哈工大2019年春算法设计与分析期末复习
本文原载于我的博客,地址:https://blog.guoziyang.top/archives/22/
第二章 算法分析的数学基础
2.1 复杂性函数的阶
阶为复杂性函数的主导项。
如函数 T ( n ) = a n 2 + b n + c T(n)=an^2+bn+c T(n)=an2+bn+c的主导项为 a n 2 an^2 an2,当输入的n较大时,低阶项相对意义不大,系数a的意义也不大,故称:函数 T ( n ) T(n) T(n)的阶为 n 2 n^2 n2。
同阶函数:设 f ( n ) f(n) f(n)和 g ( n ) g(n) g(n)是正值函数,如果 ∃ c 1 , c 2 > 0 , n 0 , ∀ n > n 0 , c 1 g ( n ) ≤ f ( n ) ≤ c 2 g ( n ) \exists c_1,c_2>0,n_0,\forall n>n_0,c_1g(n)\le f(n)\le c_2g(n) ∃c1,c2>0,n0,∀n>n0,c1g(n)≤f(n)≤c2g(n),则称 f ( n ) f(n) f(n)与 g ( n ) g(n) g(n)同阶,记作 f ( n ) = θ ( g ( n ) ) f(n)=\theta(g(n)) f(n)=θ(g(n))。保证最高次项次数相同即可。
如果 f ( n ) = O ( n k ) f(n)=O(n^k) f(n)=O(nk),则称 f ( n ) f(n) f(n)是多项式界限的。
低阶函数:设 f ( n ) f(n) f(n)和 g ( n ) g(n) g(n)是正值函数,如果 ∃ c > 0 , n 0 , ∀ n > n 0 , f ( n ) ≤ c g ( n ) \exists c>0,n_0,\forall n>n_0,f(n)\le cg(n) ∃c>0,n0,∀n>n0,f(n)≤cg(n),则称 f ( n ) f(n) f(n)比 g ( n ) g(n) g(n)低阶或 g ( n ) g(n) g(n)是 f ( n ) f(n) f(n)的上界,记作 f ( n ) = O ( g ( n ) ) f(n)=O(g(n)) f(n)=O(g(n))。 f ( n ) f(n) f(n)比 g ( n ) g(n) g(n)低阶, g ( n ) g(n) g(n)是 f ( n ) f(n) f(n)的上界。
O ( g ( n ) ) O(g(n)) O(g(n))可以视为所有比 g ( n ) g(n) g(n)低阶的函数的集合 { f ( n ) ∣ ∃ c , n 0 , ∀ n > n 0 , f ( n ) ≤ c g ( n ) } \{f(n)|\exists c,n_0,\forall n>n_0,f(n)\le cg(n)\} {f(n)∣∃c,n0,∀n>n0,f(n)≤cg(n)}。
高阶函数:设 f ( n ) f(n) f(n)和 g ( n ) g(n) g(n)是正值函数,如果 ∃ c > 0 , n 0 , ∀ n > n 0 , f ( n ) ≥ c g ( n ) \exists c>0,n_0,\forall n>n_0,f(n)\ge cg(n) ∃c>0,n0,∀n>n0,f(n)≥cg(n),则称 f ( n ) f(n) f(n)比 g ( n ) g(n) g(n)高阶或 g ( n ) g(n) g(n)是 f ( n ) f(n) f(n)的下界,记作 f ( n ) = Ω ( g ( n ) ) f(n)=\Omega(g(n)) f(n)=Ω(g(n))。 f ( n ) f(n) f(n)比 g ( n ) g(n) g(n)高阶, g ( n ) g(n) g(n)是 f ( n ) f(n) f(n)的下界。
O ( g ( n ) ) O(g(n)) O(g(n))可以视为所有比 g ( n ) g(n) g(n)高阶的函数的集合 { f ( n ) ∣ ∃ c , n 0 , ∀ n > n 0 , f ( n ) ≥ c g ( n ) } \{f(n)|\exists c,n_0,\forall n>n_0,f(n)\ge cg(n)\} {f(n)∣∃c,n0,∀n>n0,f(n)≥cg(n)}。
注意: θ \theta θ表示渐进紧界, O O O表示渐进上界, Ω \Omega Ω表示渐进下界。由于上界和下界可以不是紧的,于是 n = O ( n ) = O ( n 2 ) = … n=O(n)=O(n^2)=… n=O(n)=O(n2)=…且 O ( n ) ∈ O ( n 2 ) O(n)\in O(n^2) O(n)∈O(n2),即比n低阶的函数必然比 n 2 n^2 n2低阶。
严格低阶函数:设 f ( n ) f(n) f(n)和 g ( n ) g(n) g(n)是正值函数,如果 ∃ c > 0 , n 0 , ∀ n > n 0 , f ( n ) < c g ( n ) \exists c>0,n_0,\forall n>n_0,f(n)
O标记可能是或者不是紧的,o标记用于肯定不是紧的标记,于是 2 n 2 = O ( n 2 ) , 2 n = O ( n 2 ) , 2 n = o ( n 2 ) 2n^2=O(n^2),2n=O(n^2),2n=o(n^2) 2n2=O(n2),2n=O(n2),2n=o(n2),但是 2 n 2 ≠ o ( n 2 ) 2n^2\not=o(n^2) 2n2=o(n2)。
严格高阶函数:与严格低阶函数类似。记为 f ( n ) = ω ( g ( n ) ) f(n)=\omega(g(n)) f(n)=ω(g(n))。
显然, f ( n ) ∈ ω ( g ( n ) ) f(n)\in\omega(g(n)) f(n)∈ω(g(n)) iff g ( n ) ∈ o ( f ( n ) ) g(n)\in o(f(n)) g(n)∈o(f(n))。、
性质:所有的阶都具有传递性,非紧阶具有自反性, θ \theta θ具有对称性, O O O与 Ω \Omega Ω具有反对称性, o o o与 ω \omega ω具有反对称性。
2.2 递归方程
定义:使用具有小输入值的相同方程来描述一个方程,用自身来定义自身。
Master方法:可用于求解 T ( n ) = a T ( n b ) + f ( n ) T(n)=aT(\frac{n}{b})+f(n) T(n)=aT(bn)+f(n)型的方程,其中 a ≥ 1 , b > 1 a\ge 1,b>1 a≥1,b>1是常数, f ( n ) f(n) f(n)为正函数。
- 若 f ( n ) = O ( n l o g b a − ϵ ) , ϵ > 0 f(n)=O(n^{log_ba-\epsilon}),\epsilon>0 f(n)=O(nlogba−ϵ),ϵ>0是常数,则 T ( n ) = θ ( n l o g b a ) T(n)=\theta(n^{log_ba}) T(n)=θ(nlogba)。
- 若 f ( n ) = θ ( n l o g b a ) f(n)=\theta(n^{log_ba}) f(n)=θ(nlogba),则 T ( n ) = θ ( n l o g b a l g n ) T(n)=\theta(n^{log_ba}lgn) T(n)=θ(nlogbalgn)。
- 若 f ( n ) = Ω ( n l o g b a + ϵ ) , ϵ > 0 f(n)=\Omega(n^{log_ba+\epsilon}),\epsilon>0 f(n)=Ω(nlogba+ϵ),ϵ>0是常数,且对于所有充分大的n, a f ( n b ) ≤ c f ( n ) , c < 1 af(\frac{n}{b})\le cf(n),c<1 af(bn)≤cf(n),c<1是常数,则 T ( n ) = θ ( f ( n ) ) T(n)=\theta(f(n)) T(n)=θ(f(n))。
该方法的较为直观的方法:将 f ( n ) f(n) f(n)与 n l o g b a n^{log_ba} nlogba比较:
- 若 n l o g b a n^{log_ba} nlogba大,则 T ( n ) = θ ( n l o g b a ) T(n)=\theta(n^{log_ba}) T(n)=θ(nlogba)。
- 若 f ( n ) f(n) f(n)大,则 T ( n ) = θ ( f ( n ) ) T(n)=\theta(f(n)) T(n)=θ(f(n))。
- 若 f ( n ) f(n) f(n)与 n l o g b a n^{log_ba} nlogba同阶,则 T ( n ) = θ ( n l o g b a l g n ) = θ ( f ( n ) l g n ) T(n)=\theta(n^{log_ba}lgn)=\theta(f(n)lgn) T(n)=θ(nlogbalgn)=θ(f(n)lgn)。
扩展master定理:消除 f ( n ) f(n) f(n)为正函数的要求。
第二条修正为:若 f ( n ) = θ ( n l o g b a l o g k n ) , k ≥ 0 f(n)=\theta(n^{log_ba}log^kn),k\ge0 f(n)=θ(nlogbalogkn),k≥0,则 T ( n ) = θ ( n l o g b a l o g k + 1 n ) T(n)=\theta(n^{log_ba}log^{k+1}n) T(n)=θ(nlogbalogk+1n)。
第三章 分治算法
3.1 分治算法的原理
三个阶段:Divide-Conquer-Combine
时间复杂度分析:
假设划分为 a a a个子问题,每个子问题的大小为 n b \frac{n}{b} bn,则划分时间为D(n),Conquer时间为 a T ( n b ) aT(\frac{n}{b}) aT(bn),Combine的时间为 C ( n ) C(n) C(n),最后得到递归方程
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲T(n)=\begin{cas…
举例:求最大值

时间复杂度分析:
T ( n ) = 2 T ( n / 2 ) + 2 = 2 ( 2 T ( n / 2 2 ) ) + 2 = 2 2 T ( n / 2 2 ) + 2 2 + 2 = . . . = 2 k − 1 T ( 2 ) + 2 k − 1 + 2 k − 2 + . . . + 2 2 + 2 = 2 k − 1 + 2 k − 2 = 3 n 2 − 2 T(n)=2T(n/2)+2\\=2(2T(n/2^2))+2=2^2T(n/2^2)+2^2+2\\=...\\=2^{k-1}T(2)+2^{k-1}+2^{k-2}+...+2^2+2\\=2^{k-1}+2^k-2\\=\frac{3n}{2}-2 T(n)=2T(n/2)+2=2(2T(n/22))+2=22T(n/22)+22+2=...=2k−1T(2)+2k−1+2k−2+...+22+2=2k−1+2k−2=23n−2
举例:整数乘法
计算n位二进制整数X和Y的乘积,通常的时间复杂度为O( n 2 n^2 n2)

3.3 基于分治的排序算法
3.3.1 QuickSort
Divide:使用partition算法生成一个q,并根据q将数据划分成两个部分。
Conquer:递归地使用QuickSort对两部分进行排序。
Combine:由于两部分已经有序,什么都不做
Partition算法:选择x作为划分点(通常是最后一个元素),并将x与其它元素逐一比较。以下选取4作为x,并使用i和j将小于4的归在左侧,大于4的归在右侧,并在最后将4添加至中间。

// 时间复杂度为O(n)
Partition(A, p, r)
{
x = A[r];
i = p - 1;
for j = p to r - 1
do if A[j] <= x
i = i + 1;
exchange(A[i] A[j]);
exchange(A[i + 1], A[r]);
return i + 1;
}
QuickSort(A, p, r)
{
if p < r
then q = Partition(A, p, r);
QuickSort(A, p, q - 1);
QuickSort(A, q + 1, r);
}
使用循环不变量保证算法的正确性:循环开始、每一次循环体结束、以及算法结束后,都要保证循环不变量成立。
时间复杂度:partition算法复杂度为 θ ( n ) \theta(n) θ(n),所以QuickSort的时间复杂度为
T ( n ) = 2 T ( n / 2 ) + θ ( n ) = θ ( n l o g n ) T(n)=2T(n/2)+\theta(n)=\theta(nlogn) T(n)=2T(n/2)+θ(n)=θ(nlogn)
最坏的情况为分割点恰好在数组开头或者结尾,这时的时间复杂度为 T ( n ) = T ( 0 ) + T ( n − 1 ) + θ ( n ) = θ ( n 2 ) T(n)=T(0)+T(n-1)+\theta(n)=\theta(n^2) T(n)=T(0)+T(n−1)+θ(n)=θ(n2)
平均时间复杂度为 T ( n ) = O ( n l o g n ) T(n)=O(nlogn) T(n)=O(nlogn)
随机快速排序:
用于防止输入基本有序,则在选取主元时加入随机因素。
Partition算法改为Randomized-Partition:
Randomized-Partition(A, p, r)
{
i = Random(p, r);
A[r]与A[i]交换;
Return Partition(A, p, r);
}
期望的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
3.3.2 排序问题的下界
解决该问题的任意算法的最小时间复杂度,问题的下界是不唯一的,但是只有紧的下界是有意义的。
基于比较和交换的排序算法可以用一棵二叉决策树来描述:

则对于特定输入的排序过程,就是从根到叶子的一条路径。
n个元素有n!中不同的排列,排序过程对应为高度为h,具有n!个叶子节点的二叉决策树,由于高度为h的二叉树最多有 2 h 2^h 2h个叶子节点,则有 2 h ≥ n ! 2^h\ge n! 2h≥n!,即
n ! = 2 π n ( n e ) n h ≥ l g ( n ! ) = Ω ( n l g n ) n!=\sqrt{2\pi n(\frac{n}{e})^n}\\h\ge lg(n!)=\Omega(nlgn) n!=2πn(en)nh≥lg(n!)=Ω(nlgn)
则排序问题的下界为 Ω ( n l g n ) \Omega(nlgn) Ω(nlgn)
3.4 中值与顺序统计量
3.4.1 Decrease and Conquer原理
原始问题划分为若干子问题,将原始问题转化为其中某个子问题的计算。例如,折半查找。
与Divide and Conquer不同,该方法(减治方法)仅需要求解某一个子问题,即可得到原始问题的解。
3.4.2 Selection Problem
描述:寻找序列中的第k小的元素
原始算法:排序后寻找,时间复杂度为O(nlgn)
主要思想:S= { a 1 , a 2 , … , a n } \{a_1, a_2, …, a_n\} {a1,a2,…,an},用S中的一个值p将S分成三部分,分别为比p小的( S 1 S_1 S1),和p相等的( S 2 S_2 S2),比p大的( S 3 S_3 S3)。如果| S 1 S_1 S1|>k,那么第k小的元素就在 S 1 S_1 S1中,继续对 S 1 S_1 S1进行上述步骤。如果 ∣ S 1 ∣ + ∣ S 2 ∣ > k |S_1|+|S_2|>k ∣S1∣+∣S2∣>k,那么p就是第k小的元素。否则,S中第k小的元素就是 S 3 S_3 S3中第 ( k − ∣ S 1 ∣ − ∣ S 2 ∣ ) (k-|S_1|-|S_2|) (k−∣S1∣−∣S2∣)小的元素,对 S 3 S_3 S3进行上述步骤。
如何寻找p:将n个元素划分为n/5个子集(每个子集有5个元素),将每个子集内部排序,p为所有子集的中间子集的中间元素。
该算法的时间复杂度为 O ( n ) O(n) O(n)
3.5 寻找最近的一对点(一维空间)
原始算法:将点集排序,扫描即可,时间复杂度为O(nlgn)
分治算法:
边界条件:如果Q中仅包含两个点,就返回这个点对。
Divide:求出Q里点的中位数m,用m将Q划分为两个大小相等的子集合 Q 1 , Q 2 Q_1, Q_2 Q1,Q2
Conquer:递归地在 Q 1 , Q 2 Q_1,Q_2 Q1,Q2中找出最接近的点对
Merge:将 Q 1 Q_1 Q1中最大点和 Q 2 Q_2 Q2中最小点组成一个点对,与刚刚找到的两个点对比较,找出结果。
该算法的时间复杂度为O(nlgn)
二维空间的搜索:
边界条件:若Q中仅包含三个点,就返回最近的点对
Divide:寻找x坐标的中位数并分割
Conquer:递归地在两部分中寻找最小点对
Merge:设两部分的最小点对距离为d,则在中线左右距离为d的临界区查找小于d的点对。
在临界区的搜索算法:
点对必然跨越中线
Q‘L = QL - {非临界区点};
Q‘R = QR - {非临界区点} ;
For p in Q’L Do
For q in Q’R Do
If Dis(p, q)<d
Then d=Dis(p, q), 记录(p, q);
如果d发生过变化, 与最后的d对应的点对即为(pl , qr),
否则不存在(pl, qr)
该算法的时间复杂度为O(nlgn)
3.6 凸包算法
原始算法:
求Q中y-坐标值最小的点p0;
按照与p0极角(逆时针方向)大小排序Q中其余点,结果为<p1, p2, …, pn>;
Push p0, p1, p2 into S;
FOR i=3 TO n DO
While Next-to-top(S)、 Top(S)和pi形成非左移动 Do
Pop(S);
Push(pi, S);
Return S.
时间复杂度:O(nlgn)
分治算法:
边界条件:如果|Q|<3,算法停止,如果|Q|=3,按照逆时针方向输出CH(Q)的顶点
Divide:使用x轴中线将Q划分为左右两个集合
Conquer:递归地为左右两个部分构造凸包
Merge:对左右两个凸包上的点进行原始算法合并凸包
该算法的时间复杂度为O(nlgn)
第四章 动态规划算法
4.1 概述
用于解决分治算法的问题:如果子问题不是相互独立的,分治算法会重复计算
优化问题:动态规划是解决优化问题的一种常见方法
步骤:
- 把原始子问题划分为一系列子问题
- 求解每个子问题一次,并将结果保存在表中,以后用到直接存取
- 自底向上求解
条件:
- 优化子结构:当一个问题的优化解包含了子问题的优化解时, 我们说这个问题具有优化子结构。
- 重叠子问题
算法设计步骤:
- 分析优化解的结构
- 递归地定义最优解的代价
- 递归地划分子问题,直至不可分
- 自底向上地求解各个子问题
- 计算优化解的代价并保存之
- 获取构造最优解的信息
- 根据构造最优解的信息构造优化解
4.2 矩阵链乘法
问题:输入多个矩阵,求出计算所有矩阵相乘所需的最小计算代价
矩阵乘法的代价:若A为 p × q p\times q p×q的矩阵,B是 q × r q\times r q×r的矩阵,则 A × B A\times B A×B的代价是 O ( p q r ) O(pqr) O(pqr)。
动态规划算法:
-
分析优化解的结构
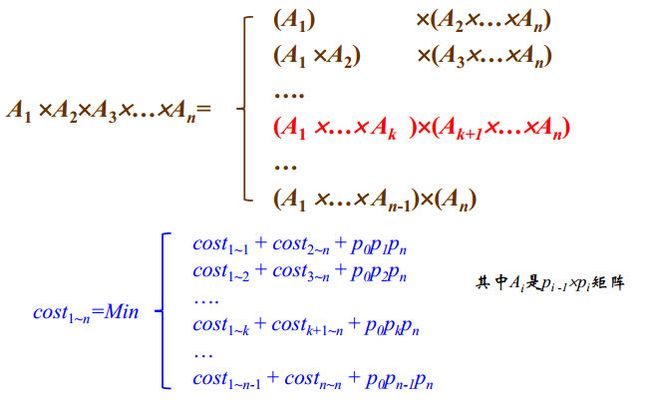
优化子结构:如果红色方案代价最小,那么计算 A 1 × … × A k A_1\times…\times A_k A1×…×Ak的方案必须是代价最小的方案,计算 A K + 1 × … × A n A_{K+1}\times…\times A_n AK+1×…×An的方案必须是代价最小的方案
子问题重叠性:
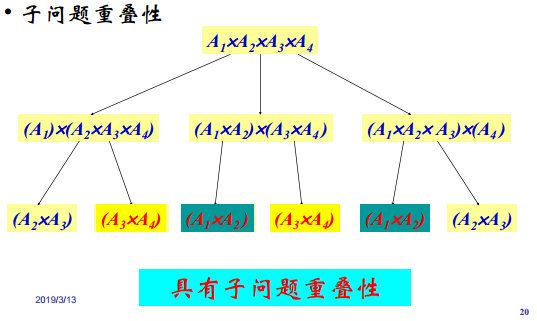
-
递归定义最优解代价
设m[i, j]为计算 A i ∼ j A_{i\sim j} Ai∼j的最小乘法数
考虑到所有的k,优化解的代价方程为
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲\begin{cases}m[…

最终的最优解存放在m[1, 5]中。
该算法的时间复杂度为 O ( n 3 ) O(n^3) O(n3)
4.3 最长公共子序列(LCS)
问题:寻找两个序列的最长公共子序列
注意:子序列不同于子串,子序列可以不相互连接
第i前缀:设X=( x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn)是一个序列,则Xi=( x 1 , . . . , x i x_1, ..., x_i x1,...,xi)是X的第i前缀。
优化子结构:设X=( x 1 , x 2 , … , x m x_1, x_2, …, x_m x1,x2,…,xm),Y= { y 1 , . . . , y n } \{y_1, ..., y_n\} {y1,...,yn}为两个序列, L C S X Y = { z 1 , . . . , z k } LCS_{XY}=\{z_1, ..., z_k\} LCSXY={z1,...,zk}是X与Y的LCS,则有
- 如果 x m = y n x_m=y_n xm=yn,则 z k = x m = y n z_k=x_m=y_n zk=xm=yn, L C S X Y = L C S X m − 1 Y n − 1 + < x m = y n > LCS_{XY}=LCS_{X_{m-1}Y_{n-1}}+
- 如果 x m ≠ y n x_m\not=y_n xm=yn,且 z k ≠ x m z_k\not=x_m zk=xm,则 L C S X Y LCS_{XY} LCSXY是 X m − 1 X_{m-1} Xm−1和Y的LCS,即 L C S X Y = L C S X m − 1 Y LCS_{XY}=LCS_{X_{m-1}Y} LCSXY=LCSXm−1Y
- 如果 x m ≠ y n x_m\not=y_n xm=yn,且 z k ≠ y n z_k\not=y_n zk=yn,则 L C S X Y LCS_{XY} LCSXY是X和 Y n − 1 Y_{n-1} Yn−1的LCS,即 L C S X Y = L C S X Y n − 1 LCS_{XY}=LCS_{XY_{n-1}} LCSXY=LCSXYn−1
定义 C [ i , j ] = X i C[i,j]=X_i C[i,j]=Xi与 Y j Y_j Yj的LCS长度。
子问题重叠性:
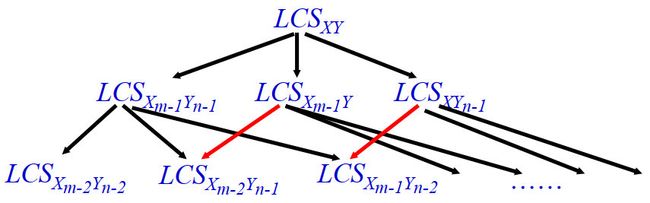
LCS长度的递归方程:
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲C[i,j]=\begin{c…
递归求解过程:
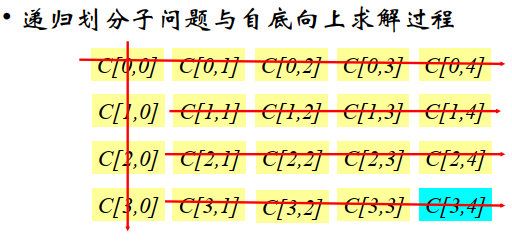
字符串的第0位认为为空。
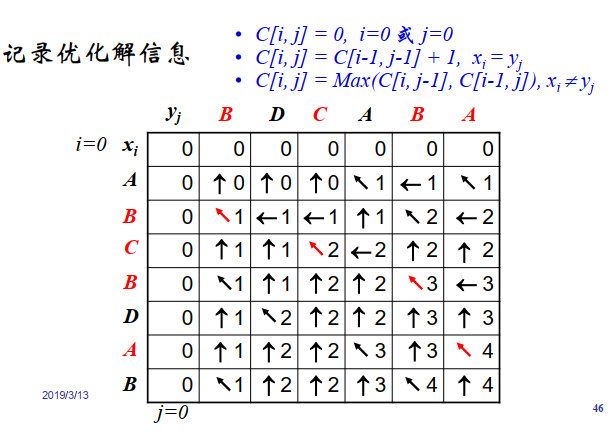
构造优化解:从B[m,n]开始按照指针搜索,若为斜向箭头,则是LCS的一部分,搜索到的结果为最终结果的Inverse。
该算法的时间复杂度为 O ( m n ) O(mn) O(mn)
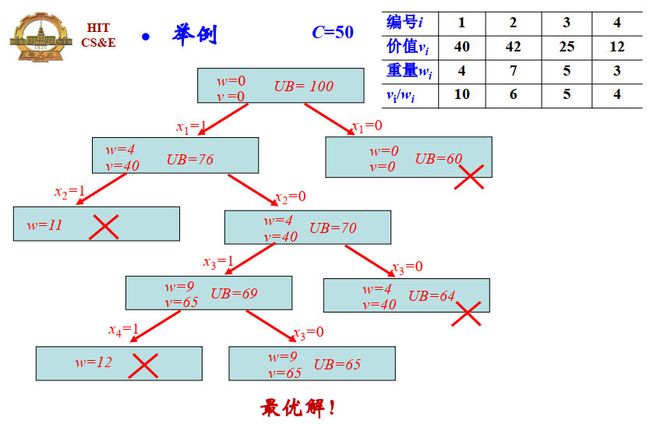
4.4 0-1背包问题
问题描述:给定n种物品和一个背包,物品i的重量是 w i w_i wi,价值 v i v_i vi, 背包承重为C, 问如何选择装入背包的物品,使装入背包中的物品的总价值最大?
原始方法:n个物品共 2 n 2^n 2n种方案,每个方案的计算代价为n,则总计算代价为 O ( n 2 n ) O(n2^n) O(n2n)。
子问题的重叠性:

每个分叉处都对应着某个物品装或不装,向右为不装,向左为装,大括号外为剩余的容量
定理:如果 S i = ( y i , y i + 1 , … , y n ) S_i=(y_i,y_{i+1},…,y_n) Si=(yi,yi+1,…,yn)是0-1背包问题的子问题 P i = [ { i , i + 1 , … , n } , C i = C − ∑ 1 ≤ k ≤ i − 1 w k y k ] P_i=[\{i,i+1,…,n\}, C_i=C-\sum_{1\le k\le i-1}w_ky_k] Pi=[{i,i+1,…,n},Ci=C−∑1≤k≤i−1wkyk]的优化解,则 ( y i + 1 , … , y n ) (y_{i+1},…,y_n) (yi+1,…,yn)是如下子问题 P i + 1 P_{i+1} Pi+1的优化解:
m a x ∑ i + 1 ≤ k ≤ n v k x k ∑ i + 1 ≤ k ≤ n w k x k ≤ C i − w i y i x k ∈ { 0 , 1 } , i + 1 ≤ k ≤ n max\sum_{i+1\le k\le n}v_kx_k\\\sum_{i+1\le k\le n}w_kx_k\le C_i-w_iy_i\\x_k\in\{0,1\},i+1\le k\le n maxi+1≤k≤n∑vkxki+1≤k≤n∑wkxk≤Ci−wiyixk∈{0,1},i+1≤k≤n
以上问题的最优解代价为: m ( i , j ) = ∑ i ≤ k ≤ n v k x k m(i,j)=\sum_{i\le k\le n}v_kx_k m(i,j)=∑i≤k≤nvkxk
递归求解:

4.5 最优二叉搜索树
第五章 贪心算法
5.1 贪心算法基本原理
期望使用局部最优以达到整体最优的效果,但是不一定能达到全局最优。
贪心算法产生优化解的条件:
- 优化子结构:一个优化问题的优化解包含它的剩余子问题的优化解
- Greedy选择性:一个优化问题的全局优化解可以通过局部优化选择得到

准确Greedy算法的设计步骤:
- 设计贪心选择方法
- 证明:对于1的贪心选择来说,所求解的问题具有优化子结构
- 证明:对于1的贪心选择来说,所求解的问题具有Greedy选择性
- 按照1设计算法
5.2 活动选择问题
问题描述:设S={1,2,…,n}是n个活动的集合,所有活动共享一个资源,该资源同时只能为一个活动使用。每个活动i有起始时间 s i s_i si, 终止时间 f i f_i fi, s i ≤ f i s_i\le f_i si≤fi。活动i和j是相容的, 若 s j ≥ f i 或 s i ≥ f j s_j\ge f_i或s_i\ge f_j sj≥fi或si≥fj。输入一系列活动和它们的起始结束时间,求最大相容活动的集合。
贪心思想:为了选择最多的相容活动, 每次选 f i f_i fi最小的活动, 使我们能够选更多的活动。
剩余子问题: S i = { j ∈ S ∣ s j ≥ f i } S_i=\{j\in S|s_j\ge f_i\} Si={j∈S∣sj≥fi}
优化解结构分析:
引理1:设 S = { 1 , 2 , … , n } S=\{1,2,…,n\} S={1,2,…,n}是n个活动集合, [ s i , f i ] [s_i,f_i] [si,fi]是活动i的起始终止时间,且 f 1 ≤ f 2 ≤ … ≤ f n f_1\le f_2\le…\le f_n f1≤f2≤…≤fn。则S的活动选择问题的某个优化解包括活动1。
引理2:设S={1, 2, …, n}是n个活动集合, [ s i , f i ] [s_i, f_i] [si,fi]是活动i的起始终止时间,且 f 1 ≤ f 2 ≤ … ≤ f n f_1\le f_2\le…\le f_n f1≤f2≤…≤fn, 设A是S的调度问题的一个优化解且包括活动1,则 A ′ = A − { 1 } 是 S ′ = { i ∈ S ∣ s i ≥ f 1 } A'=A-\{1\}是S'=\{i\in S|s_i\ge f_1\} A′=A−{1}是S′={i∈S∣si≥f1}的调度问题的优化解。(优化子结构)
引理3:设 S={1, 2, …., n}是 n 个活动集合, f 1 ≤ f 2 ≤ … ≤ f n f_1\le f_2\le…\le f_n f1≤f2≤…≤fn, f l 0 = 0 f_{l_0}=0 fl0=0, l i l_i li是 S i = { j ∈ S ∣ s j ≥ f l i − 1 } S_i=\{j\in S|s_j\ge f_{l_i-1}\} Si={j∈S∣sj≥fli−1}中具有最小结束时间 f l i f_{l_i} fli的活动。设A是S的包含活动1的优化解, 则 A = ∪ i = 1 k { l i } A=\cup_{i=1}^k\{l_i\} A=∪i=1k{li}。(Greedy选择性),如:

如果结束时间已经排序,那么 T ( n ) = θ ( n ) T(n)=\theta(n) T(n)=θ(n),否则为 T ( n ) = θ ( n l o g n ) T(n)=\theta(nlogn) T(n)=θ(nlogn)
5.3 哈夫曼编码
问题:编码树的代价:
设C是字母表(给定文件中的字母集合), ∀ c ∈ C \forall c\in C ∀c∈C,f©是c在文件中出现的频数, d T ( c ) d_T(c) dT(c)是叶子c在树T中的深度, 即c的编码长度,T的代价是编码一个文件的所有字符的代码长度。即
B ( T ) = ∑ c ∈ C f ( c ) d T ( c ) B(T)=\sum_{c\in C}f(c)d_T(c) B(T)=c∈C∑f(c)dT(c)
贪心思想:循环地选择具有最低频数F的两个结点,生成一棵子树,直至形成树(哈夫曼算法)。
剩余子问题的结构:
C ′ = ( C − { x , y } ) ∪ { z } F ′ = ( F − { f ( x ) , f ( y ) } ) ∪ { f ( z ) } , f ( z ) = f ( x ) + f ( y ) C'=(C-\{x,y\})\cup\{z\}\\F'=(F-\{f(x),f(y)\})\cup\{f(z)\},f(z)=f(x)+f(y) C′=(C−{x,y})∪{z}F′=(F−{f(x),f(y)})∪{f(z)},f(z)=f(x)+f(y)
引理(优化子结构):设T是字母表C的优化前缀树, ∀ c ∈ C \forall c\in C ∀c∈C, f©是c在文件中出现的频数.设x、 y是T中任意两个相邻叶结点, z是它们的父结点,则z作为频数是f(z)=f(x)+f(y)的字符, T’=T-{x,y}是字母表C’=C-{x,y}∪{z}的优化前缀编码树。
引理(Greedy选择性):设C是字母表, ∀ c ∈ C \forall c\in C ∀c∈C, c具有频数f©, x、 y是C中具有最小频数的两个字符, 则存在一个C的优化前缀树, x与y的编码具有相同最大长度, 且仅在最末一位不同.
哈夫曼算法的时间复杂度为:O(nlgn)
5.4 最小生成树问题
问题描述:边加权无向图,边加权和最小的连通图
Kruskal算法:
算法的思想:初始:A=空,构造森林 G A = ( V , A ) G_A=(V,A) GA=(V,A),选择连接 G A G_A GA中两棵树的具有最小权值的边加入A。
引理(Greedy选择性):设(u,v)是G中权值最小的边, 则必有一棵最小生成树包含边(u,v)。
引理(优化子结构):给定加权无向连通图G=(V,E),权值函数为 W:E → \rightarrow →R, ( u , v ) ∈ E (u,v)\in E (u,v)∈E是G中权值最小的边。设T是G的包含(u,v)的一棵最小生成树,则T/(u,v)是G/(u,v)的一棵最小生成树。
算法:

时间复杂度:设边的个数为n,则时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
Prim算法:
贪心策略:
- 以任意顶点vr作为树根,初始C={vr}
- 选择C和V-C之间权值最小的边(x,y), x ∈ C , y ∈ V − C x\in C, y\in V-C x∈C,y∈V−C
- C = C ∪ y C=C\cup{y} C=C∪y
引理(Greedy选择性):设(u,v)是G中与节点u相关联的权值最小的边, 则必有一棵最小生成树包含边(u,v)。
引理(优化子结构):给定加权无向连通图G=(V,E),权值函数为 W:E → \rightarrow →R, ( u , v ) ∈ E (u,v)\in E (u,v)∈E是G中权值最小的边。设T是G的包含(u,v)的一棵最小生成树,则T/(u,v)是G/(u,v)的一棵最小生成树。
算法:

第六章 树搜索
6.2 最优树搜索策略
爬山法:使用贪心方法确定搜索到方向,是优化的深度优先策略,使用启发式测度来排序节点扩展的顺序。
例如:8-Puzzle问题的启发式测度函数定义为 f ( n ) = W ( n ) f(n)=W(n) f(n)=W(n),其中 W ( n ) W(n) W(n)是节点n中处于错误位置的方块数。
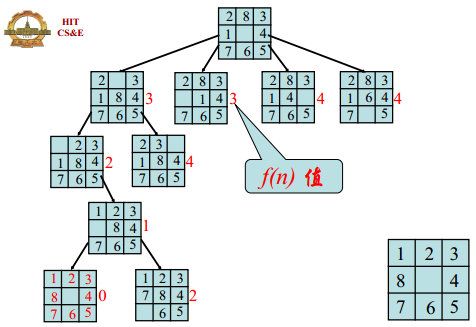
爬山法:
- 构造由根组成的单元素栈S;
- If Top(S)是目标节点 Then 停止;
- Pop(S);
- S的子节点按照其启发测度由大到小的顺序压入S;
- If S空 Then 失败 Else goto 2.
最佳优先搜索策略:
结合深度优先和广度优先,根据评价函数,在目前产生的所有节点中选择具有最小评价函数值的节点进行扩展,具有全局优化观念。

分支界限法:以上算法难以求解优化问题
分支界限法可以有效地求解组合优化问题,思想:
- 迅速找到一个可行解
- 将该可行解作为优化解的一个界限
- 利用界限裁剪
与爬山法和Best-First法相结合。
举例:
6.3 人员安排问题
问题描述:人的有序集合和工作的有序集合(人数与工作数相等),以及矩阵 [ C i j ] [C_{ij}] [Cij],其中 C i j C_{ij} Cij是 P i P_i Pi被分配工作 J i J_i Ji的代价。要使总代价最少。
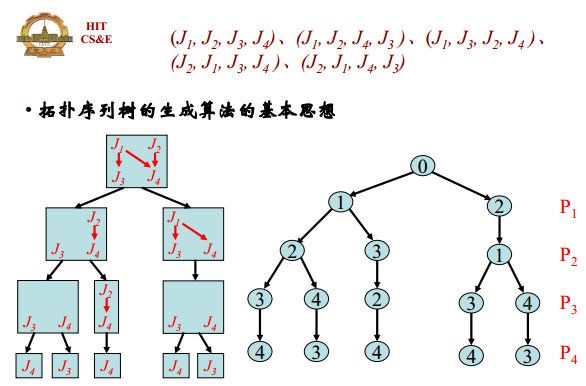
命题: P 1 → J k 1 P_1\rightarrow J_{k1} P1→Jk1、 P 2 → J k 2 P_2\rightarrow J_{k2} P2→Jk2、 …、 P n → J k n P_n\rightarrow J_{kn} Pn→Jkn是一个可能解, 当且仅当 J k 1 、 J k 2 、 … 、 J k n J_{k1}、J_{k2}、…、J_{kn} Jk1、Jk2、…、Jkn是一个拓扑排序的序列
问题的树表示(由偏序关系直接生成拓扑排序树):
逐渐删除没有入边(没有前序元素)的节点即可:
解空间的加权树表示:

将代价矩阵的每一行减掉最小值使其出现0,再将每一列减掉最小值使其出现0,所有的0即为具有最小代价的分配方案,若不可行,则其代价和为可行解的代价下界。

使用改进后的解空间求解。
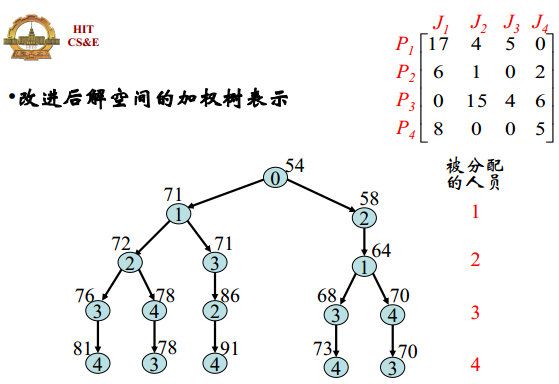
由于使用爬山法首先遍历右支,得到可行解的下界为70,于是左支可直接减掉。
即:一旦发现一个可能解, 将其代价作为界限, 循环地进行分支界限搜索: 剪掉不能导致优化解的子解, 使用爬山法继续扩展新增节点, 直至发现优化解。
6.4 旅行商问题
问题描述:无向连通图,非负加权边,寻找一条从任意节点开始,经过每个节点一次,最后返回开始节点的路径,且路径的代价(加权和)最小。
二叉树建立算法中可以应用策略:
- 发现优化解的上界 α \alpha α;
- 如果一个子节点的代价下界超过 α \alpha α,则终止该节点的扩展
待补充
6.5 0-1背包问题
转换为树搜索问题:
- 按照价值重量比降序排列n个物品
- 空包为根
- 用爬山法或Best-First递归地划分解空间,得到二叉树
- 树中第i层的每个节点都代表了n个物品中所有符合以下特征的子集
- 每个子集对应于序列中前i个物品的一个特定选择
- 这个特定选择是根据从根到该节点的一条路径确定的:向左的分支表示包含下一个物品,向右的分支表示不包含下一个物品
- 每个节点中记录如下信息:当前装入背包物品的总重量w及总价值v,此时背包能够容纳的物品价值上界UB
分支界限搜索算法:计算节点代价的上界UB: U B = v + ( C − ω ) × ( v i + 1 / ω i + 1 ) UB=v+(C-\omega)\times(v_{i+1}/\omega_{i+1}) UB=v+(C−ω)×(vi+1/ωi+1)或UB=v+UB’,UB’是部分背包算法在子问题({i+1, i+2,…,n}, C-w)上的最优解代价。
注意:0/1背包问题的优化解是部分背包问题的可行解,部分背包问题的优化解是0/1背包问题优化解上界。
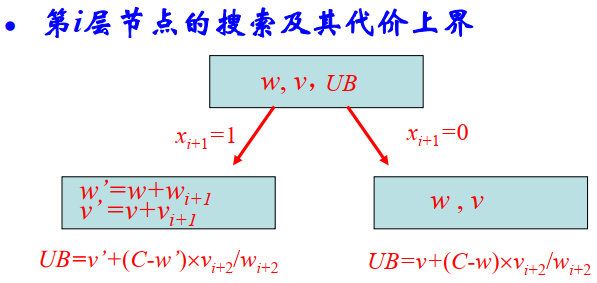
策略:

举例:
6.6 A*算法
基本思想:A*算法使用Best-First策略进行搜索,某些情况下,一旦得到了一个解,它一定是优化解,于是算法可以停止而无需搜索整个解空间。
关键:代价函数
对于任意节点n:g(n)=从树根到n的代价,h*(n)=从n到目标结点的优化路径代价,f*(n)=g(n)+h*(n)是经过结点n到达目标结点的代价。
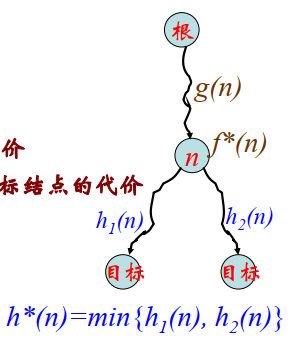
h*(n)未知,所以需要估计h*(n),保证以下即可:
- 使用任何方法去估计h*(n), 用h(n)表示h*(n)的估计
- h ( n ) ≤ h(n)\le h(n)≤h*(n)总为真
- f(n)=g(n)+h(n) ≤ \le ≤g(n)+h*(n)=f*(n)定义为n的代价
举例:最短路径问题

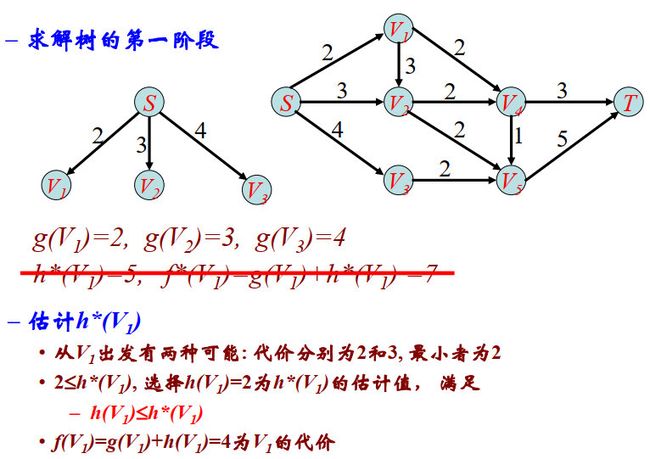
A*算法规则:
- 使用Best-first搜索策略
- 算法中代价函数f(n)定义为g(n)+h(n),g(n)是从根到n的路径代价, h(n)是h*(n)的估计值,且对于所有n, h(n) ≤ \le ≤h*(n)
- 当选择到的结点是目标结点时,算法停止,该目标结点即为优化解。
A*算法的正确性:使用Best-first策略搜索树,如果A*选择的结点是目标结点,则该结点表示的解是优化解
第七章 平摊分析
7.1 平摊分析的基本原理
关注一系列数据结构上操作的时间复杂度:考虑序列 O P 1 , O P 2 , … , O P m OP_1,OP_2,…,OP_m OP1,OP2,…,OPm,想确定这个操作序列可能花费的最长时间。然而OP之间相互关联,无法假设独立。
举例:普通栈操作:Push(S, x):将对象x压入栈S。Pop(S):弹出并返回S的顶端元素。可将每个操作的实际代价视为1,于是n个操作的实际运行代价为 θ ( n ) \theta(n) θ(n)。
Multipop(S, k):弹出S的k的栈顶对象,该操作的实际代价为 m i n ( ∣ S ∣ , k ) min(|S|,k) min(∣S∣,k)。
聚集方法(每个操作的代价):确定n个操作的上界 T ( n ) T(n) T(n),每个操作平摊T(n)/n
会计方法(整个操作序列的代价):不同类型操作赋予不同的平摊代价,某些操作在数据结构的特殊对象上"预付"代价
Potential方法(整个操作序列的代价):不同类型操作赋予不同的平摊代价,“预付"的代价作为整个数据结构的"能量”
7.2 聚集方法
举例分析:n个栈操作序列由Push、Pop和Multipop组成
一个对象在每次被压入栈后至多被弹出一次,在非空栈上调用Pop的次数(包括在Multipop内的调用)至多为Push执行的次数, 即至多为n,最坏情况下操作序列的代价为 T ( n ) ≤ 2 n = O ( n ) T(n)\le 2n=O(n) T(n)≤2n=O(n),于是平摊代价为 T ( n ) / n = O ( 1 ) T(n)/n=O(1) T(n)/n=O(1)
举例:二进制计数器
问题描述:由0开始计数的k位二进制计数器
算法为:


分析:A[0]每次操作发生一次改变,总次数为n;A[1]每两次操作发生一次改变,总次数为n/2;A[2]每四次操作发生一次改变,总次数为n/4。一般的,对于i=0, 1, …., lgn,A[i]改变的次数为 n / 2 i n/2^i n/2i,对于i>lgn,A[i]不发生改变。则n个操作的总代价为 O ( n ) O(n) O(n),每个操作的平摊代价为O(1)。
7.3 会计方法
为每种操作分配不同的平摊代价
举例:栈操作序列
Cost(PUSH)=2,一个1用来支付PUSH的开销,另一个1存储在压入栈的元素上,预支POP的开销
Cost(POP)=0,Cost(MULTIPOP)=0
平摊代价满足: ∑ 1 ≤ i ≤ n a i − ∑ i ≤ i ≤ n c i ≥ 0 \sum_{1\le i\le n}a_i-\sum_{i\le i\le n}c_i\ge 0 ∑1≤i≤nai−∑i≤i≤nci≥0对于任意的n个操作序列都成立,因为栈中对象数$\ge$0。
n个栈操作序列的总平摊代价为 O ( n ) O(n) O(n)
举例:二进制计数器
每次一位被置为1时,Cost=2,置为0的开销为0
于是n个Increment操作序列的总平摊代价为O(n)
7.4 Potential方法
目的是分析n个操作系列的复杂性上界,在会计方法中,如果操作的平摊代价比实际代价大,我们将余额与数据结构的数据对象相关联。Potential方法把Credit余额与整个数据结构关联,所有的这样的余额之和,构成数据结构的势能
如果操作的平摊代价大于操作的实际代价, 势能增加,如果操作的平摊代价小于操作的实际代价,要用数据结构的势能来支付实际代价, 势能减少。
通常定义 ϕ ( D 0 ) = 0 , ϕ ( D i ) ≥ 0 \phi(D_0)=0,\phi(D_i)\ge 0 ϕ(D0)=0,ϕ(Di)≥0
举例:栈的势能定义:
ϕ ( D m ) \phi(D_m) ϕ(Dm)定义为 D m D_m Dm中的对象的个数, c i c_i ci为操作i的实际代价
栈操作的平摊代价(设栈 D i − 1 D_{i-1} Di−1中有s个对象)
PUSH: a i = c i + ϕ ( D i ) − ϕ ( D i − 1 ) = 1 + ( s + 1 ) − s = 2 a_i=c_i+\phi(D_i)-\phi(D_{i-1})=1+(s+1)-s=2 ai=ci+ϕ(Di)−ϕ(Di−1)=1+(s+1)−s=2
POP: a i = c i + ϕ ( D i ) − ϕ ( D i − 1 ) = 1 + ( s − 1 ) − s = 0 a_i=c_i+\phi(D_i)-\phi(D_{i-1})=1+(s-1)-s=0 ai=ci+ϕ(Di)−ϕ(Di−1)=1+(s−1)−s=0
MULTIPOP(S, k):设k’=min(k, s),于是 a i = c i + ϕ ( D i ) − ϕ ( D i − 1 ) = k ′ + ( s − k ′ ) − s = k ′ − k ′ = 0 a_i=c_i+\phi(D_i)-\phi(D_{i-1})=k'+(s-k')-s=k'-k'=0 ai=ci+ϕ(Di)−ϕ(Di−1)=k′+(s−k′)−s=k′−k′=0
举例:计数器的势能定义
ϕ ( D m ) \phi(D_m) ϕ(Dm)定义为第m个操作后计数器中1的个数 b m b_m bm
INCREMENT操作的平摊代价:
第i个INCREMENT操作把 t i t_i ti个位置成0, 实际代价为 c i = t i + 1 c_i=t_i+1 ci=ti+1,计算操作i的平摊代价 a i = c i + ϕ ( D i ) − ϕ ( D i − 1 ) a_i=c_i+\phi(D_i)-\phi(D_{i-1}) ai=ci+ϕ(Di)−ϕ(Di−1)
若 b i = 0 b_i=0 bi=0,操作i把所有k位置0,所以 b i − 1 = k , t i = k b_{i-1}=k,t_i=k bi−1=k,ti=k;若 b i > 0 b_i>0 bi>0,则 b i = b i − 1 − t i + 1 b_i=b_{i-1}-t_i+1 bi=bi−1−ti+1;于是 b i ≤ b i − 1 − t i + 1 b_i\le b_{i-1}-t_i+1 bi≤bi−1−ti+1, ϕ ( D i ) − ϕ ( D i − 1 ) = b i − b i − 1 ≤ b i − 1 − t i + 1 − b i − 1 = 1 − t i \phi(D_i)-\phi(D_{i-1})=b_i-b_{i-1}\le b_{i-1}-t_i+1-b_{i-1}=1-t_i ϕ(Di)−ϕ(Di−1)=bi−bi−1≤bi−1−ti+1−bi−1=1−ti
平摊代价为 a i = c i + ϕ ( D i ) − ϕ ( D i − 1 ) ≤ ( t i + 1 ) + ( 1 − t i ) = 2 a_i=c_i+\phi(D_i)-\phi(D_{i-1})\le (t_i+1)+(1-t_i)=2 ai=ci+ϕ(Di)−ϕ(Di−1)≤(ti+1)+(1−ti)=2,n个操作的总平摊代价为O(n)
7.5 动态表性能平摊分析
动态表支持的操作:TABLE-INSERT:将某一元素插入表中;TABLE-DELETE:将一个元素从表中删除
数据结构:用一个(一组)数组来实现动态表,非空表T的装载因子 α ( T ) = T \alpha(T)=T α(T)=T存储的对象数/表的大小。
扩张算法:

插入一个数组元素时,完成的操作包括:
- 分配一个包含比原表更多的槽的新表
- 再将原表中的各项复制到新表中去
常用的启发式技术是分配一个比原表大一倍的新表
聚集分析:
第i次操作的代价 C i C_i Ci:如果 i = 2 m i=2^m i=2m, C i = i C_i=i Ci=i,否则 C i = 1 C_i=1 Ci=1
n次TABLE—INSERT操作的总代价为 ∑ i = 1 n c i ≤ n + ∑ j = 0 ∣ l g n ∣ 2 j < n + 2 n = 3 n \sum^n_{i=1}c_i\le n+\sum_{j=0}^{|lgn|}2^j
每一操作的平摊代价为3n/n=3
会计方法:
每次执行TABLE-INSERT平摊代价为3,1支付基本插入操作的实际代价,1作为自身存款,1存入表中第一个没有存款的数据上
当发生表的扩张时,数据的复制代价由数据上的存款来支付
初始为空的表上n次TABLE-INSERT操作的平摊代价总和为3n
势能法分析:
势能函数满足:刚扩充完, ϕ ( T ) = 0 \phi(T)=0 ϕ(T)=0,表满时, ϕ ( T ) = s i z e ( T ) \phi(T)=size(T) ϕ(T)=size(T)
于是定义势能函数 ϕ ( T ) = 2 ∗ n u m [ T ] − s i z e [ T ] \phi(T)=2*num[T]-size[T] ϕ(T)=2∗num[T]−size[T]
第i次操作的平摊代价,无论是否发生扩张, α i = 3 \alpha_i=3 αi=3
初始为空的表上n次插入操作的代价的上界为3n
动态表的收缩:
策略:表的装载因子小于1/2时,收缩表为原表的一半,操作平摊代价太高
改进策略:删除数据项引起表不足1/4满时,将表缩小为原表的一半,扩张和收缩过程都使得表的装载因子变为1/2
动态表上n次(插入、删除)操作的代价分析:
势能函数的定义:
- 当装载因子为1/2时,势为0
- 装载因子为1时,有num[T]=size[T],即 ϕ \phi ϕ(T)=num[T]。这样当因插入一项而引起一次扩张时,就可用势来支付其代价
- 当装载因子为1/4时, size[T]=4 ⋅ \cdot ⋅num[T]。即 ϕ \phi ϕ(T)=num[T]。因而当删除某项引起一次收缩时就可用势来支付其代价
于是,势能函数定义为:
Φ ( T ) = { 2 ⋅ n u m [ T ] − s i z e [ T ] α ( T ) ≥ 1 / 2 s i z e [ T ] / 2 − n u m [ T ] α ( T ) < 1 / 2 \Phi(T)=\begin{cases}2\cdot num[T]-size[T]&\alpha(T)\ge1/2\\size[T]/2-num[T]&\alpha(T)<1/2\end{cases} Φ(T)={2⋅num[T]−size[T]size[T]/2−num[T]α(T)≥1/2α(T)<1/2
第i次操作的平摊代价 a i = c i + ϕ ( T i ) − ϕ ( T i − 1 ) a_i=c_i+\phi(T_i)-\phi(T_i-1) ai=ci+ϕ(Ti)−ϕ(Ti−1)
- 第i次操作是TABLE—INSERT :未扩张, α i ≤ 3 \alpha_i\le 3 αi≤3
- 第i次操作是TABLE—INSERT :扩张, α i ≤ 3 \alpha_i\le 3 αi≤3
- 第i次操作是TABLE—DELETE :未收缩, α i ≤ 3 \alpha_i\le 3 αi≤3
- 第i次操作是TABLE—DELETE :收缩, α i ≤ 3 \alpha_i\le 3 αi≤3
动态表上n个操作的实际时间为O(n)
7.6 并查集性能平摊分析
目的:管理n个不相交的集合C={ S 1 , . . . , S n S_1,...,S_n S1,...,Sn},每个集合 S i S_i Si维护一个代表元素 x i x_i xi
支持的操作:
- MAKE-SET(x): 创建仅含元素x的集合
- UNION(x,y) : 合并代表元素分别x和y的集合
- FIND-SET(x) : 返回x所在集合的代表元素
目标:使得如下操作序列的代价尽可能低
- n个MAKE-SET 操作 (开始阶段执行)
- m个MAKE-SET, UNION, FIND-SET操作(后续)
- m ≥ n m\ge n m≥n,UNION操作至多执行 n-1次
并查集的直接实现为一个链表

并查集链表实现的性能分析:
-
开始阶段执行n个MAKE-SET 操作的总代价O(n)
-
后跟n-1个 UNION操作的总代价O( n 2 n_2 n2)
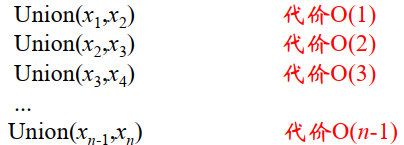
-
总共执行执行2n-1次操作的总代价为O( n 2 n_2 n2),从平摊效果看,每个操作的开销为O(n)
**改进:**每个链表表头记录集合(或)链表中元素的个数,Union操作时将较短链表链接到较长链表
在改进后的并查集上执行由Make_set, Find和Union操作构成的长度为m+n的操作序列(其中Make_Set操作有m个),则该操作序列的时间复杂度为O(m+nlogn)
并查集的森林实现:
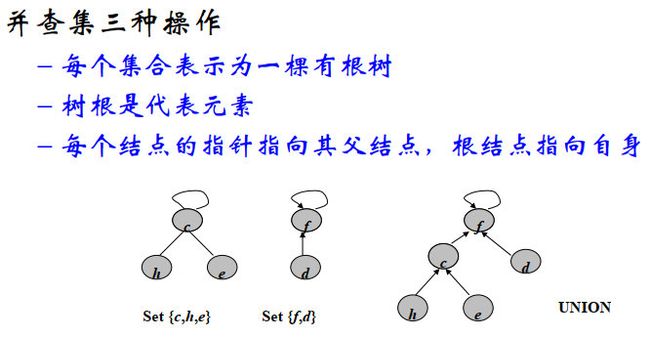
- MAKE-SET(x): 创建仅含元素x的一棵树,O(1)
- UNION(x,y) : 将x作为y的孩子,O(1)
- FIND(x) : 从结点x沿父指针访问直到树根,O( T x T_x Tx)
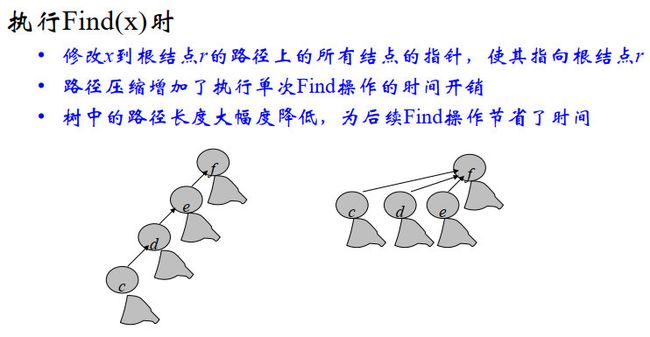
改进策略:路径压缩。
改进策略:按秩合并。
- MakeSet(x)操作执行时定义结点x的秩为0
- Find操作不改变任意顶点的秩
- Union(x,y) 分两种情况修改结点的秩
- rank(x)=rank(y)。此时,令x指向y且y是并集的代表元素, rank(y)增加1, rank(x)不变(其他结点的秩也保持不变)
- rank(x)
在并查集上执行m个操作的时间复杂度为O(m α \alpha α(n))
第八章 图算法
8.1 网络流算法
定义:一个源节点s、一个汇点t,由源节点流向汇点,流量守恒
流网络:无自环的有向图 G = ( V , E ) G=(V,E) G=(V,E)
流:设G(V,E)是一个流网络, c是容量函数, s源结点, t是汇点。G中的流是一个实值函数 f : V × V → R f:V\times V\rightarrow R f:V×V→R,满足以下性质:
-
流量约束: ∀ u , v ∈ V , 0 ≤ f ( u , v ) ≤ c ( u , v ) \forall u,v\in V,0\le f(u,v)\le c(u,v) ∀u,v∈V,0≤f(u,v)≤c(u,v)
-
流量守恒: ∀ u ∈ V − { s , t } \forall u\in V-\{s,t\} ∀u∈V−{s,t},有
∑ v ∈ V f ( v , u ) = ∑ v ∈ V f ( u , v ) \sum_{v\in V}f(v,u)=\sum_{v\in V}f(u,v) v∈V∑f(v,u)=v∈V∑f(u,v)
前提:单源单汇单向
最大流问题:求出一个流网络中具有最大流值的流
循环递进:初始时网络上的流为0,找出一条从s到t的路径p和正数a,使得p上的每一条边(u,v)的流量增加a之后仍能够满足容量约束: f ( u , v ) + a ≤ c ( u , v ) f(u,v)+a\le c(u,v) f(u,v)+a≤c(u,v),重复执行,直到找不到满足约束条件的路径
Ford-Fulkerson方法
在一个关联的剩余网络中寻找一条增广路径
剩余网络:给定流网络G(V,E)和一个流f,则由f诱导的G的剩余网络为 G f = ( V , E f ) G_f= (V, E_f) Gf=(V,Ef),其中 E f E_f Ef为
- 对于G中每条边 (u, v),若c(u,v)-f(u,v)>0,则 ( u , v ) ∈ E f (u, v)\in Ef (u,v)∈Ef ,且cf(u,v)=c(u,v)-f(u,v) (称 c f ( u , v ) c_f(u,v) cf(u,v)为剩余容量residual capacity)
- 对于G中每条边 (u, v),在 G f G_f Gf中构造边(v, u),且 c f ( v , u ) = f ( u , v ) c_f(v, u)= f(u,v) cf(v,u)=f(u,v)
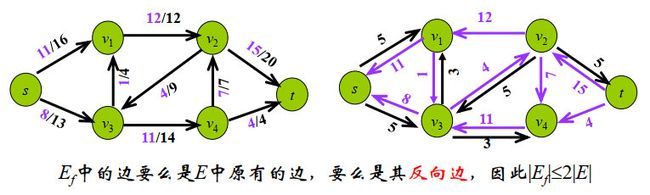
增广路径:剩余网络中的一条由源结点s到汇点t的一条路径p
增广路径p的剩余容量: c f ( p ) = m i n { c f ( u , v ) : ( u , v ) 属 于 路 径 p } c_f(p)=min\{c_f(u,v):(u,v)属于路径p\} cf(p)=min{cf(u,v):(u,v)属于路径p},表示了该路径能够增加的流的最大值
举例:

Ford-Fulkerson方法:在剩余网络中寻找增广路径
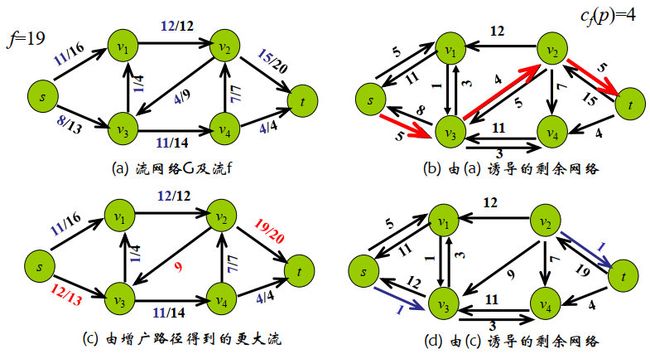
FF算法的核心是:通过增广路径不断增加路径上的流量,直到找到一个最大流为止
如何判断是否已经获得最大流
流网络的割:
给定流网络 G=(V,E),其源为s,汇为t,G的一个割(cut)是V的2-集合划分(S, T), T=V-S, 且 s ∈ S , t ∈ T s\in S, t\in T s∈S,t∈T,割的容量定义为 c ( S , T ) = ∑ u ∈ S , v ∈ T c ( u , v ) c(S,T)=\sum_{u\in S,v\in T}c(u,v) c(S,T)=∑u∈S,v∈Tc(u,v)

割的净流量为 ∣ f ∣ , f ( S , T ) = ∑ u ∈ S ∑ v ∈ T f ( u , v ) − ∑ u ∈ S ∑ v ∈ T f ( v , u ) |f|,f(S,T)=\sum_{u\in S}\sum_{v\in T}f(u,v)-\sum_{u\in S}\sum_{v\in T}f(v,u) ∣f∣,f(S,T)=∑u∈S∑v∈Tf(u,v)−∑u∈S∑v∈Tf(v,u)
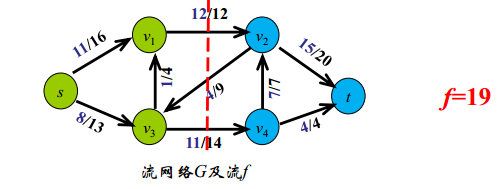
显然:流网络G中任意流的值不能超过G的任意割的容量
最小割:整个网络中容量最小的割
最大割最小割定理:
- f是G的最大流
- 剩余网络 G f G_f Gf不包含增强路径
- 对于G的某个划分(S, T), ∣ f ∣ = c ( S , T ) |f|=c(S,T) ∣f∣=c(S,T)
即,一个最大流的值实际上等于一个最小割的容量
Max-Min关系:对偶关系,最大流和最小割,最大匹配和最小覆盖
利用Max-Min关系求解最大流问题
- 初始化一个可行流 f f f,0-流:所有边的流量均等于0的流
- 不断将 f f f增大,直到 f f f不能继续增大
- 找出一个割(S, T)使得 ∣ f ∣ = c ( S , T ) |f|=c(S,T) ∣f∣=c(S,T)
Ford-Fulkerson算法

时间复杂度为O(|f*||E|)
如何加速增广路径的寻找
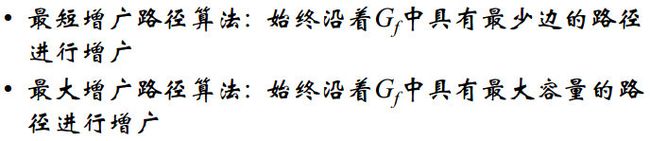
Edmonds-Karp算法
利用宽度优先在剩余网络 G f G_f Gf中寻找增广路径
- 从源结点s到汇点t的一条最短路径
- 每条边的权重为单位距离
- δ f ( u , v ) \delta_f(u, v) δf(u,v)=剩余网络 G f G_f Gf中从结点u到结点v的最短路径距离
Push-Relable方法:

第九章 字符串匹配算法
9.2 精确匹配算法
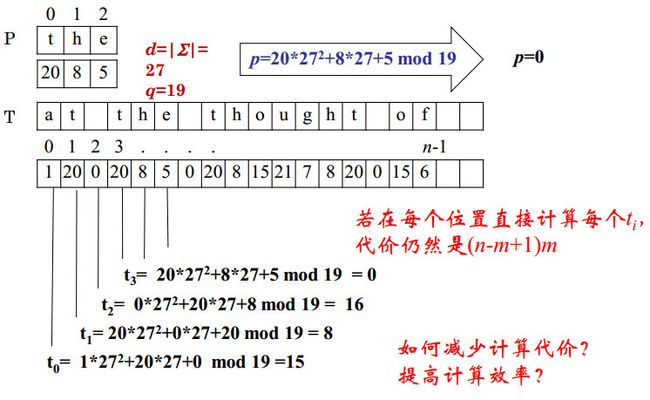
Rabin-Karp算法:
将字符串的比较转化成数的比较:两个数相对于第三个数模等价
即,若 a m o d q = b m o d q a\mod{q}=b\mod{q} amodq=bmodq,则a和b有可能相等
另 d = ∣ Σ ∣ d=|\Sigma| d=∣Σ∣,于是 Σ ∗ \Sigma^* Σ∗中的任意字符串x可以看作一个d进制数


有限自动机与字符串匹配:
- 有限自动机就是构建出一个满足某个特定模式的判断系统

Knuth-Morris-Pratt 算法:
即KMP算法
| P | a | b | a | b | a | c | a |
|---|---|---|---|---|---|---|---|
| q | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| π [ q ] \pi[q] π[q] | 0 | 0 | 1 | 2 | 3 | 0 | 1 |
Boyer-Moore 算法:
- 逆向搜索:从P的后面开始搜索
- 坏字符启发式规则
- 好后缀启发式规则
坏字符规则:
若 P [ j ] ≠ T [ i ] P[j]\not= T[i] P[j]=T[i]时,
- 如果坏字符T[i]没有出现在模式P中,则直接将模式串移动到坏字符的下一个字符
- 如果坏字符T[i]出现在模式P中,将P中位置j左面最近的x移到T(i)下面
好后缀:从后向前扫描遇到“ 坏字符” 前已经匹配的子串
给定P、T,T中字符t后面子串s匹配了P的一个后缀, 但是再往左一个字符就不匹配了。 寻找t’
- t’和t相同
- t’不是P的后缀
- t’左边的那个字符同与t匹配的P的后缀的左面那个字符不相同
将P向右移, 直到t’位于t的下面

若不存在t’, 则将P向右移动最少的步数, 使P的前缀同t右子串s的后缀相匹配(与KMP类似)
若这种情况也不存在, 则将P右移m步(与KMP类似)
Boyer-Moore-Horspool 算法:
仅考虑坏字符规则