多线程(三)偏向锁,轻量级锁,重量级锁,自旋锁,线程池的实现
多线程(三)偏向锁,轻量级锁,重量级锁,自旋锁,线程池的实现
- 一、偏向锁
- 1.1 、java对象在内存中的存储结构主要有以下三部分
- 1.2、java虚拟机的对象头里主要包含两部分信息
- 1.3、偏向锁
- 1.4、轻量级锁
- 1.5 、自旋锁
- 1.6、重量级锁
- 二、一个线程连续调用两次start()会出现什么?
- 三、线程池的实现
- 3.1、各个参数的含义
- 3.2、ThreadPoolExecutor的继承关系
- 3.3、ThreadPoolExecutor的状态变量
- 3.4、任务的执行:execute()方法
- 四、常用的四种线程池
- 4.1、newFixedThreadPool
- 4.2、newCachedThreadPool
- 4.3、newSingleThreadExecutor
- 4.4、newScheduledThreadPool
一、偏向锁
1.1 、java对象在内存中的存储结构主要有以下三部分
1.对象头(主要是一些运行时的数据) 2.实例数据 3.对齐填充
1.2、java虚拟机的对象头里主要包含两部分信息
| 长度 | 内容 | 说明 |
|---|---|---|
| 32/64bit | Mark Word | 用于存储自身运行时数据,如hashCode,GC分代年龄,锁状态标志,线程持有的锁,偏向线程ID,偏向时间戳等。 |
| 32/64bit | Class Meta Address | 指向对象类型数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。 |
| 32/64bit | Array Length | 数组的长度(当对象为数据时) |
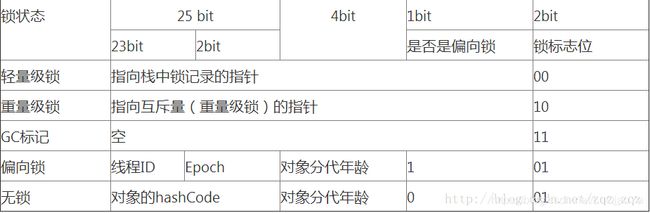
MarkWord这部分数据的长度在32位和64位的虚拟机中分别为32bit和64bit,
32bit空间的25bit用于存储对象哈希码,4bit用于存储对象分代年龄,2bit用于存储锁标志位,1bit固定为0.
32位虚拟机在不同状态下markword的结构如下图。
1.3、偏向锁
大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得的代价更低而引入偏向锁。
如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会消除它身上的偏向锁,将锁恢复到标准的轻量级锁。
如果有两个线程来竞争锁的话,此时锁就会膨胀,偏向锁就被升级为轻量级锁,这也是常说的锁膨胀。
偏向锁的获取过程:
- 1.访问Markword中偏向锁的标识是否设置成1,锁标志位是否为01,确认为可偏向状态。
- 2.如果为可偏向状态,则测试线程ID是否指向当前线程,如果是,则进入步骤5,否则进入步骤3
- 3.如果线程ID并未指向当前线程,则通过CAS操作竞争锁。如果竞争成功,则将Markword中线程ID设置为当前线程ID,然后执行5,如果竞争失败,执行4
- 4.如果CAS获取偏向锁失败,则表示有竞争。当到达全局安全点时获取偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码。
- 5.执行同步代码。
锁撤销的过程:
- 1.在一个安全点停止拥有锁的线程,(撤销偏向锁会导致stop the word操作,导致性能下降)
- 2.遍历线程栈,如果存在锁记录的话,需要修复锁记录和Markword,使其变成无锁状态。
- 3.唤醒当前线程,将当前锁升级为轻量级锁。
由于锁撤销花销挺大,所以,如果某些同步代码块大多数情况下都是有两个或者两个以上的线程来竞争的话,那么偏向锁就是一种累赘,我们可以一开始就把偏向锁关掉。
1.4、轻量级锁
轻量级锁的加锁过程:
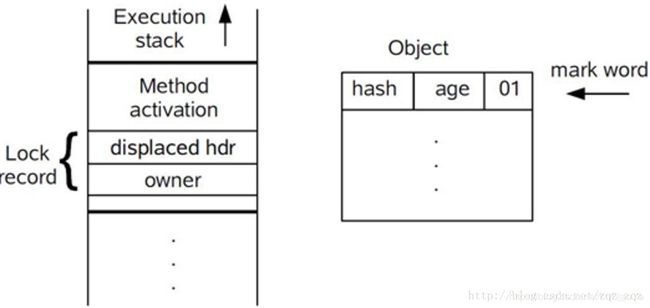
- 1.在代码进入同步块的时候,如果同步对象锁为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先在当前线程的线帧中建立一个名为锁记录(Lock Record)
的空间,用于存储锁对象目前的Markword的拷贝,官方称之为Displaced Mark Word。这个时候线程堆栈与对象头的状态如图所示:
- 2.拷贝对象头中的Markword复制到锁记录中
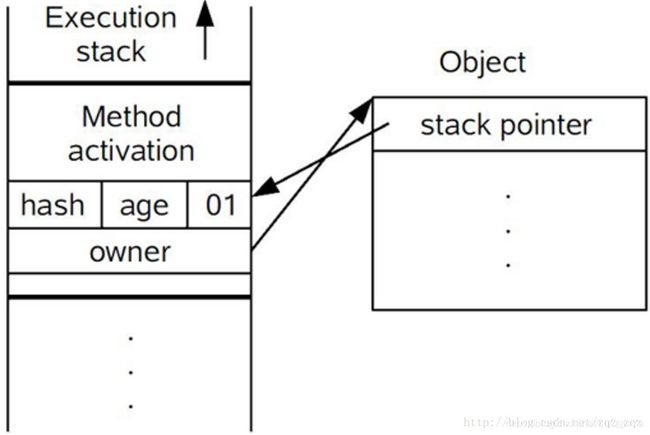
- 3.拷贝成功后,虚拟机将使用CAS操作尝试将对象的Markword更新为指向Lock Record的指针,并将Lock Record中的owner指针指向object Mark word。如果更新成功则
执行步骤4,否则执行5 - 4.如果这个更新成功了,那么这个线程就拥有了这个对象的锁,并且对象Markword的标志位设置为“00”,即表示此对象处于轻量级锁定状态,这时候线程堆栈与对象头的状态如图所示:
- 5.如果这个更新失败了,虚拟机首先会检查对象的Mark word是否指向当前线程的线帧,如果是说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。
轻量级锁的释放:
由轻量级锁切换到重量锁,是发生在轻量锁释放锁的期间,之前在获取锁的时候它拷贝了锁对象头的Markword,在释放锁的时候如果它发现它持有锁的期间有其他线程来
尝试获取锁了,并且该线程对Markword做了修改,两者对比发现不一致,则切换到重量锁。
1.5 、自旋锁
轻量级锁有两种:
1.自旋锁 2.自适应自旋锁
自旋锁:指当另一个线程来竞争时,这个线程会在原地等待,而不是把该线程给阻塞,直到那个获得锁的线程释放锁之后,这个线程就可以马上获得锁。
但是,锁在原地循环的时候,是会消耗CPU的,相当于一个什么也不做的for循环。所以,轻量级锁适用于那些同步代码块执行的很快的场景,这样,线程在原地等待较短的时间就可以获取锁了。
由于线程在原地空转是消耗CPU的,我们可以给空循环设置一个次数,当线程超过了这个次数,我们就认为,继续自旋不合适了,此时锁会继续膨胀,升级为重量级锁。
默认情况下,自旋的次数为10次,用户可以通过-XX:PreBlockSpin来进行更改
自适应自旋锁:
自适应自旋锁就是线程自旋次数不是固定的,而是根据实际情况来改变自旋等待的时间。
大概原理:
假如线程1刚刚获得了锁,释放之后,线程2获得了锁,但是线程2在运行的过程中,线程1又想获取锁,但是线程2还没有释放,所以线程1只能自旋等待,但是虚拟机认为由于线程1
刚刚获得过锁,所以线程1这次获得锁的几率还是很大的,所以会延长线程1的自旋次数。
1.6、重量级锁
重量级锁是依赖对象内部的monitor对象来实现的,而monitor又依赖操作系统的MutexLock(互斥锁)来实现的,所以重量级锁也被称为互斥锁。
为什么说重量级锁开销大呢?
当系统检查到锁是重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗CPU,
但是阻塞或者唤醒一个线程时,都需要操作系统帮忙,这就需要从用户态转换到内核态,
而转换状态是需要消耗很多时间的,有可能比用户执行代码的时间还要长。
参考网址:https://www.cnblogs.com/lzh-blogs/p/7477157.html
二、一个线程连续调用两次start()会出现什么?
// start 方法源码
public synchronized void start() {
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}
private native void start0();
会抛出IllegalThreadStateException异常,由于start0()方法的实现已经封装在dll中了,但是肯定是在start0方法中修改了线程状态值threadStatus,如果再次进入,就会抛异常。
三、线程池的实现
如果我们每次使用一个线程就去创建一个线程,使用起来非常方便,但是频繁创建线程会大大降低系统效率,因为创建和销毁线程都需要时间。在java中,我们可以通过线程池来实现线程的复用。ThreadPoolExecutor是线程池中最核心的一个类。
// 构造方法1
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
// 构造方法2
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
// 构造方法3
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
// 构造方法4
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor一共有4个构造方法,但是从代码可以看出来,前三个构造方法都是调用最后一个构造方法进行的初始化工作。
3.1、各个参数的含义
corePoolSize:核心池的大小。
在创建了线程池之后,默认情况下,线程池中并没有任何线程,而是等待有任务来了才去创建线程。除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,这两个方法是预先创建线程的,即在没有任务来临之前,就先创建了corePoolSize个线程或者一个线程。但是默认情况下,线程池的线程数为0,当有任务到来时,才创建线程执行任务,当线程池中的数量达到了corePoolSize的时候,就把接下来的线程放入缓存队列。
maximumPoolSize:线程池最大线程数。它表示线程池中最多能创建多少线程。
keepAliveTime:表示线程没有任务执行时最多保持多长时间会终止。默认情况下,只有线程池的线程数量大于corePoolSize的时候,keepAliveTime才会起作用,如果一个线程的空闲时间达到了keepAliveTime,则会终止,直到线程数不大于corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,就算线程池中的线程数不大于corePoolSize,keepAliveTime参数也会起作用。
unit:keepAliveTime的时间单位。有7种取值。
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒
workQueue:一个阻塞队列,用来存储等待执行的任务。一般来说,这个参数有以下几种选择。
- ArrayBlockingQueue:是一个基于数组的有序阻塞队列,此队列按照FIFO(先进先出)原则对元素进行排列。
- LinkedBlockingQueue:一个基于链表的有序阻塞队列,此队列按照FIFO(先进先出)排序,吞吐量通常要高于ArrayBlockingQueue。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态。吞吐量要高于LinkedBlockingQueue。
threadFactory:线程工厂。主要用来创建线程
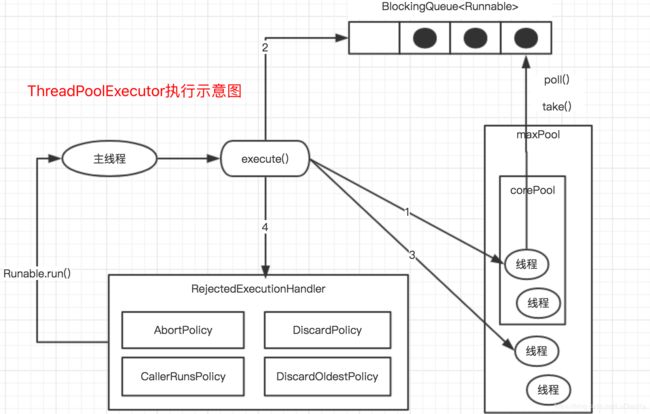
handler:表示拒绝处理任务时的策略,当运行线程数已经到达maximumPoolSize时,队列也已经装满时,会调用该参数值拒绝任务。默认情况是AbortPolicy。
有以下四种取值:
AbortPolicy:直接抛出异常。
CallerRunsPolicy:只用调用者所在线程来执行任务。
DiscardOldestPolicy:丢弃队列中最近的一个任务,并执行当前任务。
DiscardPolicy:不处理,丢弃掉。
3.2、ThreadPoolExecutor的继承关系
public class ThreadPoolExecutor extends AbstractExecutorService { … }
public abstract class AbstractExecutorService implements ExecutorService { … }
public interface ExecutorService extends Executor { … }
public interface Executor { … }
3.3、ThreadPoolExecutor的状态变量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
其中ctl是ThreadPoolExecutor的状态变量。
workerCountOf():方法取得当前线程池的线程数量,算法是将ctl的值取低29位。
runStateOf():方法取得线程池的状态,算法是将ctl的值取高3位。
RUNNING 111:表示正在运行
SHUTDOWN 000:表示拒绝接收新的任务。
STOP 001:表示拒绝接收新的任务,并且不再处理任务队列中剩余的任务,还要中断正在执行的任务
TIDYING 010:表示所有线程已经停止,准备执行terminated()方法。
TERMINATED 011:表示已经执行完terminated()方法。
3.4、任务的执行:execute()方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
// 第一种情况
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 第二种情况
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 第三种情况
else if (!addWorker(command, false))
reject(command);
}
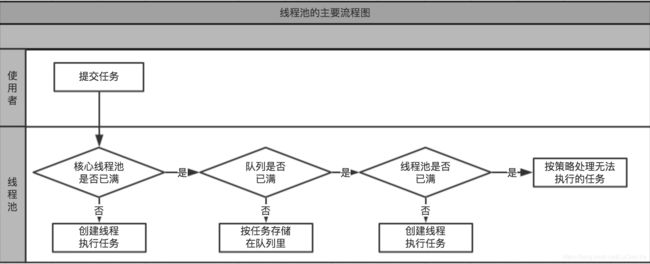
以上三种情况分别对应以下:
1.线程池的线程数量小于corePoolSize核心线程任务数量,开启核心线程执行任务。
2.线程池的线程数量不小于corePoolSize核心线程数量,或者开启核心线程失败,尝试将线程以非阻塞的方式添加到任务队列。
3.任务队列已满导致添加任务失败,开启新的非核心线程任务。
四、常用的四种线程池
4.1、newFixedThreadPool
一个固定线程数量的线程池。可控制线程最大并发数,超出的线程会在队列中等待。
public static ExecutorService newFixedThreadPool(int nThreads) {
// corePoolSize和maximumPoolSize大小一样,同时传入一个无界阻塞队列,
// 该线程池的线程数会维持在指定线程数,不会进行回收(根据worker逻辑分析)
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
4.2、newCachedThreadPool
不固定线程数量,且支持最大为Integer.MAX_VALUE的线程数量。
public static ExecutorService newCachedThreadPool() {
// corePoolSize为0,maximumPoolSize为Integer.MAX_VALUE
// 就是说来一个任务就创建一个worker,回收时间是60s
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可缓存线程池:
1.线程数无限制
2.有空闲线程则复用空闲线程,没有就创建新线程
3.一定程度减少频繁创建/销毁线程,减少系统开销
4.3、newSingleThreadExecutor
可以理解为线程数为1的FixedThreadPool。
public static ExecutorService newSingleThreadExecutor() {
// corePoolSize和maximumPoolSize大小都为1,
// 线程池中只有一个线程在运行,其他的都放入阻塞队列。
// 外面包装的FinalizableDelegatedExecutorService类实现了finalize方法,
// 在JVM垃圾回收的时候会关闭线程池。
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
单线程化的线程池:
1.有且只有一个工作线程执行任务
2.所有任务按照指定顺序执行,遵循队列的先入先出
4.4、newScheduledThreadPool
支持定时以指定周期循环执行任务。前三种线程池是ThreadPoolExecutor不同配置的实例,最后一种是ScheduledThreadPoolExecutor的实例。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
转载自:https://blog.csdn.net/u010983881/article/details/79322499