基于匹配点集对单应性矩阵进行估计
前言
在立体视觉中,对单应性矩阵进行估计是一个很重要的任务,我们在之前的博文[1,2,3]中的讨论中都或多或少地涉及到了单应性矩阵,我们知道它是在投影变换中保持共线性的一种性质。在本文中,我们将讨论如何通过匹配点的关系,对单应性矩阵进行估计。如有谬误,请联系指出,转载请联系作者并注明出处,谢谢。
注:本文参考[7]的内容。
∇ \nabla ∇ 联系方式:
e-mail: [email protected]
QQ: 973926198
github: https://github.com/FesianXu
估计问题
估计(estimation)是什么?这个词我们在统计学中经常听到,估计指的是基于观测数据的基础上,对一个模型的参数进行估计,在立体视觉中,一般有以下几种估计问题:
- 2D 单应性(2D homography): 给定一系列点 x i ∈ P 2 \mathbf{x}_i \in \mathbb{P}^2 xi∈P2,并且给定其对应的匹配点 x i ′ ∈ P 2 \mathbf{x}_i^{\prime} \in \mathbb{P}^2 xi′∈P2,我们的估计的目标是根据这些对应点,估计出能够将 f : x i → x i ′ f:\mathbf{x}_i \rightarrow \mathbf{x}_i^{\prime} f:xi→xi′的投影变换。在实际中, x i \mathbf{x}_i xi和 x i ′ \mathbf{x}_i^{\prime} xi′通常是两张不同的图片上的对应/匹配点(match points),每个图片都可以看成是投影空间 P 2 \mathbb{P}^2 P2。在本路问题中,其实就是根据2D匹配点进行单应性矩阵 H ∈ R 3 × 3 H \in \mathbb{R}^{3 \times 3} H∈R3×3的估计。
- 3D到2D的相机投影(3D to 2D camera projection):给定在三维空间中的点 X i \mathbf{X}_i Xi,并且给定这些3D点在平面图像上的对应的2D点 x i \mathbf{x}_i xi。在这里的估计指的就是估计这里的3D到2D的投影变换 f : X i → x i f:\mathbf{X}_i \rightarrow \mathbf{x}_i f:Xi→xi,这里的投影通常是由投影相机模型得到的,参考[4]的讨论内容。
- 基础矩阵的计算(Fundamental matrix computation):给定在一张图像上的一系列点 x i \mathbf{x}_i xi和其在另一张图像上的对应点集 x i ′ \mathbf{x}_i^{\prime} xi′,计算根据这些对应关系计算出来的基础矩阵,我们在[5]中介绍过本征矩阵和基础矩阵,我们知道基础矩阵 F \mathcal{F} F是一个对所有的 i i i都满足 x i ′ T F x i = 0 {\mathbf{x}_i^{\prime}}^{\mathrm{T}} \mathcal{F} \mathbf{x}_i = 0 xi′TFxi=0的 3 × 3 3 \times 3 3×3的矩阵。
- 三焦张量计算(Trifocal tensor computation): 给定三张图片中的对应关系: x i ↔ x i ′ ↔ x i ′ ′ \mathbf{x}_i \leftrightarrow \mathbf{x}_i^{\prime} \leftrightarrow \mathbf{x}_i^{\prime\prime} xi↔xi′↔xi′′ ,计算其三焦张量(Trifocal tensor), 三焦张量对三张图像的对应点或者对应线进行了关系联系。
这些问题都是考虑到了“对应性”(correspondance),或者说是“匹配性”,然后对某种变换进行参数估计,因此这四个问题或多或少有着关联。在此,我们仅讨论第一种问题,其中提出的解法,能对其他三种问题的解决提供思路。
估计单应性矩阵
重申下问题:
我们考虑两个图像之间的匹配点集 x i ↔ x i ′ \mathbf{x}_i \leftrightarrow \mathbf{x}_i^{\prime} xi↔xi′,我们需要估计出单应性矩阵 H H H,使得对于所有的 i i i都有 x i ′ = H x i \mathbf{x}_i^{\prime} = H \mathbf{x}_i xi′=Hxi。
首先我们需要确定至少需要多少对匹配点集才足以确定一个单应性矩阵,我们知道单应性矩阵有9个元素,但是其可以进行尺度归一化[6],因此2D的单应性矩阵只有8个自由度(同理,3D的单应性矩阵为15的自由度)。每一对匹配点集提供了两个自由度的约束(也就是x和y),因此最少需要四对匹配点集才足以确定一个单应性矩阵。
自然地,给定了4对匹配点集(其中不能是三点共线的,我们后续讨论),我们可以确定一个单应性矩阵,这个是最小解。然而在实际中,我们通常能得到两张图片的很多对匹配点集,如Fig 1.1所示,而通常在这很多的匹配点集中,存在有误匹配的情况,这些误匹配称之为噪声(noise),通常我们会采用类似于RANSAC的鲁棒估计减少噪声的干扰(我们将在以后的博文中讨论RANSAC鲁棒估计)。除了鲁棒估计,我们也可以通过设置一个损失函数(cost function),尝试最小化损失函数,我们能找到一个最佳的单应性矩阵估计。一般来说,有两大类的损失函数:
- 基于代数损失的(algebraic error),也就是不考虑图像的几何上的因素,只考虑代数形式上的损失。
- 基于几何损失(geometric error)或统计上的图像距离的(statistical image distance),这种损失函数通常带有图像几何上的意义。

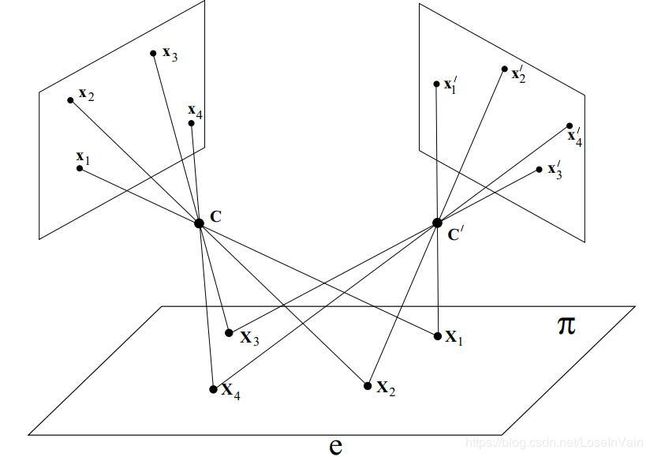
通常在对同一个平面上的点进行多视角摄像时,如Fig 1.2,图像中的像素点可以视为是投影变换的,可以用单应性矩阵对应,在进行弱透视摄像时[9],同样也可以这样认为。
DLT算法
我们首先考虑一个简单的线性算法。在给定了4对2D到2D的匹配点集时 x i ↔ x i ′ \mathbf{x}_i \leftrightarrow \mathbf{x}_i^{\prime} xi↔xi′,我们有 x i ′ = H x i \mathbf{x}_i^{\prime} = H\mathbf{x}_i xi′=Hxi (我们在齐次坐标系下进行处理[8])。因为我们在齐次坐标系下,因此严格上说 x i ′ \mathbf{x}_i^{\prime} xi′和 H x i H\mathbf{x}_i Hxi在尺度(scale)上并不相同,而是有着同样的方向。因此为了更加精确,我们可以把这个线性关系表示为:
x i ′ × H x i = 0 (1.1) \mathbf{x}_i^{\prime} \times H \mathbf{x}_i = 0 \tag{1.1} xi′×Hxi=0(1.1)
如果我们 H H H的第 j j j行表示为 h j T {\mathbf{h}^{j}}^{\mathrm{T}} hjT,那么我们有:
H x i = ( h 1 T x i h 2 T x i h 3 T x i ) (1.2) H\mathbf{x}_i = \left( \begin{matrix} {\mathbf{h}^1}^{\mathrm{T}}\mathbf{x}_i \\ {\mathbf{h}^2}^{\mathrm{T}}\mathbf{x}_i \\ {\mathbf{h}^3}^{\mathrm{T}}\mathbf{x}_i \end{matrix} \right) \tag{1.2} Hxi=⎝⎜⎛h1Txih2Txih3Txi⎠⎟⎞(1.2)
将 x i ′ = ( x i ′ , y i ′ , w i ′ ) T \mathbf{x}_i^{\prime} = (x^{\prime}_i,y^{\prime}_i,w^{\prime}_i)^{\mathrm{T}} xi′=(xi′,yi′,wi′)T,那么式子(1.1)可以写成:
x i ′ × H x i = ( y i ′ h 3 T x i − w i ′ h 2 T x i w i ′ h 1 T x i − x i ′ h 3 T x i x i ′ h 2 T x i − y i ′ h 1 T x i ) = 0 (1.3) \mathbf{x}_i^{\prime} \times H \mathbf{x}_i = \left( \begin{matrix} y^{\prime}_i {\mathbf{h}^3}^{\mathrm{T}}\mathbf{x}_i-w^{\prime}_i{\mathbf{h}^2}^{\mathrm{T}} \mathbf{x}_i \\ w^{\prime}_i {\mathbf{h}^1}^{\mathrm{T}}\mathbf{x}_i-x^{\prime}_i{\mathbf{h}^3}^{\mathrm{T}} \mathbf{x}_i \\ x^{\prime}_i {\mathbf{h}^2}^{\mathrm{T}}\mathbf{x}_i-y^{\prime}_i{\mathbf{h}^1}^{\mathrm{T}} \mathbf{x}_i \end{matrix} \right) = 0 \tag{1.3} xi′×Hxi=⎝⎜⎛yi′h3Txi−wi′h2Txiwi′h1Txi−xi′h3Txixi′h2Txi−yi′h1Txi⎠⎟⎞=0(1.3)
又因为有 h j T x i = x i T h j , j = 1 , ⋯ , 3 {\mathbf{h}^j}^{\mathrm{T}}\mathbf{x}_i = \mathbf{x}_i^{\mathrm{T}}\mathbf{h}^j, j=1,\cdots,3 hjTxi=xiThj,j=1,⋯,3,所以(1.3)可以写成:
[ 0 T − w i ′ x i T y i ′ x i T w i ′ x i T 0 T x i ′ x i T y i ′ x i T x i ′ x i T 0 T ] ( h 1 h 2 h 3 ) = A i h = 0 , A i ∈ R 3 × 9 (1.4) \left[ \begin{matrix} \mathbf{0}^{\mathrm{T}} & -w^{\prime}_i\mathbf{x}_i^{\mathrm{T}} & y^{\prime}_i\mathbf{x}_i^{\mathrm{T}} \\ w^{\prime}_i\mathbf{x}_i^{\mathrm{T}} & \mathbf{0}^{\mathrm{T}} & x^{\prime}_i\mathbf{x}_i^{\mathrm{T}} \\ y^{\prime}_i\mathbf{x}_i^{\mathrm{T}} & x^{\prime}_i\mathbf{x}_i^{\mathrm{T}} & \mathbf{0}^{\mathrm{T}} \end{matrix} \right] \left( \begin{matrix} \mathbf{h}^1 \\ \mathbf{h}^2 \\ \mathbf{h}^3 \end{matrix} \right) = \mathbf{A}_i \mathbf{h} = 0, \mathbf{A}_i \in \mathbf{R}^{3 \times 9} \tag{1.4} ⎣⎡0Twi′xiTyi′xiT−wi′xiT0Txi′xiTyi′xiTxi′xiT0T⎦⎤⎝⎛h1h2h3⎠⎞=Aih=0,Ai∈R3×9(1.4)
我们发现,对于未知量 h \mathbf{h} h而言,其是线性的,而且我们也可以发现这里的 A i \mathbf{A}_i Ai的秩为2,只有两个方程式是线性无关的,将 A i \mathbf{A}_i Ai的第 j j j行表示为 A i j \mathbf{A}_i^j Aij,我们有:
A i 3 = x i ′ A i 1 + y i ′ A i 2 (1.5) \mathbf{A}_i^3 = x^{\prime}_i\mathbf{A}^1_i+y^{\prime}_i\mathbf{A}_i^2 \tag{1.5} Ai3=xi′Ai1+yi′Ai2(1.5)
因此,我们可以将(1.4)去掉最后一行,得到
[ 0 T − w i ′ x i T y i ′ x i T w i ′ x i T 0 T x i ′ x i T ] ( h 1 h 2 h 3 ) = A i h = 0 (1.6) \left[\begin{matrix}\mathbf{0}^{\mathrm{T}} & -w^{\prime}_i\mathbf{x}_i^{\mathrm{T}} & y^{\prime}_i\mathbf{x}_i^{\mathrm{T}} \\w^{\prime}_i\mathbf{x}_i^{\mathrm{T}} & \mathbf{0}^{\mathrm{T}} & x^{\prime}_i\mathbf{x}_i^{\mathrm{T}} \end{matrix}\right]\left(\begin{matrix}\mathbf{h}^1 \\\mathbf{h}^2 \\\mathbf{h}^3 \end{matrix}\right) = \mathbf{A}_i \mathbf{h} = 0\tag{1.6} [0Twi′xiT−wi′xiT0Tyi′xiTxi′xiT]⎝⎛h1h2h3⎠⎞=Aih=0(1.6)
此时的 A i ∈ R 2 × 9 \mathbf{A}_i \in \mathbb{R}^{2 \times 9} Ai∈R2×9
又因为这个表示是在齐次坐标系下的,我们可以让 w i ′ = 1 w_i^{\prime} = 1 wi′=1。每一对匹配点都存在着一个如同(1.6)的等式约束,约束了两个自由度,因此在4对匹配点的情况下,我们的 A ∈ R 8 × 9 \mathbf{A} \in \mathbb{R}^{8 \times 9} A∈R8×9,当 r a n k ( A ) = 8 \mathrm{rank}(\mathbf{A}) = 8 rank(A)=8的时候,就存在非零解(平凡解)的 h \mathbf{h} h,这点我们在线性代数中已经学习过了,求出了 h \mathbf{h} h我们自然就知道了 H H H。特别的,我们的 H H H是和尺度有关的,任何尺度的 H H H都满足(1.1)的条件(除了0之外),因此我们通常对其进行一个限制,比如对范数进行归一化,如 ∣ ∣ h ∣ ∣ = 1 ||\mathbf{h}|| = 1 ∣∣h∣∣=1。
当给出超过4对匹配点的时候,我们处在超定方程(over-determined)的情况,此时可能没有一个解可以精确地满足所有点的匹配关系,因此我们设计一个损失函数,让损失函数最小以达到最佳的估计效果。因为我们知道 A h = 0 \mathbf{A}\mathbf{h} = 0 Ah=0是整个匹配点集的最优解,因此我们尝试最小化这个函数:
arg min h ∣ ∣ A h ∣ ∣ (1.7) \arg\min_{\mathbf{h}} || \mathbf{A}\mathbf{h} || \tag{1.7} arghmin∣∣Ah∣∣(1.7)
然而,我们还有个约束: ∣ ∣ h ∣ ∣ = 1 ||\mathbf{h}|| = 1 ∣∣h∣∣=1,因此整个问题等价于我们最小化:
arg min h = ∣ ∣ A h ∣ ∣ ∣ ∣ h ∣ ∣ (1.8) \arg\min_{\mathbf{h}} = \dfrac{||\mathbf{A}\mathbf{h}||}{||\mathbf{h}||} \tag{1.8} arghmin=∣∣h∣∣∣∣Ah∣∣(1.8)
(1.8)存在有解析解,其解是 A T A {\mathbf{A}}^{\mathrm{T}}\mathbf{A} ATA的最小的特征值所对应的单位特征向量,等价来说是 A \mathbf{A} A的奇异值分解中最小奇异值对应的奇异向量,首先我们对给定的 A \mathbf{A} A进行奇异值分解,有 A = U D V T \mathbf{A} = \mathbf{U}\mathbf{D}\mathbf{V}^{\mathrm{T}} A=UDVT,我们知道其中的 D \mathbf{D} D是一个对角矩阵,每个对角元都是一个奇异值,我们对这些奇异值进行降序排序,根据此更新特征向量 V T {\mathbf{V}}^{\mathrm{T}} VT的值排序,那么更新后的 V T {\mathbf{V}}^{\mathrm{T}} VT最后一列就是最小的奇异值对应的奇异向量,也就是我们要的解 h \mathbf{h} h。这个算法被称之为DLT,Direct Linear Transformation算法。
其他的损失函数
代数距离
代数距离(algebraic distance),我们在(1.7)中尝试去最小化的 ∣ ∣ A h ∣ ∣ ||\mathbf{A}\mathbf{h}|| ∣∣Ah∣∣,我们把 ϵ = A h \mathbf{\epsilon} = \mathbf{A}\mathbf{h} ϵ=Ah称之为残留向量(residual vector),并且定义代数距离为:
d a l g ( x i ′ , H x i ) 2 = ∣ ∣ ϵ i ∣ ∣ 2 = ∣ ∣ [ 0 T − w i ′ x i T y i ′ x i T w i ′ x i T 0 T x i ′ x i T ] h ∣ ∣ 2 (1.8) d_{\mathrm{alg}}(\mathbf{x}^{\prime}_i, H\mathbf{x}_i)^2 = ||\epsilon_i||^2 = || \left[ \begin{matrix} \mathbf{0}^{\mathrm{T}} & -w^{\prime}_i\mathbf{x}_i^{\mathrm{T}} & y^{\prime}_i\mathbf{x}_i^{\mathrm{T}} \\ w^{\prime}_i\mathbf{x}_i^{\mathrm{T}} & \mathbf{0}^{\mathrm{T}} & x^{\prime}_i\mathbf{x}_i^{\mathrm{T}} \end{matrix} \right] \mathbf{h} ||^2 \tag{1.8} dalg(xi′,Hxi)2=∣∣ϵi∣∣2=∣∣[0Twi′xiT−wi′xiT0Tyi′xiTxi′xiT]h∣∣2(1.8)
我们发现,每一对的匹配点都对应着一个代数距离,这个代数距离没有任何几何上或者统计上的意义,只是一个数值而已。具体点,我们有:
d a l g ( x 1 , x 2 ) 2 = a 1 2 + a 2 2 , 其 中 a = ( a 1 , a 2 , a 3 ) = x 1 × x 2 (1.9) d_{\mathrm{alg}} (\mathbf{x}_1, \mathbf{x}_2)^2 = a_1^2+a_2^2, 其中\mathbf{a} = (a_1, a_2, a_3)=\mathbf{x_1}\times \mathbf{x}_2 \tag{1.9} dalg(x1,x2)2=a12+a22,其中a=(a1,a2,a3)=x1×x2(1.9)
考虑到所有的匹配点集,我们对其求和有:
∑ i d a l g ( x i ′ , H x i ) 2 = ∑ i ∣ ∣ ϵ i ∣ ∣ 2 = ∣ ∣ A h ∣ ∣ 2 = ∣ ∣ ϵ ∣ ∣ 2 (1.10) \sum_id_{\mathrm{alg}}(\mathbf{x}^{\prime}_i, H\mathbf{x}_i)^2 = \sum_i ||\epsilon_i||^2= ||\mathbf{A}\mathbf{h}||^2 = ||\epsilon||^2 \tag{1.10} i∑dalg(xi′,Hxi)2=i∑∣∣ϵi∣∣2=∣∣Ah∣∣2=∣∣ϵ∣∣2(1.10)
代数距离没有几何含义,并且最小化代数距离通常给出的解并不够好,但是其有个很好的性质就是其是线性的,因此有唯一的一个解,并且计算起来很容易,可以作为其他更为复杂的非线性几何损失的初始化条件。
几何距离
在讨论几何距离之前,我们要明晰三种不同的概念:
- x \mathbf{x} x表示在图像上的实际测量坐标结果,比如某个像素点的坐标位置。因为存在某些成像上的误差,可能实际成像和理论应该的成像位置不一致的情况,当然理论的成像位置我们并不知道,我们能测量出的一般只是 x \mathbf{x} x。
- x ^ \hat{\mathbf{x}} x^表示某个模型对该点的估计值。
- x ˉ \mathbf{\bar{x}} xˉ表示实际实体点的理论真实值,这个通常不能被直接测量出来。
在一张图像上的误差,迁移误差:
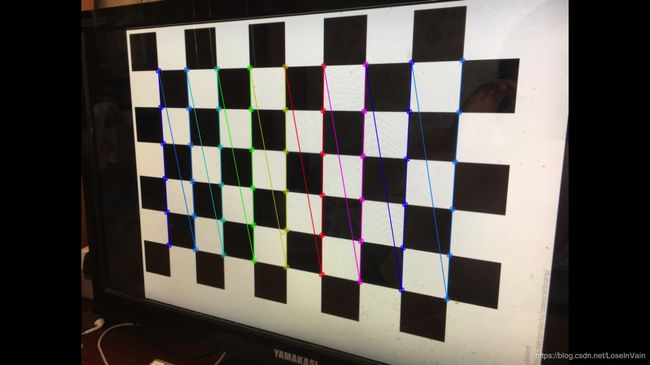
如果我们假设在第一张图像上,其测量到的点不存在误差,也就是说假设第一张图上有 x = x ˉ \mathbf{x} = \mathbf{\bar {x}} x=xˉ,那么我们只需要考虑第二张图像的误差即可。一般情况下,这种情况当然不现实,这个我们在上文讨论过,因为成像误差,实际的成像位置和真正理论上的成像位置有所偏移。但是我们这个假设在某些情况下是可以接受的,比如我们现在对相机进行矫正(calibration,也即是计算相机的内参数和外参数[11]),我们会使用一种称之为矫正图样(calibration pattern)的标定板,如Fig 1.3所示,在这种标定板上交叠着黑白色的方块,其交叠点清晰,模式明显,如Fig 1.4所示。因此可以认为这些交叠的角点的成像位置和理论成像位置一致,因此我们这个假设就有用武之地了。注意,在这个情况中,我们的一个平面是标定板,一个平面是相机的成像平面,我们在试图寻找标定板角点到相机成像平面的单应性矩阵。

考虑到这种假设合理的情况,我们设计出所谓的最小化 迁移误差(transfer error),公式表示如(1.11)所示
E t r a n s f e r = ∑ i d ( x i ′ , H x ˉ i ) 2 (1.11) \mathcal{E}_{\mathrm{transfer}} = \sum_{i} \mathrm{d}(\mathbf{x}^{\prime}_i, H\mathbf{\bar{x}}_i)^2\tag{1.11} Etransfer=i∑d(xi′,Hxˉi)2(1.11)
注意到其中的 d ( ⋅ ) \mathrm{d}(\cdot) d(⋅)是欧几里德距离。这个公式其实就是在描述如果在知道了单应性矩阵 H H H的情况下,将第一张图像的像点通过单应性矩阵投影到第二张图像上后得到投影点 H x ˉ i H\mathbf{\bar{x}}_i Hxˉi,计算实际的成像点 x i ′ \mathbf{x}^{\prime}_i xi′与之的欧式距离。
注意,这里的欧式距离 d ( x , y ) \mathrm{d}(\mathbf{x}, \mathbf{y}) d(x,y)其中是对 x , y \mathbf{x}, \mathbf{y} x,y中的非齐次坐标进行计算的,也就是说如果 x = { x 1 , x 2 , x 3 } , y = { y 1 , y 2 , y 3 } \mathbf{x} = \{x_1, x_2, x_3\}, \mathbf{y} = \{y_1,y_2,y_3\} x={x1,x2,x3},y={y1,y2,y3},其中 x 3 , y 3 x_3,y_3 x3,y3是齐次分量,不参与欧式距离计算,因此实际的欧式距离为:
d ( x , y ) 2 = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 (1.12) \mathrm{d}(\mathbf{x}, \mathbf{y})^2 = (x_1-x_2)^2+(y_1-y_2)^2\tag{1.12} d(x,y)2=(x1−x2)2+(y1−y2)2(1.12)
总而言之,最后有:
H ^ = arg min H E t r a n s f e r (1.13) \hat{H} = \arg\min_{H} \mathcal{E}_{\mathrm{transfer}}\tag{1.13} H^=argHminEtransfer(1.13)
对称迁移误差:
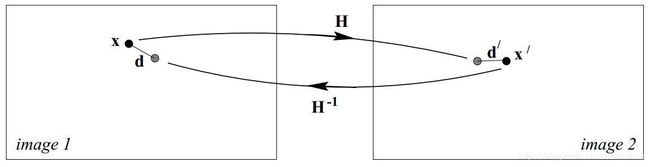
然而更为通用且实际的方法,是考虑所谓的对称迁移,也就是将第一张图像上的像点投射到第二张图像,计算误差 E 1 \mathcal{E}_1 E1;相反地,将第二张图像上的像点投影到第一张图像,计算误差 E 2 \mathcal{E}_2 E2,相加两个误差得到最后的对称迁移误差 E = E 1 + E 2 \mathcal{E} = \mathcal{E}_1+\mathcal{E}_2 E=E1+E2。公式表达如(1.14)
E = ∑ i d ( x i , H − 1 x i ′ ) 2 + d ( x i ′ , H x i ) 2 (1.14) \mathcal{E} = \sum_{i} \mathrm{d}(\mathbf{x}_i, H^{-1}\mathbf{x}^{\prime}_i)^2+ \mathrm{d}(\mathbf{x}^{\prime}_i,H\mathbf{x}_i)^2\tag{1.14} E=i∑d(xi,H−1xi′)2+d(xi′,Hxi)2(1.14)
最后的优化结果如:
H ^ = arg min H E (1.15) \hat{H} = \arg \min_{H} \mathcal{E}\tag{1.15} H^=argHminE(1.15)
整个过程的图示如Fig 1.5所示。
重投影误差:
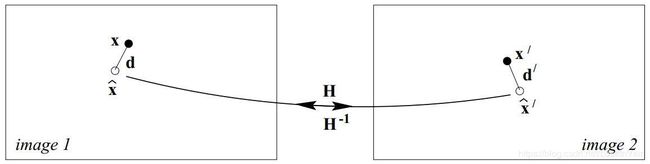
我们从式子(1.14)和Fig 1.5中发现,其实我们的投影点和实际点并不是完全匹配的,因为我们的观察点都是带噪声的,并不是实际理论上的完美的点,因此即便通过单应性矩阵它们也不会完全的重合。我们可以考虑一种这种情况,假设我们通过匹配点集 x i ↔ x i ′ \mathbf{x}_i \leftrightarrow \mathbf{x}^{\prime}_i xi↔xi′,我们能推算出其在现实中的实际实体点 X i \mathbf{X}_i Xi,然后通过投影,可以得到完美的一个匹配对 x ^ i ↔ x ^ i ′ \mathbf{\hat{x}}_i \leftrightarrow \mathbf{\hat{x}}_i^{\prime} x^i↔x^i′,其中有 x ^ i ′ = H x ^ i \mathbf{\hat{x}}_i^{\prime} = H\mathbf{\hat{x}}_i x^i′=Hx^i。当然这里的实体点并不需要显式地进行估计,我们只需要如式子(1.16)所示地设计误差函数即可:
E = ∑ i d ( x i , x ^ i ) 2 + d ( x i ′ , x ^ i ′ ) 2 s . t . x ^ i ′ = H ^ x ^ i , ∀ i (1.16) \mathcal{E} = \sum_i\mathrm{d}(\mathbf{x}_i, \mathbf{\hat{x}}_i)^2+\mathrm{d}(\mathbf{x}_i^{\prime},\mathbf{\hat{x}}_i^{\prime})^2 \\s.t. \ \ \mathbf{\hat{x}}_i^{\prime} = \hat{H}\mathbf{\hat{x}}_i, \forall i\tag{1.16} E=i∑d(xi,x^i)2+d(xi′,x^i′)2s.t. x^i′=H^x^i,∀i(1.16)
最小化误差,有:
H ^ = arg min H E (1.17) \hat{H} = \arg \min_{H} \mathcal{E}\tag{1.17} H^=argHminE(1.17)
因为这个过程需要重新投影,得到一个新的估计的辅助匹配对,因此称之为重投影误差(reprojection error)。整个过程如图Fig 1.6所示。对比Fig 1.5和Fig 1.6,我们能发现,我们在重投影过程中,是充分考虑了每张图的像素点的位置误差的。
Reference
[1]. https://blog.csdn.net/LoseInVain/article/details/104533575
[2]. https://blog.csdn.net/LoseInVain/article/details/102739778
[3]. https://blog.csdn.net/LoseInVain/article/details/103369203
[4]. https://blog.csdn.net/LoseInVain/article/details/102632940
[5]. https://blog.csdn.net/LoseInVain/article/details/102665911
[6]. https://blog.csdn.net/LoseInVain/article/details/104533575
[7]. Hartley R, Zisserman A. Multiple view geometry in computer vision[M]. Cambridge university press, 2003.
[8]. https://blog.csdn.net/LoseInVain/article/details/102756630
[9]. https://blog.csdn.net/LoseInVain/article/details/102883243
[10]. https://blog.csdn.net/LoseInVain/article/details/102739778
[11]. https://blog.csdn.net/LoseInVain/article/details/102632940