验证码识别(二)tensorflow实战训练技巧- 全国高校计算机能力挑战赛(基于tensorflow+python+opencv)
验证码识别-全国高校计算机能力挑战赛(基于tensorflow+python+opencv)(二)
接着上一篇~
- 读取图片和图片预处理;
- 搭建VGG神经网络;
- 开始训练和一些训练技巧;
- 制作新数据集和数据增强;
- 模型融合;
对比一下不同灰度化结果

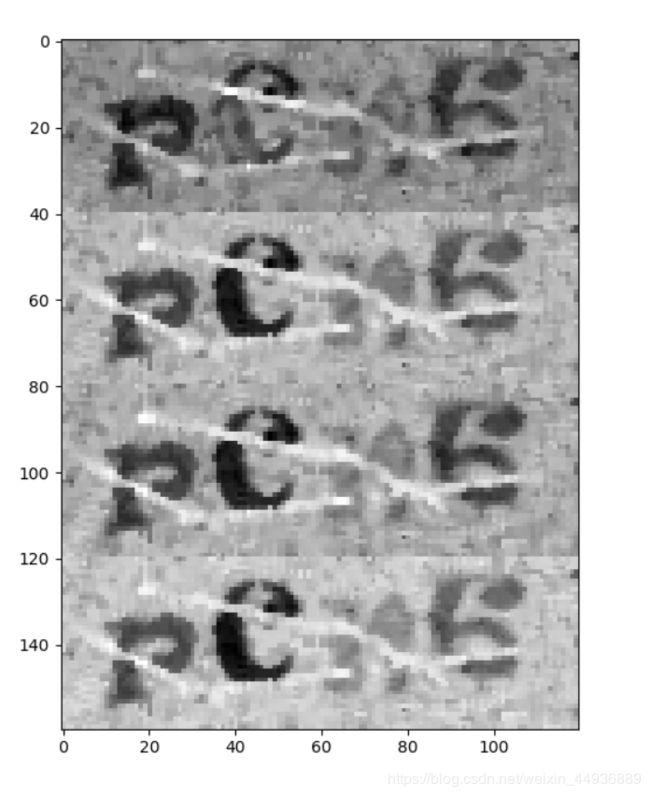

上图从上至下依次为最大灰度化,cv2自带的灰度化,均值灰度化和权重灰度化。
搭建VGG神经网络
上一篇我们完成了图片的预处理,这里就用tensorflow搭建一个VGG网络模型。(版本号:python3.7, tensorflow1.15.0)
注意pip安装tensorflow时默认安装最新版本(2.0.0),可能会报错,不如卸载重新安装吧。。。
pip uninstall tensorflow
pip install tensorflow==1.15
或者有能力的也可以安装gpu版本(需要cuda10.1和cudnn,cuda10.0安装tensorflow1.14版本),需要安装包的可以私戳我~
pip install tensorflow-gpu==1.15

vgg网络结构如图,我们会在最后几层做一点小小的调整。
这里定义了一个 Net 类,通过 train_net 方法进行训练,模型保存在model文件夹下。
先上代码:
# network_gray_vgg.py
import tensorflow as tf
import config as cfg
from read_data import Reader
import numpy as np
import os
class Net(object):
def __init__(self, is_training=True):
self.batch_size = cfg.IMAGE_BATCH
self.learning_rate = cfg.LEARNING_RATE
self.height = cfg.HEIGHT
self.width = cfg.WIDTH
self.value_num = 4
self.cls_num = len(cfg.CLASSES)
self.batch_num = cfg.BATCH_NUM
self.is_training = is_training
self.reader = Reader()
self.steps = cfg.TRAIN_STEPS
self.x = tf.placeholder(
tf.float32, [None, self.height, self.width, 1]
)
self.y = tf.placeholder(
tf.float32, [None, self.cls_num]
)
self.keep_rate = tf.placeholder(tf.float32)
self.y_hat, self.logits = self.network(self.x)
self.right_pre = tf.equal(
tf.argmax(self.y, axis=-1),
tf.argmax(self.y_hat, axis=-1)
)
self.accuracy = tf.reduce_mean(
tf.cast(self.right_pre, tf.float32)
)
self.saver = tf.train.Saver()
self.optimizer = tf.compat.v1.train.AdamOptimizer(
learning_rate=self.learning_rate)
self.loss = self.loss_layer(self.y, self.y_hat)
self.trian_step = self.optimizer.minimize(self.loss)
def train_net(self):
with tf.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
ckpt = tf.train.get_checkpoint_state(cfg.MODEL_PATH)
if ckpt and ckpt.model_checkpoint_path:
# 如果保存过模型,则在保存的模型的基础上继续训练
self.saver.restore(sess, ckpt.model_checkpoint_path)
print('Model Reload Successfully!')
for step in range(2000):
loss_list = []
test_data = self.reader.generate(
cfg.TEST_NUM, is_training=False)
test_dict = {
self.x: test_data['images'],
self.y: test_data['labels'],
self.keep_rate: 1.0}
for batch in range(cfg.BATCH_NUM):
batch_data = self.reader.generate(self.batch_size, is_training=True)
feed_dict = {
self.x: batch_data['images'],
self.y: batch_data['labels'],
self.keep_rate: cfg.KEEP_RATE
}
_, loss = sess.run(
[self.trian_step, self.loss],
feed_dict=feed_dict
)
print('batch:{}/{} loss:{} '.format(
batch, self.batch_num, loss
), end='\r')
loss_list.append(loss)
loss_value = np.mean(
np.array(loss_list)
)
pred = sess.run(self.y_hat, test_dict)
acc = self.calculate_test_acc(test_data['labels'], pred)
print('step:{}/{} loss:{} accuracy:{}'.format(
step, self.steps, loss_value, acc
))
self.saver.save(sess, cfg.MODEL_PATH+'model.ckpt')
if acc > cfg.STOP_ACC:
print('Early Stop with acc:{}'.format(acc))
break
def loss_layer(self, y, y_hat):
loss = tf.nn.softmax_cross_entropy_with_logits_v2(
logits=y_hat, labels=y
)
return tf.reduce_mean(loss)
def network(self, inputs):
with tf.variable_scope('VGG'): net = self.conv2d(
inputs, filters=64, k_size=3,
strides=1, padding='SAME'
)
net = self.conv2d(
net, filters=64, k_size=3,
strides=1, padding='SAME'
)
net = self.max_pool2d(
net, k=3, strides=2,
padding='SAME'
) # (20,15,3)
net = self.conv2d(
net, filters=128, k_size=3,
strides=1, padding='SAME'
)
net = self.conv2d(
net, filters=128, k_size=3,
strides=1, padding='SAME'
)
net = self.max_pool2d(
net, k=3, strides=2,
padding='SAME'
) # (10, 8, 3)
net = tf.layers.batch_normalization(
net, training=self.is_training
)
net = self.conv2d(
net, filters=256, k_size=1,
strides=1, padding='SAME'
)
net = self.conv2d(
net, filters=256, k_size=1,
strides=1, padding='SAME'
)
net = self.max_pool2d(
net, k=3, strides=2,
padding='SAME'
) # (5,4,3)
net = self.conv2d(
net, filters=512, k_size=3,
strides=1, padding='VALID'
)
net = self.conv2d(
net, filters=512, k_size=2,
strides=1, padding='VALID'
)
net = tf.contrib.layers.flatten(net)
weights_1 = tf.Variable(tf.truncated_normal( [2*1*512, 128], stddev=0.1, mean=0))
biases_1 = tf.Variable(tf.random.normal(shape=[128]) )
net = tf.add(tf.matmul(net, weights_1), biases_1) # -1*256
weights_3 = tf.Variable(tf.truncated_normal( [128, self.cls_num], stddev=0.1, mean=0))
biases_3 = tf.Variable(tf.random.normal(shape=[self.cls_num]) )
logits = tf.add(tf.matmul(net, weights_3), biases_3)
if self.is_training:
logits = tf.nn.dropout(logits, rate=1-self.keep_rate)
predictions = tf.nn.softmax(logits, axis=-1)
return predictions, logits
def conv2d(self, x, filters, k_size=3, strides=1, padding='SAME', dilation=[1, 1]):
return tf.layers.conv2d(x, filters, kernel_size=[k_size, k_size], strides=[strides, strides],
dilation_rate=dilation, padding=padding, activation=tf.nn.relu,
use_bias=True)
def max_pool2d(self, x, k, strides, padding='SAME'):
return tf.layers.max_pooling2d(inputs=x, pool_size=k, strides=strides, padding=padding)
def average_pool2d(self, x, k, strides, padding='SAME'):
return tf.layers.average_pooling2d(inputs=x, pool_size=k, strides=strides, padding=padding)
def calculate_test_acc(self, labels, pred):
labels = labels.reshape((cfg.TEST_NUM, 4, self.cls_num))
pred = pred.reshape((cfg.TEST_NUM, 4, self.cls_num))
labels = np.argmax(labels, axis=-1)
pred = np.argmax(pred, axis=-1)
acc = 0
for i in range(cfg.TEST_NUM):
if all(np.equal(labels[i], pred[i])):
acc += 1
return acc/cfg.TEST_NUM
if __name__ == "__main__":
if not os.path.exists(cfg.MODEL_PATH):
os.makedirs(cfg.MODEL_PATH)
net_obj = Net()
net_obj.train_net()
1、传入一个batch的图片(大小为(batch_size, 40, 32, 1),1代表灰度单通道),输出长度为62(字母+数字)的向量标签;
2、train_net 方法训练模型,如果之前有训练过的模型,则加载模型继续训练;
3、net_work 方法定义了VGG网络;
4、其他的方法都是常规的函数,这里不详细说明了;
训练结果
大概迭代100次,loss会从4.12(-1 * log(1/62),相当于瞎猜)下降到3.1左右,准确率(注意这里的准确率是单数字/字母准确率的4次方)大概会到0.96~0.97之间(单数字0.99以上);
训练时注意的几点:
1、程序没有使用学习率衰减,起始学习率一般在1e-3到1e-5之间,训练loss到3.2左右可以手动减小一个数量级(这里修改config.py参数就可以了);
2、使用了图片的随机偏移,可以稍微减小一下数据量较小的问题;
3、keep_prob 一开始可以设置为0.8左右,随着训练过程可以慢慢调大到0.95左右,能够提高在测试集上的准确率;
4、图片预处理很重要!很重要!很重要!(说三遍),计算机视觉图像预处理是很重要的一环,搞好预处理比做一个调参侠提高准确率快得多(参考不同的处理方法对比);
5、要做数据均值归零化和方差归一化;
6、测试集的准确率相比训练集的是一个更好的参考,如果没有测试集标签不如从训练集分离出一些;
7、batch_normalization 能够加速收敛;
8、处理这样的图片最好要灰度化,因为RGB三通道在计算机这里相当于多了更多干扰,使得模型难以收敛;
9、处理前要先观察图像特征,观察图片可以看出,字母/数字部分RGB普遍比背景小,但是RGB三通道分布很随机,所以使用最大灰度化方法得到的结果,似乎比其他的方法似乎更好一点;
10、使用gamma变换能够使灰度图对比度更高,从而使得识别更容易;
11、不要一开始就像自己造一个网络,最好使用已经有的模型(经典的如VGG,ResNet等)训练;
进度~
- 读取图片和图片预处理;
- 搭建VGG神经网络;
- 开始训练和一些训练技巧;
- 制作新数据集和数据增强;
- 模型融合;
下一篇将讲一下如何制作跟训练集一样的验证码数据集~敬请期待(咕咕咕)
联系我们:
权重文件需要的请私戳作者~
联系我时请备注所需模型权重,我会拉你进交流群~
该群会定时分享各种源码和模型,之前分享过的请从群文件中下载~