PyTorch 深度学习的技巧
7. 深度学习的技巧
- 过拟合与欠拟合
- 欠拟合
- 过拟合
- 交叉验证
- 数据划分
- K-flod 交叉验证
- 正则化
- 奥卡姆剃刀原理
- 防止过拟合的方法
- 正则化
- L1范数
- L2范数
- 动量与学习率衰减
- 动量
- 学习率衰减
- 提前停止更新与 dropout
- 提前停止更新
- dropout
过拟合与欠拟合
欠拟合
模 型 简 单 , 表 达 能 力 不 够 , 导 致 欠 拟 合.
过拟合
现 实 生 活 中 更 多 地 是 过 拟 合 , 模 型 表 达 能 力 太 强 , 数 据 量 太 少 导 致 的。
那如何检测过拟合状况,当发生了过拟合如何减少过拟合,是要着重考虑和解决的问题。
检测过拟合-交叉验证
防止过拟合-正则化
交叉验证
数据划分
拟合是模型学习过程中非常重要的一个问题。那么如何检测过拟合也是非常重要
的。通过在数据集划分进行训练测试,寻找在过拟合之前的最优参数。

事实上将数据划分成训练集, 验证集, 测试集。

将数据划分成三类,客户用保密的测试集来测试模型效果,防止作弊
train_db = datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
test_db = datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
test_loader = torch.utils.data.DataLoader(test_db,
batch_size=batch_size, shuffle=True)
print('train:', len(train_db), 'test:', len(test_db))
train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000])
print('db1:', len(train_db), 'db2:', len(val_db))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(
val_db,
batch_size=batch_size, shuffle=True)
K-flod 交叉验证
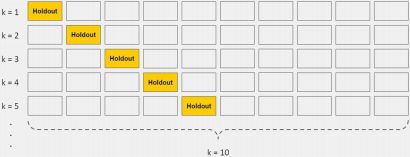
将训练集划分成十份,每次将其中九份用于训练,一份用于验证,选择较好的时间戳权值参数。
正则化
奥卡姆剃刀原理
能使用简单模型参数量解决的模型问题不要使用复杂模型的参数量。
More things should not be used than are necessary.
防止过拟合的方法
- 数据扩充
- 限制模型的复杂度
- 浅层网络
- 添加正则化项
- Dropout
- Data argument(数据增强)
- Early Stop
正则化
Regularization == Weight Decay
L1范数
J ( θ ) = − 1 m ∑ i = 1 m [ y i l o g y i ^ + ( 1 − y i ) l o g ( 1 − y i ) + λ ∑ i = 1 n ∣ θ ∣ ] J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}\big[y_ilog\hat{y_i}+(1-y_i)log(1-y_i)+\lambda\sum_{i=1}^{n}|\theta|\big] J(θ)=−m1i=1∑m[yilogyi^+(1−yi)log(1−yi)+λi=1∑n∣θ∣]
regularizatin_loss = 0
for param in model.parameters():
regularization_loss += torch.sum(torch.abs(param))
classify_loss = criteon(logits, target)
loss = classify_loss + 0.01 + regularization_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
L2范数
J ( θ ) = − 1 m ∑ i = 1 m [ y i l o g y i ^ + ( 1 − y i ) l o g ( 1 − y i ) + 1 2 λ ∣ ∣ W ∣ ∣ 2 ] J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}\big[y_ilog\hat{y_i}+(1-y_i)log(1-y_i)+\frac{1}{2}\lambda||W||^2\big] J(θ)=−m1i=1∑m[yilogyi^+(1−yi)log(1−yi)+21λ∣∣W∣∣2]
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01)
criteon = nn.CrossEntropyLoss().to(device)
动量与学习率衰减
动量
momentum 动量也称惯性
w k + 1 = w k − α ∇ f ( w k ) w^{k+1}=w^{k}-\alpha\nabla f(w^k) wk+1=wk−α∇f(wk)
z k + 1 = β z k + ∇ f ( w k ) z^{k+1}=\beta z^k + \nabla f(w^k) zk+1=βzk+∇f(wk)
w k + 1 = w k − α z k + 1 w^{k+1}=w^k-\alpha z^{k+1} wk+1=wk−αzk+1
加入动量的迭代式,实际上就是当前的梯度方向加上上一次的惯性的方向。尽快收敛,并且大概率的跳出局部极小值。
-
没加动量的例子
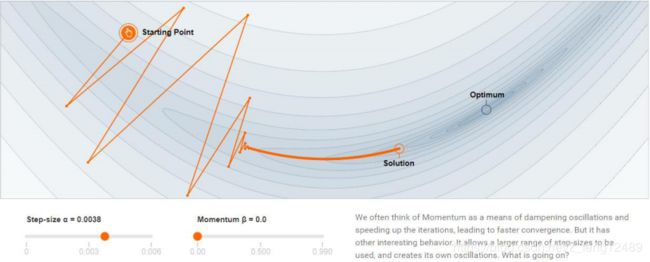
梯度更新刁钻,迭代效率低,容易陷入局部极小。 -
引入动量的例子

optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
梯度更新效率高,越过了局部极小,步入全局最小。
PyTorch 中 Adam 优化器已经内置了 momentum 机制,所以不需要变量维护;
但是 SGD 却没有。
学习率衰减
learning rate decay
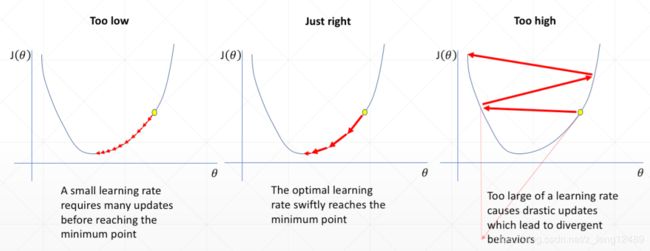
Learning Rate 设置过大,导致摇摆,得不到较好的效果。
Learning Rate 设置过小,更新迭代次数过多。
学习率衰减,刚开始选择大一点的学习率,也不会较大影响,前期还能较快更新。 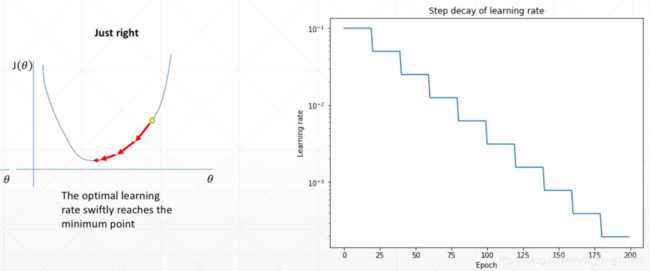
学习率衰减,刚开始选择大一点的学习率,也不会较大影响,前期还能较快更新。
**pytorch 设置学习率
- 方法一遇平原衰减
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
schedule = ReduceLROnPlateau(optimizer, 'min') #'学习率衰减监听'
for epoch in xrange(args.start_opech, args.epochs):
train(train_loader, model, criterion, optimizer, epoch)
result_avg, loss_val = validate(val_model, criterion, epoch)
schedule.step(loss_val)
- 方法二定时衰减
'''
Assuming optimizer uses lr = 0.05 for all groups
lr = 0.05 if epoch < 30
lr = 0.005 if 30 <= epoch <= 60
lr = 0.0005 if 60 <= epoch <= 90
'''
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100)
schedule.step()
train(...)
validate(...)
提前停止更新与 dropout
提前停止更新
提前停止更新是为了模型学习过拟合。
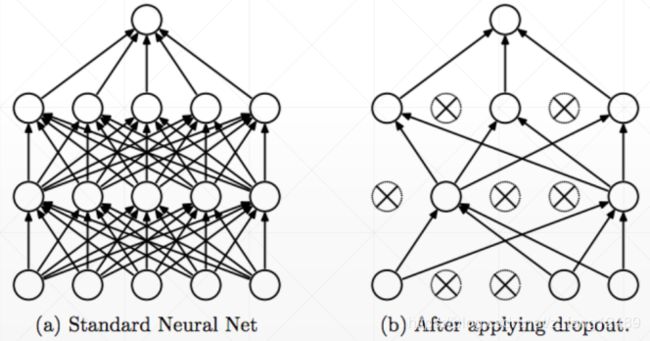
dropout
dropout 也是防止过拟合常用的小技巧。
- Learning less to learn better
- Each connection has ρ= 0, 1 to lose
net_dropped = torch.nn.Sequential(
torch.nn.Linear(784, 200),
torch.nn.Dropout(0.5), #dropout 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(200, 200),
torch.nn.Dropout(0.5), #dropout 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(200, 10)
)
在训练时,我们把部分连接断掉;但是在测试或者验证时,必须把状态切换回来。
for epoch for range(epochs):
# train
net_dropped.train()
for batch_idx, (data, target) in enumerate(train_loader):
...
net_dropped.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
...