ES6学习笔记(2019.7.29)
- ES6学习笔记(2019.7.29)
- let和const
- let
- let 基本用法
- let 不存在变量提升
- 暂时性死区
- 不允许重复声明
- 块级作用域
- 级作用域
- ES6的块级作用域
- 块级作用域与函数声明
- const
- 基本用法
- 本质
- 顶层对象
- let
- 解构赋值
- 数组的解构
- 基本用法
- 默认值
- 对象的解构
- 基本用法
- 默认值
- 注意点
- 字符串的解构
- 数值布尔值的解构
- 函数参数的解构
- 圆括号问题
- 不能使用圆括号的情况
- 可以使用圆括号的情况
- 用途
- for、for in、for of、foreach的用法和区别
- 遍历对象
- Object.keys(o)
- Object.getOwnPropertyNames(o)
- Reflect.ownKeys(o)
- 数组的解构
- 字符串的扩展
- 字符的unicode表示法
- 字符串的遍历
- 模板字符串
- 字符串新增方法
- String.fromCodePoint()
- includes(), startsWith(), endsWith()
- repeat()
- padStart(),padEnd()
- trimStart(),trimEnd()
- 函数的扩展
- 函数参数的默认值
- 基本用法
- 解构赋值默认值结合使用
- 参数默认值的位置
- 函数length属性
- 作用域
- 应用
- rest参数
- 严格模式
- name属性
- 箭头函数
- 基本用法
- 注意点
- 不适用场合
- 嵌套的箭头函数
- 尾调用优化
- 什么是尾调用
- 尾调用优化
- 尾递归
- 递归函数的改写
- JS函数柯里化
- 面试题add()
- arguments转化为数组
- 严格模式
- 尾递归优化的实现
- 函数参数的尾逗号
- Function.prototype.toString()
- catch 命令的参数省略
- 函数参数的默认值
- 手写call apply bind
- 手写call
- 手写apply
- 手写bind
- 类型转换
- {} + [] 和 [] + {}
- [] == ![]为true,而 {} == !{}为false
- JS中数据类型的判断
- typeof
- instanceof
- constructor
- Object.prototype.toString.call()
- Object.prototype.toString.call() 对数据类型检测进行封装:
- 面试题:
- 数组的扩展
- 扩展运算符
- 替代函数的apply方法
- 扩展运算符的应用
- Array.from
- 扩展运算符
- let和const
let和const
let
let 基本用法
-
let声明的变量只在它所在的代码块(花括号)有效。{ let a = 10; var b = 1; } a // ReferenceError: a is not defined. b -
for循环的计数器,合适使用let命令, i用var命令声明的话,在全局范围内都有效。 -
另外,
for循环还有一个特别之处,就是设置循环变量的那部分是一个父作用域,而循环体内部是一个单独的子作用域。for (let i = 0; i < 3; i++) { let i = 'abc'; console.log(i); } // abc // abc // abc
let 不存在变量提升
暂时性死区
-
ES6 明确规定,如果区块中存在
let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。var tmp = 123; if (true) { tmp = 'abc'; // ReferenceError let tmp; } typeof x; // ReferenceError (typeof不再是一个百分之百安全的操作) let x;function bar(x = y, y = 2) { return [x, y]; } bar(); // 报错
调用bar函数之所以报错(某些实现可能不报错),是因为参数x默认值等于另一个参数y,而此时y还没有声明,属于“死区”。如果y的默认值是x,就不会报错.
不允许重复声明
let不允许在相同作用域内,重复声明同一个变量。
// 报错
function func() {
let a = 10;
var a = 1;
}
// 报错
function func() {
let a = 10;
let a = 1;
}
//因此,不能在函数内部重新声明参数。
function func(arg) {
let arg;
}
func() // 报错
function func(arg) {
{
let arg;
}
}
func() // 不报错
块级作用域
级作用域
ES5 只有全局作用域和函数作用域,没有块级作用域,带来很多不合理的场景:
- 内层变量可能会覆盖外层变量,变量提升,导致内层的
tmp变量覆盖了外层的tmp变量。
var tmp = new Date();
function f() {
console.log(tmp);
if (false) {
var tmp = 'hello world';
}
}
f(); // undefined
- 计数的循环变量泄露为全局变量。
var s = 'hello';
for (var i = 0; i < s.length; i++) {
console.log(s[i]);
}
console.log(i); // 5
ES6的块级作用域
- 外层代码块不受内层代码块的影响。如果两次都使用
var定义变量n,最后输出的值才是 10。
function f1() {
let n = 5;
if (true) {
let n = 10;
}
console.log(n); // 5
}
- ES6 允许块级作用域的任意嵌套,第四层作用域无法读取第五层作用域的内部变量。
{{{{
{let insane = 'Hello World'}
console.log(insane); // 报错
}}}};
- 内层作用域可以定义外层作用域的同名变量。
{{{{
let insane = 'Hello World';
{let insane = 'Hello World'}
}}}};
- 块级作用域的出现,实际上使得获得广泛应用的匿名立即执行函数表达式(匿名 IIFE)不再必要了。
// IIFE 写法
(function () {
var tmp = ...;
...
}());
// 块级作用域写法
{
let tmp = ...;
块级作用域与函数声明
- ES5 规定,函数只能在顶层作用域和函数作用域之中声明,不能在块级作用域声明。
// 情况一
if (true) {
function f() {}
}
// 情况二
try {
function f() {}
} catch(e) {
// ...
}
上面两种函数声明,根据 ES5 的规定都是非法的。
但是,浏览器没有遵守这个规定,为了兼容以前的旧代码,还是支持在块级作用域之中声明函数,因此上面两种情况实际都能运行,不会报错。
- ES6 引入了块级作用域,明确允许在块级作用域之中声明函数。ES6 规定,块级作用域之中,函数声明语句的行为类似于
let,在块级作用域之外不可引用。
function f() { console.log('I am outside!'); }
(function () {
if (false) {
// 重复声明一次函数f
function f() { console.log('I am inside!'); }
}
f();
}());
上面代码在 ES5 中运行,会得到“I am inside!”,因为在if内声明的函数f会被提升到函数头部,实际运行的代码如下。
// ES5 环境
function f() { console.log('I am outside!'); }
(function () {
function f() { console.log('I am inside!'); }
if (false) {
}
f();
}());
ES6 理论上会得到“I am outside!”。因为块级作用域内声明的函数类似于let,对作用域之外没有影响。但是,在 ES6 浏览器中运行一下上面的代码,是会报错的,改变了块级作用域内声明的函数的处理规则,显然会对老代码产生很大影响。为了减轻因此产生的不兼容问题,ES6 在附录 B里面规定,浏览器的实现可以不遵守上面的规定,有自己的行为方式。
- 允许在块级作用域内声明函数。
- 函数声明类似于
var,即会提升到全局作用域或函数作用域的头部。 - 同时,函数声明还会提升到所在的块级作用域的头部。
考虑到环境导致的行为差异太大,应该避免在块级作用域内声明函数。如果确实需要,也应该写成函数表达式,而不是函数声明语句。
// 块级作用域内部的函数声明语句,建议不要使用
{
let a = 'secret';
function f() {
return a;
}
}
// 块级作用域内部,优先使用函数表达式
{
let a = 'secret';
let f = function () {
return a;
};
}
- 有一个需要注意的地方。ES6 的块级作用域必须有大括号
// 第一种写法,报错
if (true) let x = 1;
// 第二种写法,不报错
if (true) {
let x = 1;
}
const
基本用法
-
const声明一个只读的常量。一旦声明,常量的值就不能改变。const PI = 3.1415; PI // 3.1415 PI = 3;// TypeError: Assignment to constant variable. -
const一旦声明变量,就必须立即初始化,不能留到以后赋值。const foo; // SyntaxError: Missing initializer in const declaration -
与
let命令相同:只在声明所在的块级作用域内有效。if (true) { const MAX = 5; } MAX // Uncaught ReferenceError: MAX is not defined -
声明的常量不提升,存在暂时性死区,只能在声明的位置后面使用。
if (true) { console.log(MAX); // ReferenceError const MAX = 5; } -
const声明的常量,也与let一样不可重复声明。var message = "Hello!"; let age = 25; // 以下两行都会报错 const message = "Goodbye!"; const age = 30;
本质
const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址所保存的数据不得改动。对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指向实际数据的指针,const只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。因此,将一个对象声明为常量必须非常小心。
const foo = {};
// 为 foo 添加一个属性,可以成功
foo.prop = 123;
foo.prop // 123
// 将 foo 指向另一个对象,就会报错
foo = {}; // TypeError: "foo" is read-only
const a = [];
a.push('Hello'); // 可执行
a.length = 0; // 可执行
a = ['Dave']; // 报错
上面代码中,常量a是一个数组,这个数组本身是可写的,但是如果将另一个数组赋值给a,就会报错。
如果真的想将对象冻结,应该使用Object.freeze方法。
const foo = Object.freeze({});
// 常规模式时,下面一行不起作用;
// 严格模式时,该行会报错
foo.prop = 123;
var constantize = (obj) => {
Object.freeze(obj);
Object.keys(obj).forEach( (key, i) => {
if ( typeof obj[key] === 'object' ) {
constantize( obj[key] );
}
});
};
上面是一个将对象彻底冻结的函数。
顶层对象
顶层对象,在浏览器环境指的是window对象,在 Node 指的是global对象。ES5 之中,顶层对象的属性与全局变量是等价的。
window.a = 1;
a // 1
a = 2;
在ES6 中,为了改变这一点,一方面为了保持兼容性,var命令和function命令声明的全局变量,依旧是顶层对象的属性;另一方面规定,let命令、const命令、class命令声明的全局变量,不属于顶层对象的属性。也就是说,从 ES6 开始,全局变量将逐步与顶层对象的属性脱钩。
var a = 1;
// 如果在 Node 的 REPL 环境,可以写成 global.a
// 或者采用通用方法,写成 this.a
window.a // 1
let b = 1;
window.b // undefined
解构赋值
数组的解构
基本用法
ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring)。
以前,为变量赋值,只能直接指定值。
let a = 1;
let b = 2;
let c = 3;
- ES6 允许写成下面这样。从数组中提取值,按照对应位置,对变量赋值。
let [a, b, c] = [1, 2, 3];
下面是对嵌套数组进行解构的例子
let [foo, [[bar], baz]] = [1, [[2], 3]];
foo // 1
bar // 2
baz // 3
let [ , , third] = ["foo", "bar", "baz"];
third // "baz"
let [x, , y] = [1, 2, 3];
x // 1
y // 3
let [head, ...tail] = [1, 2, 3, 4];
head // 1
tail // [2, 3, 4]
let [x, y, ...z] = ['a'];
x // "a"
y // undefined
z // []
- 如果解构不成功,变量的值就等于
undefined。
let [foo] = [];
let [bar, foo] = [1];
// foo的值都等于undefined
- 另一种情况是不完全解构,即等号左边的模式,只匹配一部分的等号右边的数组
let [x, y] = [1, 2, 3];
x // 1
y // 2
let [a, [b], d] = [1, [2, 3], 4];
a // 1
b // 2
d // 4
- 如果等号的右边不是数组(或者严格地说,不是可遍历的结构,参见《Iterator》一章),那么将会报错。
// 报错
let [foo] = 1;
let [foo] = false;
let [foo] = NaN;
let [foo] = undefined;
let [foo] = null;
let [foo] = {};
- 对于 Set 结构,也可以使用数组的解构赋值。
let [x, y, z] = new Set(['a', 'b', 'c']);
x // "a"
默认值
- 解构赋值允许指定默认值。
let [foo = true] = [];
foo // true
let [x, y = 'b'] = ['a']; // x='a', y='b'
let [x, y = 'b'] = ['a', undefined]; // x='a', y='b'
- 只有当一个数组成员严格等于
undefined,默认值才会生效。因为null不严格等于undefined。
let [x = 1] = [undefined];
x // 1
let [x = 1] = [null];
x // null
- 如果默认值是一个表达式,那么这个表达式是惰性求值的,即只有在用到的时候,才会求值。
function f() {
console.log('aaa');
}
let [x = f()] = [1];
//因为x能取到值,所以函数f根本不会执行。
- 默认值可以引用解构赋值的其他变量,但该变量必须已经声明。
let [x = 1, y = x] = []; // x=1; y=1
let [x = 1, y = x] = [2]; // x=2; y=2
let [x = 1, y = x] = [1, 2]; // x=1; y=2
let [x = y, y = 1] = []; // ReferenceError: y is not defined
上面最后一个表达式之所以会报错,是因为x用y做默认值时,y还没有声明。
对象的解构
基本用法
解构不仅可以用于数组,还可以用于对象。
- 对象的解构与数组有一个重要的不同。数组的元素是按次序排列的,变量的取值由它的位置决定;而对象的属性没有次序,变量必须与属性同名,才能取到正确的值。
let { bar, foo } = { foo: 'aaa', bar: 'bbb' };
foo // "aaa"
bar // "bbb"
let { baz } = { foo: 'aaa', bar: 'bbb' };
baz // undefined
-
解构不成功,变量的值就等于
undefined。 -
对象的解构赋值,可以很方便地将现有对象的方法,赋值到某个变量。
// 例一
let { log, sin, cos } = Math;
// 例二
const { log } = console;
log('hello') // hello
- 如果变量名与属性名不一致,必须写成下面这样。
let { foo: baz } = { foo: 'aaa', bar: 'bbb' };
baz // "aaa"
let obj = { first: 'hello', last: 'world' };
let { first: f, last: l } = obj;
f // 'hello'
l // 'world'
这实际上说明,对象的解构赋值是下面形式的简写
let { foo: foo, bar: bar } = { foo: 'aaa', bar: 'bbb' };
也就是说,对象的解构赋值的内部机制,是先找到同名属性,然后再赋给对应的变量。真正被赋值的是后者,而不是前者。
let { foo: baz } = { foo: 'aaa', bar: 'bbb' };
baz // "aaa"
foo // error: foo is not defined
上面代码中,foo是匹配的模式,baz才是变量。真正被赋值的是变量baz,而不是模式foo。
- 解构也可以用于嵌套结构的对象。
let obj = {
p: [
'Hello',
{ y: 'World' }
]
};
let { p: [x, { y }] } = obj;
x // "Hello"
y // "World"
注意,这时p是模式,不是变量,因此不会被赋值。如果p也要作为变量赋值,可以写成下面这样。
let obj = {
p: [
'Hello',
{ y: 'World' }
]
};
let { p, p: [x, { y }] } = obj;
x // "Hello"
y // "World"
p // ["Hello", {y: "World"}]
- 如果解构模式是嵌套的对象,而且子对象所在的父属性不存在,那么将会报错。
// 报错
let {foo: {bar}} = {baz: 'baz'};
foo这时等于undefined,再取子属性就会报错。
默认值
对象的解构也可以指定默认值。
var {x = 3} = {};
x // 3
var {x, y = 5} = {x: 1};
x // 1
y // 5
var {x: y = 3} = {};
y // 3
var {x: y = 3} = {x: 5};
y // 5
var { message: msg = 'Something went wrong' } = {};
msg // "Something went wrong"
- 默认值生效的条件是,对象的属性值严格等于
undefined。同数组一样。
注意点
- 如果要将一个已经声明的变量用于解构赋值,必须非常小心。
// 错误的写法
let x;
{x} = {x: 1};
// SyntaxError: syntax error
JavaScript 引擎会将{x}理解成一个代码块,从而发生语法错误。只有不将大括号写在行首,避免 JavaScript 将其解释为代码块,才能解决这个问题。
// 正确的写法
let x;
({x} = {x: 1});
- 解构赋值允许等号左边的模式之中,不放置任何变量名。因此,可以写出非常古怪的赋值表达式。表达式虽然毫无意义,但是语法是合法的,可以执行。
({} = [true, false]);
({} = 'abc');
({} = []);
- 由于数组本质是特殊的对象,因此可以对数组进行对象属性的解构
let arr = [1, 2, 3];
let {0 : first, [arr.length - 1] : last} = arr;
first // 1
last // 3
字符串的解构
字符串也可以解构赋值。这是因为此时,字符串被转换成了一个类似数组的对象。
const [a, b, c, d, e] = 'hello';
a // "h"
b // "e"
c // "l"
d // "l"
e // "o"
类似数组的对象都有一个length属性,因此还可以对这个属性解构赋值。
let {length : len} = 'hello';
len // 5
数值布尔值的解构
解构赋值时,如果等号右边是数值和布尔值,则会先转为对象。
let {toString: s} = 123;
s === Number.prototype.toString // true
let {toString: s} = true;
s === Boolean.prototype.toString // true
数值和布尔值的包装对象都有toString属性,因此变量s都能取到值。
函数参数的解构
- 函数的参数也可以使用解构赋值。
function add([x, y]){
return x + y;
}
add([1, 2]); // 3
上面代码中,函数add的参数表面上是一个数组,但在传入参数的那一刻,数组参数就被解构成变量x和y。对于函数内部的代码来说,它们能感受到的参数就是x和y。
例二:
[[1, 2], [3, 4]].map(([a, b]) => a + b);
- 函数参数的解构也可以使用默认值(必须在前面)
function move({x = 0, y = 0} = {}) {
return [x, y];
}
move({x: 3, y: 8}); // [3, 8]
move({x: 3}); // [3, 0]
move({}); // [0, 0]
move(); // [0, 0]
注意,下面的写法会得到不一样的结果。
function move({x, y} = { x: 0, y: 0 }) {
return [x, y];
}
move({x: 3, y: 8}); // [3, 8]
move({x: 3}); // [3, undefined]
move({}); // [undefined, undefined]
move(); // [0, 0]
上面代码是为函数move的参数指定默认值,而不是为变量x和y指定默认值,所以会得到与前一种写法不同的结果。
undefined就会触发函数参数的默认值。
[1, undefined, 3].map((x = 'yes') => x);
// [ 1, 'yes', 3 ]
圆括号问题
解构赋值虽然很方便,但是解析起来并不容易。对于编译器来说,一个式子到底是模式,还是表达式,没有办法从一开始就知道,必须解析到(或解析不到)等号才能知道。
不能使用圆括号的情况
- 变量声明语句
// 全部报错
let [(a)] = [1];
let {x: (c)} = {};
let ({x: c}) = {};
let {(x: c)} = {};
let {(x): c} = {};
let { o: ({ p: p }) } = { o: { p: 2 } };
上面6 个语句都会报错,因为它们都是变量声明语句,模式不能使用圆括号。
- 函数参数
// 报错
function f([(z)]) { return z; }
// 报错
function f([z,(x)]) { return x; }
函数参数也属于变量声明,因此不能带有圆括号。
- 赋值语句的模式
// 全部报错
({ p: a }) = { p: 42 };
([a]) = [5];
上面代码将整个模式放在圆括号之中,导致报错。
// 报错
[({ p: a }), { x: c }] = [{}, {}];
上面代码将一部分模式放在圆括号之中,导致报错。
可以使用圆括号的情况
可以使用圆括号的情况只有一种:赋值语句的非模式部分即需要赋值的变量,可以使用圆括号。
[(b)] = [3]; // 正确
({ p: (d) } = {}); // 正确
[(parseInt.prop)] = [3]; // 正确
用途
- 交换变量的值
let x = 1;
let y = 2;
[x, y] = [y, x];
-
从函数返回多个值
函数只能返回一个值,如果要返回多个值,只能将它们放在数组或对象里返回。有了解构赋值,取出这些值就非常方便。
// 返回一个数组
function example() {
return [1, 2, 3];
}
let [a, b, c] = example();
// 返回一个对象
function example() {
return {
foo: 1,
bar: 2
};
}
let { foo, bar } = example();
-
函数参数的定义
解构赋值可以方便地将一组参数与变量名对应起来
// 参数是一组有次序的值
function f([x, y, z]) { ... }
f([1, 2, 3]);
// 参数是一组无次序的值
function f({x, y, z}) { ... }
f({z: 3, y: 2, x: 1});
- 提取 JSON 数据
let jsonData = {
id: 42,
status: "OK",
data: [867, 5309]
};
let { id, status, data: number } = jsonData;
console.log(id, status, number);
// 42, "OK", [867, 5309]
- 函数参数的默认值
jQuery.ajax = function (url, {
async = true,
beforeSend = function () {},
cache = true,
complete = function () {},
crossDomain = false,
global = true,
// ... more config
} = {}) {
// ... do stuff
};
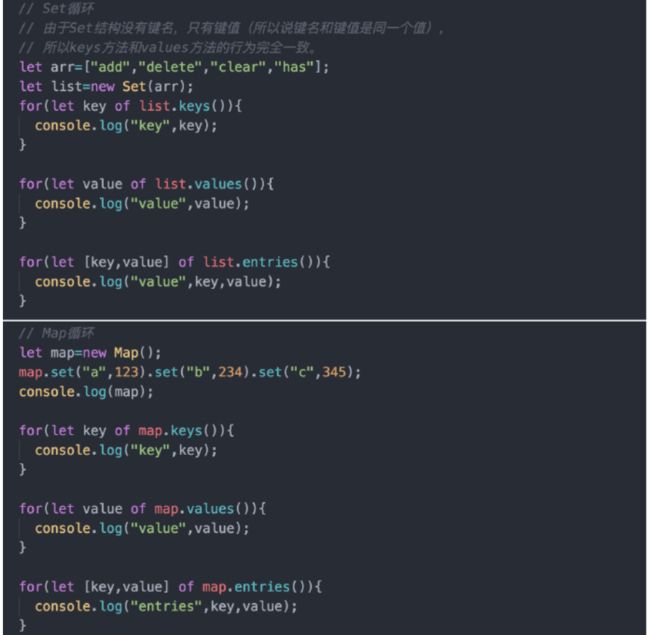
- 遍历 Map 结构
const map = new Map();
map.set('first', 'hello');
map.set('second', 'world');
for (let [key, value] of map) {
console.log(key + " is " + value);
}
// first is hello
// second is world
如果只想获取键名,或者只想获取键值,可以写成下面这样。
// 获取键名
for (let [key] of map) {
// ...
}
// 获取键值
for (let [,value] of map) {
// ...
}
- 输入模块的指定方法
const { SourceMapConsumer, SourceNode } = require("source-map");
for、for in、for of、foreach的用法和区别
一、普通for循环在Array和Object中都可以使用。

二、for in在Array和Object中都可以使用。
注意:在对象中包含原型上的属性。

三、for of在Array、Object、Set、Map中都可以使用。
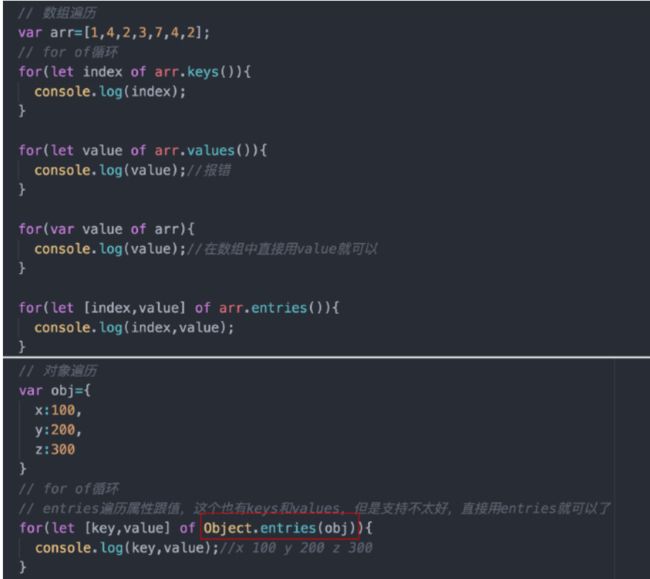
四、forEach循环在Array、Set、Map中都可以使用。

遍历对象
Object.keys(o)
返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含Symbol属性).
var obj = {'0':'a','1':'b','2':'c'};
Object.keys(obj).forEach(function(key){
console.log(key,obj[key]);
});
Object.getOwnPropertyNames(o)
返回一个数组,包含对象自身的所有属性(不含Symbol属性,但是包括不可枚举属性).
var obj = {'0':'a','1':'b','2':'c'};
Object.getOwnPropertyNames(obj).forEach(function(key){
console.log(key,obj[key]);
});
Reflect.ownKeys(o)
返回一个数组,包含对象自身的所有属性,不管属性名是Symbol或字符串,也不管是否可枚举.
var obj = {'0':'a','1':'b','2':'c'};
Reflect.ownKeys(obj).forEach(function(key){
console.log(key,obj[key]);
});
字符串的扩展
字符的unicode表示法
ES6 加强了对 Unicode 的支持,允许采用\uxxxx形式表示一个字符,其中xxxx表示字符的 Unicode 码点。
"\u0061"
// "a"
这种表示法只限于码点在\u0000~\uFFFF之间的字符。超出这个范围的字符,必须用两个双字节的形式表示。
"\uD842\uDFB7"
// ""
"\u20BB7"
// " 7"
ES6 对这一点做出了改进,只要将码点放入大括号,就能正确解读该字符。
"\u{20BB7}"
// ""
"\u{41}\u{42}\u{43}"
// "ABC"
let hello = 123;
hell\u{6F} // 123
'\u{1F680}' === '\uD83D\uDE80'
// true
有了这种表示法之后,JavaScript 共有 6 种方法可以表示一个字符。
'\z' === 'z' // true
'\172' === 'z' // true
'\x7A' === 'z' // true
'\u007A' === 'z' // true
'\u{7A}' === 'z' // true
字符串的遍历
ES6 为字符串添加了遍历器接口(详见《Iterator》一章),使得字符串可以被for...of循环遍历。
for (let codePoint of 'foo') {
console.log(codePoint)
}
// "f"
// "o"
// "o"
这个遍历器最大的优点是可以识别大于0xFFFF的码点,传统的for循环无法识别这样的码点。
let text = String.fromCodePoint(0x20BB7);
for (let i = 0; i < text.length; i++) {
console.log(text[i]);
}
// " "
// " "
for (let i of text) {
console.log(i);
}
// ""
模板字符串
模板字符串(template string)是增强版的字符串,用反引号(`)标识。它可以当作普通字符串使用,也可以用来定义多行字符串,或者在字符串中嵌入变量。
// 普通字符串
`In JavaScript '\n' is a line-feed.`
// 多行字符串
`In JavaScript this is
not legal.`
console.log(`string text line 1
string text line 2`);
// 字符串中嵌入变量
let name = "Bob", time = "today";
`Hello ${name}, how are you ${time}?`
如果在模板字符串中需要使用反引号,则前面要用反斜杠转义。
let greeting = `\`Yo\` World!`;
$('#list').html(`
- first
- second
`);
上面代码中,所有模板字符串的空格和换行,都是被保留的,比如trim方法消除它。
$('#list').html(`
- first
- second
`.trim());
模板字符串中嵌入变量,需要将变量名写在${}之中。
function authorize(user, action) {
if (!user.hasPrivilege(action)) {
throw new Error(
// 传统写法为
// 'User '
// + user.name
// + ' is not authorized to do '
// + action
// + '.'
`User ${user.name} is not authorized to do ${action}.`);
}
}
大括号内部可以放入任意的 JavaScript 表达式,可以进行运算,以及引用对象属性。
let x = 1;
let y = 2;
`${x} + ${y} = ${x + y}`
// "1 + 2 = 3"
`${x} + ${y * 2} = ${x + y * 2}`
// "1 + 4 = 5"
let obj = {x: 1, y: 2};
`${obj.x + obj.y}`
// "3"
模板字符串之中还能调用函数。
function fn() {
return "Hello World";
}
`foo ${fn()} bar`
// foo Hello World bar
如果大括号中的值不是字符串,将按照一般的规则转为字符串。比如,大括号中是一个对象,将默认调用对象的toString方法。
// 变量place没有声明
let msg = `Hello, ${place}`;
// 报错
由于模板字符串的大括号内部,就是执行 JavaScript 代码,因此如果大括号内部是一个字符串,将会原样输出。由于模板字符串的大括号内部,就是执行 JavaScript 代码,因此如果大括号内部是一个字符串,将会原样输出。
`Hello ${'World'}`
// "Hello World"
模板字符串甚至还能嵌套。
const tmpl = addrs => `
${addrs.map(addr => `
${addr.first} ${addr.last}
`;
const data = [
{ first: '', last: 'Bond' },
{ first: 'Lars', last: '' },
];
console.log(tmpl(data));
//
//
// Bond Lars
字符串新增方法
String.fromCodePoint()
ES5 提供String.fromCharCode()方法,用于从 Unicode 码点返回对应字符,但是这个方法不能识别码点大于0xFFFF的字符。
ES6 提供了String.fromCodePoint()方法,可以识别大于0xFFFF的字符,弥补了String.fromCharCode()方法的不足。在作用上,正好与下面的codePointAt()方法相反。
includes(), startsWith(), endsWith()
传统上,JavaScript 只有indexOf方法,可以用来确定一个字符串是否包含在另一个字符串中。ES6 又提供了三种新方法。
- includes():返回布尔值,表示是否找到了参数字符串。
- startsWith():返回布尔值,表示参数字符串是否在原字符串的头部。
- endsWith():返回布尔值,表示参数字符串是否在原字符串的尾部。
let s = 'Hello world!';
s.startsWith('Hello') // true
s.endsWith('!') // true
s.includes('o') // true
这三个方法都支持第二个参数,表示开始搜索的位置。
let s = 'Hello world!';
s.startsWith('world', 6) // true
s.endsWith('Hello', 5) // true
s.includes('Hello', 6) // false
上面代码表示,使用第二个参数n时,endsWith的行为与其他两个方法有所不同。它针对前n个字符,而其他两个方法针对从第n个位置直到字符串结束。
repeat()
repeat方法返回一个新字符串,表示将原字符串重复n次。
'x'.repeat(3) // "xxx"
'hello'.repeat(2) // "hellohello"
'na'.repeat(0) // ""
参数如果是小数,会被取整。
'na'.repeat(2.9) // "nana"
如果repeat的参数是负数或者Infinity,会报错。
但是,如果参数是 0 到-1 之间的小数,则等同于 0,这是因为会先进行取整运算。0 到-1 之间的小数,取整以后等于-0,repeat视同为 0。
'na'.repeat(-0.9) // ""
参数NaN等同于 0。
如果repeat的参数是字符串,则会先转换成数字。
'na'.repeat('na') // ""
'na'.repeat('3') // "nanana"
padStart(),padEnd()
ES2017 引入了字符串补全长度的功能。如果某个字符串不够指定长度,会在头部或尾部补全。padStart()用于头部补全,padEnd()用于尾部补全。
'x'.padStart(5, 'ab') // 'ababx'
'x'.padStart(4, 'ab') // 'abax'
'x'.padEnd(5, 'ab') // 'xabab'
'x'.padEnd(4, 'ab') // 'xaba'
如果原字符串的长度,等于或大于最大长度,则字符串补全不生效,返回原字符串。
如果用来补全的字符串与原字符串,两者的长度之和超过了最大长度,则会截去超出位数的补全字符串。
'abc'.padStart(10, '0123456789')
// '0123456abc'
如果省略第二个参数,默认使用空格补全长度。
'x'.padStart(4) // ' x'
'x'.padEnd(4) // 'x '
padStart()的常见用途是为数值补全指定位数。下面代码生成 10 位的数值字符串。
'1'.padStart(10, '0') // "0000000001"
'12'.padStart(10, '0') // "0000000012"
'123456'.padStart(10, '0') // "0000123456"
另一个用途是提示字符串格式。
'12'.padStart(10, 'YYYY-MM-DD') // "YYYY-MM-12"
'09-12'.padStart(10, 'YYYY-MM-DD') // "YYYY-09-12"
trimStart(),trimEnd()
ES2019 对字符串实例新增了trimStart()和trimEnd()这两个方法。它们的行为与trim()一致,trimStart()消除字符串头部的空格,trimEnd()消除尾部的空格。它们返回的都是新字符串,不会修改原始字符串。
const s = ' abc ';
s.trim() // "abc"
s.trimStart() // "abc "
s.trimEnd() // " abc"
函数的扩展
函数参数的默认值
基本用法
ES6 之前,不能直接为函数的参数指定默认值,只能采用变通的方法。
function log(x, y) {
y = y || 'World';
console.log(x, y);
}
log('Hello') // Hello World
log('Hello', 'China') // Hello China
log('Hello', '') // Hello World
这种写法的缺点在于,如果参数y赋值了,但是对应的布尔值为false,则该赋值不起作用。就像上面代码的最后一行,参数y等于空字符,结果被改为默认值。
为了避免这个问题,通常需要先判断一下参数y是否被赋值,如果没有,再等于默认值。
if (typeof y === 'undefined') {
y = 'World';
}
ES6 允许为函数的参数设置默认值,即直接写在参数定义的后面。
function log(x, y = 'World') {
console.log(x, y);
}
log('Hello') // Hello World
log('Hello', 'China') // Hello China
log('Hello', '') // Hello
参数变量是默认声明的,所以不能用let或const再次声明
一个容易忽略的地方是,参数默认值不是传值的,而是每次都重新计算默认值表达式的值。也就是说,参数默认值是惰性求值的。
let x = 99;
function foo(p = x + 1) {
console.log(p);
}
foo() // 100
x = 100;
foo() // 101
上面代码中,参数p的默认值是x + 1。这时,每次调用函数foo,都会重新计算x + 1,而不是默认p等于 100。
解构赋值默认值结合使用
function foo({x, y = 5}) {
console.log(x, y);
}
foo({}) // undefined 5
foo({x: 1}) // 1 5
foo({x: 1, y: 2}) // 1 2
foo() // TypeError: Cannot read property 'x' of undefined
上面代码只使用了对象的解构赋值默认值,没有使用函数参数的默认值。只有当函数foo的参数是一个对象时,变量x和y才会通过解构赋值生成。如果函数foo调用时没提供参数,变量x和y就不会生成,从而报错。通过提供函数参数的默认值,就可以避免这种情况。
function foo({x, y = 5} = {}) {
console.log(x, y);
}
foo() // undefined 5
上面代码指定,如果没有提供参数,函数foo的参数默认为一个空对象。
下面是另一个解构赋值默认值的例子。
function fetch(url, { body = '', method = 'GET', headers = {} }) {
console.log(method);
}
fetch('http://example.com', {})
// "GET"
fetch('http://example.com')
// 报错
练习:
// 写法一
function m1({x = 0, y = 0} = {}) {
return [x, y];
}
// 写法二
function m2({x, y} = { x: 0, y: 0 }) {
return [x, y];
}
上面两种写法都对函数的参数设定了默认值,区别是写法一函数参数的默认值是空对象,但是设置了对象解构赋值的默认值;写法二函数参数的默认值是一个有具体属性的对象,但是没有设置对象解构赋值的默认值。
// 函数没有参数的情况
m1() // [0, 0]
m2() // [0, 0]
// x 和 y 都有值的情况
m1({x: 3, y: 8}) // [3, 8]
m2({x: 3, y: 8}) // [3, 8]
// x 有值,y 无值的情况
m1({x: 3}) // [3, 0]
m2({x: 3}) // [3, undefined]
// x 和 y 都无值的情况
m1({}) // [0, 0];
m2({}) // [undefined, undefined]
m1({z: 3}) // [0, 0]
m2({z: 3}) // [undefined, undefined]
参数默认值的位置
通常情况下,定义了默认值的参数,应该是函数的尾参数。因为这样比较容易看出来,到底省略了哪些参数。如果非尾部的参数设置默认值,实际上这个参数是没法省略的。
// 例一
function f(x = 1, y) {
return [x, y];
}
f() // [1, undefined]
f(2) // [2, undefined])
f(, 1) // 报错
f(undefined, 1) // [1, 1]
// 例二
function f(x, y = 5, z) {
return [x, y, z];
}
f() // [undefined, 5, undefined]
f(1) // [1, 5, undefined]
f(1, ,2) // 报错
f(1, undefined, 2) // [1, 5, 2]
上面代码中,有默认值的参数都不是尾参数。这时,无法只省略该参数,而不省略它后面的参数,除非显式输入undefined。
如果传入undefined,将触发该参数等于默认值,null则没有这个效果。
函数length属性
指定了默认值以后,函数的length属性,将返回没有指定默认值的参数个数。也就是说,指定了默认值后,length属性将失真。
(function (a) {}).length // 1
(function (a = 5) {}).length // 0
(function (a, b, c = 5) {}).length // 2
如果设置了默认值的参数不是尾参数,那么length属性也不再计入后面的参数了。
(function (a = 0, b, c) {}).length // 0
(function (a, b = 1, c) {}).length // 1
作用域
一旦设置了参数的默认值,函数进行声明初始化时,参数会形成一个单独的作用域(context)。等到初始化结束,这个作用域就会消失。这种语法行为,在不设置参数默认值时,是不会出现的。
var x = 1;
function f(x, y = x) {
console.log(y);
}
f(2) // 2
上面代码中,参数y的默认值等于变量x。调用函数f时,参数形成一个单独的作用域。在这个作用域里面,默认值变量x指向第一个参数x,而不是全局变量x,所以输出是2。
let x = 1;
function f(y = x) {
let x = 2;
console.log(y);
}
f() // 1
上面代码中,函数f调用时,参数y = x形成一个单独的作用域。这个作用域里面,变量x本身没有定义,所以指向外层的全局变量x。函数调用时,函数体内部的局部变量x影响不到默认值变量x。
如果此时,全局变量x不存在,就会报错。
function f(y = x) {
let x = 2;
console.log(y);
}
f() // ReferenceError: x is not defined
下面这样写,也会报错。
var x = 1;
function foo(x = x) {
// ...
}
foo() // ReferenceError: x is not defined
上面代码中,参数x = x形成一个单独作用域。实际执行的是let x = x,由于暂时性死区的原因,这行代码会报错”x 未定义“。
如果参数的默认值是一个函数,该函数的作用域也遵守这个规则。请看下面的例子。
let foo = 'outer';
function bar(func = () => foo) {
let foo = 'inner';
console.log(func());
}
bar(); // outer
上面代码中,函数bar的参数func的默认值是一个匿名函数,返回值为变量foo。函数参数形成的单独作用域里面,并没有定义变量foo,所以foo指向外层的全局变量foo,因此输出outer。
如果写成下面这样,就会报错。
function bar(func = () => foo) {
let foo = 'inner';
console.log(func());
}
bar() // ReferenceError: foo is not defined
上面代码中,匿名函数里面的foo指向函数外层,但是函数外层并没有声明变量foo,所以就报错了。
下面是一个更复杂的例子。
var x = 1;
function foo(x, y = function() { x = 2; }) {
var x = 3;
y();
console.log(x);
}
foo() // 3
x // 1
上面代码中,函数foo的参数形成一个单独作用域。这个作用域里面,首先声明了变量x,然后声明了变量y,y的默认值是一个匿名函数。这个匿名函数内部的变量x,指向同一个作用域的第一个参数x。函数foo内部又声明了一个内部变量x,该变量与第一个参数x由于不是同一个作用域,所以不是同一个变量,因此执行y后,内部变量x和外部全局变量x的值都没变。
(调用foo的时候,会调用y,y函数变量作用域中没有变量x,所以会一直向上层作用域查找,终于在foo参数变量作用域中找到x,然后将该作用域的x变为2;然后执行console.log(x)的时候,这个语句是在foo函数内变量作用域中的,这个作用域中正好有变量x,x的值是3,所以输出3。全局作用域中的x依然是1,所以输出1。)
生成类似下面的作用域:
如果将var x = 3的var去除,函数foo的内部变量x就指向第一个参数x,与匿名函数内部的x是一致的,所以最后输出的就是2,而外层的全局变量x依然不受影响。
(和上图对比你会发现不同的地方在foo函数内变量作用域没有声明一个新的变量x。
执行x = 3的时候因为foo函数内变量作用域内没有x变量,所以会到foo参数变量作用域中查找,发现有x变量,然后将该作用域中的变量
x赋值为3;然后执行y的时候,因为y函数变量作用域中也没有x变量,所以会向上查找,直到在foo参数变量作用域找到变量x,然后将x赋值为2;执行console.log(x)的时候,因为foo函数内变量作用域没有x变量,所以打印的是foo参数变量作用域内的x变量,此时x为2;然后输出全局的x为1。)
var x = 1;
function foo(x, y = function() { x = 2; }) {
x = 3;
y();
console.log(x);
}
foo() // 2
x // 1
生成类似下面的作用域:

应用
利用参数默认值,可以指定某一个参数不得省略,如果省略就抛出一个错误。
function throwIfMissing() {
throw new Error('Missing parameter');
}
function foo(mustBeProvided = throwIfMissing()) {
return mustBeProvided;
}
foo()
// Error: Missing parameter
上面代码的foo函数,如果调用的时候没有参数,就会调用默认值throwIfMissing函数,从而抛出一个错误。
另外,可以将参数默认值设为undefined,表明这个参数是可以省略的。
function foo(optional = undefined) { ··· }
rest参数
ES6 引入 rest 参数(形式为...变量名),用于获取函数的多余参数,这样就不需要使用arguments对象了。rest 参数搭配的变量是一个数组,该变量将多余的参数放入数组中。
function add(...values) {
let sum = 0;
for (var val of values) {
sum += val;
}
return sum;
}
add(2, 5, 3) // 10
下面是一个 rest 参数代替arguments变量的例子。
// arguments变量的写法
function sortNumbers() {
return Array.prototype.slice.call(arguments).sort();
}
// rest参数的写法
const sortNumbers = (...numbers) => numbers.sort();
arguments对象不是数组,而是一个类似数组的对象。所以为了使用数组的方法,必须使用Array.prototype.slice.call先将其转为数组。rest 参数就不存在这个问题,它就是一个真正的数组,数组特有的方法都可以使用。下面是一个利用 rest 参数改写数组push方法的例子。
注:Array.prototype.slice.call(arguments,1),类数组转化为数组
这里首先使用了Array.prototype.slice.call(arguments,1)对于calllt函数的参数进行了截取。
因为arguments是一个类数组,没有slice方法,因此在Array类型的原型链上调用slice()方法;call()函数里面传入arguments和1,是将slice()函数的调用对象设置为arguments,即在arguments上调用slice方法,1作为参数传入slice方法返回的新数组的项是arguments去掉第一个参数后的所有参数;
注意:这里不能使用apply来代替call,apply方法要求第二个参数为arguments对象或者合法的数组,而“1”很明显不是数组,所以会报“Arguments list has wrong type”错误。
function push(array, ...items) {
items.forEach(function(item) {
array.push(item);
console.log(item);
});
}
var a = [];
push(a, 1, 2, 3)
注意,rest 参数之后不能再有其他参数(即只能是最后一个参数),否则会报错。
// 报错
function f(a, ...b, c) {
// ...
}
函数的length属性,不包括 rest 参数。
严格模式
从 ES5 开始,函数内部可以设定为严格模式。
ES2016 做了一点修改,规定只要函数参数使用了默认值、解构赋值、或者扩展运算符,那么函数内部就不能显式设定为严格模式,否则会报错。
// 报错
function doSomething(a, b = a) {
'use strict';
// code
}
// 报错
const doSomething = function ({a, b}) {
'use strict';
// code
};
// 报错
const doSomething = (...a) => {
'use strict';
// code
};
const obj = {
// 报错
doSomething({a, b}) {
'use strict';
// code
}
};
两种方法可以规避这种限制。第一种是设定全局性的严格模式,这是合法的
'use strict';
function doSomething(a, b = a) {
// code
}
第二种是把函数包在一个无参数的立即执行函数里面。
const doSomething = (function () {
'use strict';
return function(value = 42) {
return value;
};
}());
name属性
函数的name属性,返回该函数的函数名。
function foo() {}
foo.name // "foo"
需要注意的是,ES6 对这个属性的行为做出了一些修改。如果将一个匿名函数赋值给一个变量,ES5 的name属性,会返回空字符串,而 ES6 的name属性会返回实际的函数名。
var f = function () {};
// ES5
f.name // ""
// ES6
f.name // "f"
如果将一个具名函数赋值给一个变量,则 ES5 和 ES6 的name属性都返回这个具名函数原本的名字。
const bar = function baz() {};
// ES5
bar.name // "baz"
// ES6
bar.name // "baz"
Function构造函数返回的函数实例,name属性的值为anonymous。
bind返回的函数,name属性值会加上bound前缀。
function foo() {};
foo.bind({}).name // "bound foo"
(function(){}).bind({}).name // "bound "
箭头函数
基本用法
ES6 允许使用“箭头”(=>)定义函数。
var f = v => v;
// 等同于
var f = function (v) {
return v;
};
如果箭头函数不需要参数或需要多个参数,就使用一个圆括号代表参数部分。
var f = () => 5;
// 等同于
var f = function () { return 5 };
var sum = (num1, num2) => num1 + num2;
// 等同于
var sum = function(num1, num2) {
return num1 + num2;
};
如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回。
var sum = (num1, num2) => { return num1 + num2; }
由于大括号被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外面加上括号,否则会报错。
// 报错
let getTempItem = id => { id: id, name: "Temp" };
// 不报错
let getTempItem = id => ({ id: id, name: "Temp" });
let foo = () => { a: 1 };
foo() // undefined
上面代码中,原始意图是返回一个对象{ a: 1 },但是由于引擎认为大括号是代码块,所以执行了一行语句a: 1。这时,a可以被解释为语句的标签,因此实际执行的语句是1;,然后函数就结束了,没有返回值。
如果箭头函数只有一行语句,且不需要返回值,可以采用下面的写法,就不用写大括号了。
let fn = () => void doesNotReturn();
箭头函数可以与变量解构结合使用。
const full = ({ first, last }) => first + ' ' + last;
// 等同于
function full(person) {
return person.first + ' ' + person.last;
}
箭头函数使得表达更加简洁。
// 正常函数写法
[1,2,3].map(function (x) {
return x * x;
});
// 箭头函数写法
[1,2,3].map(x => x * x);
另一个例子是
// 正常函数写法
var result = values.sort(function (a, b) {
return a - b;
});
// 箭头函数写法
var result = values.sort((a, b) => a - b);
下面是 rest 参数与箭头函数结合的例子。
const numbers = (...nums) => nums;
numbers(1, 2, 3, 4, 5)
// [1,2,3,4,5]
const headAndTail = (head, ...tail) => [head, tail];
headAndTail(1, 2, 3, 4, 5)
// [1,[2,3,4,5]]
注意点
- 函数体内的
this对象,就是定义时所在的对象,而不是使用时所在的对象。 - 不可以当作构造函数,也就是说,不可以使用
new命令,否则会抛出一个错误。 - 不可以使用
arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。 - 不可以使用
yield命令,因此箭头函数不能用作 Generator 函数。
上面四点中,第一点尤其值得注意。this对象的指向是可变的,但是在箭头函数中,它是固定的。
function foo() {
setTimeout(() => {
console.log('id:', this.id);
}, 100);
}
var id = 21;
foo.call({ id: 42 });
// id: 42
上面代码中,setTimeout的参数是一个箭头函数,这个箭头函数的定义生效是在foo函数生成时,而它的真正执行要等到 100 毫秒后。如果是普通函数,执行时this应该指向全局对象window,这时应该输出21。但是,箭头函数导致this总是指向函数定义生效时所在的对象(本例是{id: 42}),所以输出的是42。
function Timer() {
this.s1 = 0;
this.s2 = 0;
// 箭头函数
setInterval(() => this.s1++, 1000);
// 普通函数
setInterval(function () {
this.s2++;
}, 1000);
}
var timer = new Timer();
setTimeout(() => console.log('s1: ', timer.s1), 3100);
setTimeout(() => console.log('s2: ', timer.s2), 3100);
// s1: 3
// s2: 0
上面代码中,Timer函数内部设置了两个定时器,分别使用了箭头函数和普通函数。前者的this绑定定义时所在的作用域(即Timer函数),后者的this指向运行时所在的作用域(即全局对象)。所以,3100 毫秒之后,timer.s1被更新了 3 次,而timer.s2一次都没更新。
this指向的固定化,并不是因为箭头函数内部有绑定this的机制,实际原因是箭头函数根本没有自己的this,导致内部的this就是外层代码块的this。正是因为它没有this,所以也就不能用作构造函数。
function foo() {
return () => {
return () => {
return () => {
console.log('id:', this.id);
};
};
};
}
var f = foo.call({id: 1});
var t1 = f.call({id: 2})()(); // id: 1
var t2 = f().call({id: 3})(); // id: 1
var t3 = f()().call({id: 4}); // id: 1
上面代码之中,只有一个this,就是函数foo的this,所以t1、t2、t3都输出同样的结果。因为所有的内层函数都是箭头函数,都没有自己的this,它们的this其实都是最外层foo函数的this。
另外,由于箭头函数没有自己的this,所以当然也就不能用call()、apply()、bind()这些方法去改变this的指向。
(function() {
return [
(() => this.x).bind({ x: 'inner' })()
];
}).call({ x: 'outer' });
// ['outer']
不适用场合
由于箭头函数使得this从“动态”变成“静态”,下面两个场合不应该使用箭头函数。
- 第一个场合是定义对象的方法,且该方法内部包括
this。
const cat = {
lives: 9,
jumps: () => {
this.lives--;
}
}
上面代码中,cat.jumps()方法是一个箭头函数,这是错误的。调用cat.jumps()时,如果是普通函数,该方法内部的this指向cat;如果写成上面那样的箭头函数,使得this指向全局对象,因此不会得到预期结果。这是因为对象不构成单独的作用域,导致jumps箭头函数定义时的作用域就是全局作用域。
- 第二个场合是需要动态
this的时候,也不应使用箭头函数。
var button = document.getElementById('press');
button.addEventListener('click', () => {
this.classList.toggle('on');
});
上面代码运行时,点击按钮会报错,因为button的监听函数是一个箭头函数,导致里面的this就是全局对象。如果改成普通函数,this就会动态指向被点击的按钮对象。
另外,如果函数体很复杂,有许多行,或者函数内部有大量的读写操作,不单纯是为了计算值,这时也不应该使用箭头函数,而是要使用普通函数,这样可以提高代码可读性。
嵌套的箭头函数
箭头函数内部,还可以再使用箭头函数。下面是一个 ES5 语法的多重嵌套函数。
function insert(value) {
return {into: function (array) {
return {after: function (afterValue) {
array.splice(array.indexOf(afterValue) + 1, 0, value);
return array;
}};
}};
}
insert(2).into([1, 3]).after(1); //[1, 2, 3]
上面这个函数,可以使用箭头函数改写。
let insert = (value) => ({into: (array) => ({after: (afterValue) => {
array.splice(array.indexOf(afterValue) + 1, 0, value);
return array;
}})});
insert(2).into([1, 3]).after(1); //[1, 2, 3]
尾调用优化
什么是尾调用
尾调用(Tail Call)是函数式编程的一个重要概念,本身非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。
function f(x){
return g(x);
}
以下三种情况,都不属于尾调用。
// 情况一
function f(x){
let y = g(x);
return y;
}
// 情况二
function f(x){
return g(x) + 1;
}
// 情况三
function f(x){
g(x);
}
尾调用不一定出现在函数尾部,只要是最后一步操作即可。
function f(x) {
if (x > 0) {
return m(x)
}
return n(x);
}
上面代码中,函数m和n都属于尾调用,因为它们都是函数f的最后一步操作。
尾调用优化
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3);
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除f(x)的调用帧,只保留g(3)的调用帧。
这就叫做“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是“尾调用优化”的意义。
注意,只有不再用到外层函数的内部变量,内层函数的调用帧才会取代外层函数的调用帧,否则就无法进行“尾调用优化”。
function addOne(a){
var one = 1;
function inner(b){
return b + one;
}
return inner(a);
}
上面的函数不会进行尾调用优化,因为内层函数inner用到了外层函数addOne的内部变量one。
尾递归
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
factorial(5) // 120
上面代码是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
function factorial(n, total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5, 1) // 120
还有一个比较著名的例子,就是计算 Fibonacci 数列,也能充分说明尾递归优化的重要性。
非尾递归的 Fibonacci 数列实现如下。
function Fibonacci (n) {
if ( n <= 1 ) {return 1};
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
Fibonacci(10) // 89
Fibonacci(100) // 超时
Fibonacci(500) // 超时
尾递归优化过的 Fibonacci 数列实现如下。
function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
if( n <= 1 ) {return ac2};
return Fibonacci2 (n - 1, ac2, ac1 + ac2);
}
Fibonacci2(100) // 573147844013817200000
Fibonacci2(1000) // 7.0330367711422765e+208
Fibonacci2(10000) // Infinity
由此可见,“尾调用优化”对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6 亦是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署“尾调用优化”。这就是说,ES6 中只要使用尾递归,就不会发生栈溢出(或者层层递归造成的超时),相对节省内存。
递归函数的改写
尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身。做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。比如上面的例子,阶乘函数 factorial 需要用到一个中间变量total,那就把这个中间变量改写成函数的参数。这样做的缺点就是不太直观,第一眼很难看出来,为什么计算5的阶乘,需要传入两个参数5和1?
方法一是在尾递归函数之外,再提供一个正常形式的函数。
function tailFactorial(n, total) {
if (n === 1) return total;
return tailFactorial(n - 1, n * total);
}
function factorial(n) {
return tailFactorial(n, 1);
}
factorial(5) // 120
函数式编程有一个概念,叫做柯里化(currying),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
function currying(fn, n) {
return function (m) {
return fn.call(this, m, n);
};
}
function tailFactorial(n, total) {
if (n === 1) return total;
return tailFactorial(n - 1, n * total);
}
const factorial = currying(tailFactorial, 1);
factorial(5) // 120
上面代码通过柯里化,将尾递归函数tailFactorial变为只接受一个参数的factorial。
第二种方法就简单多了,就是采用 ES6 的函数默认值。
function factorial(n, total = 1) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5) // 120
JS函数柯里化
柯里化,英语:Currying(果然是满满的英译中的既视感),是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
// 普通的add函数
function add(x, y) {
return x + y
}
// Currying后
function curryingAdd(x) {
return function (y) {
return x + y
}
}
add(1, 2) // 3
curryingAdd(1)(2) // 3
实际上就是把add函数的x,y两个参数变成了先用一个函数接收x然后返回一个函数去处理y参数。现在思路应该就比较清晰了,就是只传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
Currying有哪些好处:
- 参数复用
// 正常正则验证字符串 reg.test(txt)
// 函数封装后
function check(reg, txt) {
return reg.test(txt)
}
check(/\d+/g, 'test') //false
check(/[a-z]+/g, 'test') //true
// Currying后
function curryingCheck(reg) {
return function(txt) {
return reg.test(txt)
}
}
var hasNumber = curryingCheck(/\d+/g)
var hasLetter = curryingCheck(/[a-z]+/g)
hasNumber('test1') // true
hasNumber('testtest') // false
hasLetter('21212') // false
如果我有很多地方都要校验是否有数字,其实就是需要将第一个参数reg进行复用,这样别的地方就能够直接调用hasNumber,hasLetter等函数,让参数能够复用,调用起来也更方便。
- 提前确认
var on = function(element, event, handler) {
if (document.addEventListener) {
if (element && event && handler) {
element.addEventListener(event, handler, false);
}
} else {
if (element && event && handler) {
element.attachEvent('on' + event, handler);
}
}
}
var on = (function() {
if (document.addEventListener) {
return function(element, event, handler) {
if (element && event && handler) {
element.addEventListener(event, handler, false);
}
};
} else {
return function(element, event, handler) {
if (element && event && handler) {
element.attachEvent('on' + event, handler);
}
};
}
})();
//换一种写法可能比较好理解一点,上面就是把isSupport这个参数给先确定下来了
var on = function(isSupport, element, event, handler) {
isSupport = isSupport || document.addEventListener;
if (isSupport) {
return element.addEventListener(event, handler, false);
} else {
return element.attachEvent('on' + event, handler);
}
}
面试题add()
实现一个add方法,使计算结果能够满足如下预期:
add(1)(2)(3) = 6;
add(1, 2, 3)(4) = 10;
add(1)(2)(3)(4)(5) = 15;
实现如下:
function add(...arguments) {
// 第一次执行时,定义一个数组专门用来存储所有的参数
var _args = [].slice.call(arguments);
//var _args = [...arguments]
//var _args = Array.from(arguments)
// 在内部声明一个函数,利用闭包的特性保存_args并收集所有的参数值
var adder = function () {
var _adder = function() {
// [].push.apply(_args, [].slice.call(arguments));
_args.push(...arguments);
return _adder;
};
// 利用隐式转换的特性,当最后执行时隐式转换,并计算最终的值返回
_adder.toString = function () {
return _args.reduce(function (a, b) {
return a + b;
});
}
return _adder;
}
// return adder.apply(null, _args);
return adder(..._args);
}
var a = add(1)(2)(3)(4); // f 10
var b = add(1, 2, 3, 4); // f 10
var c = add(1, 2)(3, 4); // f 10
var d = add(1, 2, 3)(4); // f 10
// 可以利用隐式转换的特性参与计算
console.log(a + 10); // 20
console.log(b + 20); // 30
console.log(c + 30); // 40
console.log(d + 40); // 50
// 也可以继续传入参数,得到的结果再次利用隐式转换参与计算
console.log(a(10) + 100); // 120
console.log(b(10) + 100); // 120
console.log(c(10) + 100); // 120
console.log(d(10) + 100); // 120
// 其实上栗中的add方法,就是下面这个函数的柯里化函数,只不过我们并没有使用通用式来转化,而是自己封装
function add(...args) {
return args.reduce((a, b) => a + b);
}
arguments转化为数组
var args = Array.prototype.slice.call(arguments);
var args = [].slice.call(arguments);
const args = Array.from(arguments);
const args = [...arguments];
严格模式
ES6 的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
func.arguments:返回调用时函数的参数。func.caller:返回调用当前函数的那个函数。
尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
function restricted() {
'use strict';
restricted.caller; // 报错
restricted.arguments; // 报错
}
restricted();
尾递归优化的实现
尾递归优化只在严格模式下生效,那么正常模 不支持该功能的环境中,有没有办法也使用尾递归优化呢?回答是可以的,就是自己实现尾递归优化。
它的原理非常简单。尾递归之所以需要优化,原因是调用栈太多,造成溢出,那么只要减少调用栈,就不会溢出。怎么做可以减少调用栈呢?就是采用“循环”换掉“递归”。
function sum(x, y) {
if (y > 0) {
return sum(x + 1, y - 1);
} else {
return x;
}
}
sum(1, 100000)
// Uncaught RangeError: Maximum call stack size exceeded(…)
上面代码中,sum是一个递归函数,参数x是需要累加的值,参数y控制递归次数。一旦指定sum递归 100000 次,就会报错,提示超出调用栈的最大次数。
蹦床函数(trampoline)可以将递归执行转为循环执行。
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}
上面就是蹦床函数的一个实现,它接受一个函数f作为参数。只要f执行后返回一个函数,就继续执行。注意,这里是返回一个函数,然后执行该函数,而不是函数里面调用函数,这样就避免了递归执行,从而就消除了调用栈过大的问题。
然后,要做的就是将原来的递归函数,改写为每一步返回另一个函数。
function sum(x, y) {
if (y > 0) {
return sum.bind(null, x + 1, y - 1);
} else {
return x;
}
}
上面代码中,sum函数的每次执行,都会返回自身的另一个版本。
现在,使用蹦床函数执行sum,就不会发生调用栈溢出。
trampoline(sum(1, 100000))
// 100001
蹦床函数并不是真正的尾递归优化,下面的实现才是
function tco(f) {
var value;
var active = false;
var accumulated = [];
return function accumulator() {
accumulated.push(arguments);
if (!active) {
active = true;
while (accumulated.length) {
value = f.apply(this, accumulated.shift());
}
active = false;
return value;
}
};
}
var sum = tco(function(x, y) {
if (y > 0) {
return sum(x + 1, y - 1)
}
else {
return x
}
});
sum(1, 100000)
// 100001
上面代码中,tco函数是尾递归优化的实现,它的奥妙就在于状态变量active。默认情况下,这个变量是不激活的。一旦进入尾递归优化的过程,这个变量就激活了。然后,每一轮递归sum返回的都是undefined,所以就避免了递归执行;而accumulated数组存放每一轮sum执行的参数,总是有值的,这就保证了accumulator函数内部的while循环总是会执行。这样就很巧妙地将“递归”改成了“循环”,而后一轮的参数会取代前一轮的参数,保证了调用栈只有一层。
函数参数的尾逗号
ES2017 允许函数的最后一个参数有尾逗号(trailing comma)。
此前,函数定义和调用时,都不允许最后一个参数后面出现逗号。
Function.prototype.toString()
ES2019 对函数实例的toString()方法做出了修改。
toString()方法返回函数代码本身,以前会省略注释和空格。修改后的toString()方法,明确要求返回一模一样的原始代码。
catch 命令的参数省略
JavaScript 语言的try...catch结构,以前明确要求catch命令后面必须跟参数,接受try代码块抛出的错误对象。
try {
// ...
} catch (err) {
// 处理错误
}
上面代码中,catch命令后面带有参数err。
很多时候,catch代码块可能用不到这个参数。但是,为了保证语法正确,还是必须写。ES2019 做出了改变,允许catch语句省略参数。
try {
// ...
} catch {
// ...
}
手写call apply bind
手写call
思路
- 根据call的规则设置上下文对象,也就是
this的指向。 - 通过设置
context的属性,将函数的this指向隐式绑定到context上 - 通过隐式绑定执行函数并传递参数。
- 删除临时属性,返回函数执行结果
Function.prototype.myCall = function (context, ...arr) {
if (context === null || context === undefined) {
// 指定为 null 和 undefined 的 this 值会自动指向全局对象(浏览器中为window)
context = window
} else {
context = Object(context) // 值为原始值(数字,字符串,布尔值)的 this 会指向该原始值的实例对象
}
const specialPrototype = Symbol('特殊属性Symbol') // 用于临时储存函数
context[specialPrototype] = this; // 函数的this指向隐式绑定到context上
let result = context[specialPrototype](...arr); // 通过隐式绑定执行函数并传递参数
delete context[specialPrototype]; // 删除上下文对象的属性
return result; // 返回函数执行结果
};
很多人判断函数上下文对象,只是简单的以context是否为false来判断,比如:
// 判断函数上下文绑定到`window`不够严谨
context = context ? Object(context) : window;
context = context || window;
经过测试,以下三种为false的情况,函数的上下文对象都会绑定到window上:
// 网上的其他绑定函数上下文对象的方案: context = context || window;
function handle(...params) {
this.test = 'handle'
console.log('params', this, ...params) // do some thing
}
handle.elseCall('') // window
handle.elseCall(0) // window
handle.elseCall(false) // window
而call则将函数的上下文对象会绑定到这些原始值的实例对象上:
所以正确的解决方案,应该是像我上面那么做
手写apply
思路:
- 传递给函数的参数处理,不太一样,其他部分跟
call一样。 apply接受第二个参数为类数组对象, 这里用了JavaScript权威指南中判断是否为类数组对象的方法。
Function.prototype.myApply = function (context) {
if (context === null || context === undefined) {
context = window // 指定为 null 和 undefined 的 this 值会自动指向全局对象(浏览器中为window)
} else {
context = Object(context) // 值为原始值(数字,字符串,布尔值)的 this 会指向该原始值的实例对象
}
// JavaScript权威指南判断是否为类数组对象
function isArrayLike(o) {
if (o && // o不是null、undefined等
typeof o === 'object' && // o是对象
isFinite(o.length) && // o.length是有限数值
o.length >= 0 && // o.length为非负值
o.length === Math.floor(o.length) && // o.length是整数或用 Number.isInteger(o.length)
o.length < Math.pow(2, 32) // o.length < 2^32
return true
else
return false
}
const specialPrototype = Symbol('特殊属性Symbol') // 用于临时储存函数
context[specialPrototype] = this; // 隐式绑定this指向到context上
let args = arguments[1]; // 获取参数数组
let result
// 处理传进来的第二个参数
if (args) {
// 是否传递第二个参数
if (!Array.isArray(args) && !isArrayLike(args)) {
throw new TypeError('myApply 第二个参数不为数组并且不为类数组对象抛出错误');
} else {
args = Array.from(args) // 转为数组
result = context[specialPrototype](...args); // 执行函数并展开数组,传递函数参数
}
} else {
result = context[specialPrototype](); // 执行函数
}
delete context[specialPrototype]; // 删除上下文对象的属性
return result; // 返回函数执行结果
};
手写bind
思路
- 拷贝源函数:
- 通过变量储存源函数
- 使用
Object.create复制源函数的prototype给fToBind
- 返回拷贝的函数
- 调用拷贝的函数:
- new调用判断:通过
instanceof判断函数是否通过new调用,来决定绑定的context - 绑定this+传递参数
- 返回源函数的执行结果
- new调用判断:通过
Function.prototype.myBind = function (objThis, ...params) {
const thisFn = this; // 存储源函数以及上方的params(函数参数)
// 对返回的函数 secondParams 二次传参
let fToBind = function (...secondParams) {
console.log('secondParams',secondParams,...secondParams)
const isNew = this instanceof fToBind // this是否是fToBind的实例 也就是返回的fToBind是否通过new调用
const context = isNew ? this : Object(objThis) // new调用就绑定到this上,否则就绑定到传入的objThis上
return thisFn.call(context, ...params, ...secondParams); // 用call调用源函数绑定this的指向并传递参数,返回执行结果
};
fToBind.prototype = Object.create(thisFn.prototype); // 复制源函数的prototype给fToBind
return fToBind; // 返回拷贝的函数
};
类型转换
自动转换类型:
5 + null // 返回 5 null 转换为 0
"5" + null // 返回"5null" null 转换为 "null"
"5" + 1 // 返回 "51" 1 转换为 "1"
"5" - 1 // 返回 4 "5" 转换为 5
/*
数字+字符串=字符串
数字+布尔值=数值
字符串+布尔值=字符串
布尔值+布尔值=数字
*/
自动转换为字符串:
document.getElementById("demo").innerHTML = myVar;
myVar = {name:"Fjohn"} // toString 转换为 "[object Object]"
myVar = [1,2,3,4] // toString 转换为 "1,2,3,4"
myVar = new Date() // toString 转换为 "Fri Jul 18 2014 09:08:55 GMT+0200"
myVar = 123 // toString 转换为 "123"
myVar = true // toString 转换为 "true"
myVar = false // toString 转换为 "false"
下表展示了使用不同的数值转换为数字(Number), 字符串(String), 布尔值(Boolean):
| 原始值 | 转换为数字 | 转换为字符串 | 转换为布尔值 |
|---|---|---|---|
| false | 0 | "false" | false |
| true | 1 | "true" | true |
| 0 | 0 | "0" | false |
| 1 | 1 | "1" | true |
| "0" | 0 | "0" | true |
| "000" | 0 | "000" | true |
| "1" | 1 | "1" | true |
| NaN | NaN | "NaN" | false |
| Infinity | Infinity | "Infinity" | true |
| -Infinity | -Infinity | "-Infinity" | true |
| "" | 0 | "" | false |
| "20" | 20 | "20" | true |
| "Runoob" | NaN | "Runoob" | true |
| [ ] | 0 | "" | true |
| [20] | 20 | "20" | true |
| [10,20] | NaN | "10,20" | true |
| ["Runoob"] | NaN | "Runoob" | true |
| ["Runoob","Google"] | NaN | "Runoob,Google" | true |
| function(){} | NaN | "function(){}" | true |
| { } | NaN | "[object Object]" | true |
| null | 0 | "null" | false |
| undefined | NaN | "undefined" | false |
总结:
转换为 Boolean类型为 false 的有:0,NaN,false,"",null,undefined
转换为数字0的有:"",[ ],null
对象{ }转化字符串为:[object Object]
转换为数字NaN特殊的有:NaN, { },undefined
- 基本类型
总结:当加号运算符时,String和其他类型时,其他类型都会转为 String;其他情况,都转化为Number类型 , 注: undefined 转化为Number是 为’NaN‘, 任何Number与NaN相加都为NaN。
其他运算符时, 基本类型都转换为 Number,String类型的带有字符的比如: '1a' ,'a1' 转化为 NaN 与undefined 一样。
tip:(1)NaN 不与 任何值相等 包括自身,所以判断一个值 是否为 NaN, 即用 "!==" 即可。
(2) 转换为 Boolean类型为 false 的有:null,0,"",undefined,NaN,false
(3)number() 与 parseInt() 都可以将对象转化为Number类型,Number函数要比parseInt函数严格很多。基本上,只要有一个字符无法转成数值,整个字符串就会被转为NaN。
- 对象类型
总结: Number类型会先调用valueOf(), String类型会先调用toString(), 如果结果是原始值,则返回原始值,否则继续用toString 或 valueOf(),继续计算,如果结果还不是原始值,则抛出一个类型错误;
请看以下情况:
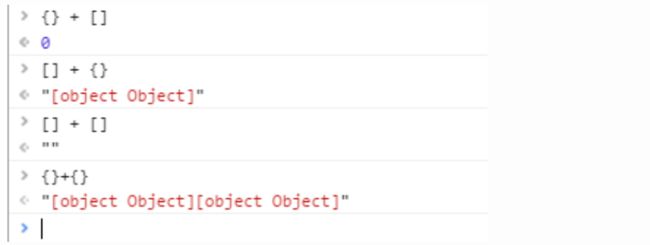
为什么 {} + [] = 0 ? 因为 javascript在运行时, 将 第一次{} 认为是空的代码块,所以就相当于 +[] = 0. 还有 {} +5 = 5, 同理。
{} + [] 和 [] + {}
js里的隐式的rule:
- js在进行加法运算的时候, 会先推测两个操作数是不是number。如果是,则直接相加得出结果。
- 如果其中有一个操作数为string,则将另一个操作数隐式的转换为string,然后进行字符串拼接得出结果。
- 如果操作数为对象或者是数组这种复杂的数据类型,那么就将两个操作数都转换为字符串,进行拼接
- 如果操作数是像boolean这种的简单数据类型,那么就将操作数转换为number相加得出结果
先来看第一个[] + {},这是两个复杂数据结构相加的例子,按照上面的rule,我们先将两个操作数转换为string,然后进行拼接,于是
[] -----> ''
{} -----> '[object Object]'
[] + {} = '[object Object]'
再来看第二个{} + [],这也是两个复杂数据结构相加的例子,看样子与第一个没有什么差别,按理说也应该是[object Object],但是你相加的时候你会发现, 得出的答案是 0!
原因是有的js解释器会将开头的 {} 看作一个代码块,而不是一个js对象,于是真正参与运算的是+[],就是将[]转换为number,于是得出答案0
[] == ![]为true,而 {} == !{}为false
基本规则:
1. 相等和不相等——先转换再比较 (==)
2. 全等和不全等——仅比较而不转换 (===)
ECMAScript中相等操作符由两个等于号(==)表示,如果两个操作数相等,则返回true,这种操作符都会先转换操作数(通常称为强制转型),然后再比较它们的相等性
在转换不同的数据类型时,对于相等和不相等操作符,给出如下的基本转换规则:
①、如果有一个操作数是布尔值,则在比较相等性之前先将其转换为数值——false转换为0,而true转换为1;
②、如果一个操作数是字符串,另一个操作数是数值,在比较相等性之前先将字符串转换为数值
③、如果一个操作数是对象,另一个操作数不是,则调用对象的valueOf()方法,用得到的基本类型值按照前面的规则进行比较
这两个操作符在进行比较时则要遵循下列规则。
①、null 和undefined 是相等的
②、要比较相等性之前,不能将null 和 undefined 转换成其他任何值
③、如果有一个操作数是NaN,则相等操作符返回 false ,而不相等操作符返回 true。重要提示:即使两个操作数都是NaN,相等操作符也返回 false了;因为按照规则, NaN 不等于 NaN(注:isNaN() 函数用于检查其参数是否是非数字值。)
④、如果两个操作数都是对象,则比较它们是不是同一个对象,如果两个操作数都指向同一个对象,则相等操作符返回 true;否则, 返回false

现在来探讨 [] == ! [] 的结果为什么会是true:
①、根据运算符优先级 ,! 的优先级是大于 == 的,所以先会执行 ![]
!可将变量转换成boolean类型,0、false、NaN、、空字符串('')、null、undefined取反都为true,其余都为false。
所以 ! [] 运算后的结果就是 false
也就是 [] == ! [] 相当于 [] == false
②、根据上面提到的规则(如果有一个操作数是布尔值,则在比较相等性之前先将其转换为数值——false转换为0,而true转换为1),则需要把 false 转成 0
也就是 [] == ! [] 相当于 [] == false 相当于 [] == 0
③、根据上面提到的规则(如果一个操作数是对象,另一个操作数不是,则调用对象的valueOf()方法,用得到的基本类型值按照前面的规则进行比较,如果对象没有valueOf()方法,则调用 toString())
而对于空数组,[].toString() -> '' (返回的是空字符串)
也就是 [] == 0 相当于 '' == 0
④、根据上面提到的规则(如果一个操作数是字符串,另一个操作数是数值,在比较相等性之前先将字符串转换为数值)
Number('') -> 返回的是 0
相当于 0 == 0 自然就返回 true了
总结一下:
[] == ! [] -> [] == false -> [] == 0 -> '' == 0 -> 0 == 0 -> true
那么对于 {} == !{} 也是同理的
关键在于 {}.toString() -> NaN(返回的是NaN)
根据上面的规则(如果有一个操作数是NaN,则相等操作符返回 false)
总结一下:
{} == ! {} -> {} == false -> {} == 0 -> NaN == 0 -> false
JS中数据类型的判断
typeof
console.log(typeof 2); // number
console.log(typeof true); // boolean
console.log(typeof 'str'); // string
console.log(typeof []); // object []数组的数据类型在 typeof 中被解释为 object
console.log(typeof function(){}); // function
console.log(typeof {}); // object
console.log(typeof undefined); // undefined
console.log(typeof null); // object null 的数据类型被 typeof 解释为 object
结果如下图显示,空数组 和 null被 typeof 解释为 object 类型,有的人可能会认为 typeof 关键字对数组 和 null 的类型判断是错误的,其实typeof对于数组 和 null 的类型判断是正确的,只不过不够精准而已。
instanceof
console.log(2 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log('str' instanceof String); // false
console.log([] instanceof Array); // true
console.log(function(){} instanceof Function); // true
console.log({} instanceof Object); // true
// console.log(undefined instanceof Undefined);
// console.log(null instanceof Null);
undefined 和 null 在这里的表现有点异于寻常数据,我们先注释掉
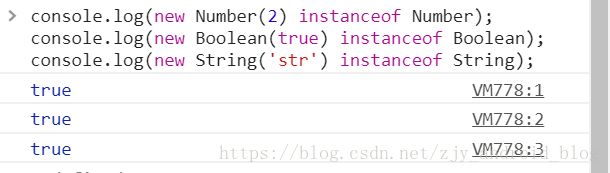
直接的字面量值判断数据类型,只有引用数据类型(Array,Function,Object)被精准判断,其他(数值Number,布尔值Boolean,字符串String)字面值不能被instanceof精准判断。
(注:instanceof 在MDN中的解释:instanceof 运算符用来测试一个对象在其原型链中是否存在一个构造函数的 prototype 属性。其意思就是判断对象是否是某一数据类型(如Array)的实例,请重点关注一下是判断一个对象是否是数据类型的实例。在这里字面量值,2, true ,'str'不是实例,所以判断值为false。眼见为实,看下面的例子:)
字面值被实例化了,他们的判断值变为了 true。
接着,我们看一下 undefined 和 null ,说说为什么这两货比较特殊,实际上按理来说,null的所属类就是Null,undefined就是Undefined,但事实并非如此:控制台输出如下结果:
 浏览器认为null,undefined不是构造器。但是在 typeof 中你可能已经发现了,typeof null的结果是object,typeof undefined的结果是undefined ,这是怎么回事呢?
浏览器认为null,undefined不是构造器。但是在 typeof 中你可能已经发现了,typeof null的结果是object,typeof undefined的结果是undefined ,这是怎么回事呢?
尤其是null,其实这是js发展过程中设计者的重大失误,早期准备更改null的类型为null,由于当时已经有大量网站使用了null,如果更改,将导致很多网站的逻辑出现漏洞问题,就没有更改过来,于是一直遗留到现在。作为学习者,我们只需要记住就好。
constructor
console.log((2).constructor === Number); //true
console.log((true).constructor === Boolean); //true
console.log(('str').constructor === String); //true
console.log(([]).constructor === Array); //true
console.log((function() {}).constructor === Function); //true
console.log(({}).constructor === Object); //true
用costructor来判断类型看起来是完美的,然而,如果我创建一个对象,更改它的原型,这种方式也变得不可靠了。
function Fn(){};
Fn.prototype=new Array();
var f=new Fn();
console.log(f.constructor===Fn); // false
console.log(f.constructor===Array); // true
Object.prototype.toString.call()
var a = Object.prototype.toString;
console.log(a.call(2)); //[object Number]
console.log(a.call(true)); //[object Boolean]
console.log(a.call('str')); //[object String]
console.log(a.call([])); //[object Array]
console.log(a.call(function(){})); //[object Function]
console.log(a.call({})); //[object Object]
console.log(a.call(undefined)); //[object Undefined]
console.log(a.call(null)); //[object Null]
结果精准的显示我们需要的数据类型。
就算我们改变对象的原型,他依然会显示正确的数据类型。
Object.prototype.toString.call() 对数据类型检测进行封装:
var type = function (o){
var s = Object.prototype.toString.call(o);
return s.slice(8, -1).toLowerCase();
};
['Null',
'Undefined',
'Object',
'Array',
'String',
'Number',
'Boolean',
'Function',
'RegExp'
].forEach(function (value) {
type['is' + value] = function (o) {
return type(o) === value.toLowerCase();
};
});
type.isObject({}) // true
type.isNumber(NaN) // true
type.isRegExp(/abc/) // true
面试题:
实现一个函数clone,可以对js中的5种主要的数据类型(包括number string object array Boolean)进行值复制
function cloneDataByType(data) {
let typeName = Object.prototype.toString.call(data).slice(8, -1)
let copyData
switch (typeName) {
case 'Number':
copyData = data
break
case 'String':
copyData = "'" + data + "'"
break
case 'Boolean':
copyData = data
break
case 'Array':
copyData = []
for (let index = 0; index < data.length; index++) {
copyData[index] = data[index]
}
break
/* data.forEach(i=>{
copyData[i] = data[i]
}) */
case 'Function':
copyData = data
break
case 'Object':
copyData = {}
Object.keys(data).forEach(i => {
copyData[i] = data[i]
})
break
case 'Null':
copyData = null
break
case 'Undefined':
copyData = undefined
break
default:
copyData = data
break
}
return copyData
}
数组的扩展
扩展运算符
扩展运算符(spread)是三个点(...)。它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列。
console.log(...[1, 2, 3])
// 1 2 3
console.log(1, ...[2, 3, 4], 5)
// 1 2 3 4 5
[...document.querySelectorAll('div')]
// [, , ]
该运算符主要用于函数调用。
function push(array, ...items) {
array.push(...items);
}
function add(x, y) {
return x + y;
}
const numbers = [4, 38];
add(...numbers) // 42
扩展运算符与正常的函数参数可以结合使用,非常灵活
function f(v, w, x, y, z) { }
const args = [0, 1];
f(-1, ...args, 2, ...[3]);
扩展运算符后面还可以放置表达式。
const arr = [
...(x > 0 ? ['a'] : []),
'b',
];
如果扩展运算符后面是一个空数组,则不产生任何效果。
[...[], 1]
// [1]
注意,只有函数调用时,扩展运算符才可以放在圆括号中,否则会报错。
(...[1, 2])
// Uncaught SyntaxError: Unexpected number
console.log((...[1, 2]))
// Uncaught SyntaxError: Unexpected number
console.log(...[1, 2])
// 1 2
替代函数的apply方法
由于扩展运算符可以展开数组,所以不再需要apply方法,将数组转为函数的参数了。
// ES5 的写法
function f(x, y, z) {
// ...
}
var args = [0, 1, 2];
f.apply(null, args);
// ES6的写法
function f(x, y, z) {
// ...
}
let args = [0, 1, 2];
f(...args);
下面是扩展运算符取代apply方法的一个实际的例子,应用Math.max方法,简化求出一个数组最大元素的写法。
// ES5 的写法
Math.max.apply(null, [14, 3, 77])
// ES6 的写法
Math.max(...[14, 3, 77])
// 等同于
Math.max(14, 3, 77);
另一个例子是通过push函数,将一个数组添加到另一个数组的尾部。
// ES5的 写法
var arr1 = [0, 1, 2];
var arr2 = [3, 4, 5];
Array.prototype.push.apply(arr1, arr2);
// ES6 的写法
let arr1 = [0, 1, 2];
let arr2 = [3, 4, 5];
arr1.push(...arr2);
上面代码的 ES5 写法中,push方法的参数不能是数组,所以只好通过apply方法变通使用push方法。有了扩展运算符,就可以直接将数组传入push方法。
下面是另外一个例子。
// ES5
new (Date.bind.apply(Date, [null, 2015, 1, 1]))
// ES6
new Date(...[2015, 1, 1]);
扩展运算符的应用
- 复制数组
数组是复合的数据类型,直接复制的话,只是复制了指向底层数据结构的指针,而不是克隆一个全新的数组。
const a1 = [1, 2];
const a2 = a1;
a2[0] = 2;
a1 // [2, 2]
上面代码中,a2并不是a1的克隆,而是指向同一份数据的另一个指针。修改a2,会直接导致a1的变化。
ES5 只能用变通方法来复制数组
const a1 = [1, 2];
const a2 = a1.concat();
a2[0] = 2;
a1 // [1, 2]
上面代码中,a1会返回原数组的克隆,再修改a2就不会对a1产生影响。
扩展运算符提供了复制数组的简便写法。
const a1 = [1, 2];
// 写法一
const a2 = [...a1];
// 写法二
const [...a2] = a1;
上面的两种写法,a2都是a1的克隆。
- 合并数组
扩展运算符提供了数组合并的新写法。
const arr1 = ['a', 'b'];
const arr2 = ['c'];
const arr3 = ['d', 'e'];
// ES5 的合并数组
arr1.concat(arr2, arr3);
// [ 'a', 'b', 'c', 'd', 'e' ]
// ES6 的合并数组
[...arr1, ...arr2, ...arr3]
// [ 'a', 'b', 'c', 'd', 'e' ]
不过,这两种方法都是浅拷贝,使用的时候需要注意。
const a1 = [{ foo: 1 }];
const a2 = [{ bar: 2 }];
const a3 = a1.concat(a2);
const a4 = [...a1, ...a2];
a3[0] === a1[0] // true
a4[0] === a1[0] // true
上面代码中,a3和a4是用两种不同方法合并而成的新数组,但是它们的成员都是对原数组成员的引用,这就是浅拷贝。如果修改了原数组的成员,会同步反映到新数组。
- 与解构赋值结合
扩展运算符可以与解构赋值结合起来,用于生成数组。
// ES5
a = list[0], rest = list.slice(1)
// ES6
[a, ...rest] = list
const [first, ...rest] = [1, 2, 3, 4, 5];
first // 1
rest // [2, 3, 4, 5]
const [first, ...rest] = [];
first // undefined
rest // []
const [first, ...rest] = ["foo"];
first // "foo"
rest // []
如果将扩展运算符用于数组赋值,只能放在参数的最后一位,否则会报错。
- 字符串
扩展运算符还可以将字符串转为真正的数组。
[...'hello']
// [ "h", "e", "l", "l", "o" ]
上面的写法,有一个重要的好处,那就是能够正确识别四个字节的 Unicode 字符。
'x\uD83D\uDE80y'.length // 4
[...'x\uD83D\uDE80y'].length // 3
上面代码的第一种写法,JavaScript 会将四个字节的 Unicode 字符,识别为 2 个字符,采用扩展运算符就没有这个问题。因此,正确返回字符串长度的函数,可以像下面这样写
function length(str) {
return [...str].length;
}
length('x\uD83D\uDE80y') // 3
凡是涉及到操作四个字节的 Unicode 字符的函数,都有这个问题。因此,最好都用扩展运算符改写。
let str = 'x\uD83D\uDE80y';
str.split('').reverse().join('')
// 'y\uDE80\uD83Dx'
[...str].reverse().join('')
// 'y\uD83D\uDE80x'
上面代码中,如果不用扩展运算符,字符串的reverse操作就不正确。
- 实现了 Iterator 接口的对象
任何定义了遍历器(Iterator)接口的对象(参阅 Iterator 一章),都可以用扩展运算符转为真正的数组。
let nodeList = document.querySelectorAll('div');
let array = [...nodeList];
上面代码中,querySelectorAll方法返回的是一个NodeList对象。它不是数组,而是一个类似数组的对象。这时,扩展运算符可以将其转为真正的数组,原因就在于NodeList对象实现了 Iterator 。
对于那些没有部署 Iterator 接口的类似数组的对象,扩展运算符就无法将其转为真正的数组。
- Map 和 Set 结构,Generator 函数
扩展运算符内部调用的是数据结构的 Iterator 接口,因此只要具有 Iterator 接口的对象,都可以使用扩展运算符,比如 Map 结构。
let map = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three'],
]);
let arr = [...map.keys()]; // [1, 2, 3]
Generator 函数运行后,返回一个遍历器对象,因此也可以使用扩展运算符。
const go = function*(){
yield 1;
yield 2;
yield 3;
};
[...go()] // [1, 2, 3]
上面代码中,变量go是一个 Generator 函数,执行后返回的是一个遍历器对象,对这个遍历器对象执行扩展运算符,就会将内部遍历得到的值,转为一个数组。
如果对没有 Iterator 接口的对象,使用扩展运算符,将会报错。
Array.from
Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括 ES6 新增的数据结构 Set 和 Map)。
下面是一个类似数组的对象,Array.from将它转为真正的数组。
let arrayLike = {
'0': 'a',
'1': 'b',
'2': 'c',
length: 3
};
// ES5的写法
var arr1 = [].slice.call(arrayLike); // ['a', 'b', 'c']
// ES6的写法
let arr2 = Array.from(arrayLike); // ['a', 'b', 'c']
实际应用中,常见的类似数组的对象是 DOM 操作返回的 NodeList 集合,以及函数内部的arguments对象。Array.from都可以将它们转为真正的数组。
// NodeList对象
let ps = document.querySelectorAll('p');
Array.from(ps).filter(p => {
return p.textContent.length > 100;
});
// arguments对象
function foo() {
var args = Array.from(arguments);
// ...
}
上面代码中,querySelectorAll方法返回的是一个类似数组的对象,可以将这个对象转为真正的数组,再使用filter方法。
只要是部署了 Iterator 接口的数据结构,Array.from都能将其转为数组。
Array.from('hello')
// ['h', 'e', 'l', 'l', 'o']
let namesSet = new Set(['a', 'b'])
Array.from(namesSet) // ['a', 'b']
如果参数是一个真正的数组,Array.from会返回一个一模一样的新数组。
扩展运算符背后调用的是遍历器接口(Symbol.iterator),如果一个对象没有部署这个接口,就无法转换。Array.from方法还支持类似数组的对象。所谓类似数组的对象,本质特征只有一点,即必须有length属性。因此,任何有length属性的对象,都可以通过Array.from方法转为数组,而此时扩展运算符就无法转换。
Array.from({ length: 3 });
// [ undefined, undefined, undefined ]
对于还没有部署该方法的浏览器,可以用Array.prototype.slice方法替代。
const toArray = (() =>
Array.from ? Array.from : obj => [].slice.call(obj)
)();
Array.from还可以接受第二个参数,作用类似于数组的map方法,用来对每个元素进行处理,将处理后的值放入返回的数组。
Array.from(arrayLike, x => x * x);
// 等同于
Array.from(arrayLike).map(x => x * x);
Array.from([1, 2, 3], (x) => x * x)
// [1, 4, 9]
下面的例子是取出一组 DOM 节点的文本内容。
let spans = document.querySelectorAll('span.name');
// map()
let names1 = Array.prototype.map.call(spans, s => s.textContent);
// Array.from()
let names2 = Array.from(spans, s => s.textContent)
下面的例子将数组中布尔值为false的成员转为0。
Array.from([1, , 2, , 3], (n) => n || 0)
// [1, 0, 2, 0, 3]
另一个例子是返回各种数据的类型。
function typesOf () {
return Array.from(arguments, value => typeof value)
}
typesOf(null, [], NaN)
// ['object', 'object', 'number']
Array.from()可以将各种值转为真正的数组,并且还提供map功能。这实际上意味着,只要有一个原始的数据结构,你就可以先对它的值进行处理,然后转成规范的数组结构,进而就可以使用数量众多的数组方法。
Array.from({ length: 2 }, () => 'jack')
// ['jack', 'jack']
Array.from()的另一个应用是,将字符串转为数组,然后返回字符串的长度。因为它能正确处理各种 Unicode 字符,可以避免 JavaScript 将大于\uFFFF的 Unicode 字符,算作两个字符的 bug。
function countSymbols(string) {
return Array.from(string).length;
}