单例模式(懒汉+饿汉+双重锁+volatile关键字)
单例模式
目录
单例模式
基本解释
必要条件
基本目标
单例模式的优点
单例模式的缺点
单线程变为多线程时
举例说明
为什么是双重校验锁实现单例模式呢?
volatile 关键字修饰
前驱知识点
关键点
探究与结论
基本解释
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
必要条件
- 1、单例类只能有一个实例。
- 2、单例类必须自己创建自己的唯一实例。
- 3、单例类必须给所有其他对象提供这一实例。
基本目标
设计模式比较常见的就是让你手写一个单例模式或者设计模式项目中的使用。
单例模式的优点
对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销; 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间;避免对资源的多重占用 。
单例模式的缺点
没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
单线程变为多线程时
单例模式在单线程下一般分为懒汉模式,和饿汉模式,总体来说,懒汉模式的优点可以突出的显现;但是当变成多线程时,饿汉模式可以很好的避免安全隐患,而懒汉模式则不可以。
//饿汉式
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}//懒汉模式
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
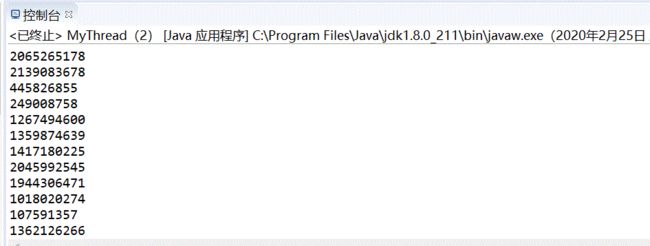
}举例说明
这里通过hashcode验证,忘记hashcode的同学可以看一下关于hash的相关知识
https://blog.csdn.net/weixin_43914278/article/details/104398493
class MySingleton {
private static MySingleton instance = null;
private MySingleton(){}
public static MySingleton getInstance() {
try {
if(instance != null){//懒汉式
}else{
//创建实例之前可能会有一些准备性的耗时工作
Thread.sleep(100);
instance = new MySingleton();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
return instance;
}
}
public class MyThread extends Thread{
@Override
public void run() {
System.out.println(MySingleton.getInstance().hashCode());
}
public static void main(String[] args) {
MyThread[] thread = new MyThread[100];
for(int i = 0 ; i < 100 ; i++){
thread[i] = new MyThread();
}
for (int j = 0; j < 100; j++) {
thread[j].start();
}
}
} 
那么我们就会引入改进方法——双重校验锁实现单例模式。
为什么是双重校验锁实现单例模式呢?
是一个重点知识敲黑板,第一层为了提高效率,思想:优化思想,提升执行效率(速度和开销),第二次实际上才是真正的实现单例模式,实际上变成普通的一个懒汉模式+synchronzied关键字,多了一个同步锁。
第一次校验:也就是第一个if(uniqueInstance==null),这个是为了代码提高代码执行效率,由于单例模式只要一次创建实例即可,所以当创建了一个实例之后,再次调用getUniqueInstance方法就不必要进入同步代码块,不用竞争锁。直接返回前面创建的实例即可。说白了假设第一次不检验,看似问题也不大,但是其实这里所用到的思想就如我们在学习hashmap时为什么需要先比较hashcode再比较equals方法,就一句话谁快选谁,这里看似多判断了一次,然而synchronzied同步锁会大大削减效率,开销很大,所以我们就任性地先比较一次,这样如果运气好的话可以通过if语句,跳过synchronized这个步骤。
第二次校验:也就是第二个if(uniqueInstance==null),这个校验是防止二次创建实例,假如有一种情况,当uniqueInstance还未被创建时,线程t1调用getUniqueInstance方法,由于第一次判断if(uniqueInstance==null),此时线程t1准备继续执行,但是由于资源被线程t2抢占了,此时t2页调用getUniqueInstance方法,同样的,由于singleton并没有实例化,t2同样可以通过第一个if,然后继续往下执行,同步代码块,第二个if也通过,然后t2线程创建了一个实例singleton。此时t2线程完成任务,资源又回到t1线程,t1此时也进入同步代码块,如果没有这个第二个if,那么,t1就也会创建一个singleton实例,那么,就会出现创建多个实例的情况,但是加上第二个if,就可以完全避免这个多线程导致多次创建实例的问题。
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() { };//
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) { //目的:提高效率
//刚开始所有进入这行代码的线程,uniqueInstance对象都是null
//可能是第一个进去的线程,这时候uniqueInstance对象都是null
//也可能是第一个线程之后的线程进入并执行
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
volatile 关键字修饰
前驱知识点
synchronized对象进行加锁操作,会造成线程执行代码互斥
理解多个线程执行同一行代码
三个线程抢占资源,出现问题
package test_26;
public class MyThread implements Runnable{
private int num=10;
@Override
public void run() {
// TODO 自动生成的方法存根
for(int i=0;i<500;i++) {
if(this.num>=0) {
System.out.println(Thread.currentThread().getName()+(this.num--));
}
}
}
public static void main(String[] args) {
MyThread myThread=new MyThread();
Thread thread1=new Thread(myThread,"a");
Thread thread2=new Thread(myThread,"b");
Thread thread3=new Thread(myThread,"c");
thread1.start();
thread2.start();
thread3.start();
}
}

对象的实例化是做了个什么事情
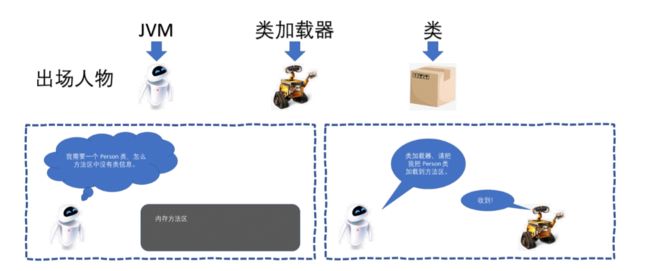
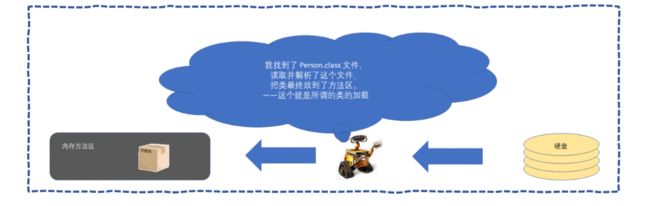
1.从方法去中找该类的信息
如果没找到?触发类的加载(类的加载器:)
做月饼-找模子模型:
举个例子类似于要做一个月饼,你是不是首先需要找月饼模子,从方法中找该类的信息就是你到处找一个月饼模子,如果你要是自己找不到,就需要有人帮你找,类的加载器就是到处给你找月饼模子的部门
2.对象最终放在堆上
3.计算对象的大小(属性(包括父类))
4.开辟的空间初始化为0X0(属性的默认值都是0)
5.属性的初始化

static与private的作用
一个类中如果有成员变量或者方法被static关键字修饰,那么该成员变量或方法将独立于该类的任何对象。它不依赖类特定的实例,被类的所有实例共享,只要这个类被加载,为了避免单例的类被频繁创建对象,我们可以用private的构造函数来确保单例类无法被外部实例化。
实例分析
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton();
public class Singleton {
private volatile static Singleton uniqueInstance;//1
private Singleton() { };//2
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) { //目的:提高效率
//刚开始所有进入这行代码的线程,uniqueInstance对象都是null
//可能是第一个进去的线程,这时候uniqueInstance对象都是null
//也可能是第一个线程之后的线程进入并执行
synchronized (Singleton.class) {
//尝试获取同一个对象锁的线程,尝试获取锁,获取不到就阻塞
//锁住类名的class(这里用到了反射的知识)
if (uniqueInstance == null) {
//初始化操作,使用volatile关键字禁止指令重排序
uniqueInstance = new Singleton(); //3
}
}
}
return uniqueInstance;
}
}这段代码其实是分为三步执行:
Ⅰ、给 uniqueInstance分配内存
Ⅱ、调用 Singleton 的构造函数来初始化成员变量
Ⅲ、将uniqueInstance对象指向分配的内存空间(执行完这步uniqueInstance 就为非 null 了), 但是在 JVM 的即时编译器中存在指令重排序的优化。也就是说上面的第二步和第三步的顺序是不能保证的,最终的执行顺序可能是 1-2-3 也可能是 1-3-2。如果是后者,则在 3 执行完毕、2 未执行之前,被线程二抢占了,这时 instance 已经是非 null 了(但却没有初始化),所以线程二会直接返回 instance,然后使用,然后顺理成章地报错。
例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被 初始化。使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
例如现在有2个线程A,B,线程A在执行 uniqueInstance = new Singleton(); 代码时,B线程进来,而此时A执行了 1和3,没有执行2,此时B线程判断s不为null 直接返回一个未初始化的对象,就会出现问题
关于多线程的分析图

实际应用,还是通过hashcode
package test_26;
class MySingleton {
//使用volatile关键字保其可见性,防止重排序
volatile private static MySingleton instance = null;
private MySingleton(){}
public static MySingleton getInstance() {
try {
if(instance != null){//懒汉式
}else{
//创建实例之前可能会有一些准备性的耗时工作
Thread.sleep(300);
synchronized (MySingleton.class) {
if(instance == null){//二次检查
instance = new MySingleton();
}
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
return instance;
}
}
public class MyThread extends Thread{
@Override
public void run() {
System.out.println(MySingleton.getInstance().hashCode());
}
public static void main(String[] args) {
MyThread[] thread = new MyThread[10];
for(int i = 0 ; i < 10 ; i++){
thread[i] = new MyThread();
}
for (int j = 0; j < 10; j++) {
thread[j].start();
}
}
}

初步结论
volatile的可见性: 一个线程在进行写操作的同时, 可以被其他正在进行读操作的线程立即看到。
volatile的禁止指令重排序:防止初始化对象与对象赋值给引用的顺序发生颠倒的错误。
关于volatile这里介绍的相对比较少,详细看学姐的博客,正所谓眼前好景道不得,学姐题诗在上头,直接拿来主义了:https://blog.csdn.net/asdx1020/article/details/104443565
严谨探究
第一:保证此变量对所有线程的可见性,这里的"可见性"是指 : 当一条线程修改了这个变量的值,新值对于其他线程来说是可以立即得知的。而普通变量做不到这一点,普通变量的值在线程间传递均需要通过主内存来完成。例如:线程A修改一个普通变量的值,然后向主内存进行回写,另外一条线程B在线程A回写完成之后再从主内存进行读取操作,新值才会对线程B可见。volatile变量在各个线程中是一致的,但是volatile变量的运算,在并发下一样是不安全的。原因在于Java里面的运算并非原子操作。
package test_229;
public class Main {
public static volatile int num = 0;
public static void increase() {
num++;
}
public static void main(String[] args) {
Thread[] threads = new Thread[10];
for (int i = 0; i < 10; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 100; j++) {
increase();
}
}
});
threads[i].start();
}
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(num);
}
}这段代码你运行几遍,会有不同的答案,输出值可能是正确的1000,可能900,可能995,……这些都运行出来过 ,问题就在于为什么呢》》》实际上num++等同于num = num+1。看到这里,聪明的你熟悉多线程立刻眼前一亮。
volatile关键字保证了num的值在取值时是正确的,但是在执行num+1的时候,其他线程可能已经把num值增大了,这样在+1后会把较小的数值同步回主内存之中。
由于volatile关键字只保证可见性,在不符合以下两条规则的运算场景中,我们仍然需要通过加锁(synchronized或者
lock)来保证原子性。
第二:使用volatile变量的语义是禁止指令重排序。普通的变量仅仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序和程序代码中执行的顺序一致。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对
后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句
放到其前面执行。
volatile应用环境
1. 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值
2. 变量不需要与其他的状态变量共同参与不变约束
