YOLOV5测试及训练自己的数据集
YOLOV5项目复现
- 一、YOLOv5 实现检测
- 1.1 下载源码
- 1.2 下载官方模型(.pt文件)
- 1.3 配置虚拟环境
- 1.4 进行测试
- 二、YOLOV5 实现训练
- 2.1 首先是准备数据集
- 2.2 文件修改
- 2.2.1 修改数据集方面的yaml文件
- 2.2.2 修改网络参数方面的yaml文件
- 2.2.3 修改train.py中的一些参数
- 2.3开始训练
- 2.4 ?
- 三、个人对于yolov5的看法
首先说一下软硬件配置这一块:win10 + i7-9700kf + rtx2070Super + cuda10.2 + anaconda
一、YOLOv5 实现检测
1.1 下载源码
进入官方地址,进行源码下载 https://github.com/ultralytics/yolov5[大概4M左右]
1.2 下载官方模型(.pt文件)
文中作者是把模型都放到了谷歌网盘里了,如果没有梯子,访问会很慢–>>作者给的模型地址
如果你实在是下载不下来,并且如果你也还有积分的话–>>CSDN下载模型【可怜可怜孩子吧】
再如果你没有积分,好吧,好吧,那就,那就,那就留邮箱吧,但别忘了给卑微的我点个赞呦、、、额额额额
1.3 配置虚拟环境
虚拟环境的优点不再阐述
创建虚拟环境:conda create -n yolov5 python==3.7,在yolov5中尽量用python3.7。
进 入 环 境 :conda activate yolov5
再安装所需库:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt(使用清华镜像源)
在pip install的时候,可能会出现read timeout的情况,你需要更换镜像源,或者多执行几次pip install,如果还有其他报错,请留言评论区,我会及时回复,因为我在安装的时候也报了一些错,但是都没有记录下来
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
1.4 进行测试
进入到yolov5根目录下,我这里是用的powershell,你也可以在控制台,都是一样的。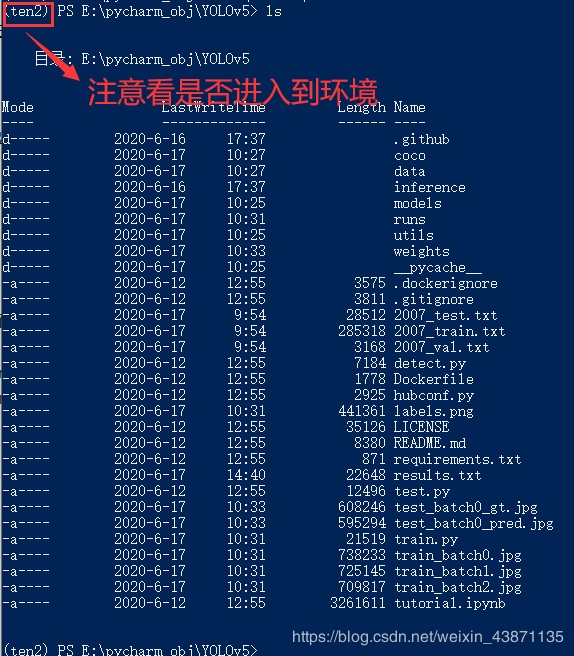
运行测试文件: python detect.py --source 0 【0:是指定的本机摄像头】PS:我特么的竟然一次运行成功,多少是挺失望
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓雷霆嘎巴↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ZBC↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓


二、YOLOV5 实现训练
2.1 首先是准备数据集
★ 数据集的准备工作,我以前的博客有细写过,—>>传送门
★ 数据集准备好后,一定先确保label和JPEGImages这两个文件夹在同一目录里
2.2 文件修改
2.2.1 修改数据集方面的yaml文件
作者是把以前用的.data、.names文件合并到了data/coco.yaml中,打开coco.yaml进行修改
# COCO 2017 dataset http://cocodataset.org
# Download command: bash yolov5/data/get_coco2017.sh
# Train command: python train.py --data ./data/coco.yaml
# Dataset should be placed next to yolov5 folder:
# /parent_folder
# /coco
# /yolov5
# 这些是生成的图片的路径文件,这里是我自己的路径,需要修改成你自己的路径,绝对路径也ok
train: ../coco/2007_train.txt # 118k images
val: ../coco/2007_val.txt # 5k images
test: ../coco/2007_test.txt # 20k images for submission to https://competitions.codalab.org/competitions/20794
# 你数据集的类别数
nc: 1
# 类别的名称
names: ['cell phone']
# Print classes
# with open('data/coco.yaml') as f:
# d = yaml.load(f, Loader=yaml.FullLoader) # dict
# for i, x in enumerate(d['names']):
# print(i, x)
2.2.2 修改网络参数方面的yaml文件
这个相当于以前版本的.cfg文件,在models/yolov3-spp.yaml【当然,你想用哪个模型就去修改对应的yaml文件】
# parameters
nc: 1 # 数据集类别数
depth_multiple: 1.0 # expand model depth
width_multiple: 1.0 # expand layer channels
# anchors【你也可以使用k-means去产出你自己数据集的anchors】
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# darknet53 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Bottleneck, [64]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 2, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 5-P3/8
[-1, 8, Bottleneck, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 8, Bottleneck, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
[-1, 4, Bottleneck, [1024]], # 10
]
# yolov3-spp head
# na = len(anchors[0])
head:
[[-1, 1, Bottleneck, [1024, False]], # 11
[-1, 1, SPP, [512, [5, 9, 13]]],
[-1, 1, Conv, [1024, 3, 1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [1024, 3, 1]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 16 (P5/32-large)
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P4
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [512, 3, 1]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 24 (P4/16-medium)
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 1, Bottleneck, [256, False]],
[-1, 2, Bottleneck, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 30 (P3/8-small)
[[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.2.3 修改train.py中的一些参数
train.py在根目录里,修改一些主要的参数,奥利给
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
parser.add_argument('--epochs', type=int, default=200) # 训练的epoch
parser.add_argument('--batch-size', type=int, default=16) # batch_size 显卡垃圾的话,就调小点
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='*.cfg path')
parser.add_argument('--data', type=str, default='data/coco.yaml', help='*.data path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes')
2.3开始训练
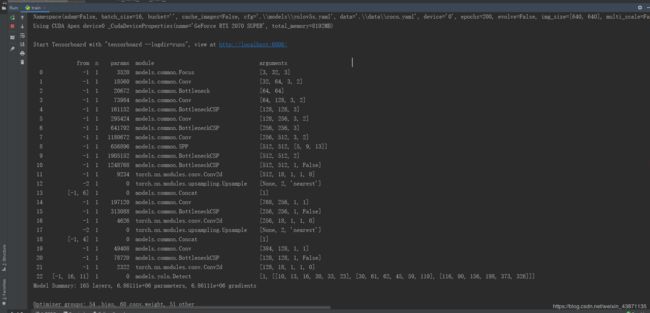
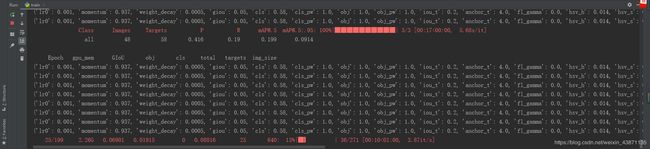
直接 python train.py 就Ok了
成功训练如图所示

↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓无情哈拉少↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
2.4 ?
都已经在训练了,你接下来还有最重要的一步,就是看个日本特产电影啥的,或者是吃个瓜啥的,拉个屎啥的,反正我是去拉屎了
等它训练完就没问题了,但是还是要时不时看一眼,具体看什么,我也不知道呀,反正是看就完事儿了
都训练完了,测试的话,就不用再说的吧,阿sir,
三、个人对于yolov5的看法
先说一个情况吧,我在复现yolov4时,使用1080p的摄像头进行测试的时候,检测的帧率只有1.7fps(在我的rtx2070s显卡上),不管我如何调整cfg文件里的宽高,基本都无济于事,然后我用480p的摄像头才可以达到20fps,不要搞我啊,阿sir,现在摄像头基本都是在1080p检测的啊,480p怎么能满足!!!!!我不知道为什么图像在相同的cfg参数下,分辨率对检测速度影响会这么大。但是,啊,但是,我在用yolov5的时候,用1080P就可以达到实时,最主要的是yolov5的模型非常小,比yolo的前几个系列小了大概4倍,非常适合做嵌入。对于yolov5,虽然是作者自封的,但是非常达到我心里的预期!!!,不吹不黑,yolov5是我遇到最牛啤的目标检测算法,你说呢,你是不是也这么感觉的呢
