选序列:[[ 770 3119] [3234 963] [ 770 2097]],接下来更新最高的三个token得分;output_scores= [-6.38893311 -5.34736949 -0.03293386],则best_one = 2,最佳预测token为“将”,接下来不断重复这个步骤就行,将每次产生得分最高的三个token添加到输入序列中,在得到的三组得分中再次选择三个得分最高的三个token,不断循环。