think-in-java(17)容器深入研究
注意: 17章接着 11章继续分析 java容器, think-in-java(11)
【17.1】完整的容器分类方法
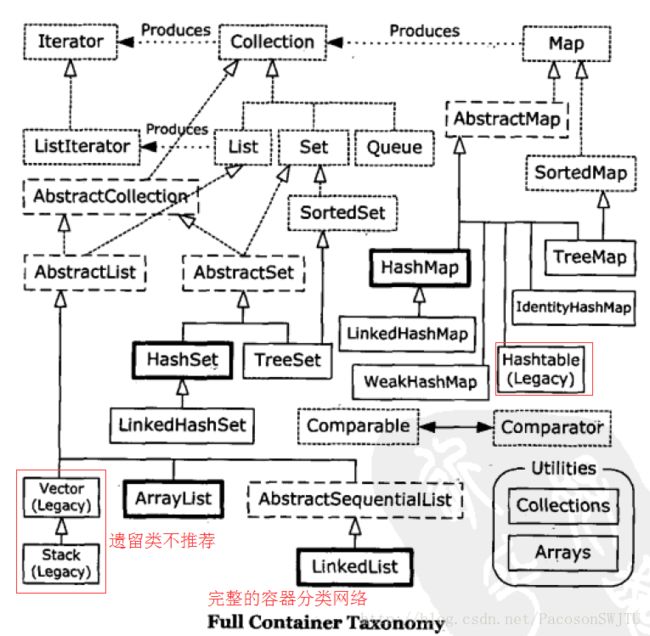
【容器分类网络解说】
1)接口:虚线框,没有实线入边(没有实体类继承关系,只有接口继承关系);
2)抽象类:虚线框,有实现入边(有实体类继承关系);SortedSet 除外,SortedSet 明显是一个接口, TreeSet 实现了 NavigableSet 接口,而 NavigableSet 接口继承了 SortedSet 接口(来自java 8 版本);
3)实体类:其他的都是继承关系;
4)常用实体类: 加粗实线框;
5)Collections 和 Arrays 是工具类;
java 5 添加了新特性:
1)Queue接口(队列可以通过 LinkedList来实现了,当然包括 Stack栈数据结构)机器实现 PriorityQueue 和 BlockingQueue阻塞队列(21章 java 多线程编程介绍);
2)ConcurrentMap 接口 和 实现类 CurrentHashMap,也在21章;
3)CopyOnWriteArrayList 和 CopyOnWriteArraySet, 也是多线程的内容;
4)EnumSet 和 EnumMap,为使用 enum 而设计的 Set 和 Map的特殊实现;
5)Collections类中添加了多个 便利的工具方法;
【17.2】填充容器
1)用单个对象引用来填充 Collection:通过 Collections.nCopies() 方法 添加, 而通过 Collections.fill() 来替换添加;
class StringAddress {
private String s;
public StringAddress(String s) {
this.s = s;
}
public String toString() {
return super.toString() + " " + s;
}
}
public class FillingLists {
public static void main(String[] args) {
/* 构建4个StringAddress对象,并封装到List ,操作的都是同一个对象 */
List list = new ArrayList(
Collections.nCopies(4, new StringAddress("Hello")));
System.out.println(list);
/* 把 新对象StringAddress引用 填充到list中 ,操作的都是同一个对象 */
/* Collections.fill() 方法只能替换 list中已经存在的元素,不能添加新元素 */
Collections.fill(list, new StringAddress("World!"));
System.out.println(list);
}
}
// 打印结果(List使用的都是同一个对象引用):
[chapter17.StringAddress@15db9742 Hello, chapter17.StringAddress@15db9742 Hello, chapter17.StringAddress@15db9742 Hello, chapter17.StringAddress@15db9742 Hello]
[chapter17.StringAddress@6d06d69c World!, chapter17.StringAddress@6d06d69c World!, chapter17.StringAddress@6d06d69c World!, chapter17.StringAddress@6d06d69c World!]
【17.2.1】一种 Generator 解决方案
1)所有Collection的子容器都有接受另一个 Collection 对象的构造器,用所接受的 Collection对象中的元素来填充新容器;
【荔枝】通过适配器模式模拟 将 Collection容器对象作为输入参数传入 另一个 Collection的构造方法
class Government implements Generator {
String[] foundation = ("strange women lying in ponds "
+ "distributing swords is no basis for a system of " + "government")
.split(" ");
private int index;
public String next() {
return foundation[index++];
}
}
public class CollectionDataTest {
public static void main(String[] args) {
/* ArrayList容器作为参数传入 LinkedHashSet 构造器(这个适配器代码很经典的) */
Set set = new LinkedHashSet(new CollectionData(
new Government(), 15));
// Using the convenience method:
set.addAll(CollectionData.list(new Government(), 15));
System.out.println(set);
}
} /*
public class CollectionData extends ArrayList {
// Generator类
public CollectionData(Generator gen, int quantity) {
for (int i = 0; i < quantity; i++)
add(gen.next());
}
// A generic convenience method:
public static CollectionData list(Generator gen, int quantity) {
return new CollectionData(gen, quantity);
}
}
// 打印结果:
[strange, women, lying, in, ponds, distributing, swords, is, no, basis, for, a, system, of, government]
public interface Generator { T next(); } ///:~
【CollectionData 应用的荔枝】
public class CollectionDataGeneration {
public static void main(String[] args) {
/* Convenience method */
System.out.println(new ArrayList(CollectionData.list(new RandomGenerator.String(9), 10)));
System.out.println(new HashSet(new CollectionData(new RandomGenerator.Integer(), 10)));
}
} // 打印结果
[YNzbrnyGc, FOWZnTcQr, GseGZMmJM, RoEsuEcUO, neOEdLsmw, HLGEahKcx, rEqUCBbkI, naMesbtWH, kjUrUkZPg, wsqPzDyCy]
[2017, 8037, 871, 7882, 6090, 4779, 299, 573, 4367, 3455]【17.2.2】Map 生成器
【荔枝】将 Generator适配到 Map的构造器中;
// 键值对类
public class Pair {
public final K key;
public final V value;
public Pair(K k, V v) {
key = k;
value = v;
}
}
public class MapData extends LinkedHashMap {
// A single Pair Generator:
public MapData(Generator> gen, int quantity) { // 使用一个 generator 构建 map
for (int i = 0; i < quantity; i++) {
Pair p = gen.next();
put(p.key, p.value);
}
}
// Two separate Generators:
public MapData(Generator genK, Generator genV, int quantity) { // 使用两个 generator 构建map
for (int i = 0; i < quantity; i++) {
put(genK.next(), genV.next());
}
}
// A key Generator and a single value:
public MapData(Generator genK, V value, int quantity) { // 使用一个 泛型为key的generator,但值都相同的方法构建 map。
for (int i = 0; i < quantity; i++) {
put(genK.next(), value);
}
}
// An Iterable and a value Generator:
public MapData(Iterable genK, Generator genV) { // 使用 Iterable 和 一个 generator 构建map
for (K key : genK) {
put(key, genV.next());
}
}
// An Iterable and a single value:
public MapData(Iterable genK, V value) { // 使用一个 泛型为 key的Iterable 但值都相同的 方式构建map
for (K key : genK) {
put(key, value);
}
}
// Generic convenience methods:(泛型简单方法,调用以上的构造方法)
public static MapData map(Generator> gen,
int quantity) {
return new MapData(gen, quantity);
}
public static MapData map(Generator genK,
Generator genV, int quantity) {
return new MapData(genK, genV, quantity);
}
public static MapData map(Generator genK, V value,
int quantity) {
return new MapData(genK, value, quantity);
}
public static MapData map(Iterable genK, Generator genV) {
return new MapData(genK, genV);
}
public static MapData map(Iterable genK, V value) {
return new MapData(genK, value);
}
} 【荔枝】调用MapData构建 Map的荔枝
class Letters implements Generator>, Iterable {
private int size = 9;
private int number = 1;
private char letter = 'A';
public Pair next() {
return new Pair(number++, "" + letter++);
}
public Iterator iterator() {
return new Iterator() {
public Integer next() {
return number++;
}
public boolean hasNext() {
return number < size;
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
}
public class MapDataTest {
public static void main(String[] args) {
/* 以下构造方式看懂一个即可。非常经典的使用 一个容器 构造另一个容器的方法,调用过程非常经典 */
// Pair Generator:
print(MapData.map(new Letters(), 11));
// Two separate generators:
print(MapData.map(new CountingGenerator.Character(), new RandomGenerator.String(3), 8));
// A key Generator and a single value:
print(MapData.map(new CountingGenerator.Character(), "Value", 6));
// An Iterable and a value Generator:
print(MapData.map(new Letters(), new RandomGenerator.String(3)));
// An Iterable and a single value:
print(MapData.map(new Letters(), "Pop"));
}
}
// 打印结果:
{1=A, 2=B, 3=C, 4=D, 5=E, 6=F, 7=G, 8=H, 9=I, 10=J, 11=K}
{a=YNz, b=brn, c=yGc, d=FOW, e=ZnT, f=cQr, g=Gse, h=GZM}
{a=Value, b=Value, c=Value, d=Value, e=Value, f=Value}
{1=mJM, 2=RoE, 3=suE, 4=cUO, 5=neO, 6=EdL, 7=smw, 8=HLG}
{1=Pop, 2=Pop, 3=Pop, 4=Pop, 5=Pop, 6=Pop, 7=Pop, 8=Pop}【补充】 可以使用工具来创建 任何用于 Map 或 Collection 的生成数据集,然后通过 构造器 或 Map.putAll() 和 Collection.putAll() 来初始化 Map 和Collection;
【总结】Collection的一个项存储一个值,而map 的一个项存储一个键值对;以上是 把 generator 适配到 Collection 和 map 的构造过程的方式,非常经典的调用,果然厉害;
【17.2.3】使用 Abstract: 显然, 各种容器对应 的 Abstract类 是 继承了 容器基类接口,实现基类接口的一部分方法或全部方法,然后实体类容器 再来继承 Abstract类,这样实体类容器无需实现 容器接口的全部方法。如AbstractCollection, AbstractSet, AbstractList, AbstractMap 等容器抽象类;
【荔枝】创建定制的Map 和 Collection
public class Countries {
/* 二维数组 */
public static final String[][] DATA = {
// Africa
{ "ALGERIA", "Algiers" },
{ "ANGOLA", "Luanda" },
{ "BENIN", "Porto-Novo" },
{ "BOTSWANA", "Gaberone" },
{ "BURKINA FASO", "Ouagadougou" },
{ "BURUNDI", "Bujumbura" },
{ "CAMEROON", "Yaounde" },
{ "CAPE VERDE", "Praia" },
{ "CENTRAL AFRICAN REPUBLIC", "Bangui" },
{ "CHAD", "N'djamena" },
{ "COMOROS", "Moroni" },
{ "CONGO", "Brazzaville" },
{ "DJIBOUTI", "Dijibouti" },
{ "EGYPT", "Cairo" },
{ "EQUATORIAL GUINEA", "Malabo" },
{ "ERITREA", "Asmara" },
{ "ETHIOPIA", "Addis Ababa" },
{ "GABON", "Libreville" },
{ "THE GAMBIA", "Banjul" },
{ "GHANA", "Accra" },
{ "GUINEA", "Conakry" },
{ "BISSAU", "Bissau" },
{ "COTE D'IVOIR (IVORY COAST)", "Yamoussoukro" },
{ "KENYA", "Nairobi" },
{ "LESOTHO", "Maseru" },
{ "LIBERIA", "Monrovia" },
{ "LIBYA", "Tripoli" },
{ "MADAGASCAR", "Antananarivo" },
{ "MALAWI", "Lilongwe" },
{ "MALI", "Bamako" },
{ "MAURITANIA", "Nouakchott" },
{ "MAURITIUS", "Port Louis" },
{ "MOROCCO", "Rabat" },
{ "MOZAMBIQUE", "Maputo" },
{ "NAMIBIA", "Windhoek" },
{ "NIGER", "Niamey" },
{ "NIGERIA", "Abuja" },
{ "RWANDA", "Kigali" },
{ "SAO TOME E PRINCIPE", "Sao Tome" },
{ "SENEGAL", "Dakar" },
{ "SEYCHELLES", "Victoria" },
{ "SIERRA LEONE", "Freetown" },
{ "SOMALIA", "Mogadishu" },
{ "SOUTH AFRICA", "Pretoria/Cape Town" },
{ "SUDAN", "Khartoum" },
{ "SWAZILAND", "Mbabane" },
{ "TANZANIA", "Dodoma" },
{ "TOGO", "Lome" },
{ "TUNISIA", "Tunis" },
{ "UGANDA", "Kampala" },
{ "DEMOCRATIC REPUBLIC OF THE CONGO (ZAIRE)", "Kinshasa" },
{ "ZAMBIA", "Lusaka" },
{ "ZIMBABWE", "Harare" },
// Asia
{ "AFGHANISTAN", "Kabul" },
{ "BAHRAIN", "Manama" },
{ "BANGLADESH", "Dhaka" },
{ "BHUTAN", "Thimphu" },
{ "BRUNEI", "Bandar Seri Begawan" },
{ "CAMBODIA", "Phnom Penh" },
{ "CHINA", "Beijing" },
{ "CYPRUS", "Nicosia" },
{ "INDIA", "New Delhi" },
{ "INDONESIA", "Jakarta" },
{ "IRAN", "Tehran" },
{ "IRAQ", "Baghdad" },
{ "ISRAEL", "Jerusalem" },
{ "JAPAN", "Tokyo" },
{ "JORDAN", "Amman" },
{ "KUWAIT", "Kuwait City" },
{ "LAOS", "Vientiane" },
{ "LEBANON", "Beirut" },
{ "MALAYSIA", "Kuala Lumpur" },
{ "THE MALDIVES", "Male" },
{ "MONGOLIA", "Ulan Bator" },
{ "MYANMAR (BURMA)", "Rangoon" },
{ "NEPAL", "Katmandu" },
{ "NORTH KOREA", "P'yongyang" },
{ "OMAN", "Muscat" },
{ "PAKISTAN", "Islamabad" },
{ "PHILIPPINES", "Manila" },
{ "QATAR", "Doha" },
{ "SAUDI ARABIA", "Riyadh" },
{ "SINGAPORE", "Singapore" },
{ "SOUTH KOREA", "Seoul" },
{ "SRI LANKA", "Colombo" },
{ "SYRIA", "Damascus" },
{ "TAIWAN (REPUBLIC OF CHINA)", "Taipei" },
{ "THAILAND", "Bangkok" },
{ "TURKEY", "Ankara" },
{ "UNITED ARAB EMIRATES", "Abu Dhabi" },
{ "VIETNAM", "Hanoi" },
{ "YEMEN", "Sana'a" },
// Australia and Oceania
{ "AUSTRALIA", "Canberra" },
{ "FIJI", "Suva" },
{ "KIRIBATI", "Bairiki" },
{ "MARSHALL ISLANDS", "Dalap-Uliga-Darrit" },
{ "MICRONESIA", "Palikir" },
{ "NAURU", "Yaren" },
{ "NEW ZEALAND", "Wellington" },
{ "PALAU", "Koror" },
{ "PAPUA NEW GUINEA", "Port Moresby" },
{ "SOLOMON ISLANDS", "Honaira" },
{ "TONGA", "Nuku'alofa" },
{ "TUVALU", "Fongafale" },
{ "VANUATU", "< Port-Vila" },
{ "WESTERN SAMOA", "Apia" },
// Eastern Europe and former USSR
{ "ARMENIA", "Yerevan" },
{ "AZERBAIJAN", "Baku" },
{ "BELARUS (BYELORUSSIA)", "Minsk" },
{ "BULGARIA", "Sofia" },
{ "GEORGIA", "Tbilisi" },
{ "KAZAKSTAN", "Almaty" },
{ "KYRGYZSTAN", "Alma-Ata" },
{ "MOLDOVA", "Chisinau" },
{ "RUSSIA", "Moscow" },
{ "TAJIKISTAN", "Dushanbe" },
{ "TURKMENISTAN", "Ashkabad" },
{ "UKRAINE", "Kyiv" },
{ "UZBEKISTAN", "Tashkent" },
// Europe
{ "ALBANIA", "Tirana" }, { "ANDORRA", "Andorra la Vella" },
{ "AUSTRIA", "Vienna" }, { "BELGIUM", "Brussels" },
{ "BOSNIA", "-" },
{ "HERZEGOVINA", "Sarajevo" },
{ "CROATIA", "Zagreb" },
{ "CZECH REPUBLIC", "Prague" },
{ "DENMARK", "Copenhagen" },
{ "ESTONIA", "Tallinn" },
{ "FINLAND", "Helsinki" },
{ "FRANCE", "Paris" },
{ "GERMANY", "Berlin" },
{ "GREECE", "Athens" },
{ "HUNGARY", "Budapest" },
{ "ICELAND", "Reykjavik" },
{ "IRELAND", "Dublin" },
{ "ITALY", "Rome" },
{ "LATVIA", "Riga" },
{ "LIECHTENSTEIN", "Vaduz" },
{ "LITHUANIA", "Vilnius" },
{ "LUXEMBOURG", "Luxembourg" },
{ "MACEDONIA", "Skopje" },
{ "MALTA", "Valletta" },
{ "MONACO", "Monaco" },
{ "MONTENEGRO", "Podgorica" },
{ "THE NETHERLANDS", "Amsterdam" },
{ "NORWAY", "Oslo" },
{ "POLAND", "Warsaw" },
{ "PORTUGAL", "Lisbon" },
{ "ROMANIA", "Bucharest" },
{ "SAN MARINO", "San Marino" },
{ "SERBIA", "Belgrade" },
{ "SLOVAKIA", "Bratislava" },
{ "SLOVENIA", "Ljuijana" },
{ "SPAIN", "Madrid" },
{ "SWEDEN", "Stockholm" },
{ "SWITZERLAND", "Berne" },
{ "UNITED KINGDOM", "London" },
{ "VATICAN CITY", "---" },
// North and Central America
{ "ANTIGUA AND BARBUDA", "Saint John's" }, { "BAHAMAS", "Nassau" },
{ "BARBADOS", "Bridgetown" }, { "BELIZE", "Belmopan" },
{ "CANADA", "Ottawa" }, { "COSTA RICA", "San Jose" },
{ "CUBA", "Havana" }, { "DOMINICA", "Roseau" },
{ "DOMINICAN REPUBLIC", "Santo Domingo" },
{ "EL SALVADOR", "San Salvador" },
{ "GRENADA", "Saint George's" },
{ "GUATEMALA", "Guatemala City" },
{ "HAITI", "Port-au-Prince" },
{ "HONDURAS", "Tegucigalpa" },
{ "JAMAICA", "Kingston" },
{ "MEXICO", "Mexico City" },
{ "NICARAGUA", "Managua" },
{ "PANAMA", "Panama City" },
{ "ST. KITTS", "-" },
{ "NEVIS", "Basseterre" },
{ "ST. LUCIA", "Castries" },
{ "ST. VINCENT AND THE GRENADINES", "Kingstown" },
{ "UNITED STATES OF AMERICA", "Washington, D.C." },
// South America
{ "ARGENTINA", "Buenos Aires" },
{ "BOLIVIA", "Sucre (legal)/La Paz(administrative)" },
{ "BRAZIL", "Brasilia" }, { "CHILE", "Santiago" },
{ "COLOMBIA", "Bogota" }, { "ECUADOR", "Quito" },
{ "GUYANA", "Georgetown" }, { "PARAGUAY", "Asuncion" },
{ "PERU", "Lima" }, { "SURINAME", "Paramaribo" },
{ "TRINIDAD AND TOBAGO", "Port of Spain" },
{ "URUGUAY", "Montevideo" }, { "VENEZUELA", "Caracas" }, };
// Use AbstractMap by implementing entrySet(): 实现 entrySet()方法来 应用 AbstractMap 抽象类
private static class FlyweightMap extends AbstractMap {// 静态内部类
private static class Entry implements Map.Entry { // 静态内部类
int index;
Entry(int index) {
this.index = index;
}
/* 判断 key 是否相等 */
public boolean equals(Object o) {
return DATA[index][0].equals(o);
}
public String getKey() {
return DATA[index][0];
}
public String getValue() {
return DATA[index][1];
}
public String setValue(String value) {
throw new UnsupportedOperationException();
}
/* key的 哈希值 */
public int hashCode() {
return DATA[index][0].hashCode();
}
}
// Use AbstractSet by implementing size() & iterator(): 通过实现 size() 和 iterator() 方法来应用 AbstractSet 抽象类
static class EntrySet extends AbstractSet> {// 静态内部类
private int size;
EntrySet(int size) {
if (size < 0)
this.size = 0;
// Can't be any bigger than the array:
else if (size > DATA.length)
this.size = DATA.length;
else
this.size = size;
}
public int size() {
return size;
}
private class Iter implements Iterator> { // 内部类
// Only one Entry object per Iterator:
Collection col;
private Entry entry = new Entry(-1);
public boolean hasNext() {
return entry.index < size - 1;
}
public Map.Entry next() {
entry.index++;
return entry;
}
public void remove() {
throw new UnsupportedOperationException();
}
}
public Iterator> iterator() {
return new Iter();
}
}
private static Set> entries = new EntrySet(
DATA.length);
public Set> entrySet() {
return entries;
}
}
// Create a partial map of 'size' countries:
static Map select(final int size) {
HashMap map = null;
return new FlyweightMap() {
@Override
public Set> entrySet() {
return new EntrySet(size);
}
};
}
static Map map = new FlyweightMap();
// 返回 存储首都的 map容器
public static Map capitals() {
return map; // The entire map
}
// 返回给定size 的 map
public static Map capitals(int size) {
return select(size); // A partial map
}
static List names = new ArrayList(map.keySet());
// 返回所有的 names
public static List names() {
return names;
}
// 返回给定 size 的 name list
public static List names(int size) {
return new ArrayList(select(size).keySet());
}
public static void main(String[] args) {
print(capitals(10));
print(names(10));
print(new HashMap(capitals(3)));
print(new LinkedHashMap(capitals(3)));
print(new TreeMap(capitals(3)));
print(new Hashtable(capitals(3)));
print(new HashSet(names(6)));
print(new LinkedHashSet(names(6)));
print(new TreeSet(names(6)));
print(new ArrayList(names(6)));
print(new LinkedList(names(6)));
print(capitals().get("BRAZIL"));
}
}
// 打印结果::
{ALGERIA=Algiers, ANGOLA=Luanda, BENIN=Porto-Novo, BOTSWANA=Gaberone, BURKINA FASO=Ouagadougou, BURUNDI=Bujumbura, CAMEROON=Yaounde, CAPE VERDE=Praia, CENTRAL AFRICAN REPUBLIC=Bangui, CHAD=N'djamena}
[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI, CAMEROON, CAPE VERDE, CENTRAL AFRICAN REPUBLIC, CHAD]
{BENIN=Porto-Novo, ANGOLA=Luanda, ALGERIA=Algiers}
{ALGERIA=Algiers, ANGOLA=Luanda, BENIN=Porto-Novo}
{ALGERIA=Algiers, ANGOLA=Luanda, BENIN=Porto-Novo}
{ALGERIA=Algiers, ANGOLA=Luanda, BENIN=Porto-Novo}
[BENIN, BOTSWANA, ANGOLA, BURKINA FASO, ALGERIA, BURUNDI]
[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
Brasilia【荔枝的关键之处】 通过继承容器抽象类来创建定制的 Map 和 Collection 有多简单。。为了创建只读的 Map,可以继承 AbstractMap 并实现 entrySet() 方法。为了创建只读的 Set ,可以继承 AbstractSet 并实现 iterator() 和 size()方法;
【定制ArrayList的荔枝】
public class CountingIntegerList extends AbstractList {
private int size;
public CountingIntegerList(int size) {
this.size = size < 0 ? 0 : size;
}
public Integer get(int index) {
return Integer.valueOf(index);
}
public int size() {
return size;
}
public static void main(String[] args) {
System.out.println(new CountingIntegerList(30));
}
} /*
* Output: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
* 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
*/// :~ 【代码解说】为了基于 AbstractList 创建只读的List, 必须实现 size() 和 get() 方法;
【荔枝】创建定制的Map
public class CountingMapData extends AbstractMap {
private int size;
private static String[] chars = "A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".split(" ");
public CountingMapData(int size) {
if (size < 0)
this.size = 0;
this.size = size;
}
private static class Entry implements Map.Entry {// 静态内部类
int index;
Entry(int index) {
this.index = index;
}
public boolean equals(Object o) {
return Integer.valueOf(index).equals(o);
}
public Integer getKey() {
return index;
}
public String getValue() {
return chars[index % chars.length]
+ Integer.toString(index / chars.length);
}
public String setValue(String value) {
throw new UnsupportedOperationException();
}
public int hashCode() {
return Integer.valueOf(index).hashCode();
}
}
public Set> entrySet() {
// LinkedHashSet retains initialization order:
// LinkedHashSet 保持了初始化顺序。
Set> entries = new LinkedHashSet>();
for (int i = 0; i < size; i++)
entries.add(new Entry(i));
return entries;
}
public static void main(String[] args) {
/*AbstractMap的toString() 方法调用了 entrySet().iterator() 迭代器*/
/* iteraotr迭代器 调用了 entry.getKey() 和 entry.getValue() 方法 */
System.out.println(new CountingMapData(60));
}
}
/*
* Output: {0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0, 9=J0, 10=K0,
* 11=L0, 12=M0, 13=N0, 14=O0, 15=P0, 16=Q0, 17=R0, 18=S0, 19=T0, 20=U0, 21=V0,
* 22=W0, 23=X0, 24=Y0, 25=Z0, 26=A1, 27=B1, 28=C1, 29=D1, 30=E1, 31=F1, 32=G1,
* 33=H1, 34=I1, 35=J1, 36=K1, 37=L1, 38=M1, 39=N1, 40=O1, 41=P1, 42=Q1, 43=R1,
* 44=S1, 45=T1, 46=U1, 47=V1, 48=W1, 49=X1, 50=Y1, 51=Z1, 52=A2, 53=B2, 54=C2,
* 55=D2, 56=E2, 57=F2, 58=G2, 59=H2}
*/// :~【17.3】Collection的功能方法

【荔枝】Collection方法列表展示
public class CollectionMethods {
public static void main(String[] args) {
Collection c = new ArrayList();
c.addAll(Countries.names(6));
c.add("ten");
c.add("eleven");
print("c = ", c);
/* list 转 数组 */
Object[] array = c.toArray();
// Make a String array from the List:
String[] str = c.toArray(new String[0]);
/* Collections.max() 和 Collections.min() 方法:找出list的最大最小值 */
print("Collections.max(c) = " + Collections.max(c));
print("Collections.min(c) = " + Collections.min(c));
/* addAll(): 把一个容器添加到另一个容器中 */
Collection c2 = new ArrayList();
c2.addAll(Countries.names(6));
c.addAll(c2);
print("c2.addAll(Countries.names(6)), c.addAll(c2), c = ", c);
/* remove(): 移除某个元素 */
c.remove(Countries.DATA[0][0]);
print("c.remove(Countries.DATA[0][0]), c = ", c);
c.remove(Countries.DATA[1][0]);
print("c.remove(Countries.DATA[1][0]), c = ", c);
/* removeAll(): 从c中移除c 和 c2 的交集元素 */
print("c2 = ", c2);
c.removeAll(c2);
print("c.removeAll(c2), c = ", c);
c.addAll(c2);
print("c.addAll(c2), c = " + c);
/* contains(): 集合是否包含单个元素 */
String val = Countries.DATA[3][0];
print("c.contains(" + val + ") = " + c.contains(val));
/* containsAll(): 集合间是否存在包含关系 */
print("c.containsAll(c2) = " + c.containsAll(c2));
/* subList(start, end):截取子集,包括start,不包括end */
Collection c3 = ((List) c).subList(3, 5);
print("c3 = ((List) c).subList(3, 5), c3 = " + c3);
/* retainAll(): 求两个集合的交集 */
print("c2 = ", c2);
c2.retainAll(c3);
print("c2.retainAll(c3), c2 = ", c2);
/* a.removeAll(b): 从a中移除a与b的交集 */
c2.removeAll(c3);
print("c2.removeAll(c3), c2.isEmpty() = " + c2.isEmpty());
c = new ArrayList();
c.addAll(Countries.names(6));
print("c.addAll(Countries.names(6)), c = ", c);
c.clear(); // Remove all elements
print("c.clear(), c = " + c);
}
}
// 打印结果:
c = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI, ten, eleven]
Collections.max(c) = ten
Collections.min(c) = ALGERIA
c2.addAll(Countries.names(6)), c.addAll(c2), c = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI, ten, eleven, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
c.remove(Countries.DATA[0][0]), c = [ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI, ten, eleven, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
c.remove(Countries.DATA[1][0]), c = [BENIN, BOTSWANA, BURKINA FASO, BURUNDI, ten, eleven, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
c2 = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
c.removeAll(c2), c = [ten, eleven]
c.addAll(c2), c = [ten, eleven, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
c.contains(BOTSWANA) = true
c.containsAll(c2) = true
c3 = ((List) c).subList(3, 5), c3 = [ANGOLA, BENIN]
c2 = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
c2.retainAll(c3), c2 = [ANGOLA, BENIN]
c2.removeAll(c3), c2.isEmpty() = true
c.addAll(Countries.names(6)), c = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
c.clear(), c = []
1)可选操作是什么: 执行 各种不同的添加和移除的方法在 Collection接口中都是可选操作;
2)未获支持的操作这种方式可以实现java容器类库的一个重要目标: 容器应该易学易用;
3)UnsupportedOperationException 未获支持的异常
3.1)UnsupportedOperationException 必须是一种罕见事件。。大多数情况下, 所有操作都应该是可以工作的,只有在特例中才会有 未获支持的操作;
3.2)如果一个操作是未获支持的,那么在实现接口时可能会导致 UnsupportedOperationException异常,而不是把 程序交给客户之后才出现此异常,这种情况是有道理的;
3.3)注意: 未获支持的操作只有在运行时才能探测到,因此它们表示动态类型检查;
【17.4.1】未获支持的操作
【荔枝】当执行未获支持操作时,抛出UnsupportedOperationException异常
public class Unsupported {
static void test(String msg, List list) {
System.out.println("--- " + msg + " ---");
Collection c = list;
Collection subList = list.subList(1, 8);
// Copy of the sublist:
Collection c2 = new ArrayList(subList);
try {
c.retainAll(c2);
} catch (Exception e) {
System.out.println("retainAll(): " + e);
}
try {
c.removeAll(c2);
} catch (Exception e) {
System.out.println("removeAll(): " + e);
}
try {
c.clear();
} catch (Exception e) {
System.out.println("clear(): " + e);
}
try {
c.add("X");
} catch (Exception e) {
System.out.println("add(): " + e);
}
try {
c.addAll(c2);
} catch (Exception e) {
System.out.println("addAll(): " + e);
}
try {
c.remove("C");
} catch (Exception e) {
System.out.println("remove(): " + e);
}
// The List.set() method modifies the value but
// doesn't change the size of the data structure:
try {
/* 对于Arrays.asList()生成的list, 修改其某个index上的值是可以的 */
list.set(0, "X");
} catch (Exception e) {
System.out.println("List.set(): " + e);
}
}
public static void main(String[] args) {
List list = Arrays.asList("A B C D E F G H I J K L".split(" "));
// 可修改的拷贝,因为 new ArrayList 是利用list的基本数组数据 进行深度拷贝。
test("Modifiable Copy", new ArrayList(list));
System.out.println();
// 这个list(Arrays$ArrayList) 的基本数组 的 数据 是无法 改变的。
test("Arrays.asList()", list);
System.out.println();
// 这是一种 不可修改的 拷贝,同 new ArrayList()
test("unmodifiableList()", Collections.unmodifiableList(new ArrayList(list)));
}
}
// 打印结果:
--- Modifiable Copy ---
--- Arrays.asList() ---
retainAll(): java.lang.UnsupportedOperationException
removeAll(): java.lang.UnsupportedOperationException
clear(): java.lang.UnsupportedOperationException
add(): java.lang.UnsupportedOperationException
addAll(): java.lang.UnsupportedOperationException
remove(): java.lang.UnsupportedOperationException
--- unmodifiableList() ---
retainAll(): java.lang.UnsupportedOperationException
removeAll(): java.lang.UnsupportedOperationException
clear(): java.lang.UnsupportedOperationException
add(): java.lang.UnsupportedOperationException
addAll(): java.lang.UnsupportedOperationException
remove(): java.lang.UnsupportedOperationException
List.set(): java.lang.UnsupportedOperationException【代码解说】
1)因为Arrays.asList() 会生成一个 List,它基于一个固定大小的数组,仅支持哪些不会改变数组大小的操作,对他而言是有道理的;
2)注意,应该把Arrays.asList() 产生的list 作为构造器参数传给任何其他的 Collection(推荐用 Collections.addAll() 方法),这样就可以生成允许使用所有容器方法的 list了;
3)list.set(0, "X") : 可以看到 修改 Arrays.asList() 产生的list 的 某个元素的时候 是不会抛出异常的,因为它并没有修改 list容器的大小;
4)Arrays.asList() 返回了固定尺寸的List, 而 Collections.unmodifiableList() 产生不可修改的列表:所以你会看见 当 list = ArrayList.asList()的时候, list.set(0, "X") 执行通过;而当 list = Collections.unmodifiableList() 时,则会抛出 java.lang.UnsupportedOperationException 未获支持的异常;
【17.5】List的功能方法
1)List的常用方法列表: add()方法添加对象,get() 方法取出一个元素, 调用 iterator() 方法获取遍历list的 迭代器 Iterator;
【荔枝】List方法列表
public class Lists {
private static boolean b;
private static String s;
private static int i;
private static Iterator it;
private static ListIterator lit;
public static void basicTest(String collectionName, List a) {
print("\n// collectionName = " + collectionName + "from basicTest method.");
a.add(1, "x"); // Add at location 1(即第2个位置)
a.add("x"); // Add at end
print("a.add(1, \"x\"), a.add(\"x\"), a = " + a);
a.addAll(Countries.names(5));
a.addAll(3, Countries.names(5));
print("a.addAll(Countries.names(5)), a.addAll(3, Countries.names(5)), a = " + a);
b = a.contains("1"); // Is it in there?
print("a.contains(\"1\") = " + b);
// Is the entire collection in there?
b = a.containsAll(Countries.names(5));
print("a.containsAll(Countries.names(5)) = " + b);
/* 以下操作成本对ArrayList很便宜,对LinkedList很昂贵 */
s = a.get(1); // 取出 index = 1 处的值
i = a.indexOf("1"); // Tell index of object
b = a.isEmpty(); // Any elements inside?
it = a.iterator(); // Ordinary Iterator
lit = a.listIterator(); // ListIterator
lit = a.listIterator(3); // Start at loc 3
i = a.lastIndexOf("1"); // Last match
System.out.println("a.get(1) = " + s + ", a.indexOf(\"1\") = " + i
+ ", a.isEmpty() = " + b + ", a.iterator() = " + it + ", "
+ "a.listIterator(3) = " + lit + ", a.lastIndexOf(\"1\") = " + a.lastIndexOf("1"));
print("a = " + a);
a.remove(1); // Remove location 1
a.remove("3"); // Remove this object
a.remove("tr");
a.set(1, "y"); // Set location 1 to "y"
print("a.remove(1), a.remove(\"3\"), a.set(1, \"y\"), a = " + a);
/* retainAll() 求交集 */
print("a = " + a);
a.retainAll(Countries.names(5));
print("Countries.names(5) = " + Countries.names(5));
print("a.retainAll(Countries.names(5)), a = " + a);
// Remove everything that's in the argument:
a.removeAll(Countries.names(5));
System.out.println("a.removeAll(Countries.names(5)), a = " + a);
i = a.size(); // How big is it?
a.clear(); // Remove all elements
// mycode
System.out.println("====== this is my mycode ======");
a = new ArrayList(Arrays.asList("A B C D E F G".split(" ")));
List subList = new ArrayList(Arrays.asList("A Z C I".split(" ")));
print("a = " + a);
print("subList = " + subList);
a.retainAll(subList);
print("a.retainAll(subList), a = " + a);
print("sublist = " + subList);
System.out.println("\n====== this is my mycode ======");
a = new ArrayList(Arrays.asList("A B C D E F G".split(" ")));
subList = new ArrayList(Arrays.asList("A Z C I".split(" ")));
print("a = " + a);
print("subList = " + subList);
subList.retainAll(a);
print("after subList.retainAll(a)");
print("a = " + a);
print("sublist = " + subList);
System.out.println("====== this is my mycode ====== \nover");
}
/* 双向移动的迭代器 */
public static void iterMotion(String collectionName, List a) {
print("\n// collectionName = " + collectionName + ", from iterMotion method");
print("a = " + a);
ListIterator it = a.listIterator(); // 双向移动的迭代器
b = it.hasNext();
print("it.hasNext() = " + b);
b = it.hasPrevious();
print("it.hasPrevious() = " + b);
s = it.next(); // 先返回值 后 counter++.
print("it.next() = " + s);
i = it.nextIndex(); // 返回当值的 counter 大小
print("it.nextIndex() = " + i);
s = it.previous(); // --counter 先减 返回值 .
print("it.previous() = " + s);
i = it.previousIndex(); // --counter 先减
print("it.previousIndex() = " + i);
}
/* 通过迭代器操作容器元素(增删改查) */
public static void iterManipulation(String collectionName, List a) {
print("\n// collectionName = " + collectionName + ", from iterManipulation method");
ListIterator it = a.listIterator();
print("a = " + a);
it.add("47");
print("it.add(\"47\"), a = " + a);
it.next(); // 先返回值,后更新游标
it.remove();// 移除游标的上一个元素,然后更新游标;
print("ListIterator.next(), ListIterator.remove(), a = " + a);
// Must move to an element after remove():
/* remove 操作后,必须调用next() 方法,因为 remove() 把 lastRet 赋值为 -1 */
it.next();
// Change the element after the deleted one:
it.set("47");
print("a = " + a);
}
public static void testVisual(String collectionName, List a) {
print("\n// collectionName = " + collectionName);
print(a);
List b = Countries.names(5);
print("b = " + b);
ArrayList list;
a.addAll(b);
a.addAll(b);
print("a.addAll(b) a.addAll(b); a = " + a);
// Insert, remove, and replace elements
// using a ListIterator:
ListIterator x = a.listIterator(a.size() / 2);
x.add("one");
print("x.add('one'); a = " + a);
print(x.next());
x.remove();
print(x.next());
x.set("47");
print(a);
// Traverse the list backwards:
x = a.listIterator(a.size());
while (x.hasPrevious())
printnb(x.previous() + " ");
print();
print("====== testVisual finished ======\n");
}
// There are some things that only LinkedLists can do:
public static void testLinkedList(String collectionName) {
print("\n====== testLinkedList ======");
LinkedList ll = new LinkedList();
ll.addAll(Countries.names(5));
print(ll);
// Treat it like a stack, pushing:
ll.addFirst("one");
ll.addFirst("two");
print(ll);
// Like "peeking" at the top of a stack:
print(ll.getFirst());
// Like popping a stack:
print(ll.removeFirst());
print(ll.removeFirst());
// Treat it like a queue, pulling elements
// off the tail end:
print(ll.removeLast());
print(ll);
print("====== testLinkedList over.======\n");
}
public static void main(String[] args) {
// Make and fill a new list each time:
basicTest("basicTest, LinkedList", new LinkedList(Countries.names(5)));
basicTest("basicTest, ArrayList", new ArrayList(Countries.names(5)));
iterMotion("iterMotion, LinkedList", new LinkedList(Countries.names(5)));
iterMotion("iterMotion, ArrayList", new ArrayList(Countries.names(5)));
iterManipulation("iterManipulation, LinkedList", new LinkedList(Countries.names(5)));
iterManipulation("iterManipulation, ArrayList", new ArrayList(Countries.names(5)));
testVisual("testVisual, LinkedList", new LinkedList(Countries.names(5)));
testLinkedList("testLinkedList");
}
} // 打印结果:
// collectionName = basicTest, LinkedListfrom basicTest method.
a.add(1, "x"), a.add("x"), a = [ALGERIA, x, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, x]
a.addAll(Countries.names(5)), a.addAll(3, Countries.names(5)), a = [ALGERIA, x, ANGOLA, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, x, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.contains("1") = false
a.containsAll(Countries.names(5)) = true
a.get(1) = x, a.indexOf("1") = -1, a.isEmpty() = false, a.iterator() = java.util.LinkedList$ListItr@15db9742, a.listIterator(3) = java.util.LinkedList$ListItr@6d06d69c, a.lastIndexOf("1") = -1
a = [ALGERIA, x, ANGOLA, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, x, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.remove(1), a.remove("3"), a.set(1, "y"), a = [ALGERIA, y, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, x, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a = [ALGERIA, y, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, x, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
Countries.names(5) = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.retainAll(Countries.names(5)), a = [ALGERIA, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.removeAll(Countries.names(5)), a = []
====== this is my mycode ======
a = [A, B, C, D, E, F, G]
subList = [A, Z, C, I]
a.retainAll(subList), a = [A, C]
sublist = [A, Z, C, I]
====== this is my mycode ======
a = [A, B, C, D, E, F, G]
subList = [A, Z, C, I]
after subList.retainAll(a)
a = [A, B, C, D, E, F, G]
sublist = [A, C]
====== this is my mycode ======
over
// collectionName = basicTest, ArrayListfrom basicTest method.
a.add(1, "x"), a.add("x"), a = [ALGERIA, x, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, x]
a.addAll(Countries.names(5)), a.addAll(3, Countries.names(5)), a = [ALGERIA, x, ANGOLA, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, x, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.contains("1") = false
a.containsAll(Countries.names(5)) = true
a.get(1) = x, a.indexOf("1") = -1, a.isEmpty() = false, a.iterator() = java.util.ArrayList$Itr@7852e922, a.listIterator(3) = java.util.ArrayList$ListItr@4e25154f, a.lastIndexOf("1") = -1
a = [ALGERIA, x, ANGOLA, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, x, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.remove(1), a.remove("3"), a.set(1, "y"), a = [ALGERIA, y, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, x, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a = [ALGERIA, y, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, x, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
Countries.names(5) = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.retainAll(Countries.names(5)), a = [ALGERIA, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BENIN, BOTSWANA, BURKINA FASO, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.removeAll(Countries.names(5)), a = []
====== this is my mycode ======
a = [A, B, C, D, E, F, G]
subList = [A, Z, C, I]
a.retainAll(subList), a = [A, C]
sublist = [A, Z, C, I]
====== this is my mycode ======
a = [A, B, C, D, E, F, G]
subList = [A, Z, C, I]
after subList.retainAll(a)
a = [A, B, C, D, E, F, G]
sublist = [A, C]
====== this is my mycode ======
over
// collectionName = iterMotion, LinkedList, from iterMotion method
a = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
it.hasNext() = true
it.hasPrevious() = false
it.next() = ALGERIA
it.nextIndex() = 1
it.previous() = ALGERIA
it.previousIndex() = -1
// collectionName = iterMotion, ArrayList, from iterMotion method
a = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
it.hasNext() = true
it.hasPrevious() = false
it.next() = ALGERIA
it.nextIndex() = 1
it.previous() = ALGERIA
it.previousIndex() = -1
// collectionName = iterManipulation, LinkedList, from iterManipulation method
a = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
it.add("47"), a = [47, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
ListIterator.next(), ListIterator.remove(), a = [47, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a = [47, 47, BENIN, BOTSWANA, BURKINA FASO]
// collectionName = iterManipulation, ArrayList, from iterManipulation method
a = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
it.add("47"), a = [47, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
ListIterator.next(), ListIterator.remove(), a = [47, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a = [47, 47, BENIN, BOTSWANA, BURKINA FASO]
// collectionName = testVisual, LinkedList
[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
b = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
a.addAll(b) a.addAll(b); a = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
x.add('one'); a = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, ALGERIA, ANGOLA, one, BENIN, BOTSWANA, BURKINA FASO, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
BENIN
BOTSWANA
[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, ALGERIA, ANGOLA, one, 47, BURKINA FASO, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
BURKINA FASO BOTSWANA BENIN ANGOLA ALGERIA BURKINA FASO 47 one ANGOLA ALGERIA BURKINA FASO BOTSWANA BENIN ANGOLA ALGERIA
====== testVisual finished ======
====== testLinkedList ======
[ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
[two, one, ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO]
two
two
one
BURKINA FASO
[ALGERIA, ANGOLA, BENIN, BOTSWANA]
====== testLinkedList over.======【17.6】Set和存储顺序
1)Set需要一种方式来维护存储顺序。而存储顺序的维护依赖于Set的不同实现(HashSet, TreeSet 和 LinkedHashSet);
2)Set 基类 和 子类:
2.1)Set接口: 存入 Set 的每个元素是唯一的,Set 不保持重复元素。 加入Set 的元素必须重写 equals 方法 以确保对象唯一性;
2.2)HashSet* (默认选择,优先推荐使用HashSet): 为快速查找而设计的 Set。 存入HashSet 的元素重写 hashCode 方法;
2.3)TreeSet:保持顺序的 Set, 底层基于 红黑树实现。存入 TreeSet 的元素必须实现 Comparable接口;
2.4)LinkedHashSet: 具有HashSet的 快速查询优点, 内部使用链表维护元素顺序(插入的次序)。存入LinkedHashSet的元素重写 hashCode 方法;
3)重写 equals 和 hashCode 方法:
3.1)重写equals方法:必须为 存入 HashSet 和 TreeSet 的元素 重写其 equals 方法;
3.2)重写 hashCode方法: 当元素被存储到 HashSet 或 LinkedHashSet 中时,必须重写元素的 hashCode 方法;
(建议: 良好的编码风格是 同时重写 equals 方法 和 hashCode 方法)
【荔枝-HashSet, TreeSet, LinkedHashSet存储规则】
// 存入Set的元素, 必须重写 equals 方法
class SetType {
int i;
public SetType(int n) {
i = n;
}
/* 重写 equals 方法 */
@Override
public boolean equals(Object o) {
return o instanceof SetType && (i == ((SetType) o).i);
}
public String toString() {
return Integer.toString(i);
}
}
/* 存入 HashSet的元素 */
class HashType extends SetType {
public HashType(int n) {
super(n);
}
/* 重写 hashCode 方法 */
public int hashCode() {
return i;
}
}
/* 存入 TreeSet的元素, 实现 Comparable 接口 */
class TreeType extends SetType implements Comparable {
public TreeType(int n) {
super(n);
}
@Override
public int compareTo(TreeType arg) {
return (arg.i < i ? -1 : (arg.i == i ? 0 : 1));
}
}
public class TypesForSets {
static Set fill(Set set, Class type) {
try {
for (int i = 0; i < 10; i++)
set.add(type.getConstructor(int.class).newInstance(i));
} catch (Exception e) {
throw new RuntimeException(e);
}
return set;
}
static void test(Set set, Class type) {
fill(set, type);
fill(set, type); // Try to add duplicates, 不重复的。
fill(set, type);
System.out.println(set);
}
public static void main(String[] args) {
test(new HashSet(), HashType.class); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] // 无序
test(new LinkedHashSet(), HashType.class); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 输出顺序和插入顺序同
test(new TreeSet(), TreeType.class); // [9, 8, 7, 6, 5, 4, 3, 2, 1, 0], 按照排序规则,有序
System.out.println("\n======\n");
// Things that don't work: Set 存储不重复元素不起作用了(凡是使用到 hash散列机制的容器,必须重写该容器中存储元素的 hashCode 方法,否则容器的存储规则不奏效)
test(new HashSet(), SetType.class); // HashSet 添加 SetType元素,而SetType 没有重写 hashCode() 方法
test(new HashSet(), TreeType.class); // HashSet 添加 TreeType元素,而TreeType 没有重写 hashCode() 方法
test(new LinkedHashSet(), SetType.class); // LinkedHashSet 添加 SetType元素,而SetType 没有重写 hashCode() 方法
test(new LinkedHashSet(), TreeType.class); // LinkedHashSet 添加 TreeType元素,而TreeType 没有重写 hashCode() 方法
System.out.println("\n======\n");
try {
test(new TreeSet(), SetType.class); // SetType 没有实现 Comparable接口,不是Comparable子类,所以插入TreeSet失败并抛出异常;
} catch (Exception e) {
System.out.println(e.getMessage());
}
try {
test(new TreeSet(), HashType.class); // HashType 没有实现 Comparable接口,不是Comparable子类,所以插入TreeSet失败并抛出异常;
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
/*
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] // 无序
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] // 输出顺序和插入顺序同
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0] // 按照排序规则,有序
======
[7, 3, 1, 9, 6, 5, 9, 1, 3, 8, 9, 0, 5, 2, 6, 1, 5, 4, 2, 0, 7, 4, 3, 8, 8, 7, 6, 4, 0, 2]
[8, 0, 3, 9, 0, 2, 8, 5, 2, 3, 4, 1, 2, 9, 4, 1, 9, 6, 7, 7, 4, 1, 3, 8, 6, 5, 7, 5, 6, 0]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
======
java.lang.ClassCastException: chapter17.SetType cannot be cast to java.lang.Comparable
java.lang.ClassCastException: chapter17.HashType cannot be cast to java.lang.Comparable
*/ 解说1)compareTo() 方法和equals() 方法的自然排序规则一致: equals 返回true,compareTo 方法返回 0;equals 返回 false, compareTo 方法返回 非0;
解说2)对于没有重写 hashCode() 方法的 SetType 或 TreeType, 如果将他们放置到任何散列实现中都会产生重复值;因为 HashSet 或 LinkedHashSet 中 重复的意义在于 元素的 哈希值或 hashCode 相同;
【干货——HashSet 和 LinkedHashSet 底层采用 HashMap.key 进行存储元素,因为 LinkedHashSet 继承 HashSet】
// HashSet 的构造器 和 Iterator() 方法源码
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public Iterator iterator() {
return map.keySet().iterator();
}
// TreeMap 的构造器 和 iterator() 方法源码
TreeSet(NavigableMap m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap());
}
public TreeSet(Comparator comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection c) {
this();
addAll(c);
}
public TreeSet(SortedSet s) {
this(s.comparator());
addAll(s);
}
public Iterator iterator() {
return m.navigableKeySet().iterator();
} 【荔枝-Object.equals() 和 hashCode() 方法源码】
// Object.equals() and hashCode() 源码
public boolean equals(Object obj) {
return (this == obj);
}
public native int hashCode();4)HashSet, LinkedHashSet, TreeSet 存储机制
HashSet, 以某种散列机制 保持所有元素;
LinkedHashSet, 按照元素插入的顺序保存元素;
TreeSet, 按照排序顺序维护元素的次序, 排序规则 通过 实现 Comparable接口并重写 compareTo() 方法来实现;
【17.6.1】SortedSet
1)介绍: SortedSet中的元素保证处于排序状态; 其 comparator() 方法返回当前 Set 使用 的 Comparator;或者返回null 表示 以自然方式排序;
first() 返回第一个元素;
last() 返回最后一个元素;
subSet(from, to ) 生成set的子集, 包含from 不包含 to;
headSet(to) 生成该set 的子集, 且子集元素的值 小于 to 元素的值;
tailSet(from) 生成该set 的子集, 且子集元素的值 大于 或等于 from 元素的值;
【荔枝-SortedSet方法演示】
public class SortedSetDemo {
public static void main(String[] args) {
SortedSet sortedSet = new TreeSet();
Collections.addAll(sortedSet,
"one two three four five six seven eight".split(" "));
print("sortedSet = " + sortedSet); // sortedSet = [eight, five, four, one, seven, six, three, two]
String low = sortedSet.first(); // 第一个元素
String high = sortedSet.last(); // 最后一个元素
print("low = " + low);
print("high = " + high);
Iterator it = sortedSet.iterator(); // 迭代器
for (int i = 0; i <= 6; i++) {
if (i == 3)
low = it.next();
if (i == 6)
high = it.next();
else
it.next();
}
print(low); // one
print(high); // two
print(sortedSet.subSet(low, high)); // 子集(包括low,不包括high):[one, seven, six, three]
print(sortedSet.headSet(high)); // 元素值小于high的子集: [eight, five, four, one, seven, six, three]
print(sortedSet.tailSet(low)); // 元素值大于等于low的子集:[one, seven, six, three, two]
print("sortedSet.comparator() = " + sortedSet.comparator()); // sortedSet.comparator() = null(自然排序)
}
}
【17.7】队列
1)Queue的实现: java SE5 中的实现是 LinkedList 和 PriorityQueue, 它们的差异在于 排序行为而不是性能;
/* Queue容器进队和出队的荔枝 */
public class QueueBehavior {
private static int count = 10;
static void test(Queue queue, Generator gen) {
for (int i = 0; i < count; i++)
queue.offer(gen.next()); // 插入尾部:offer() == add() 方法
while (queue.peek() != null) // 不删除头部并返回头部: peek() 当queue为空返回空
System.out.print(queue.remove() + " "); // 删除头部;
System.out.println();
}
static class Gen implements Generator {
String[] s = ("one two three four five six seven " + "eight nine ten")
.split(" ");
int i;
public String next() {
return s[i++];
}
}
public static void main(String[] args) {
test(new LinkedList(), new Gen()); // 出队顺序与进队顺序一致
test(new PriorityQueue(), new Gen()); // 不一致
test(new ArrayBlockingQueue(count), new Gen()); // 出队顺序与进队顺序一致
test(new ConcurrentLinkedQueue(), new Gen()); // 出队顺序与进队顺序一致
test(new LinkedBlockingQueue(), new Gen()); // 出队顺序与进队顺序一致
test(new PriorityBlockingQueue(), new Gen()); // 不一致
}
} 【代码解说】除了优先级队列 PriorityQueue 和 PriorityBlockingQueue, 其他队列 将精确地按照进队顺序进行出队操作;
【17.7.1】优先级队列
/* 优先级队列的荔枝 */
public class ToDoList extends PriorityQueue {
static class ToDoItem implements Comparable { // 静态内部类
private char primary;
private int secondary;
private String item;
public ToDoItem(char pri, int sec, String item) {
primary = pri;
secondary = sec;
this.item = item;
}
/* 优先级计算规则 */
public int compareTo(ToDoItem arg) {
if (primary > arg.primary)
return +1;
if (primary == arg.primary)
if (secondary > arg.secondary)
return +1;
else if (secondary == arg.secondary)
return 0;
return -1;
}
public String toString() {
return Character.toString(primary) + secondary + ": " + item + "; ";
}
}
public void add(String item, char pri, int sec) {
super.add(new ToDoItem(pri, sec, item));
}
public static void main(String[] args) {
ToDoList toDoList = new ToDoList();
toDoList.add("A4", 'C', 4);
toDoList.add("A2", 'A', 2);
toDoList.add("B7", 'B', 7);
toDoList.add("C3", 'C', 3);
toDoList.add("A1", 'A', 1);
toDoList.add("B1", 'B', 1);
while (!toDoList.isEmpty())
System.out.print(toDoList.remove() + " ");
}
}
/*
A1: A1; A2: A2; B1: B1; B7: B7; C3: C3; C4: A4;
*/
1)介绍: 可以在双向队列(双端队列) 的任何一段添加 或 移除元素。LinkedList提供了支持 双向队列的方法,但在java 标准类库中 没有任何显式 的用于双向队列的接口;
2)如何实现双向队列: 使用组合来创建一个 Deque类, 并直接中 LinkedList中暴露方法,如下:
// 这是 作者 自定义的 双向队列 Deque, 该双向队列的底层基于 LinkedList
public class Deque {
private LinkedList deque = new LinkedList();
public void addFirst(T e) {
deque.addFirst(e);
}
public void addLast(T e) {
deque.addLast(e);
}
public T getFirst() {
return deque.getFirst();
}
public T getLast() {
return deque.getLast();
}
public T removeFirst() {
return deque.removeFirst();
}
public T removeLast() {
return deque.removeLast();
}
public int size() {
return deque.size();
}
public String toString() {
return deque.toString();
}
// And other methods as necessary... 这里添加其他必须的方法
} // /:~ 【代码解说】首先, 这个双向队列是 thinking-in-java 作者 自定义的,并不是java 类库中的; 且该自定义的 双向队列是基于 LinkedList来实现的;
第二: Deque 双向队列没有 Queue 那样常用;
1)Map的几种基本实现: HashMap, TreeMap, LinkedHashMap, WeakHashMap, ConcurrentHashMap, IdentityHashMap 等;
2)Map的简单荔枝:
【荔枝-通过 2维数组 来实现 HashMap的键值对存储原理】
// 通过 2维数组 来实现 HashMap的键值对存储原理
public class AssociativeArray {
Set set = new HashSet();
private Object[][] pairs;
private int index;
public AssociativeArray(int length) {
pairs = new Object[length][2];
}
public void put(K key, V value) {
if (index >= pairs.length)
throw new ArrayIndexOutOfBoundsException();
pairs[index++] = new Object[] { key, value };
}
@SuppressWarnings("unchecked")
public V get(K key) {
for (int i = 0; i < index; i++)
if (key.equals(pairs[i][0]))
return (V) pairs[i][1];
return null; // Did not find key
}
public String toString() {
StringBuilder result = new StringBuilder();
for (int i = 0; i < index; i++) {
result.append(pairs[i][0].toString());
result.append(" : ");
result.append(pairs[i][1].toString());
if (i < index - 1)
result.append("\n");
}
return result.toString();
}
public static void main(String[] args) {
AssociativeArray map = new AssociativeArray(6);
map.put("sky", "blue");
map.put("grass", "green");
map.put("ocean", "dancing");
map.put("tree", "tall");
map.put("earth", "brown");
map.put("sun", "warm");
try {
map.put("extra", "object"); // Past the end。当容器存储元素存满的时候,继续插入元素,抛出异常。
} catch (ArrayIndexOutOfBoundsException e) {
print("Too many objects!");
}
print("map = " + map);
print("map.get(\"ocean\") = " + map.get("ocean"));
}
}
/*
Too many objects!
map = sky : blue
grass : green
ocean : dancing
tree : tall
earth : brown
sun : warm
map.get("ocean") = dancing
*/
1)性能是映射表中的一个重要问题,当在 get() 中使用线性搜索时,执行速度回相当地慢,这正是 HashMap 提高速度的地方;
2)散列码: HashMap 使用了特殊的值,称作 散列码,来取代对键的缓慢搜索; HashMap 使用对象的hashCode()方法进行快速查询的;
3)下面是Map的基本实现类,其中HashMap 是默认选择:
HashMap:Map基于散列表实现,取代了 Hashtable。通过构造器设置容量和负载因子,以调整容器性能;
LinkedHashMap:使用链表维护内部次序,其中输出顺序 是 其 插入顺序 或者是最近最少使用(LRU, least recently used)次序;
TreeMap:基于红黑树实现, 被Comparable 或 Comparator 排序。TreeMap 是唯一有 subMap() 方法的Map, 它可以返回一个子树;
WeakHashMap: 弱键映射,允许释放映射所指向的对象;
ConcurrentHashMap:线程安全的Map, 不涉及同步加锁;
IdentityHashMap:使用 == 代替 equals() 方法 对 键 进行比较的散列映射;
4)散列:散列是映射中存储元素时最常用的方式;
5)任何Map容器所存储的元素必须满足以下要求:任何键都必须重写 equals() 方法; 如果存储在HashMap的元素, 该元素还必须重写 hashCode()方法;如果使用 TreeMap 来存储元素,则元素必须实现 Comparable;
【荔枝-Map实现类】
/* Map实现类的荔枝: HashMap, TreeMap, LinkedHashMap, ConcurrentHashMap, WeakHashMap */
public class Maps {
Properties pro;
public static void printKeys(Map map) {
printnb("map.size() = " + map.size() + ", ");
printnb("map.keySet() = ");
print(map.keySet()); // Produce a Set of the keys
}
public static void test(Map map, String mapType) {
System.out.println("\n ======" + mapType + "======");
print("map.getClass().getSimpleName() = " + map.getClass().getSimpleName());
map.putAll(new CountingMapData(5));
// Map has 'Set' behavior for keys:
map.putAll(new CountingMapData(5));
printKeys(map);
// Producing a Collection of the values:
printnb("map.values() = ");
print(map.values());
print("map = "+ map);
print("map.containsKey(3) = " + map.containsKey(3));
print("map.get(3) = " + map.get(3));
print("map.containsValue(\"C0\") = " + map.containsValue("C0"));
Integer key = map.keySet().iterator().next();
print("First key in map = " + key);
map.remove(key);
printKeys(map);
map.clear();
print("map.clear(), map.isEmpty() = " + map.isEmpty());
map.putAll(new CountingMapData(10));
// Operations on the Set change the Map:
map.keySet().removeAll(map.keySet());
print("map.isEmpty(): " + map.isEmpty());
}
public static void main(String[] args) {
test(new HashMap(), "HashMap");
test(new TreeMap(), "TreeMap");
test(new LinkedHashMap(), "LinkedHashMap");
test(new IdentityHashMap(), "IdentityHashMap");
test(new ConcurrentHashMap(), "ConcurrentHashMap");
test(new WeakHashMap(), "WeakHashMap");
}
}
/*
======HashMap======
map.getClass().getSimpleName() = HashMap
map.size() = 5, map.keySet() = [0, 1, 2, 3, 4]
map.values(): [A0, B0, C0, D0, E0]
map = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0}
map.containsKey(3): true
map.get(3): D0
map.containsValue("C0"): true
First key in map: 0
map.size() = 4, map.keySet() = [1, 2, 3, 4]
map.isEmpty(): true
map.isEmpty(): true
======TreeMap======
map.getClass().getSimpleName() = TreeMap
map.size() = 5, map.keySet() = [0, 1, 2, 3, 4]
map.values(): [A0, B0, C0, D0, E0]
map = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0}
map.containsKey(3): true
map.get(3): D0
map.containsValue("C0"): true
First key in map: 0
map.size() = 4, map.keySet() = [1, 2, 3, 4]
map.isEmpty(): true
map.isEmpty(): true
======LinkedHashMap======
map.getClass().getSimpleName() = LinkedHashMap
map.size() = 5, map.keySet() = [0, 1, 2, 3, 4]
map.values(): [A0, B0, C0, D0, E0]
map = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0}
map.containsKey(3): true
map.get(3): D0
map.containsValue("C0"): true
First key in map: 0
map.size() = 4, map.keySet() = [1, 2, 3, 4]
map.isEmpty(): true
map.isEmpty(): true
======IdentityHashMap======
map.getClass().getSimpleName() = IdentityHashMap
map.size() = 5, map.keySet() = [0, 2, 4, 3, 1] // 无序
map.values(): [A0, C0, E0, D0, B0]
map = {0=A0, 2=C0, 4=E0, 3=D0, 1=B0}
map.containsKey(3): true
map.get(3): D0
map.containsValue("C0"): false
First key in map: 0
map.size() = 4, map.keySet() = [2, 4, 3, 1]
map.isEmpty(): true
map.isEmpty(): true
======ConcurrentHashMap======
map.getClass().getSimpleName() = ConcurrentHashMap
map.size() = 5, map.keySet() = [0, 1, 2, 3, 4]
map.values(): [A0, B0, C0, D0, E0]
map = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0}
map.containsKey(3): true
map.get(3): D0
map.containsValue("C0"): true
First key in map: 0
map.size() = 4, map.keySet() = [1, 2, 3, 4]
map.isEmpty(): true
map.isEmpty(): true
======WeakHashMap======
map.getClass().getSimpleName() = WeakHashMap
map.size() = 5, map.keySet() = [4, 3, 2, 1, 0]
map.values(): [E0, D0, C0, B0, A0]
map = {4=E0, 3=D0, 2=C0, 1=B0, 0=A0}
map.containsKey(3): true
map.get(3): D0
map.containsValue("C0"): true
First key in map: 4
map.size() = 4, map.keySet() = [3, 2, 1, 0]
map.isEmpty(): true
map.isEmpty(): true
*/ // Maps.java 调用了 CountingMapData 类
public class CountingMapData extends AbstractMap {
private int size;
private static String[] chars = "A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".split(" ");
public CountingMapData(int size) {
if (size < 0)
this.size = 0;
this.size = size;
}
private static class Entry implements Map.Entry {// 静态内部类
int index;
Entry(int index) {
this.index = index;
}
public boolean equals(Object o) {
return Integer.valueOf(index).equals(o);
}
public Integer getKey() {
return index;
}
public String getValue() {
return chars[index % chars.length]
+ Integer.toString(index / chars.length);
}
public String setValue(String value) {
throw new UnsupportedOperationException();
}
public int hashCode() {
return Integer.valueOf(index).hashCode();
}
}
public Set> entrySet() {
// LinkedHashSet retains initialization order:
// LinkedHashSet 保持了初始化顺序。
Set> entries = new LinkedHashSet>();
for (int i = 0; i < size; i++)
entries.add(new Entry(i));
return entries;
}
public static void main(String[] args) {
/*AbstractMap的toString() 方法调用了 entrySet().iterator() 迭代器*/
/* iteraotr迭代器 调用了 entry.getKey() 和 entry.getValue() 方法 */
System.out.println(new CountingMapData(60));
}
} /*
* Output: {0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0, 9=J0, 10=K0,
* 11=L0, 12=M0, 13=N0, 14=O0, 15=P0, 16=Q0, 17=R0, 18=S0, 19=T0, 20=U0, 21=V0,
* 22=W0, 23=X0, 24=Y0, 25=Z0, 26=A1, 27=B1, 28=C1, 29=D1, 30=E1, 31=F1, 32=G1,
* 33=H1, 34=I1, 35=J1, 36=K1, 37=L1, 38=M1, 39=N1, 40=O1, 41=P1, 42=Q1, 43=R1,
* 44=S1, 45=T1, 46=U1, 47=V1, 48=W1, 49=X1, 50=Y1, 51=Z1, 52=A2, 53=B2, 54=C2,
* 55=D2, 56=E2, 57=F2, 58=G2, 59=H2}
*/// :~ // CountingMapData extends AbstractMap, 调用的也是 AbstractMap的toString()
//AbstractMap.toString() 源码
public String toString() {
Iterator> i = entrySet().iterator();
if (! i.hasNext())
return "{}";
StringBuilder sb = new StringBuilder();
sb.append('{');
for (;;) {
Entry e = i.next();
K key = e.getKey();
V value = e.getValue();
sb.append(key == this ? "(this Map)" : key);
sb.append('=');
sb.append(value == this ? "(this Map)" : value);
if (! i.hasNext())
return sb.append('}').toString();
sb.append(',').append(' ');
}
}
【17.8.2】SortedMap(TreeMap 是 SortedMap 现阶段的唯一实现)
1)使用SortedMap : 确保键处于排序状态;
2)SortMap的方法列表如下:
// 荔枝-SortedMap 方法列表
public class SortedMapDemo {
public static void main(String[] args) {
TreeMap sortedMap = new TreeMap(
new CountingMapData(10));
print("sortedMap = " +sortedMap); // sortedMap = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0, 9=J0}
Integer low = sortedMap.firstKey(); // 第一个键
Integer high = sortedMap.lastKey(); // 最后一个键
print("sortedMap.firstKey() = " + low);
print("sortedMap.lastKey() = " + high);
Iterator it = sortedMap.keySet().iterator();
for (int i = 0; i <= 6; i++) {
if (i == 3)
low = it.next();
if (i == 6)
high = it.next();
else
it.next();
}
print("low = " + low); // low = 3
print("high = " + high); // high = 7
print("sortedMap.subMap(low, high) = " + sortedMap.subMap(low, high));
print("sortedMap.headMap(high) = " + sortedMap.headMap(high));
print("sortedMap.tailMap(low) = " + sortedMap.tailMap(low));
}
}
/*
sortedMap = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0, 9=J0}
sortedMap.firstKey() = 0
sortedMap.lastKey() = 9
low = 3
high = 7
sortedMap.subMap(low, high) = {3=D0, 4=E0, 5=F0, 6=G0}(map子集,包括low=3,不包括high=7)
sortedMap.headMap(high) = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0}(map子集,键值小于high的键值对子集)
sortedMap.tailMap(low) = {3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0, 9=J0}(map子集,键值大于等于low的键值对子集)
*/ sortedMap.subMap(low, high): map子集,包括low=3,不包括high=7;
sortedMap.headMap(high):map子集,键值小于high的键值对子集;
sortedMap.tailMap(low) : map子集,键值大于等于low的键值对子集;
【17.8.3】LinkedHashMap
1)为了提高速度, LinkedHashMap' 散列化所有元素: 遍历键值对的顺序 与 元素的插入顺序相同 或 最近最少使用LRU顺序;
2)LinkedHashMap 演示荔枝
// 荔枝-LinkedHashMap 演示
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap linkedHashMap = new LinkedHashMap(
new CountingMapData(9));
print("linkedHashMap1 = " + linkedHashMap);
// Least-recently-used order: 最近最少使用 LRU 顺序
linkedHashMap = new LinkedHashMap(16, 0.75f, true);
linkedHashMap.putAll(new CountingMapData(9));
print("linkedHashMap2 = " + linkedHashMap);
for (int i = 0; i < 6; i++)
// Cause accesses:
linkedHashMap.get(i);
// 最近最少使用顺序:0,1,2,3,4,5 分别先后被使用过而6,7,8没有被使用,所以 LRU = 6, 7, 8, 0, 1, 2, 3, 4, 5,
print("linkedHashMap3 = " + linkedHashMap);
linkedHashMap.get(0);
print("linkedHashMap4 = " + linkedHashMap); // 键为0的元素被使用过,所以键=0的entry 排到了最后;
}
}
/*
linkedHashMap1 = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0}
linkedHashMap2 = {0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0}
linkedHashMap3 = {6=G0, 7=H0, 8=I0, 0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0}
linkedHashMap4 = {6=G0, 7=H0, 8=I0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 0=A0}
*/
public class Groundhog {
protected int number;
public Groundhog(int n) {
number = n;
}
public String toString() {
return "Groundhog #" + number;
}
} // /:~public class Prediction {
private static Random rand = new Random(47);
private boolean shadow = rand.nextDouble() > 0.5;
public String toString() {
if (shadow)
return "Six more weeks of Winter!";
else
return "Early Spring!";
}
} // /:~ // HashMap荔枝-以Groundhog作为key,Prediction作为value
public class SpringDetector {
// Uses a Groundhog or class derived from Groundhog:
// 使用 Groundhog 或 其子类 的class 作为 type
public static void detectSpring(Class type)
throws Exception {
// 获取构造器(采用反射机制来创建 HashMap.key )
Constructor ghog = type.getConstructor(int.class);
// 以Groundhog作为key,Prediction作为value
Map map = new HashMap();
for (int i = 0; i < 10; i++)
map.put(ghog.newInstance(i), new Prediction());
print("map = " + map); // 打印map,调用map中每个entry的key 和 value的toString()方法
Groundhog gh = ghog.newInstance(3);
print("ghog.newInstance(3) = " + gh);
if (map.containsKey(gh))
print("map.get(gh) = " + map.get(gh));
else
print("Key not found: " + gh);
}
public static void main(String[] args) throws Exception {
detectSpring(Groundhog.class);
}
}
/*
map = {Groundhog #1=Six more weeks of Winter!, Groundhog #4=Six more weeks of Winter!, Groundhog #5=Early Spring!, Groundhog #3=Early Spring!, Groundhog #8=Six more weeks of Winter!, Groundhog #7=Early Spring!, Groundhog #0=Six more weeks of Winter!, Groundhog #2=Early Spring!, Groundhog #9=Six more weeks of Winter!, Groundhog #6=Early Spring!}
ghog.newInstance(3) = Groundhog #3
Key not found: Groundhog #3
*/ // AbstractMap.toString() 方法源码
public String toString() {
Iterator> i = entrySet().iterator();
if (! i.hasNext())
return "{}";
StringBuilder sb = new StringBuilder();
sb.append('{');
for (;;) {
Entry e = i.next();
K key = e.getKey();
V value = e.getValue();
sb.append(key == this ? "(this Map)" : key);
sb.append('=');
sb.append(value == this ? "(this Map)" : value);
if (! i.hasNext())
return sb.append('}').toString();
sb.append(',').append(' ');
}
} 【代码解说】 SpringDetector.java 中, HashMap 明明插入了 number=3的 Groundhog 实例, 为什么以 number=3的Groundhog 实例 为键 无法查询到 其value ?因为 Groundhog 自动继承自基类 Object, 所以这里使用了 Object.hashCode() 方法生成散列码,而hashCode() 返回结果默认 使用对象的地址计算散列码;
1)HashMap 使用 equals() 方法: 判断当前的键是否与表中存在的键相同;
2)正确的 equals() 方法必须满足下面5个条件:
自反性: x.equals(x) 一定返回 true;
对称性:x.equals(y) == y.equals(x) == true or false;
传递性:x.equals(y) ==true 和 y.equals(z) == true , 则推出 x.equals.(z) == true;
一致性:如果对象中用于等价比较的信息没有改变,则 无论调用 x.equals(y) 多少次,返回的结果应该保持一致,要么一直是true 或者一直 是 false;
对任何不是 null 的x, x.equals(null) 一定返回 false;
3)Object.hashCode 和 Object.equals() 方法的默认实现:
equals()方法默认 :比较对象的地址;
hashCode()方法默认: 使用对象的地址计算散列码
// Object.equals() 和 Object.hashCode() 源码
public boolean equals(Object obj) {
return (this == obj);
}
public native int hashCode();4)hashCode() 和 equals() 方法的区别在于: hashCode方法用于计算键的散列码并给元素分配对应散列码的存储位置; equals 是比较两个键值对间的 键 是否相同;
【荔枝- HashMap荔枝-以Groundhog2作为key,Prediction作为value,并重写了Groundhog2的 hashCode() 和 equals() 方法】
public class Groundhog2 extends Groundhog {
public Groundhog2(int n) {
super(n);
}
// 重写 hashCode() 方法
@Override
public int hashCode() {
return number;
}
// 重写 equals() 方法
@Override
public boolean equals(Object o) {
return o instanceof Groundhog2 && (number == ((Groundhog2) o).number);
}
} // 荔枝- HashMap荔枝-以Groundhog2作为key,Prediction作为value,并重写了Groundhog2的 hashCode() 和 equals() 方法
// 现在可以找到键==3的value了
public class SpringDetector2 {
public static void main(String[] args) throws Exception {
SpringDetector.detectSpring(Groundhog2.class);
}
}
/*
map = {Groundhog #0=Six more weeks of Winter!, Groundhog #1=Six more weeks of Winter!, Groundhog #2=Early Spring!, Groundhog #3=Early Spring!, Groundhog #4=Six more weeks of Winter!, Groundhog #5=Early Spring!, Groundhog #6=Early Spring!, Groundhog #7=Early Spring!, Groundhog #8=Six more weeks of Winter!, Groundhog #9=Six more weeks of Winter!}
ghog.newInstance(3) = Groundhog #3 ( 已经可以找到键==3的value了)
map.get(gh) = Early Spring!
*/
【17.9.1】理解hashCode()
1)散列的目的在于: 想要使用一个对象查找另外一个对象;
2) 荔枝-使用 一对ArrayList 实现 Map
// 使用 一对ArrayList 实现 Map
public class SlowMap extends AbstractMap {
private List keys = new ArrayList();
private List values = new ArrayList();
public V put(K key, V value) {
V oldValue = get(key); // The old value or null
if (!keys.contains(key)) {
keys.add(key);
values.add(value);
} else
values.set(keys.indexOf(key), value);
return oldValue;
}
// key的数据类型为 Object, 而不是 泛型 K 类型
public V get(Object key) { // key is type Object, not K
if (!keys.contains(key))
return null;
return values.get(keys.indexOf(key));
}
public Set> entrySet() {
Set> set = new HashSet>(); // EntrySet 容器
Iterator ki = keys.iterator();
Iterator vi = values.iterator();
while (ki.hasNext())
set.add(new MapEntry(ki.next(), vi.next()));
return set;
}
public static void main(String[] args) {
SlowMap m = new SlowMap();
m.putAll(Countries.capitals(5));
System.out.println("m.putAll(Countries.capitals(5)), m = " + m);
System.out.println("m.get(\"BULGARIA\") = " + m.get("BULGARIA"));
System.out.println("m.entrySet() = " + m.entrySet());
}
}
/*
m.putAll(Countries.capitals(5)), m = {ANGOLA=Luanda, BURKINA FASO=Ouagadougou, BENIN=Porto-Novo, ALGERIA=Algiers, BOTSWANA=Gaberone}
m.get("BULGARIA") = null
m.entrySet() = [ANGOLA=Luanda, BURKINA FASO=Ouagadougou, BENIN=Porto-Novo, ALGERIA=Algiers, BOTSWANA=Gaberone]
*/
3)如果想要创建自己的 Map 类型, 就必须同时定义 Map.Entry 的实现;
【荔枝-定义自己的 MapEntry类型,且必须实现 Map.Entry 接口】
// 定义自己的 MapEntry类型,且必须实现 Map.Entry 接口
public class MapEntry implements Map.Entry {
private K key;
private V value;
public MapEntry(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V v) {
V result = value;
value = v;
return result;
}
// 重写 hashCode 方法
@Override
public int hashCode() {
return (key == null ? 0 : key.hashCode())
^ (value == null ? 0 : value.hashCode());
}
// 重写 equals 方法
@Override
public boolean equals(Object o) {
if (!(o instanceof MapEntry))
return false;
MapEntry me = (MapEntry) o;
return (key == null ? me.getKey() == null : key.equals(me.getKey()))
&& (value == null ? me.getValue() == null : value.equals(me
.getValue()));
}
public String toString() {
return key + "=" + value;
}
} // /:~ 【代码解说】
entrySet() 方法使用了 HashSet 来保持 键值对, 并且MapEntry 只使用了 key的hashCode() 方法;以上自定义的 MapEntry 不是一个恰当的实现: 因为它创建了 键值对的副本。。entrySet() 的切当实现应该在 Map 中提供视图, 而不是副本, 并且这个视图允许对原始映射表进行修改(副本就不行)。。
【HashMap.Entry 定义源码】
【17.9.2】 为速度而散列
1)散列的价值在于速度:散列使得查询得以快速进行;
2)哈希冲突由外部链接处理:数组并不直接保存值,而是保存值的 list。然后对list 中的值使用 equals() 方法进行线性查询。如果散列函数好的话,list 所存储的值就很少 (list保存着 散列码相同的元素)。
3)基于LinkedList自定义HashMap的荔枝:
// 基于LinkedList自定义HashMap的荔枝
public class SimpleHashMap extends AbstractMap {
private HashMap map;
// Choose a prime number for the hash table
// size, to achieve a uniform distribution:
static final int SIZE = 997; // 设置hashmap的大小为质数
// You can't have a physical array of generics,
// but you can upcast to one:
@SuppressWarnings("unchecked")
// HashMap 通过 LinkedList 来实现
LinkedList>[] buckets = new LinkedList[SIZE];
// 插入或更新(如果有的话则更新,没有的话则插入)
public V put(K key, V value) {
V oldValue = null;
int index = Math.abs(key.hashCode()) % SIZE; // 散列函数计算散列码
if (buckets[index] == null) // 每个数组元素不是 保存值,而是保存值的链表list.
buckets[index] = new LinkedList>();
LinkedList> bucket = buckets[index];
MapEntry pair = new MapEntry(key, value);
boolean found = false;
ListIterator> it = bucket.listIterator();
while (it.hasNext()) {
MapEntry iPair = it.next();
if (iPair.getKey().equals(key)) {
oldValue = iPair.getValue();
it.set(pair); // Replace old with new
found = true;
break;
}
}
if (!found)
buckets[index].add(pair);
return oldValue;
}
// 通过键获取值
public V get(Object key) {
int index = Math.abs(key.hashCode()) % SIZE;
if (buckets[index] == null)
return null;
for (MapEntry iPair : buckets[index])
if (iPair.getKey().equals(key))
return iPair.getValue();
return null;
}
public Set> entrySet() {
Set> set = new HashSet>();
for (LinkedList> bucket : buckets) {
if (bucket == null)
continue;
for (MapEntry mpair : bucket)
set.add(mpair);
}
return set;
}
public static void main(String[] args) {
SimpleHashMap m = new SimpleHashMap();
m.putAll(Countries.capitals(5));
System.out.println("m = " + m);
System.out.println("m.get(\"BENIN\") = " + m.get("BENIN"));
System.out.println("m.entrySet() = " + m.entrySet());
}
}
/*
m = {ANGOLA=Luanda, BURKINA FASO=Ouagadougou, BENIN=Porto-Novo, ALGERIA=Algiers, BOTSWANA=Gaberone}
m.get("BENIN") = Porto-Novo
m.entrySet() = [ANGOLA=Luanda, BURKINA FASO=Ouagadougou, BENIN=Porto-Novo, ALGERIA=Algiers, BOTSWANA=Gaberone]
*/
// 定义自己的 MapEntry类型,且必须实现 Map.Entry 接口
public class MapEntry implements Map.Entry {
private K key;
private V value;
public MapEntry(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V v) {
V result = value;
value = v;
return result;
}
// 重写 hashCode 方法
@Override
public int hashCode() {
return (key == null ? 0 : key.hashCode())
^ (value == null ? 0 : value.hashCode());
}
// 重写 equals 方法
@Override
public boolean equals(Object o) {
if (!(o instanceof MapEntry))
return false;
MapEntry me = (MapEntry) o;
return (key == null ? me.getKey() == null : key.equals(me.getKey()))
&& (value == null ? me.getValue() == null : value.equals(me
.getValue()));
}
public String toString() {
return key + "=" + value;
}
} // /:~ 【编码技巧】为使散列分布均匀, bucket桶的数量通常使用 质数;
【17.9.3】覆盖hashCode() 方法
1)buckets数组下标值: 依赖于具体的 HashMap对象的容量, 而容量的改变依赖于与容器的充满程度 和 负载因子有关。
2)hashCode() 生成的结果:经过处理后成为桶的下标(如取模);
3)设计hashCode() 方法最重要的因素: 无论何时, 对同一个对象调用hashCode() 都应该生成同样的值;
4)String 和 hashCode()方法的荔枝:String有个特点: 如果程序中有多个String对象, 都包含相同的字符串序列,那么这些 String 对象都映射到同一块内存区域;
看个荔枝:
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc");
String s4 = new String("abc"); 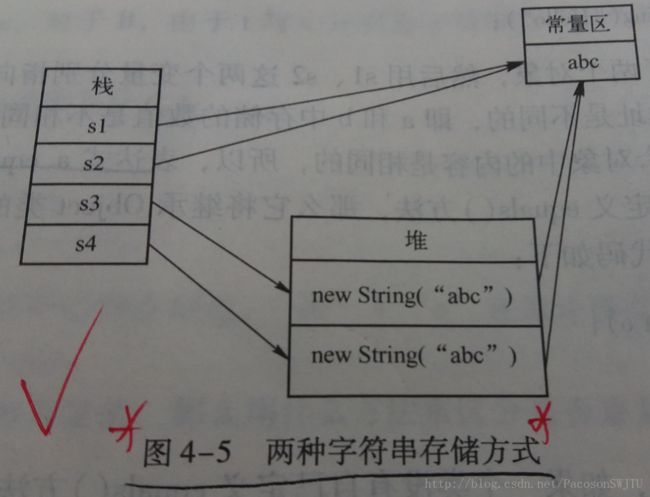
public class StringHashCode {
public static void main(String[] args) {
String[] hellos = "Hello Hello".split(" ");
System.out.println(hellos[0].hashCode()); //
System.out.println(hellos[1].hashCode());
}
}
/* hashCode 相同
69609650
69609650
*/
// 荔枝-根据Joshua Bloch的指导意见重写 存入Map容器的元素的 hashCode() 方法
public class CountedString {
private static List created = new ArrayList();
private String s;
private int id = 0;
public CountedString(String str) {
s = str;
created.add(s);
// id is the total number of instances
// of this string in use by CountedString:
for (String s2 : created)
if (s2.equals(s))
id++;
}
public String toString() {
return "key = {" + s + " , id = " + id + " , hashCode() = " + hashCode() + "}, value ";
}
// 重写 hashCode() 方法(根据Joshua Bloch的指导意见重写hashCode() 方法)
public int hashCode() {
int result = 17; // 给int变量 result 赋予某个非零常量,如17
result = 37 * result + s.hashCode(); // 为对象内每个有意义的域计算一个int类型的散列码(s.hashCode)
result = 37 * result + id; // 合并计算得到的散列码
return result;
}
// 重写 equals() 方法
public boolean equals(Object o) {
return o instanceof CountedString && s.equals(((CountedString) o).s)
&& id == ((CountedString) o).id;
}
public static void main(String[] args) {
Map map = new HashMap();
CountedString[] cs = new CountedString[5];
for (int i = 0; i < cs.length; i++) {
cs[i] = new CountedString("hi");
map.put(cs[i], i); // Autobox int -> Integer
}
print("map = " + map);
for (CountedString cstring : cs) {
print("Looking up cstring = " + cstring + ", map.get(cstring) = " + map.get(cstring));
}
}
}
/*
map = {key = {hi , id = 4 , hashCode() = 146450}, value =3, key = {hi , id = 5 , hashCode() = 146451}, value =4, key = {hi , id = 2 , hashCode() = 146448}, value =1, key = {hi , id = 3 , hashCode() = 146449}, value =2, key = {hi , id = 1 , hashCode() = 146447}, value =0}
Looking up cstring = key = {hi , id = 1 , hashCode() = 146447}, value , map.get(cstring) = 0
Looking up cstring = key = {hi , id = 2 , hashCode() = 146448}, value , map.get(cstring) = 1
Looking up cstring = key = {hi , id = 3 , hashCode() = 146449}, value , map.get(cstring) = 2
Looking up cstring = key = {hi , id = 4 , hashCode() = 146450}, value , map.get(cstring) = 3
Looking up cstring = key = {hi , id = 5 , hashCode() = 146451}, value , map.get(cstring) = 4
*/ // 根据Joshua Bloch的指导意见重写 存入Map容器的元素的 hashCode() 方法
public class Individual implements Comparable {
private static long counter = 0;
private final long id = counter++;
private String name;
public Individual(String name) {
this.name = name;
}
// 'name' is optional:
public Individual() {
}
public String toString() {
return getClass().getSimpleName() + (name == null ? "" : " " + name);
}
public long id() {
return id;
}
// 重写 equals() 方法
@Override
public boolean equals(Object o) {
return o instanceof Individual && id == ((Individual) o).id;
}
// 重写 hashCode() 方法(注意 hashCode() 方法的实现方式)
@Override
public int hashCode() {
int result = 17; // 给int变量 result 赋予某个非零常量,如17
if (name != null)
result = 37 * result + name.hashCode(); // 为对象内每个有意义的域计算一个int类型的散列码(s.hashCode)
result = 37 * result + (int) id; // 合并计算得到的散列码
return result;
}
// 实现 Comparable 接口,并重写 compareTo() 方法
@Override
public int compareTo(Individual arg) {
// Compare by class name first:
String first = getClass().getSimpleName();
String argFirst = arg.getClass().getSimpleName();
int firstCompare = first.compareTo(argFirst); // 1.第一次比较
if (firstCompare != 0)
return firstCompare;
if (name != null && arg.name != null) {
// 2.若第一次比较没有结果,则进行第二次比较
int secondCompare = name.compareTo(arg.name);
if (secondCompare != 0)
return secondCompare;
}
// 3. 若类型无法比较两则大小,则用 id 进行比较
return (arg.id < id ? -1 : (arg.id == id ? 0 : 1));
}
} // /:~ // ArrayList.set() and get() 源码
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
public E get(int index) {
rangeCheck(index);
return elementData(index);
}// LinkedList.set() and get() 源码
public E set(int index, E element) {
checkElementIndex(index);
Node x = node(index); // for 循环遍历
E oldVal = x.item;
x.item = element;
return oldVal;
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
} // ArrayList.add() 源码
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}// LinkedList.add() 源码
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}// ArrayList.remove() 源码
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}// LinkedList.remove() 源码
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node f) {
// assert f == first && f != null;
final E element = f.item;
final Node next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
// 或者 remove(i)
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
} 


// 荔枝-Collections 容器工具方法列表
public class Utilities {
/* Arrays.asList() 产生是list大小是固定的,不能执行add() 操作(会抛异常),但是可以修改即set() 操作*/
static List list = Arrays.asList("one Two three Four five six one".split(" "));
public static void main(String[] args) {
print("list = " + list);
// Collections.disjoint(c1,c2):当两个集合没有相同元素时返回true. disjoint == 互斥,不相交的;
// Collections.singletonList("Four"): 产生不可变的Set, List, Map, 它们都只包含基于给定参数的内容而形成的单一项;
print("Collections.disjoint(list, Collections.singletonList(\"Four\")) = " + Collections.disjoint(list, Collections.singletonList("Four")));
// Collections.max() 求最大元素 (默认字符大小写敏感)
print("Collections.max(list) = " + Collections.max(list));
// Collections.min() 求最小元素 (默认字符大小写敏感)
print("Collections.min(list) = " + Collections.min(list));
// Collections.max(list, String.CASE_INSENSITIVE_ORDER)) 在不考虑字母大小写敏感的基础上求最大元素;
print("Collections.max(list, String.CASE_INSENSITIVE_ORDER) = " + Collections.max(list, String.CASE_INSENSITIVE_ORDER));
// Collections.min(list, String.CASE_INSENSITIVE_ORDER)) 在不考虑字母大小写敏感的基础上求最小元素;
print("Collections.min(list, String.CASE_INSENSITIVE_ORDER) = " + Collections.min(list, String.CASE_INSENSITIVE_ORDER));
// Arrays.asList() 产生是list大小是固定的
List sublist = Arrays.asList("Four five six".split(" "));
print("Arrays.asList(\"Four five six\".split(\" \")) = " + sublist);
// Collections.indexOfSubList(list, sublist) 返回sublist在list中第一次出现的位置,或者找不到时返回 -1;
print("Collections.indexOfSubList(list, sublist) = " + Collections.indexOfSubList(list, sublist)); // 返回3,注意
// Collections.lastIndexOfSubList(list, sublist) 返回sublist在list中最后一次出现的位置,或者找不到时返回 -1;
print("Collections.lastIndexOfSubList(list, sublist) = " + Collections.lastIndexOfSubList(list, sublist)); // 返回3,注意
// Collections.replaceAll(list, "one", "Yo"), 用 Yo 替换 list中的所有 one
Collections.replaceAll(list, "one", "Yo");
print("Collections.replaceAll(list, \"one\", \"Yo\"), list = " + list);
// Collections.reverse(list), 逆转list中所有元素的顺序
Collections.reverse(list);
print("Collections.reverse(list), list = " + list);
// Collections.rotate(list, 3); 所有元素向后移动 3个位置,并将末尾的元素循环移到前面去;
Collections.rotate(list, 3);
print("Collections.rotate(list, 3), list = " + list);
List source = Arrays.asList("in the matrix".split(" "));
print("Arrays.asList(\"in the matrix\".split(\" \")) = source = " + source);
// Collections.copy(list, source), 将source中的元素复制到list中(从位置0开始复制),若source元素数量小于list,则list后面的元素会保留;
Collections.copy(list, source);
print("Collections.copy(list, source), list = " + list);
// Collections.swap(list, i, j), 交换list中 位置i 和位置j 的元素
Collections.swap(list, 0, list.size() - 1);
print("Collections.swap(list, 0, list.size() - 1), list = " + list);
// Collections.shuffle(list, new Random(47)), 随机改变指定列表的顺序, 也可以不指定 Random,而使用默认的Random
Collections.shuffle(list, new Random(47));
print("Collections.shuffle(list, new Random(47)), list = " + list);
// Collections.fill(list, "pop"), 用 pop 替换list中的所有元素;
Collections.fill(list, "pop");
print("Collections.fill(list, \"pop\"), list = " + list);
// Collections.frequency(list, "pop"),返回list中 等于 pop 的元素个数
print("Collections.frequency(list, \"pop\") = " + Collections.frequency(list, "pop"));
// Collections.nCopies(3, "snap"), 返回大小为3的 且大小和值均不可改变的List, 所有元素都引用 snap;
List dups = Collections.nCopies(3, "snap");
print("Collections.nCopies(3, \"snap\") = dups = " + dups);
// Collections.disjoint(list, dups) 两个集合如果不相交,没有交集,返回true, 否则返回false
print("Collections.disjoint(list, dups) = " + Collections.disjoint(list, dups));
print("Collections.disjoint(list, dups), list = " + list);
// Collections.enumeration(dups), 为参数dups 生成一个 旧式 枚举类
Enumeration e = Collections.enumeration(dups);
print("Enumeration e = Collections.enumeration(dups), e= ");
Vector v = new Vector();
while (e.hasMoreElements()) {
String s = e.nextElement();
print(s);
v.addElement(s); // 把元素插入 vector
}
// Converting an old-style Vector to a List via an Enumeration:
// 通过一个老式枚举类 把一个老式 Vector 转换为 List
ArrayList arrayList = Collections.list(v.elements());
print("ArrayList arrayList = Collections.list(v.elements()), arrayList: " + arrayList);
}
}
/*
list = [one, Two, three, Four, five, six, one]
Collections.disjoint(list, Collections.singletonList("Four")) = false
Collections.max(list) = three
Collections.min(list) = Four
Collections.max(list, String.CASE_INSENSITIVE_ORDER) = Two
Collections.min(list, String.CASE_INSENSITIVE_ORDER) = five
Arrays.asList("Four five six".split(" ")) = [Four, five, six]
Collections.indexOfSubList(list, sublist) = 3
Collections.lastIndexOfSubList(list, sublist) = 3
Collections.replaceAll(list, "one", "Yo"), list = [Yo, Two, three, Four, five, six, Yo]
Collections.reverse(list), list = [Yo, six, five, Four, three, Two, Yo]
Collections.rotate(list, 3), list = [three, Two, Yo, Yo, six, five, Four]
Arrays.asList("in the matrix".split(" ")) = source = [in, the, matrix]
Collections.copy(list, source), list = [in, the, matrix, Yo, six, five, Four]
Collections.swap(list, 0, list.size() - 1), list = [Four, the, matrix, Yo, six, five, in]
Collections.shuffle(list, new Random(47)), list = [six, matrix, the, Four, Yo, five, in]
Collections.fill(list, "pop"), list = [pop, pop, pop, pop, pop, pop, pop]
Collections.frequency(list, "pop") = 7
Collections.nCopies(3, "snap") = dups = [snap, snap, snap]
Collections.disjoint(list, dups) = true
Collections.disjoint(list, dups), list = [pop, pop, pop, pop, pop, pop, pop]
Enumeration e = Collections.enumeration(dups), e=
snap
snap
snap
ArrayList arrayList = Collections.list(v.elements()), arrayList: [snap, snap, snap]
*/ // 荔枝-List的排序和查询
public class ListSortSearch {
public static void main(String[] args) {
// Utilities.list: static List list = Arrays.asList("one Two three Four five six one".split(" "));
List list = new ArrayList(Utilities.list);
list.addAll(Utilities.list);
print("list = " + list);
// Collections.shuffle(list, new Random(47)), 随机改变list的元素顺序
Collections.shuffle(list, new Random(47));
print("Collections.shuffle(list, new Random(47)), list = " + list);
// Use a ListIterator to trim off the last elements:
// 移除位置10(包括0)之后的元素
ListIterator it = list.listIterator(10);
while (it.hasNext()) {
it.next(); // 删除元素时,先执行 next() 然后执行 remove()。 因为next()中, cursor = i;cursor = i+1; return elementData[lastRet = i]
it.remove(); // remove() 方法中: 先 ArrayList.this.remove(lastRet), cursor = lastRet,lastRet = -1
}
print("Trimmed: " + list);
// Collections.sort(list), list排序;(默认大小写敏感)
Collections.sort(list);
print("Collections.sort(list); list = " + list);
String key = list.get(7);
// Collections.binarySearch(list, key), 通过二叉查找找出 元素key的位置(默认大小写敏感)
int index = Collections.binarySearch(list, key);
print("Location of " + key + " is " + index + ", list.get(" + index + ") = " + list.get(index));
// Collections.sort(list, String.CASE_INSENSITIVE_ORDER); list排序(大小写不敏感)
Collections.sort(list, String.CASE_INSENSITIVE_ORDER);
print("Collections.sort(list, String.CASE_INSENSITIVE_ORDER), list = " + list);
key = list.get(7);
// Collections.binarySearch(list, key), 通过二叉查找找出 元素key的位置(大小写不敏感)
index = Collections.binarySearch(list, key, String.CASE_INSENSITIVE_ORDER);
print("Location of " + key + " is " + index + ", list.get(" + index
+ ") = " + list.get(index));
}
}
/*
list = [one, Two, three, Four, five, six, one, one, Two, three, Four, five, six, one]
Collections.shuffle(list, new Random(47)), list = [Four, five, one, one, Two, six, six, three, three, five, Four, Two, one, one]
Trimmed: [Four, five, one, one, Two, six, six, three, three, five]
Collections.sort(list); list = [Four, Two, five, five, one, one, six, six, three, three]
Location of six is 7, list.get(7) = six
Collections.sort(list, String.CASE_INSENSITIVE_ORDER), list = [five, five, Four, one, one, six, six, three, three, Two]
Location of three is 7, list.get(7) = three
*/ // ArrrayList$Itr.next() remove() 方法源码
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}// 荔枝-创建只读容器,方法列表如下:
/*
Collections.unmodifiableCollection(new ArrayList())
Collections.unmodifiableList(new ArrayList())
Collections.unmodifiableSet(new HashSet())
Collections.unmodifiableSortedSet(new TreeSet()) // TreeSet 继承了 SortedSet
Collections.unmodifiableMap(new HashMap())
Collections.unmodifiableSortedMap(new TreeMap()) // TreeMap 继承了 SortedMap
*/
public class ReadOnly {
static Collection data = new ArrayList(Countries.names(6));
public static void main(String[] args) {
// Collections.unmodifiableCollection(new ArrayList(data)), 创建只读的 ArrayList
Collection c = Collections.unmodifiableCollection(new ArrayList(data));
print(c); // Reading is OK
// ! c.add("one"); // Can't change it
// Collections.unmodifiableList(new ArrayList(data)), 创建只读的 ArrayList
List a = Collections.unmodifiableList(new ArrayList(data));
ListIterator lit = a.listIterator();
print(lit.next()); // Reading is OK
// ! lit.add("one"); // Can't change it
// Collections.unmodifiableSet(new HashSet(data)), 创建只读的 HashSet
Set s = Collections.unmodifiableSet(new HashSet(data));
print(s); // Reading is OK
// ! s.add("one"); // Can't change it
// For a SortedSet:
// Collections.unmodifiableSortedSet(new TreeSet(data)), 创建只读的 TreeSet
Set ss = Collections.unmodifiableSortedSet(new TreeSet(data));
print("Set ss = Collections.unmodifiableSortedSet(new TreeSet(data)), ss = " + ss);
// Collections.unmodifiableMap(), 创建只读的 HashMap
Map m = Collections
.unmodifiableMap(new HashMap(Countries
.capitals(6)));
print(m); // Reading is OK
// ! m.put("Ralph", "Howdy!");
// For a SortedMap:
// Collections.unmodifiableSortedMap(),创建只读的TreeMap
Map sm = Collections
.unmodifiableSortedMap(new TreeMap(Countries
.capitals(6)));
}
}
/*
Collection c = Collections.unmodifiableCollection(new ArrayList(data)) c = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
ALGERIA
[BENIN, BOTSWANA, ANGOLA, BURKINA FASO, ALGERIA, BURUNDI]
Set ss = Collections.unmodifiableSortedSet(new TreeSet(data)), ss = [ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI]
{BENIN=Porto-Novo, BOTSWANA=Gaberone, ANGOLA=Luanda, BURKINA FASO=Ouagadougou, ALGERIA=Algiers, BURUNDI=Bujumbura}
*/ // Collections 创建不可修改容器的方法源码
public static Collection unmodifiableCollection(Collection c) {
return new UnmodifiableCollection<>(c);
}
// Collection$UnmodifiableCollection.java 源码
static class UnmodifiableCollection implements Collection, Serializable {
private static final long serialVersionUID = 1820017752578914078L;
final Collection c;
UnmodifiableCollection(Collection c) {
if (c==null)
throw new NullPointerException();
this.c = c;
}
public int size() {return c.size();}
public boolean isEmpty() {return c.isEmpty();}
public boolean contains(Object o) {return c.contains(o);}
public Object[] toArray() {return c.toArray();}
public T[] toArray(T[] a) {return c.toArray(a);}
public String toString() {return c.toString();}
public Iterator iterator() {
return new Iterator() {
private final Iterator i = c.iterator();
public boolean hasNext() {return i.hasNext();}
public E next() {return i.next();}
public void remove() {
throw new UnsupportedOperationException();
}
@Override
public void forEachRemaining(Consumer action) {
// Use backing collection version
i.forEachRemaining(action);
}
};
}
public static List unmodifiableList(List list) {
return (list instanceof RandomAccess ?
new UnmodifiableRandomAccessList<>(list) :
new UnmodifiableList<>(list));
}
public static Set unmodifiableSet(Set s) {
return new UnmodifiableSet<>(s);
}
public static SortedSet unmodifiableSortedSet(SortedSet s) {
return new UnmodifiableSortedSet<>(s);
}
public static Map unmodifiableMap(Map m) {
return new UnmodifiableMap<>(m);
}
public static SortedMap unmodifiableSortedMap(SortedMap m) {
return new UnmodifiableSortedMap<>(m);
} // 荔枝-Collection 或 Map的同步机制, Colletions 自动同步整个容器的方法列表
// Collections.synchronizedCollection(new ArrayList())
// Collections.synchronizedList(new ArrayList())
// Collections.synchronizedSet(new HashSet())
// Collections.synchronizedMap(new HashMap())
// Collections.synchronizedSortedMap(new TreeMap())
public class Synchronization {
public static void main(String[] args) {
Collection c = Collections.synchronizedCollection(new ArrayList());
List list = Collections.synchronizedList(new ArrayList());
Set s = Collections.synchronizedSet(new HashSet());
Set ss = Collections.synchronizedSortedSet(new TreeSet());
Map m = Collections.synchronizedMap(new HashMap());
Map sm = Collections.synchronizedSortedMap(new TreeMap());
}
} // /:~ // Collections 自动同步整个容器的方法源码
public static Collection synchronizedCollection(Collection c) {
return new SynchronizedCollection<>(c);
}
public static List synchronizedList(List list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
public static Set synchronizedSet(Set s) {
return new SynchronizedSet<>(s);
}
public static SortedSet synchronizedSortedSet(SortedSet s) {
return new SynchronizedSortedSet<>(s);
}
public static Map synchronizedMap(Map m) {
return new SynchronizedMap<>(m);
}
public static SortedMap synchronizedSortedMap(SortedMap m) {
return new SynchronizedSortedMap<>(m);
} // 荔枝-快速报错机制
public class FailFast {
public static void main(String[] args) {
Collection c = new ArrayList();
Iterator it = c.iterator();
c.add("An object");
try {
System.out.println("before it.next()");
String s = it.next(); // it.next() 抛出异常
System.out.println("after it.next()");
} catch (ConcurrentModificationException e) {
System.out.println(e);
}
}
}
/*
before it.next()
java.util.ConcurrentModificationException
*/ // ArrayList$Itr.java 源码荔枝
private class Itr implements Iterator {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
// ...
}
class VeryBig {
private static final int SIZE = 10000;
private long[] la = new long[SIZE];
private String ident;
public VeryBig(String id) {
ident = id;
}
public String toString() {
return ident;
}
protected void finalize() {
System.out.println("Finalizing " + ident);
}
}
public class References {
private static ReferenceQueue rq = new ReferenceQueue();
public static void checkQueue() {
Reference inq = rq.poll();
if (inq != null)
System.out.println("In queue: " + inq.get());
}
public static void main(String[] args) {
int size = 10;
// Or, choose size via the command line:
if (args.length > 0)
size = new Integer(args[0]);
LinkedList> sa = new LinkedList>();
for (int i = 0; i < size; i++) {
sa.add(new SoftReference(new VeryBig("Soft " + i), rq));
System.out.println("Just created: " + sa.getLast());
checkQueue();
}
LinkedList> wa = new LinkedList>();
for (int i = 0; i < size; i++) {
wa.add(new WeakReference(new VeryBig("Weak " + i), rq));
System.out.println("Just created: " + wa.getLast());
checkQueue();
}
SoftReference s = new SoftReference(new VeryBig("Soft"));
WeakReference w = new WeakReference(new VeryBig("Weak"));
System.gc();
LinkedList> pa = new LinkedList>();
for (int i = 0; i < size; i++) {
pa.add(new PhantomReference(new VeryBig("Phantom " + i),rq));
System.out.println("Just created: " + pa.getLast());
checkQueue();
}
}
}
/*
Just created: java.lang.ref.SoftReference@15db9742
Just created: java.lang.ref.SoftReference@6d06d69c
Just created: java.lang.ref.SoftReference@7852e922
Just created: java.lang.ref.SoftReference@4e25154f
Just created: java.lang.ref.SoftReference@70dea4e
Just created: java.lang.ref.SoftReference@5c647e05
Just created: java.lang.ref.SoftReference@33909752
Just created: java.lang.ref.SoftReference@55f96302
Just created: java.lang.ref.SoftReference@3d4eac69
Just created: java.lang.ref.SoftReference@42a57993
Just created: java.lang.ref.WeakReference@75b84c92
Just created: java.lang.ref.WeakReference@6bc7c054
Just created: java.lang.ref.WeakReference@232204a1
Just created: java.lang.ref.WeakReference@4aa298b7
Just created: java.lang.ref.WeakReference@7d4991ad
Just created: java.lang.ref.WeakReference@28d93b30
Just created: java.lang.ref.WeakReference@1b6d3586
Just created: java.lang.ref.WeakReference@4554617c
Just created: java.lang.ref.WeakReference@74a14482
Just created: java.lang.ref.WeakReference@1540e19d
Finalizing Weak
Finalizing Weak 9
Finalizing Weak 8
Finalizing Weak 7
Finalizing Weak 6
Finalizing Weak 5
Finalizing Weak 4
Finalizing Weak 3
Finalizing Weak 2
Finalizing Weak 1
Finalizing Weak 0
Just created: java.lang.ref.PhantomReference@677327b6
In queue: null
Just created: java.lang.ref.PhantomReference@14ae5a5
In queue: null
Just created: java.lang.ref.PhantomReference@7f31245a
In queue: null
Just created: java.lang.ref.PhantomReference@6d6f6e28
In queue: null
Just created: java.lang.ref.PhantomReference@135fbaa4
In queue: null
Just created: java.lang.ref.PhantomReference@45ee12a7
In queue: null
Just created: java.lang.ref.PhantomReference@330bedb4
In queue: null
Just created: java.lang.ref.PhantomReference@2503dbd3
In queue: null
Just created: java.lang.ref.PhantomReference@4b67cf4d
In queue: null
Just created: java.lang.ref.PhantomReference@7ea987ac
In queue: null
*/ class Element {
private String ident; // 缩进量
public Element(String id) {
ident = id;
}
public String toString() {
return ident;
}
// 重写 hashCode() 方法
public int hashCode() {
return ident.hashCode();
}
// 重写 equals() 方法
public boolean equals(Object r) {
return r instanceof Element && ident.equals(((Element) r).ident);
}
protected void finalize() { // 垃圾回收时调用的方法
System.out.println("Finalizing " + getClass().getSimpleName() + " "
+ ident);
}
}
class Key extends Element {
public Key(String id) {
super(id);
}
}
class Value extends Element {
public Value(String id) {
super(id);
}
}
public class CanonicalMapping {
public static void main(String[] args) {
int size = 1000;
// Or, choose size via the command line:
if (args.length > 0)
size = new Integer(args[0]);
Key[] keys = new Key[size];
// WeakHashMap 允许垃圾回收器 自动清理键值;
WeakHashMap map = new WeakHashMap();
for (int i = 0; i < size; i++) {
Key k = new Key(Integer.toString(i));
Value v = new Value(Integer.toString(i));
if (i % 3 == 0)
keys[i] = k; // 把序号为3的倍数的位置上的元素保存为真实引用
map.put(k, v);
}
System.gc(); // 垃圾回收
}
}
/* 可以看到垃圾回收器 仅仅回收 不存在 keys[] 数组中的对象;(因为不存在keys[] 数组,该引用就不是真实引用,是不可获得的引用,可以回收)
Finalizing Key 476
Finalizing Key 245
Finalizing Key 244
Finalizing Key 242
Finalizing Key 241
Finalizing Key 239
Finalizing Key 238
Finalizing Key 236
Finalizing Key 235
Finalizing Key 233
Finalizing Key 232
Finalizing Key 230
Finalizing Key 229
Finalizing Key 227
Finalizing Key 226
*/ // Vector 和 Enumeration 的荔枝
public class Enumerations {
public static void main(String[] args) {
// Vector 相当于 ArrayList, Vector 是 老式的 ArrayList,不推荐 Vector
Vector v = new Vector(Countries.names(10));
// Enumeration枚举类 相当于迭代器 Iterator, Enumeration 是老式的 Iterator,不推荐 Enumeration
Enumeration e = v.elements(); // 生成 Enumeration 对象;
// Enumeration 的列表遍历方式:
while (e.hasMoreElements())
System.out.print(e.nextElement() + ", ");
// Collections.enumeration(new ArrayList()), 把 ArrayList的Iterator迭代器 转换为 Enumeration 枚举类;
e = Collections.enumeration(new ArrayList());
}
}
/* Collections.enumeration() 方法源码
public static Enumeration enumeration(final Collection c) {
return new Enumeration() { // 静态内部类
private final Iterator i = c.iterator();
public boolean hasMoreElements() {
return i.hasNext();
}
public T nextElement() {
return i.next();
}
};
}
*/
/*
ALGERIA, ANGOLA, BENIN, BOTSWANA, BURKINA FASO, BURUNDI, CAMEROON, CAPE VERDE, CENTRAL AFRICAN REPUBLIC, CHAD,
*/ public
class Stack extends Vector { // Stack 实现源码
/**
* Creates an empty Stack.
*/
public Stack() {
} // 枚举类
enum Month {
JANUARY, FEBRUARY, MARCH, APRIL, MAY, JUNE, JULY, AUGUST, SEPTEMBER, OCTOBER, NOVEMBER
}
// 荔枝-实现栈的多种方式演示(但绝不能使用 Stack ,在生产过程中)
public class Stacks {
public static void main(String[] args) {
// 第1种方式,通过 Stack
Stack stack = new Stack();
for (Month m : Month.values())
stack.push(m.toString()); // 进栈操作
print("stack = " + stack);
// Treating a stack as a Vector:
stack.addElement("The last line");
print("element 5 = " + stack.elementAt(5));
print("popping elements:");
while (!stack.empty())
printnb(stack.pop() + " ");
// 第2种方式,通过 LinkedList
LinkedList lstack = new LinkedList();
for (Month m : Month.values())
lstack.addFirst(m.toString());
System.out.println();
print("lstack = " + lstack);
while (!lstack.isEmpty())
printnb(lstack.removeFirst() + " ");
// Using the Stack class from
// the Holding Your Objects Chapter:
// 第3种方式: 通过 基于 LinkedList 的 Stack 来实现
net.mindview.util.Stack stack2 = new net.mindview.util.Stack();
for (Month m : Month.values())
stack2.push(m.toString());
System.out.println();
print("stack2 = " + stack2);
while (!stack2.empty())
printnb(stack2.pop() + " ");
}
}
/*
stack = [JANUARY, FEBRUARY, MARCH, APRIL, MAY, JUNE, JULY, AUGUST, SEPTEMBER, OCTOBER, NOVEMBER]
element 5 = JUNE
popping elements:
The last line NOVEMBER OCTOBER SEPTEMBER AUGUST JULY JUNE MAY APRIL MARCH FEBRUARY JANUARY
lstack = [NOVEMBER, OCTOBER, SEPTEMBER, AUGUST, JULY, JUNE, MAY, APRIL, MARCH, FEBRUARY, JANUARY]
NOVEMBER OCTOBER SEPTEMBER AUGUST JULY JUNE MAY APRIL MARCH FEBRUARY JANUARY
stack2 = [NOVEMBER, OCTOBER, SEPTEMBER, AUGUST, JULY, JUNE, MAY, APRIL, MARCH, FEBRUARY, JANUARY]
NOVEMBER OCTOBER SEPTEMBER AUGUST JULY JUNE MAY APRIL MARCH FEBRUARY JANUARY
*/ // 荔枝-Bits 插入 和 数据演示
public class Bits {
public static void printBitSet(BitSet b) {
print("bits: " + b);
StringBuilder bbits = new StringBuilder();
for (int j = 0; j < b.size(); j++)
bbits.append(b.get(j) ? "1" : "0");
print("bit pattern: " + bbits);
}
public static void main(String[] args) {
Random rand = new Random(47);
// Take the LSB of nextInt():
byte bt = (byte) rand.nextInt();
BitSet bb = new BitSet();
for (int i = 7; i >= 0; i--) // 每个byte 1个字节 = 8位,所以需要8次位操作
if (((1 << i) & bt) != 0)
bb.set(i);
else
bb.clear(i);
print("byte value: " + bt); // byte value: -107
printBitSet(bb); // bits: {0, 2, 4, 7} bit pattern: 1010100100000000000000000000000000000000000000000000000000000000
System.out.println();
short st = (short) rand.nextInt();
BitSet bs = new BitSet();
for (int i = 15; i >= 0; i--) // 每个short 2个字节 = 16位,所以需要16次位操作
if (((1 << i) & st) != 0)
bs.set(i);
else
bs.clear(i);
print("short value: " + st); //short value: 1302
printBitSet(bs); //bits: {1, 2, 4, 8, 10} bit pattern: 0110100010100000000000000000000000000000000000000000000000000000
System.out.println(); //
int it = rand.nextInt();
BitSet bi = new BitSet();
for (int i = 31; i >= 0; i--) // 每个 int 4个字节 = 32位
if (((1 << i) & it) != 0)
bi.set(i);
else
bi.clear(i);
print("int value: " + it); // int value: -2014573909
printBitSet(bi); // bits: {0, 1, 3, 5, 7, 9, 11, 18, 19, 21, 22, 23, 24, 25, 26, 31}
// bit pattern: 1101010101010000001101111110000100000000000000000000000000000000
System.out.println(); //
// Test bitsets >= 64 bits:
BitSet b127 = new BitSet();
b127.set(127);
print("set bit 127: " + b127); // set bit 127: {127}
BitSet b255 = new BitSet(65);
b255.set(255);
print("set bit 255: " + b255); // set bit 255: {255}
BitSet b1023 = new BitSet(512);
b1023.set(1023);
b1023.set(1024);
print("set bit 1023: " + b1023); // set bit 1023: {1023, 1024}
}
}
/*
byte value: -107
bits: {0, 2, 4, 7}
bit pattern: 1010100100000000000000000000000000000000000000000000000000000000
short value: 1302
bits: {1, 2, 4, 8, 10}
bit pattern: 0110100010100000000000000000000000000000000000000000000000000000
int value: -2014573909
bits: {0, 1, 3, 5, 7, 9, 11, 18, 19, 21, 22, 23, 24, 25, 26, 31}
bit pattern: 1101010101010000001101111110000100000000000000000000000000000000
set bit 127: {127}
set bit 255: {255}
set bit 1023: {1023, 1024}
*/