机器学习中的数学(上)
上篇博文介绍了《机器学习之支持向量机》后发现利用到了梯度、凸优化、拉格朗日对偶性等数学问题。而且凸优化是本科非数学专业学不到的科目,所以这篇博文就要和大家分享一下机器学习中常用的数学概念。
博文重点:
- 线性代数。
- 凸优化。
- 概率论(机器学习中的数学(中))。
- 机器学习中常用的不等式(机器学习中的数学(下))。
1、线性代数
这部分介绍一些机器学习中常用的线性代数知识点包括向量的范数和矩阵的范数及其相关性质。
1.1 向量和范数
这一部分将通过 H \mathbb H H来定义一个维数可能是无限的向量空间。
1.1.1 范数
定义1.1: 映射 Φ : H → R + \Phi:\mathbb H\rightarrow\mathbb R_+ Φ:H→R+被认为是 H \mathbb H H上的范数如果它满足如下公理:
- 非负性(definiteness): ∀ x ∈ H , Φ ( x ) = 0 ⇔ x = 0 , Φ ( x ) > 0 ⇔ x ≠ 0 \forall \mathbf x\in\mathbb H,\Phi(\mathbf x)=0\Leftrightarrow\mathbf x=\mathbf 0,\Phi(\mathbf x)>0\Leftrightarrow\mathbf x\ne0 ∀x∈H,Φ(x)=0⇔x=0,Φ(x)>0⇔x=0;
- 同质性(齐次性)(homogeneity): ∀ x ∈ H , ∀ α ∈ R , Φ ( α x ) = ∣ α ∣ Φ ( x ) \forall \mathbf x\in\mathbb H,\forall{\alpha}\in{\mathbb{R}},\Phi(\alpha\mathbf{x})=|\alpha|\Phi(\mathbf x) ∀x∈H,∀α∈R,Φ(αx)=∣α∣Φ(x);
- 三角不等式(triangle inequality): ∀ x , y ∈ H , Φ ( x + y ) ≤ Φ ( x ) + Φ ( y ) \forall \mathbf x,\mathbf y\in\mathbb H,\Phi(\mathbf x+\mathbf y)\le\Phi(\mathbf x)+\Phi(\mathbf y) ∀x,y∈H,Φ(x+y)≤Φ(x)+Φ(y)。
对任意 p ≥ 1 p\ge1 p≥1, L p L_p Lp范数可以通过下述定义:
∀ x ∈ R N , ∣ ∣ x ∣ ∣ p = ( ∑ j = 1 N ∣ x j ∣ p ) 1 / p . \forall{\mathbf x}\in{\mathbb R}^N,||\mathbf x||_p=\Big(\sum_{j=1}^N|x_j|^p\Big)^{1/p}. ∀x∈RN,∣∣x∣∣p=(j=1∑N∣xj∣p)1/p.
L 1 , L 2 L_1,L_2 L1,L2和 L ∞ L_\infty L∞范数是用的最多的范数,其中 ∣ ∣ x ∣ ∣ ∞ = max j ∈ [ N ] ∣ x j ∣ ||\mathbf x||_\infty=\max_{j\in[N]}|x_j| ∣∣x∣∣∞=maxj∈[N]∣xj∣。下述不等式都是成立的:
∣ ∣ x ∣ ∣ 2 ≤ ∣ ∣ x ∣ ∣ 1 ≤ N ∣ ∣ x ∣ ∣ 2 ∣ ∣ x ∣ ∣ ∞ ≤ ∣ ∣ x ∣ ∣ 2 ≤ N ∣ ∣ x ∣ ∣ ∞ ∣ ∣ x ∣ ∣ ∞ ≤ ∣ ∣ x ∣ ∣ 1 ≤ N ∣ ∣ x ∣ ∣ ∞ . ||\mathbf x||_2\le||\mathbf x||_1\le\sqrt{N}||\mathbf x||_2\\ ||\mathbf x||_\infty\le||\mathbf x||_2\le\sqrt{N}||\mathbf x||_\infty\\ ||\mathbf x||_\infty\le||\mathbf x||_1\le N||\mathbf x||_\infty. ∣∣x∣∣2≤∣∣x∣∣1≤N∣∣x∣∣2∣∣x∣∣∞≤∣∣x∣∣2≤N∣∣x∣∣∞∣∣x∣∣∞≤∣∣x∣∣1≤N∣∣x∣∣∞.
定义1.2:希尔伯特空间(Hilbert space): 希尔伯特空间是由向量空间的内积组成的 ⟨ ⋅ , ⋅ ⟩ \langle\cdot,\cdot \rangle ⟨⋅,⋅⟩,内积导出一个范数,定义如下:
∀ x ∈ H , ∣ ∣ x ∣ ∣ H = ⟨ x , x ⟩ . \forall\mathbf x\in\mathbb H,||\mathbf x||_{\mathbb H}=\sqrt{\langle\mathbf x,\mathbf x \rangle}. ∀x∈H,∣∣x∣∣H=⟨x,x⟩.
1.1.2 对偶范数(Dual norms)
定义1.3: 让 ∣ ∣ ⋅ ∣ ∣ ||\cdot|| ∣∣⋅∣∣表示一个在 R N \mathbb R^N RN上的范数。与 ∣ ∣ ⋅ ∣ ∣ ||\cdot|| ∣∣⋅∣∣相关的对偶范数 ∣ ∣ ⋅ ∣ ∣ ∗ ||\cdot||_\ast ∣∣⋅∣∣∗是如下定义:
∀ y ∈ R N , ∣ ∣ y ∣ ∣ ∗ = sup ∣ ∣ x ∣ ∣ = 1 ∣ ⟨ y ⋅ x ⟩ ∣ . \forall \mathbf y\in{\mathbb R^N},||\mathbf y||_\ast=\sup_{||\mathbf x||=1}|\langle \mathbf y\cdot\mathbf x\rangle|. ∀y∈RN,∣∣y∣∣∗=∣∣x∣∣=1sup∣⟨y⋅x⟩∣.
对任意的 p , q ≥ 1 p,q\ge1 p,q≥1是共轭的(conjugate)也就是 1 p + 1 q = 1 \frac{1}{p}+\frac{1}{q}=1 p1+q1=1,则有 L p L_p Lp和 L q L_q Lq范数互为对偶范数。一般来说, L 2 L_2 L2的对偶范数是 L 2 L_2 L2, L 1 L_1 L1的对偶范数是 L ∞ L_\infty L∞。
命题1.4:Hölder不等式: 让 p , q ≥ 1 p,q\ge1 p,q≥1是共轭的,即 1 p + 1 q = 1 \frac{1}{p}+\frac{1}{q}=1 p1+q1=1。对所有的 x , y ∈ R N x,y\in{\mathbb R}^N x,y∈RN,
∣ ⟨ x , y ⟩ ∣ ≤ ∣ ∣ x ∣ ∣ p ∣ ∣ y ∣ ∣ q , |\langle\mathbf x,\mathbf y\rangle|\le||\mathbf x||_p||\mathbf y||_q, ∣⟨x,y⟩∣≤∣∣x∣∣p∣∣y∣∣q,
当对于所有的 i ∈ [ N ] i\in{[N]} i∈[N]时, ∣ y i ∣ = ∣ x i ∣ p − 1 |y_i|=|x_i|^{p-1} ∣yi∣=∣xi∣p−1时,上式取等。
推论1.5:柯西-施瓦兹不等式(Cauchy-Schwarz inequality): 对所有的 x , y ∈ R N \mathbf x,\mathbf y\in{\mathbb R}^N x,y∈RN,
∣ ⟨ x , y ⟩ ∣ ≤ ∣ ∣ x ∣ ∣ 2 ∣ ∣ y ∣ ∣ 2 , |\langle\mathbf x,\mathbf y\rangle|\le||\mathbf x||_2||\mathbf y||_2, ∣⟨x,y⟩∣≤∣∣x∣∣2∣∣y∣∣2,当且仅当 x , y \mathbf x,\mathbf y x,y共线时,上式取等。
1.2 矩阵
对于 M ∈ R m × n \mathbf M\in\mathbb R^{m\times n} M∈Rm×n是一个 m m m行 n n n列的矩阵,定义 M i j \mathbf M_{ij} Mij是它的第 i i i行 j j j列的元素。对任意 m ≥ 1 m\ge1 m≥1,通过 I m \mathbf I_m Im表示 m m m维单位矩阵。
矩阵 M \mathbf M M的转置是 M ⊤ \mathbf M^\top M⊤,对所有的 ( i , j ) (i,j) (i,j)都有 ( M ⊤ ) i j = M j i (\mathbf M^\top)_{ij}=\mathbf M_{ji} (M⊤)ij=Mji。对任意的两个矩阵 M ∈ R m × n \mathbf M\in\mathbb R^{m\times n} M∈Rm×n和 N ∈ R n × p \mathbf N\in\mathbb R^{n\times p} N∈Rn×p, ( M N ) ⊤ = N ⊤ M ⊤ (\mathbf M\mathbf N)^\top=\mathbf N^\top\mathbf M^\top (MN)⊤=N⊤M⊤。
矩阵 M \mathbf M M的迹 Tr [ M ] = ∑ i = 1 N M i i \text{Tr}[\mathbf M]=\sum_{i=1}^N\mathbf M_{ii} Tr[M]=∑i=1NMii。对任意的两个矩阵 M ∈ R m × n \mathbf M\in\mathbb R^{m\times n} M∈Rm×n和 N ∈ R n × p \mathbf N\in\mathbb R^{n\times p} N∈Rn×p,都有 Tr [ M N ] = Tr [ N M ] \text{Tr}[\mathbf M\mathbf N]=\text{Tr}[\mathbf N\mathbf M] Tr[MN]=Tr[NM]成立。
满秩矩阵 M \mathbf M M的逆,定义为 M − 1 \mathbf M^{-1} M−1,满足 M M − 1 = M − 1 M = I \mathbf M\mathbf M^{-1}=\mathbf{M}^{-1}\mathbf{M}=\mathbf{I} MM−1=M−1M=I。
1.2.1 矩阵范数
矩阵范数是定义在 R m × n \mathbb R^{ m\times n} Rm×n上的范数,其中 m m m和 n n n是矩阵的维度。许多矩阵范数满足下列次乘法性质(相容性):
∣ ∣ M N ∣ ∣ ≤ ∣ ∣ M ∣ ∣ ⋅ ∣ ∣ N ∣ ∣ . ||\mathbf M\mathbf N||\le||\mathbf M||\cdot||\mathbf N||. ∣∣MN∣∣≤∣∣M∣∣⋅∣∣N∣∣.
由向量 p p p范数诱导的矩阵范数如下:
∣ ∣ M ∣ ∣ p = sup ∣ ∣ x ∣ ∣ p ≤ 1 ∣ ∣ M x ∣ ∣ p . ||\mathbf M||_p=\sup_{||\mathbf x||_p\le1}||\mathbf M\mathbf x||_{p}. ∣∣M∣∣p=∣∣x∣∣p≤1sup∣∣Mx∣∣p.
当 p = 2 p=2 p=2时被称为是谱范数( spectral norm),谱范数等于该矩阵的最大奇异值或者是 M ⊤ M \mathbf M^\top\mathbf M M⊤M的最大特征值的平方根:
∣ ∣ M ∣ ∣ 2 = σ 1 ( M ) = λ max ( M ⊤ M ) . ||\mathbf M||_2=\sigma_1(\mathbf M)=\sqrt{\lambda_{\max}(\mathbf M^\top\mathbf M)}. ∣∣M∣∣2=σ1(M)=λmax(M⊤M).
不是所有的范数都是向量诱导范数。Frobenius范数就是非诱导范数:
∣ ∣ M ∣ ∣ F = ( ∑ i = 1 m ∑ j = 1 n M i j 2 ) 1 / 2 . ||\mathbf M||_F=\Big(\sum_{i=1}^m\sum_{j=1}^n\mathbf M^2_{ij}\Big)^{1/2}. ∣∣M∣∣F=(i=1∑mj=1∑nMij2)1/2.
显然,当 M \mathbf M M是一个长度为 m n mn mn的向量时,此时的 F F F范数就是向量的 L 2 L_2 L2范数了。矩阵的 F F F范数和矩阵的迹的关系:
⟨ M , N ⟩ F = Tr [ M ⊤ N ] . \langle\mathbf M,\mathbf N\rangle_{F}=\text{Tr}[\mathbf M^\top\mathbf N]. ⟨M,N⟩F=Tr[M⊤N].
F F F范数与矩阵 M \mathbf M M奇异值的相关性:
∣ ∣ M ∣ ∣ F 2 = Tr [ M ⊤ M ] = ∑ i = 1 r [ σ i ( M ) ] 2 , ||\mathbf M||_{F}^2=\text{Tr}[\mathbf M^\top\mathbf M]=\sum_{i=1}^r[\sigma_i(\mathbf M)]^2, ∣∣M∣∣F2=Tr[M⊤M]=i=1∑r[σi(M)]2,其中 r r r是 M M M的秩。
对任意 j ∈ [ N ] j\in{[N]} j∈[N],让 M j \mathbf M_j Mj表示矩阵 M \mathbf M M的第 j j j列, M = [ M 1 ⋯ M n ] \mathbf M=[\mathbf M_1\cdots\mathbf M_n] M=[M1⋯Mn]。对任意 p , r ≥ 1 p,r\ge1 p,r≥1, M \mathbf M M的组范数(group norm ) L p , r L_{p,r} Lp,r是:
∣ ∣ M ∣ ∣ p , r = ( ∑ j = 1 n ∣ ∣ M ∣ ∣ p r ) 1 / r . ||\mathbf M||_{p,r}=\Big(\sum_{j=1}^n||\mathbf M||_{p}^r\Big)^{1/r}. ∣∣M∣∣p,r=(j=1∑n∣∣M∣∣pr)1/r.
使用最多的组范数是 L 2 , 1 L_{2,1} L2,1范数,如下定义:
∣ ∣ M ∣ ∣ 2 , 1 = ∑ i = 1 n ∣ ∣ M i ∣ ∣ 2 . ||\mathbf M||_{2,1}=\sum_{i=1}^n||\mathbf M_{i}||_{2}. ∣∣M∣∣2,1=i=1∑n∣∣Mi∣∣2.
就是矩阵每列作为向量的 L 2 L_2 L2范数的逐一求和。
1.2.2 奇异值分解(Singular value decomposition)
矩阵 M \mathbf M M的秩 r r r满足: r = rank ( M ) ≤ min ( m , n ) r=\text{rank}(\mathbf M)\le\min(m,n) r=rank(M)≤min(m,n)。矩阵的奇异值分解如下:
M = U M Σ M V M ⊤ . \mathbf M=\mathbf U_{M}\mathbf\Sigma_M\mathbf V_M^\top. M=UMΣMVM⊤.
其中,矩阵 Σ M = diag ( σ 1 , ⋯ , σ r ) \mathbf\Sigma_M=\text{diag}(\sigma_1,\cdots,\sigma_r) ΣM=diag(σ1,⋯,σr)是包含矩阵 M \mathbf M M的非零奇异值按照递减排列的对角阵,即 σ 1 ≥ ⋯ ≥ σ r > 0 \sigma_1\ge\cdots\ge\sigma_r>0 σ1≥⋯≥σr>0。矩阵 U M ∈ R m × r \mathbf U_M\in{\mathbb R^{m\times r}} UM∈Rm×r和 V M ∈ R n × r \mathbf V_M\in\mathbb R^{n\times r} VM∈Rn×r中的列向量是矩阵 M \mathbf M M的奇异值的左右奇异正交向量。通过 U k ∈ R m × k , k ≤ r \mathbf U_k\in{\mathbb R}^{m\times{k}},k\le r Uk∈Rm×k,k≤r来表示 M \mathbf M M的左奇异值向量。
投影到 U k \mathbf U_k Uk的正交映射可以写成 P U k = U k U k ⊤ \mathbf P_{U_k}=\mathbf U_k\mathbf U_k^\top PUk=UkUk⊤,并且 P U k \mathbf P_{U_k} PUk是对称半正定和幂等的,即 P U k 2 = P U k \mathbf P_{U_k}^2=\mathbf P_{ U_k} PUk2=PUk。矩阵 M \mathbf M M的右奇异值向量也是一样的。
对于 M \mathbf M M的广义逆矩阵或者是Moore-Penrose伪逆矩阵 M † \mathbf M^{\dagger} M†如下定义:
M † = U M Σ M † V M ⊤ , \mathbf M^\dagger=\mathbf U_M\Sigma_M^\dagger\mathbf V_M^\top, M†=UMΣM†VM⊤,
其中 Σ M † = ( σ 1 − 1 , ⋯ , σ r − 1 ) \Sigma_M^\dagger=(\sigma_1^{-1},\cdots,\sigma_r^{-1}) ΣM†=(σ1−1,⋯,σr−1),对任何 m × m m\times m m×m的满秩矩阵 M \mathbf M M,矩阵的伪逆矩阵就是矩阵的逆: M † = M − 1 \mathbf M^\dagger=\mathbf M^{-1} M†=M−1。
1.2.3 对称正半定矩阵(Symmetric positive semidefinite (SPSD) matrices)
定义7: 一个对称矩阵是 M ∈ R m × m \mathbf M\in\mathbb R^{m\times m} M∈Rm×m是半正定的,当且仅当,对所有的 x ∈ R m \mathbf x\in \mathbb R^m x∈Rm:
x ⊤ M x ≥ 0. \mathbf x^\top\mathbf{M}\mathbf{x}\ge0. x⊤Mx≥0.
当上式严格大于零时, M \mathbf M M是正定的。也可以说,当且仅当一个矩阵的特征值非负时, M \mathbf M M是对称正半定的。下述特点对任何对称半正定矩阵 M \mathbf M M均成立:
- 对某些矩阵 X \mathbf X X, M \mathbf M M可以分解成 M = X ⊤ X \mathbf M=\mathbf X^\top\mathbf X M=X⊤X。
- M \mathbf M M的左右奇异值向量是相同的,并且 M \mathbf M M的奇异值分解也是它的特征值分解。
- 任意矩阵 X = U X Σ X V X ⊤ \mathbf X=\mathbf U_X\mathbf\Sigma_X\mathbf V_X^\top X=UXΣXVX⊤的奇异值分解就是两个相关的对称正半定矩阵的奇异值分解:左奇异值向量是 X X ⊤ \mathbf X\mathbf X^\top XX⊤的特征向量,右奇异值向量就是 X ⊤ X \mathbf X^\top\mathbf X X⊤X的特征向量。并且 X \mathbf X X的非零奇异值是 X X ⊤ \mathbf X\mathbf X^\top XX⊤和 X ⊤ X \mathbf X^\top\mathbf X X⊤X非零特征值的平方根。
- X \mathbf X X的迹是它的奇异值的和, Tr [ M ] = ∑ i = 1 r σ i ( M ) \text{Tr}[\mathbf M]=\sum_{i=1}^r\sigma_i(\mathbf M) Tr[M]=∑i=1rσi(M),其中 rank ( M ) = r \text{rank}(\mathbf M)=r rank(M)=r。
2、凸优化(Convex Optimization)
这一小节介绍机器学习中常用的凸优化问题。
2.1 可微和无约束最优化(Differentiation and unconstrained optimization)
我们从一些基本的微分定义开始,这些定义是介绍费马定理和描述凸函数的一些性质所必要的准备。
定义2.1:梯度 令 f : X ⊆ R N → R f:\mathcal{X}\subseteq\mathbb R^N\rightarrow\mathbb R f:X⊆RN→R是一个可微函数。 f f f在 x ∈ X \mathbf x\in\mathcal{X} x∈X向量处的梯度表示为 ∇ f ( x ) \nabla f(\mathbf x) ∇f(x)并有如下定义:
∇ f ( x ) = [ ∂ f ∂ x 1 ( x ) ⋮ ∂ f ∂ x N ( x ) ] . \nabla f(\mathbf x)=\begin{bmatrix}\frac{\partial f}{\partial\mathbf x_1}(\mathbf x)\\\vdots\\\frac{\partial f}{\partial\mathbf x_N}(\mathbf x)\end{bmatrix}. ∇f(x)=⎣⎢⎡∂x1∂f(x)⋮∂xN∂f(x)⎦⎥⎤.
定义2.2: 海森(Hessian) 令 f : X ⊆ R N → R f:\mathcal{X}\subseteq\mathbb R^N\rightarrow\mathbb R f:X⊆RN→R是一个二阶可微函数。则 f f f在 x ∈ X \mathbf x\in\mathcal X x∈X处的海森矩阵是表示为 ∇ 2 f ( x ) \nabla^2f(\mathbf x) ∇2f(x) 的 R N × N \mathbb R^{N\times N} RN×N的矩阵,定义如下:
∇ 2 f ( x ) = [ ∂ 2 f ∂ x i ∂ x j ( x ) ] 1 ≤ i , j ≤ N . \nabla^2f(\mathbf x)=\Big[\frac{\partial^2f}{\partial \mathbf x_i\partial\mathbf x_j}(\mathbf x)\Big]_{1\le i,j\le N}. ∇2f(x)=[∂xi∂xj∂2f(x)]1≤i,j≤N.
接下来,我们给出了无约束优化的一个经典结果。
定理2.3:费马定理(Fermat’s theorem) 令 f : X ⊆ R N → R f:\mathcal{X}\subseteq\mathbb R^N\rightarrow\mathbb R f:X⊆RN→R是一个可微函数。如果 x ∗ ∈ X \mathbf x^\ast\in\mathcal{X} x∗∈X是 f f f的一个局部极值,则 ∇ f ( x ∗ ) = 0 \nabla f(\mathbf x^\ast)=0 ∇f(x∗)=0,也就是说, x ∗ \mathbf x^\ast x∗是一个驻点(stationary point) 。
2.2 凸性(Convexity)
这一部分将要介绍凸集和凸函数的概念。凸函数在机器学习算法的设计和分析中起着重要的作用,部分原因是凸函数的局部极小值就是全局最小值。因此,一个假设的特点是通过凸优化寻找到的局部最小值往往很好理解,而对于一些非凸优化问题可能会有大量的局部最小值没有明显特征的假设可以学习。
定义2.4:凸集 一个集合 X ⊆ R N \mathcal X\subseteq \mathbb R^N X⊆RN被认为是凸的,如果任意两个点 x , y ∈ X \mathbf x,\mathbf y\in\mathcal X x,y∈X,区间 [ x , y ] ⊆ X [\mathbf x,\mathbf y]\subseteq\mathcal X [x,y]⊆X,满足
{ α x + ( 1 − α ) y : 0 ≤ α ≤ 1 } ⊆ X . \{\alpha\mathbf{x}+(1-\alpha)\mathbf y:0\le\alpha\le1\}\subseteq\mathcal X. {αx+(1−α)y:0≤α≤1}⊆X.
具体地说,在欧氏空间中,凸集是对于集合内的每一对点,连接该对点的直线段上的每个点也在该集合内。
下面的引理阐述了在凸集上保持凸性的几种操作。这些将有助于证明本节的几个后续结果。
引理 2.5 凸集的一些操作 :
- 令集合 { C i } i ∈ I \{\mathcal{C}_i\}_{i\in{I}} {Ci}i∈I是凸集,则集合任意部分 ⋂ i ∈ I C i \bigcap_{i\in{I}}\mathcal C_i ⋂i∈ICi也是凸集。
- 令集合 C 1 \mathcal{C}_1 C1和 C 2 \mathcal{C}_2 C2是凸集,则它们的和 C 1 + C 2 = { x 1 + x 2 : x 1 ∈ C 1 , x 2 ∈ C 2 } \mathcal{C}_1+\mathcal{C}_2=\{x_1+x_2:x_1\in\mathcal{C}_1,x_2\in\mathcal{C}_2\} C1+C2={x1+x2:x1∈C1,x2∈C2}也是凸集。
- 令集合 C 1 \mathcal{C}_1 C1和 C 2 \mathcal{C}_2 C2是凸集,则它们叉积( cross-product)( C 1 × C 2 \mathcal{C}_1\times\mathcal{C}_2 C1×C2)也是凸的(叉积: a × b = ∣ a ∣ ⋅ ∣ b ∣ ⋅ sin θ \mathbf a\times\mathbf b=|\mathbf a|\cdot|\mathbf b|\cdot\sin\theta a×b=∣a∣⋅∣b∣⋅sinθ)。
- 凸集 C \mathcal C C的任何投影也是凸的。
定义2.6:凸包(Convex hull) 一系列点 X ∈ R N \mathcal{X}\in{\mathbb{R}^N} X∈RN的凸包 conv ( X ) \text{conv}(\mathcal{X}) conv(X)是包含 X \mathcal{X} X的最小凸集,等价于如下定义:
conv ( X ) = { ∑ i = 1 m α i x i : m ≥ 1 , ∀ i ∈ [ m ] , x i ∈ X , α i > 0 , ∑ i = 1 m α i = 1 } . \text{conv}(\mathcal X)=\Big\{\sum_{i=1}^m\alpha_i\mathbf x_i:m\ge1,\forall i\in{[m]},\mathbf x_i\in\mathcal X,\alpha_i>0,\sum_{i=1}^m\alpha_i=1\Big\}. conv(X)={i=1∑mαixi:m≥1,∀i∈[m],xi∈X,αi>0,i=1∑mαi=1}.
让 Epi f \text{Epi}\;f Epif表示 f : X → R f:\mathcal X\rightarrow\mathbb R f:X→R的epigraph ,也就是一系列的点在函数图像的上面: { ( x , y ) : x ∈ X , y ≥ f ( x ) } \{(x,y):x\in\mathcal X,y\ge f(x)\} {(x,y):x∈X,y≥f(x)}。
定义2.7:凸函数(Convex function) 令 X \mathcal X X表示凸集。函数 f : X → R f:\mathcal X\rightarrow\mathbb R f:X→R是凸集当且仅当 Epi f \text{Epi}\;f Epif是凸集,或者对所有 x , y ∈ X \mathbf x,\mathbf y\in\mathcal X x,y∈X和 α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1],
f ( α x + ( 1 − α y ) ) ≤ α f ( x ) + ( 1 − α ) f ( y ) . f(\alpha\mathbf x+(1-\alpha\mathbf y))\le\alpha{f}(\mathbf x)+(1-\alpha)f(\mathbf y). f(αx+(1−αy))≤αf(x)+(1−α)f(y).
当上式 x ≠ y \mathbf x\ne\mathbf y x=y时, f f f是严格凸函数。 f f f是(严格)凹函数当 − f -f −f是(严格)凸函数。下图是一个简单的凸凹函数的例子。凸函数也可以用它们的一阶或二阶微分来表示。
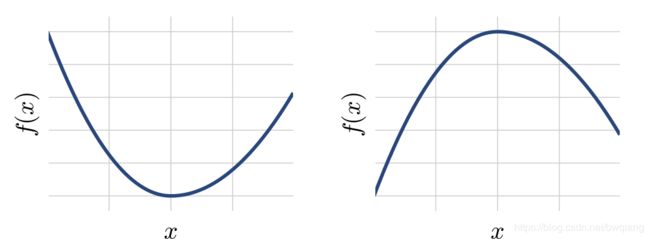
上图:(左)凸和(右)凹函数的例子。注意,在凸函数上两点之间绘制的任何线段都位于函数图形的上方,而在凹函数上两点之间绘制的任何线段都位于函数图形的下方。
定理2.8: 令 f f f是可微函数, f f f是凸的当且仅当 dom ( f ) \text{dom}(f) dom(f)是凸的,并且下述不等式成立:
∀ x , y ∈ dom ( f ) , f ( y ) − f ( x ) ≥ ∇ f ( x ) ⋅ ( y − x ) . \forall\mathbf x,\mathbf y\in{\text{dom}}(f),f(\mathbf y)-f(\mathbf{x})\ge\nabla{f}(\mathbf x)\cdot(\mathbf y-\mathbf x). ∀x,y∈dom(f),f(y)−f(x)≥∇f(x)⋅(y−x).
下图展示了上述不等式的性质:对于一个凸函数,超平面在 x \mathbf x x处的切线总是在函数图像的下方。
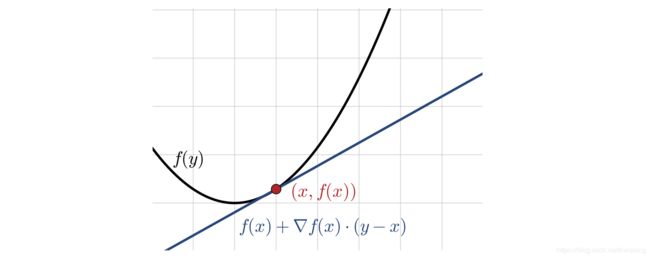
定理2.9: 令 f f f为二次可微函数, f f f是凸的当且仅当 dom f \text{dom}f domf是凸的并且它的海森矩阵是正半定的:
∀ x ∈ dom ( f ) , ∇ 2 f ( x ) ≥ 0. \forall \mathbf x\in\text{dom}(f),\nabla^2f(\mathbf x) \ge0. ∀x∈dom(f),∇2f(x)≥0.
如果一个对称矩阵的所有特征值都是非负的,那么它就是半正定的。那么当 f f f是标量时,这个定理表明 f f f是凸的当且仅当它的二阶导数总是非负的,即对于所有 x ∈ dom ( f ) , f ′ ′ ( x ) ≥ 0 x\in\text{dom}(f),f^{\prime\prime}(x)\ge0 x∈dom(f),f′′(x)≥0。
例子2.10: 线性函数(Linear functions)任何线性函数 f f f既是凸又是凹的,因为根据线性方程的定义,定义2.7对于 f f f和 − f -f −f都成立。
例子2.11: 二次函数(Quadratic functions) 函数 f : x ↦ x 2 f:x\mapsto x^2 f:x↦x2是定义在 R \mathbb R R上的凸函数,因为它是二次可微的并且对于所有 x ∈ R x\in\mathbb R x∈R, f ′ ′ ( x ) = 2 > 0 f^{\prime\prime}(x)=2>0 f′′(x)=2>0。
例子2.12:范数(Norms) 由范数的齐次性和三角不等式性,定义在凸集 X \mathcal X X上的任意范数 ∣ ∣ ⋅ ∣ ∣ ||\cdot|| ∣∣⋅∣∣是凸的。对所有的 α ∈ [ 0 , 1 ] , x , y ∈ X \alpha\in[0,1],\mathbf x,\mathbf y\in\mathcal X α∈[0,1],x,y∈X,我门可以写成
∣ ∣ α x + ( 1 − α ) y ∣ ∣ ≤ ∣ ∣ α x ∣ ∣ + ∣ ∣ ( 1 − α ) y ∣ ∣ = α ∣ ∣ x ∣ ∣ + ( 1 − α ) ∣ ∣ y ∣ ∣ . ||\alpha\mathbf x+(1-\alpha)\mathbf y||\le||\alpha\mathbf x||+||(1-\alpha)\mathbf y||=\alpha||\mathbf x||+(1-\alpha)||\mathbf y||. ∣∣αx+(1−α)y∣∣≤∣∣αx∣∣+∣∣(1−α)y∣∣=α∣∣x∣∣+(1−α)∣∣y∣∣.
定理2.13:琴生不等式(Jensen’s inequality) 令 X \mathbf X X是来自取值为一个非空凸集 C ⊆ R N \mathcal C\subseteq\mathbb R^N C⊆RN并且其有限期望是 E [ X ] \mathbb E[\mathbf X] E[X]的随机变量并且 f f f是定义在 C \mathcal{C} C上的可测凸函数。则 E [ X ] \mathbb E[\mathbf X] E[X]属于凸集 C \mathcal C C并且 E [ X ] \mathbb E[\mathbf X] E[X]是有限的,则下述不等式成立:
f ( E [ X ] ) ≤ E [ f ( X ) ] . f(\mathbb E[\mathbf X])\le\mathbb E[f(\mathbf X)]. f(E[X])≤E[f(X)].
2.3 约束最优化(Constrained optimization)
我们现在定义一个一般的约束优化问题和凸约束优化问题的具体性质。
定义2.14:约束最优化问题(Constrained optimization problem) 令 X ⊆ R N \mathcal X\subseteq\mathbb R^N X⊆RN并对所有的 i ∈ [ m ] i\in[m] i∈[m], f , g i : X → R f,g_i:\mathcal X\rightarrow\mathbb R f,gi:X→R。则约束最优化问题是如下形式:
min x ∈ X f ( x ) subjext to : g i ( x ) ≤ 0 , ∀ i ∈ { 1 , ⋯ , m } . \min_{\mathbf x\in\mathcal X}f(\mathbf x)\\\text{subjext to}:g_i(\mathbf x)\le0,\forall i\in\{1,\cdots,m\}. x∈Xminf(x)subjext to:gi(x)≤0,∀i∈{1,⋯,m}.
这个一般公式不做任何凸性假设,并且可以用等式约束加以扩充。与稍后介绍的相关问题相比,它被称为原始问题(primal problem)。我们将用 p ∗ p^\ast p∗来表示目标函数的最佳值。
对于任何 x ∈ X \mathbf x\in\mathcal X x∈X,我们将用 g ( x ) g(\mathbf x) g(x)表示向量 ( g 1 ( x ) , ⋯ , g m ( x ) ) ⊤ (g_1(\mathbf x),\cdots,g_m(\mathbf x))^\top (g1(x),⋯,gm(x))⊤。因此,约束可以写成 g ( x ) ≤ 0 g(\mathbf x)\le0 g(x)≤0。对于任何约束优化问题,我们可以把在分析问题或与另一个相关的优化问题中起重要作用的拉格朗日函数(Lagrange function)联系起来。
定义2.15:拉格朗日(Lagrangian) 与一般约束最优化问题相关的拉格朗日函数在 X ∈ R + \mathcal X\in\mathbb R_+ X∈R+的定义如下:
∀ x ∈ X , ∀ α ≥ 0 , L ( x , α ) = f ( x ) + ∑ i = 1 m α i g i ( x ) . \forall\mathbb x\in\mathcal X,\forall\alpha\ge0,\;\;\;\mathcal L(\mathbf x,\alpha)=f(\mathbf x)+\sum_{i=1}^m\alpha_ig_i(\mathbf x). ∀x∈X,∀α≥0,L(x,α)=f(x)+i=1∑mαigi(x).
注意,对于凸优化问题,等式约束函数 g ( x ) g(\mathbf x) g(x)必须是仿射函数,因为无论是 g ( x ) g(\mathbf x) g(x)和 − g ( x ) -g(\mathbf x) −g(x)都需要是凸的。
定义2.16:对偶函数(Dual function) 与约束优化问题相关的(拉格朗日)对偶函数定义如下:
∀ α > 0 , F ( α ) = inf x ∈ X L ( x , α ) = inf x ∈ X ( f ( x ) + ∑ i = 1 m α i g i ( x ) ) . \forall\alpha>0,F(\alpha)=\inf_{\mathbf x\in\mathcal X}\mathcal L(\mathbf x,\alpha)=\inf_{\mathbf x\in\mathcal X}(f(\mathbf x)+\sum_{i=1}^m\alpha_ig_i(\mathbf x)). ∀α>0,F(α)=x∈XinfL(x,α)=x∈Xinf(f(x)+i=1∑mαigi(x)).
注意 F F F经常是凹函数,因为关于 α \alpha α的拉格朗日函数是线性的,因为下确界保留凹性。我们进一步观察到
∀ α ≥ 0 , F ( α ) ≤ p ∗ , \forall\alpha\ge0,F(\alpha)\le p^\ast, ∀α≥0,F(α)≤p∗,
因为对于任何的 x \mathbf x x, f ( x ) + ∑ i = 1 m α i g i ( x ) ≤ f ( x ) f(\mathbf x)+\sum_{i=1}^m\alpha_ig_i(\mathbf x)\le f(\mathbf x) f(x)+∑i=1mαigi(x)≤f(x)。对偶函数自然会导致下述优化问题。
定义2.17:对偶问题(Dual problem) 与对偶(优化)问题相关联的约束优化问题是
max α F ( α ) subject to : α ≥ 0. \max_{\alpha}F(\mathbf \alpha)\\\text{subject to}:\alpha\ge0. αmaxF(α)subject to:α≥0.
对偶问题总是凸优化问题(最大化凹问题)。令 d ∗ d^\ast d∗表示最优解,下述不等式成立:
d ∗ ≤ p ∗ . d^\ast\le p^\ast. d∗≤p∗.
上式是弱对偶问题。它们的差值是 p ∗ − d ∗ p^\ast- d^\ast p∗−d∗,也被称作是对偶差(duality gap)。上式取等时,称为强对偶问题。
如果需要深入研究凸优化等问题,推荐Stephen boyd的《凸优化》,下篇更新《机器学习中的数学(中)》,to be continued…