ResNeSt:Split-Attention Networks(翻译)
《ResNeSt: Split-Attention Networks》
作者团队:亚马逊(张航和李沐等)&UC Davis
代码(提供PyTorch和MXNet双版本):
代码:https://github.com/zhanghang1989/ResNeSt
论文:https://hangzhang.org/files/resnest.pdf
摘要
近年来,图像分类模型不断发展,但由于其结构简单、模块化,大多数下游应用如目标检测、语义分割等仍然采用ResNet变体作为骨干网络。我们提出了一个modularSplit注意块,该注意块可以跨功能图组进行注意,通过叠加这些分割的注意块ResNet样式,我们得到了一个新的ResNet变体,我们称之为ResNeSt。我们的网络保留了整个ResNet结构,可以直接用于下游任务,而不引入额外的计算成本。ResNeSt模型优于具有类似模型复杂度的其他网络。例如,ResNeSt-50在使用224×224的单个作物的情况下,在magnet上达到81.13%的top-1精度,比先前的最佳ResNet变体的精度高出1%以上。这种改进有助于后续的任务,包括目标检测、实例分割和语义分割。例如,简单地用ResNeSt-50替换theResNet-50骨干网,我们将MS-COCO上更快的RCNN从39.3%提高到42.3%,DeeplabV3on-ADE20K上的mIoU从42.1%提高到45.1%1。
介绍
图像分类是计算机视觉研究中的一项基础性工作。用于图像分类的神经网络通常是为其他应用而设计的神经网络的骨干,例如目标检测、语义分割和姿态估计。最近的工作通过大规模神经结构搜索(NAS)显著提高了图像分类的准确性。尽管这些nas衍生模型具有最先进的性能,但它们通常没有针对通用/商用处理硬件(CPU/GPU)上的训练效率或内存使用进行优化。由于过多的内存消耗,这些模型的一些较大版本甚至无法在GPU上使用适当的每个设备批处理大小进行训练。
最近对下游应用程序的研究仍然使用ResNet或其变体作为CNN的主干。其简单和模块化的设计可以很容易适应各种任务。然而,由于ResNet模型最初是为图像分类而设计的,它们可能不适合各种下游应用,因为接收场大小有限且缺乏跨通道交互。这意味着,提高特定计算机视觉任务的性能需要“网络手术”来修改ResNet,使其对特定任务更有效。例如,一些方法添加一个金字塔模块或引入远程连接或使用跨通道特征图注意力。虽然这些方法确实提高了某些任务的转移学习性能,但它们提出了一个问题:我们能否创建一个通用的主干,它具有普遍改进的特征表示,从而提高同时跨多个任务的性能?跨通道信息在下游应用中取得了成功,而最近的图像分类网络更多地关注于组或深度卷积。尽管这些模型在分类任务中具有出色的计算能力和准确性,但由于它们的隔离表示无法捕获跨通道关系,因此不能很好地将其传递给其他任务。因此,需要具有跨通道表示的网络。
作为本文的第一个贡献,我们探索了一个简单的ResNet架构修改,在单个网络块中合并特征图分散注意力。更具体地说,我们的每一块thefeature-map分为几组(沿着通道尺寸)和finer-grainedsubgroups或分裂,每组的特征表示在哪里determinedvia加权组合表示的分裂(权重选择基于全局上下文信息)。我们指的是产生的单元asaSplit-Attentionblock,它保持了简单和模块化。通过堆叠几个分散注意力的模块,我们创建了一个类似resnet的网络,称为dresnest (sstand代表“分散”)。我们的架构不需要比现有的resnet变种更多的计算,并且很容易被用作其他视觉任务的主干。
本文的第二个贡献是图像分类和转移学习应用的大规模基准。我们发现,使用最新主干的模型能够在图像分类、目标检测、实例分割和语义分割等多个任务上达到最优状态。提出的ResNeSt性能优于所有现有的resnetvariables,具有相同的计算效率,甚至比通过神经结构搜索生成的最先进的CNN模型在速度和精度上取得了更好的权衡,如表1所示。我们的单一级联- rcnn模型使用ResNeSt-101主干实现48.3%的box mAP和41.56%的mask mAPon MS-COCO实例分割。我们的单个DeepLabV3模型再次使用了ResNeSt-101主干,在ADE20K场景解析验证集上获得了46.9%的mIoU,比之前的最佳结果高出了1%以上的mIoU。其他结果可在第5和第6节中找到。
2 相关工作
现代CNN架构 自AlexNet以来,深卷积神经网络一直主导着图像分类。随着这一趋势,研究从工程手工制作的功能转移到工程网络架构。NIN首先使用全局平均池层代替重连接层,采用1×1卷积层学习特征映射通道的非线性组合,这是第一种特征映射注意机制。VGG提出了一种模块化的网络设计策略,将同一类型的网络块反复叠加,Highway network 引入了highway 连接,使得信息无衰减地跨层流动,有助于网络的收敛。ResNet在前人工作成功的基础上,引入了一种身份跳跃连接,减轻了深层神经网络中梯度消失的困难,并允许网络学习更深层次的特征表示。ResNet已经成为最成功的CNN体系结构之一,并被广泛应用于各种计算机视觉应用中。

多路径和特征图注意力 多路径表示在GoogleNet中显示了成功,其中每个网络块由不同的卷积核组成。ResNeXt[在theResNet瓶块中采用群卷积,将多径结构转换为统一运算。SE-Net通过自适应调整信道特征响应引入了信道注意机制。SK Net通过两个网络分支引起了功能映射注意。受之前方法的启发,我们的网络将信道方向的注意力泛化为特征映射组表示,并使用统一的CNN操作符对其进行模块化和加速。
神经结构搜索(NAS) 随着计算能力的不断提高,人们的兴趣已经开始从手工设计的体系结构转移到根据特定任务进行自适应调整的系统化架构。最近的神经网络结构搜索算法已经自适应地产生了CNN结构,这些结构实现了最新的分类性能,例如:阿米巴网、MNASNet和EfficientNet。尽管它们在图像分类方面取得了巨大的成功,但它们之间的元网络结构是不同的,这使得下游模型难以建立。相反,我们的模型保留ResNet元结构,可以直接应用于许多现有的下游模型。我们的方法还可以增加神经架构搜索的搜索空间,潜在地提高整体性能,这可以在以后的工作中加以研究。
3 Split-Attention Networks
我们现在引入了分割注意块,它允许在不同的特征映射组之间进行特征映射注意。稍后,我们将描述我们的网络实例,以及如何通过标准CNN运营商加速这种架构。
3.1 Split-Attention Block
我们的分割注意块是一个计算单元,由特征映射组和分割注意操作组成。图1(右)描述了一个分割注意块的概述。
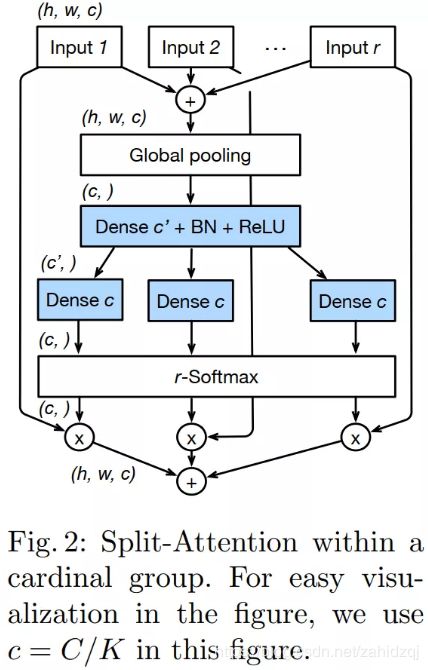
Feature-map Group(特征映射组) 和在ResNeXt块中一样,特征可以分为几组,特征图组的数量由基数超参数K给出。我们将所得的特征图组称为基数组。 我们引入了一个新的基数超参数R,该基数指示基数组内的拆分数,因此要素组的总数为G = KR。 我们可以对每个单独的组应用一系列变换{F1,F2,... FG},然后对于i∈{1,2,... G},每个组的中间表示为Ui = Fi(X)。
Split Attention in Cardinal Groups(基数组的分割注意)接下来,通过对多个分割进行元素求和融合,可以获得每个基数组的组合表示。第k个基数群的表示为![]() ,其中
,其中![]() 表示k∈1,2,…k,H,W和C表示块输出特征映射大小。嵌入信道统计的全局上下文信息可以通过跨空间维度
表示k∈1,2,…k,H,W和C表示块输出特征映射大小。嵌入信道统计的全局上下文信息可以通过跨空间维度![]() 的全局平均池来收集组件计算如下:
的全局平均池来收集组件计算如下: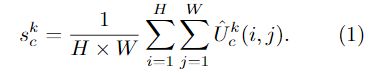
基数群表示的加权融合![]() 是使用通道级软注意进行聚合的,其中每个特征映射通道都是使用分割上的加权组合生成的。第c个通道计算如下:
是使用通道级软注意进行聚合的,其中每个特征映射通道都是使用分割上的加权组合生成的。第c个通道计算如下: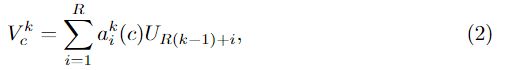
其中![]() 表示(软)分配权重,由以下给出:
表示(软)分配权重,由以下给出: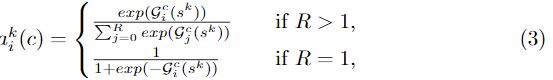
映射![]() 基于全局上下文表示
基于全局上下文表示![]() 确定第c信道的每个分割的权重。
确定第c信道的每个分割的权重。
ResNeSt Block 然后,将基数组表示形式沿通道维级联:V = Concat {V1,V2,... VK}。 与标准残差块中一样,如果输入和输出特征图共享相同的形状,则使用快捷方式连接生成我们的Split-Attention块的最终输出Y:Y = V + X。 对于具有跨步的块,将适当的变换τ应用于快捷连接以对齐输出形状:Y = V + T(X)。 例如,T可以是跨步卷积或带池组合卷积。
实例化、加速和计算成本 图1(右)显示了我们的Split-Attention块的实例,其中组变换Fi是1×1卷积,然后是3×3卷积,并且使用两个具有ReLUactivation的完全连接层对注意力权重函数G进行参数化。 我们以基数为主的视图(具有相同基数索引的要素图组彼此相邻)绘制此图,以方便地描述总体逻辑。 通过将布局切换到以基数为主的视图,可以使用标准的CNN层(例如组卷积,组完全连接的层和softmax操作)轻松加速此块,我们将在补充材料中详细介绍。 具有相同基数和通道数的“分割注意”块的参数数量和FLOPS与“残余块”大致相同。
与现有注意方法的关系 SE-Net最初引入的squeeze-and-attention(原始论文中称为“激励”)的思想是利用全局背景来预测渠道方面的关注因素。 当radix = 1时,我们的Split-Attention块将squeeze-and-attention操作应用于每个基数组,而SE-Net则在整个块的顶部运行,而与多个组无关。 诸如SK-Ne之类的先前模型在两个网络分支之间引入了关注点,但是它们的操作并未针对训练效率和扩展到大型神经网络进行优化。 我们的方法概括了基数组设置内特征图注意的先验工作,其实现在计算上仍然有效。 图1显示了与SE-Net和SK-Net块的总体比较.
4 网络和训练
4.1 网络调整
平均下采样 当迁移学习的下游应用是密集的预测任务(例如检测或分段)时,保留空间信息就变得至关重要。卷积层需要使用零填充策略来处理特征图边界,这在转移到其他密集的预测任务时通常不是最佳的。 而不是在过渡块(对空间分辨率进行下采样)上使用分步卷积,我们使用内核大小为3 * 3的平均池化层。
来自Resnet-D的调整 我们还采用了两种简单而有效的ResNet修改方法:(1)将第一个7×7卷积层替换为三个连续的3×3卷积层,它们具有与原始设计相同的接收场大小,并且具有相似的计算成本。(2) 对于跨距为2的转换块,在1×1卷积层之前的快捷连接中加入2×2平均池层。我们还采用了两种简单而有效的ResNet修改方法:(1)将第一个7×7卷积层替换为三个连续的3×3卷积层,它们具有与原始设计相同的接收场大小,并且具有相似的计算成本。(2) 对于跨距为2的转换块,在1×1卷积层之前的快捷连接中加入2×2平均池层。
5 图像分类结果
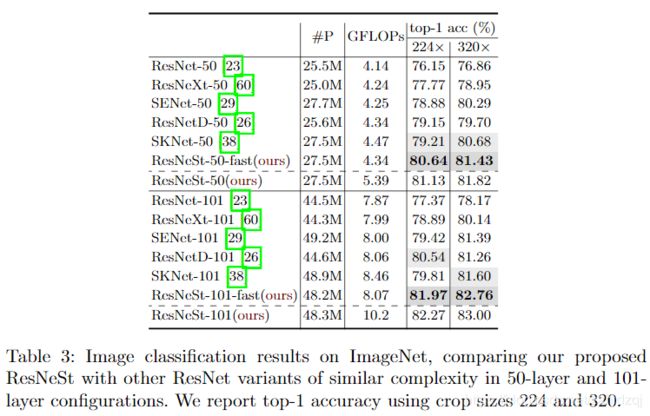
5.3 与SOTA比较

6 迁移学习结果
6.1 目标检测
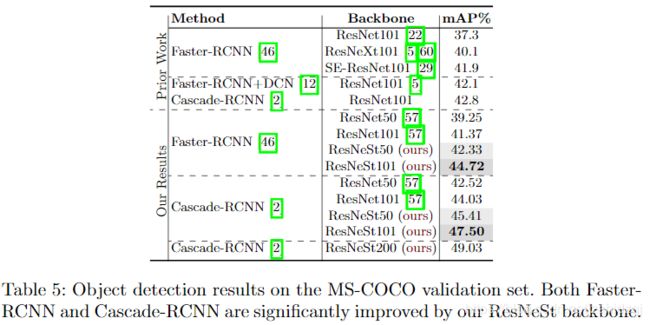
6.2 实例分割

7 总结
这项工作提出了具有新颖的Split-Attention块的ResNeSt体系结构,该块可以普遍改进学习的特征表示,从而提高图像分类,对象检测,实例分割和语义分割的性能。 在后面的下游任务中,通过简单地将骨干网络切换到我们的ResNeSt所产生的经验改进明显优于应用于标准骨干(例如ResNet)的特定于任务的修改。 我们的Split-Attention块易于使用且计算效率高,因此应广泛应用于视觉任务。