CNN之从头训练一个猫狗图片分类模型
猫狗图片下载地址:
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw
提取码:2xq4
说明:大概有816M大小,分为train和test,train有cat和dog标签作为图片名字。
一、建立训练、验证、测试图片集
import os
import shutil
original_dataset_dir = "/home/suanfa/picture/dogs-vs-cats/train/train"
base_dir = "dogs_and_cats_small"
os.makedirs(base_dir)
## TODO 建立训练、验证、测试文件夹
train_dir = os.path.join(base_dir, 'train')
os.makedirs(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.makedirs(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.makedirs(test_dir)
## TODO 建立猫狗训练文件夹
train_cats_dir = os.path.join(train_dir, 'cats')
os.makedirs(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.makedirs(train_dogs_dir)
## TODO 建立猫狗验证文件夹
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.makedirs(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.makedirs(validation_dogs_dir)
## TODO 建立猫狗测试文件夹
test_cats_dir = os.path.join(test_dir, 'cats')
os.makedirs(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.makedirs(test_dogs_dir)
## TODO 1000张猫训练图片
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
## TODO 500张猫验证图片
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
## TODO 500张猫测试证图片
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
## TODO 1000张狗训练图片
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
## TODO 1000张狗验证图片
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
## TODO 1000张狗测试图片
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
print("total training cat images: ", len(os.listdir(train_cats_dir)))
print("total training dog images: ", len(os.listdir(train_dogs_dir)))
print("total validation cat images: ", len(os.listdir(validation_cats_dir)))
print("total validation dog images: ", len(os.listdir(validation_dogs_dir)))
print("total test cat images: ", len(os.listdir(test_cats_dir)))
print("total test dog images: ", len(os.listdir(test_dogs_dir)))
运行的结果为:
total training cat images: 1000
total training dog images: 1000
total validation cat images: 500
total validation dog images: 500
total test cat images: 500
total test dog images: 500
二、构建CNN模型
from keras import layers
from keras import models
from keras import optimizers
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['acc'])
三、读取和处理图像
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255) # 像素归一
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
"./dogs_and_cats_small/train",
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
"./dogs_and_cats_small/validation",
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)
for data_batch, labels_batch in train_generator:
print("data batch shape: ", data_batch.shape)
print("labels batch shape: ", labels_batch.shape)
break
打印出来结果为:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
data batch shape: (20, 150, 150, 3)
labels batch shape: (20,)
四、训练和保存模型
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50
)
model.save('cats_and_dogs_small_1.h5')
五、绘制训练和验证的精度和损失曲线
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and Validation loss')
plt.legend()
plt.show()
训练和验证精度曲线图:

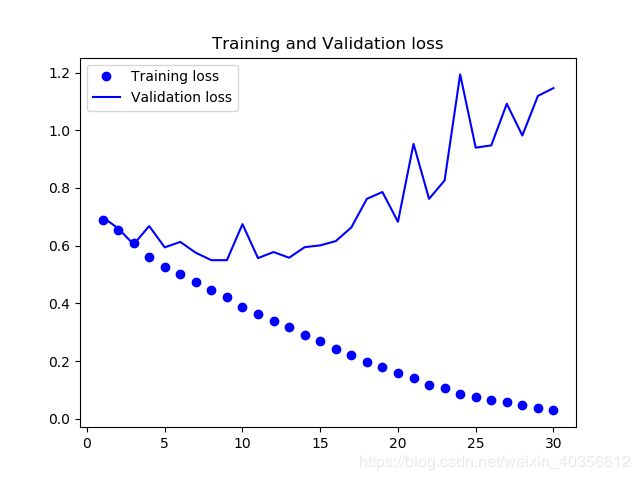
训练和验证损失曲线图:
六、结论
从以上图片可看出:
训练精度随时间线性增加,直到接近100%,而验证精度则停留在70%-72%
验证损失在10个epochs后达到最小,之后开始上升,而训练损失一直线性下降,直至接近0
因为仅有2000个训练样本,出现了过拟合,可以使用降低过拟合的方法:L2正则化或dropout,
然而,在用深度学习模型处理图像几乎总是用到:数据增强。
七、参考资料
- https://www.cnblogs.com/xiximayou/p/12372969.html#top
- 佛朗索瓦.肖莱著,张亮译. Python深度学习[M]. 人民邮电出版社.2018.8.p102-111.