Kafka-Zookeeper监控工具简介、安装及使用 03
1. Kafka-eagle概述
- Kafka没有专门的监控界面,当业务不复杂时,我们可以使用Kafka命令提供带有Zookeeper客户端工具的工具,可以轻松完成我们的工作。
- 随着业务的复杂性,增加Group和Topic,Kafka命令已经无法满足业务需求,需要专门的Kafka监控系统,来关注消费者应用的细节。
2. Kafka-eagle环境部署和安装
2.1 环境
2.1.1 安装JDK
如果Linux服务器上有JDK环境,则可以忽略此步骤,如果没有需要安装JDK,如何安装JDK请查看如下链接
安装JDK
2.1.2 JAVA_HOME配置
JDK提取可以根据自己的实际情况来提取路径,这里我们解压缩到/user/java/jdk1.8, 入下图所示:
cd /usr/java
tar -zxvf jdk-xxxx.tar.gz
mv jdk-xxxx jdk1.8
...
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/
从新编译环境
source /etc/profile
2.1.3 检验环境配置
最后,我们 java -version 根据以下信息输
java version "1.8.0_60"
Java(TM) SE Runtime Environment (build 1.8.0_60-b27)
Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mod
2.2 安装Kafka-eagle
2.2.1 下载安装包
- 下载地址:Kafka-eagle安装包下载地址1
https://github.com/smartloli/kafka-eagle-bin/archive/v1.2.6.tar
- 下载地址:Kafka-eagel安装包下载地址2
2.2.2 解压
- 将压缩包提取到/data/soft/new目录并解压缩,如下
tar -zxvf kafka-eagle-${version}-bin.tar.gz
- 重新命名该版本
mv kafka-eagle-${version} kafka-eagle
2.2.3 配置Kakfa eagel环境变量
vi /etc/profile
export KE_HOME=/data/soft/new/kafka-eagle
export PATH=$PATH:$KE_HOME/bin
2.2.4 配置Kafka eagle系统配置文件
进入Kafka-eagle的安装目录
cd ${KE_HOME}/conf
vi system-config.properties
# Multi zookeeper&kafka cluster list -- The client connection address of the Zookeeper
cluster is set here
kafka.eagle.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=tdn1:2181,tdn2:2181,tdn3:2181
cluster2.zk.list=xdn1:2181,xdn2:2181,xdn3:2181
# Zkcli limit -- Zookeeper cluster allows the number of clients to connect to
kafka.zk.limit.size=25
# Kafka Eagle webui port -- WebConsole port access address
kafka.eagle.webui.port=8048
# Kafka offset storage -- Offset stored in a Kafka cluster, if stored in the zookeeper,
you can not use this option
cluster1.kafka.eagle.offset.storage=kafka
cluster2.kafka.eagle.offset.storage=kafka
# Whether the Kafka performance monitoring diagram is enabled
kafka.eagle.metrics.charts=false
# If offset is out of range occurs, enable this property -- Only suitable for kafka sql
kafka.eagle.sql.fix.error=false
# Delete kafka topic token -- Set to delete the topic token, so that administrators can
have the right to delete
kafka.eagle.topic.token=keadmin
# kafka sasl authenticate, current support SASL_PLAINTEXT
kafka.eagle.sasl.enable=false
kafka.eagle.sasl.protocol=SASL_PLAINTEXT
kafka.eagle.sasl.mechanism=PLAIN
kafka.eagle.sasl.client=
# Default use sqlite to store data
kafka.eagle.driver=org.sqlite.JDBC
# It is important to note that the '/hadoop/kafka-eagle/db' path must exist.
kafka.eagle.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
kafka.eagle.username=root
kafka.eagle.password=smartloli
# set mysql address
#kafka.eagle.driver=com.mysql.jdbc.Driver
#kafka.eagle.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-
8&zeroDateTimeBehavior=convertToNull
#kafka.eagle.username=root
#kafka.eagle.password=smartloli
2.2.5 启动
- 进入该目录中
cd ${KE_HOME}/bin
- 给启动脚本赋值权限并启动,如下所示
chmod +x ke.sh./ke.sh start
2.3 在window上安装
2.3.1 安装jdk
详见百度
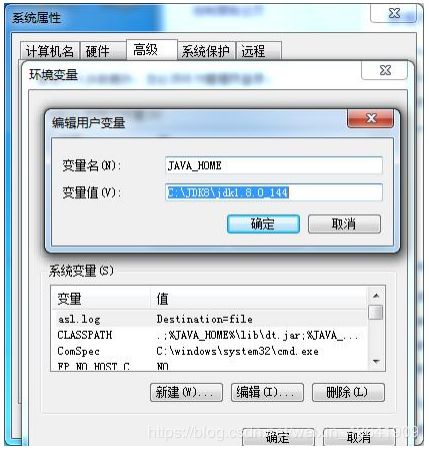
2.3.2 JAVA_HOME配置
具体配置如下图所示:
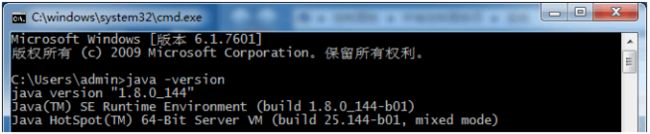
2.3.3 检查JDK
最后,我们java -version根据以下信息输入
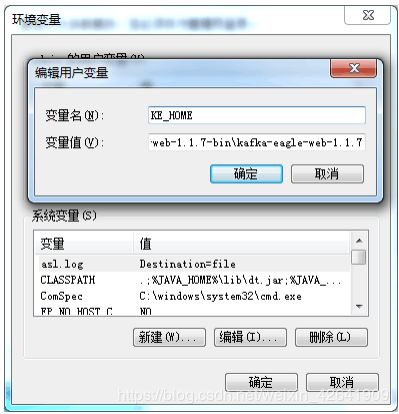
2.3.4 KE_HOME配置
配置环境变量,如下图所示:
2.3.5 启动
转到%KE_HOME%\bin目录并单击该ke.bat文
3. Kafka-eagle入门使用
3.1 DashBoard(仪表盘)
我们http://host:port/ke通过浏览器进入,访问Kafka Eagle DashBoard页面,该页面包含以下内容:
- Brokers
- Topics
- Zookeepers
- Consumers
- Kafka Brokers Graph
如下图所示:
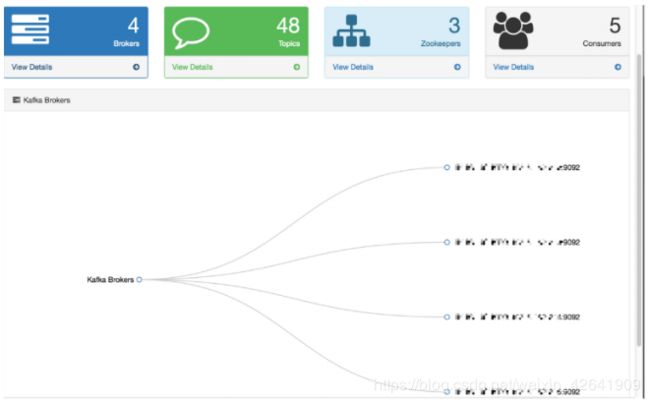
3.2 Topic(主题)
当前主题列包含创建和列表,通过创建模块可以创建自定义分区和备份主题的数量。
- 创建主题(Topic)
指定了Topic的名字,分区,副本数,点击【create】就可以创建主题,如下图所示

- 主题(Topic)列表
该模块遵循Kafka集群的所有主题,包括分区数,创建时间和修改主题,如下图所示:

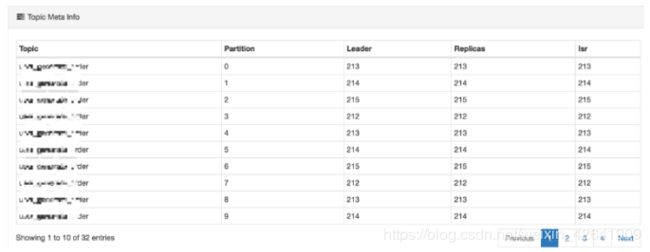
- 主题(Topic)详细信息
每一个主题对应一个超链接,则可以查看主题的细节,如:partition index number,Leader,Replicas和Isr,如下图的图中:
3.3 消费者(Consumer)
改模块显示消费者记录的主题信息,其中包含以下内容:
* Running
* Pending
* Active Topic Graph
如下图所示:
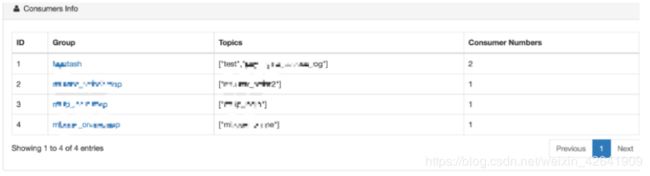

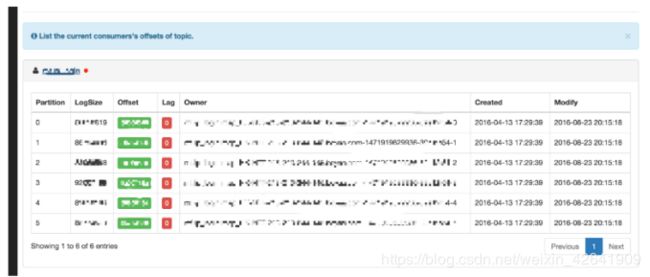
每个Group名称都是超链接,显示消费的详细信息,如下所示:
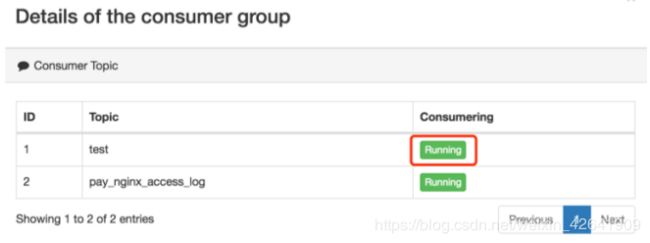
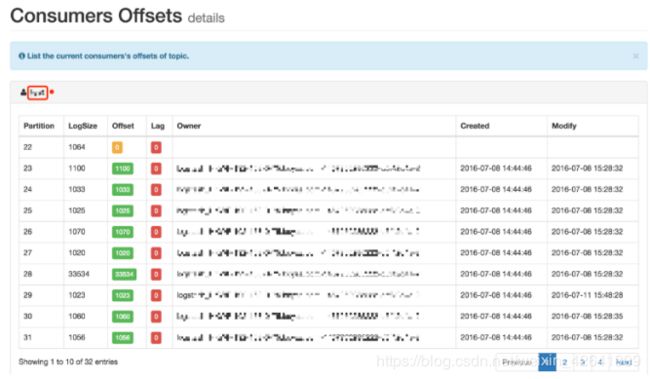
单击Topic正在使用的名称,显示主题的消耗和生产率图表,如下所示:
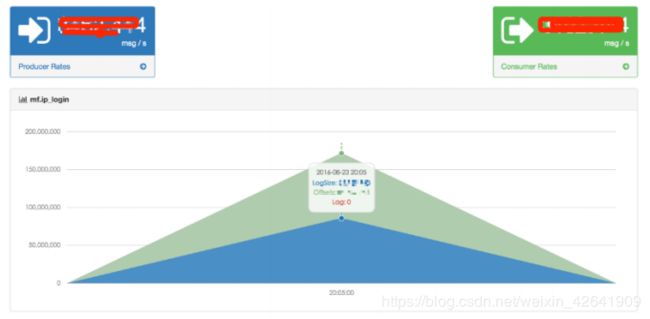
3.4 集群信息
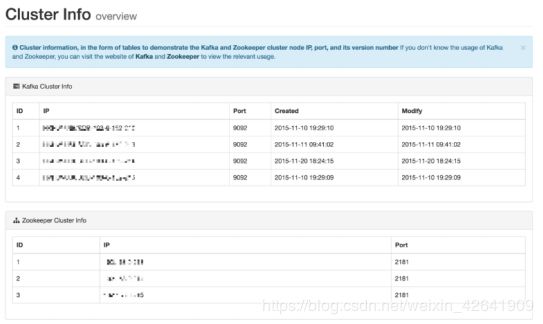
此模块显示Kafka集群信息和Zookeeper集群信息,包括以下内容:
- Kafka Broker Host &IP
- Kafka Broker创建和修改日期
- Zookeeper主机和IP
如下图所示:
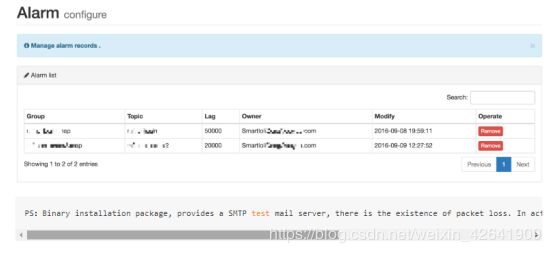
3.5 报警
新的报警模块,要注意自己的Topic报警设置,主题没有消费者信息,超过阀值,报警。目前,报警方式通过消息发出警报,设置如下图所示:
- 配置报警

- 报警清单
报警清单主要列出来自己所配置的一些报警清单,如下图所示:
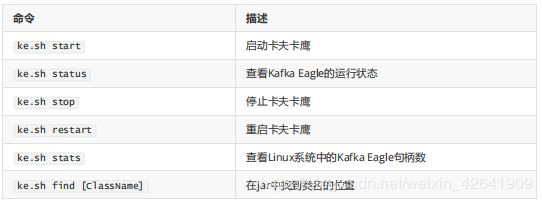
3.6 脚本命令
ke.sh启动脚本中包含以下命令:
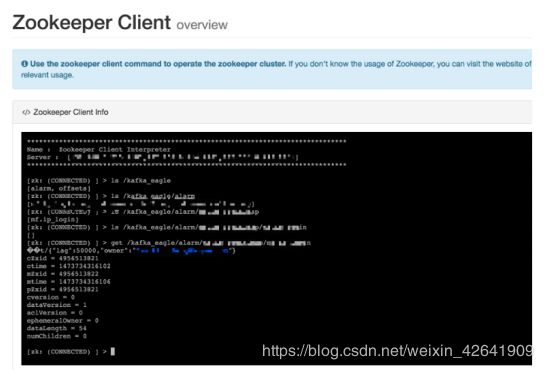
3.7 Zookeeper客户端
Zookeeper客户端命令操作时,目前仅支持ls,delete,get命令操作时,命令不支持,如下图所示:
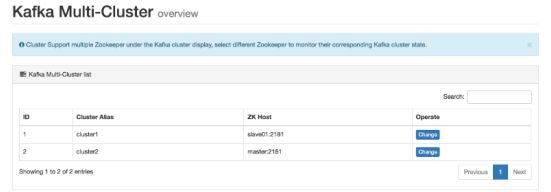
3.8 多集群
此模块显示Multi Kafka集群信息和Zookeeper集群信息,包括以下内容:
- cluster 1
- cluster 2
- cluster 3
如下图所示:
3.9 Kafka SQL
- 编辑SQL
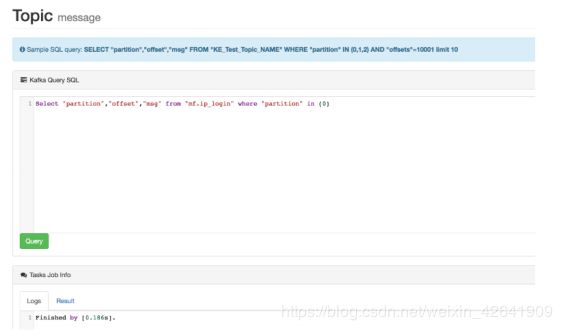
- 数据集
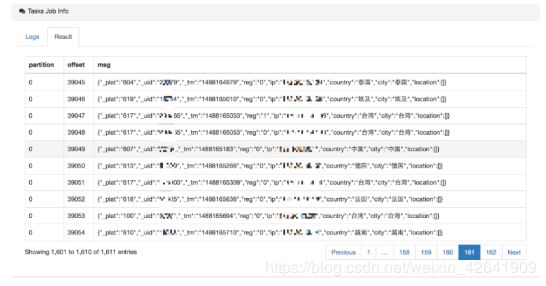
note: Access to topic message data, depending on the underlying interface record of theearliest and latest offset, the default display up to 5000 record
3.10 系统(System)
- Resource
控制删除、编辑等操作的权限,并且不控制浏览器操作。
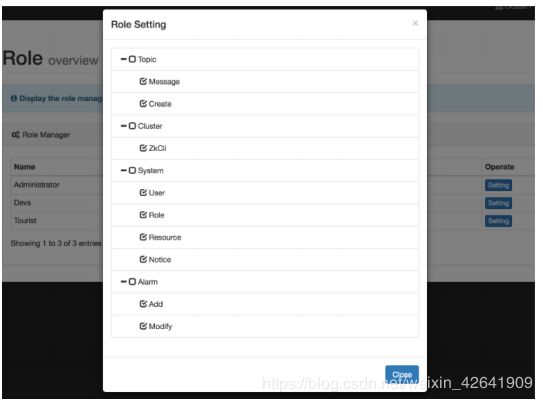
- Role
为每个角色分配一个可访问的目录
- User
添加用户,填写相应的用户信息,单击“提交”,然后填写邮箱将收到相应的登录信息(登录名和密码)。
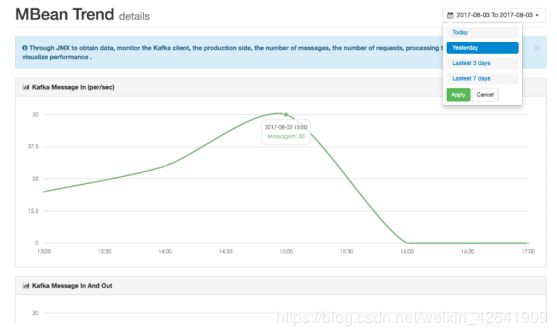
3.11 Metric(度量)
- MBean
通过JMX获取数据,监控Kafka客户端,生产端,消息数量,请求数量,处理时间和其他数据,以可视化性能。

如果您的数据为空,请检查JMX的端口是否已启动。如果您没有启动,可以再开始之前编辑脚本。
vi kafka-server-start.sh...
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
- Trend(趋势)
根据不同的维度观察Kafka索引数据。
4. 设计(Design)
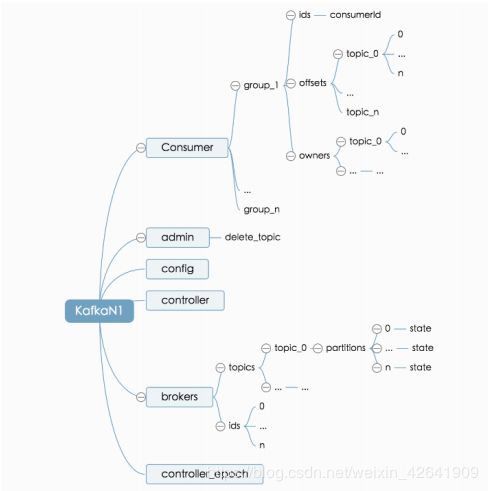
4.1 DataSet收集器
消息数据源kafkaEagel监测(兼容 __consumer_offsets 于 offset 从zookeeper)。由于创建,修改或消费Kafka消息将在Zookeeper中注册,我们可以从变更中获取数据,例如:主题,Brokers,分区和组,Kafka在Zookeeper的存储结构中,如下图所: