FastBFT共识协议:Scalable Byzantine Consensus via Hardware-assisted Secret Sharing
文章目录
- 摘要
- 1.介绍(INTRODUCTION)
- 2.基础(PRELIMINARIES)
- 2.1状态机复制(State Machine Replication (SMR))
- 2.2 Practical Byzantine Fault Tolerance (PBFT)
- 2.3优化常见案例(Optimizing for the Common Case)
- 2.4使用硬件安全机制(Using Hardware Security Mechanisms)
- 2.5聚合消息(Aggregating Messages)
- 3. FastBFT概述(FASTBFT OVERVIEW)
- 4. FASTBFT:详细设计(FASTBFT: DETAILED DESIGN)
- 4.1 TEE托管的功能(TEE-hosted Functionality)
- 4.2正常情况下的操作(Normal-case Operation)
- 4.3故障检测(Failure Detection)
- 4.4视图切换(View-change)
- 4.5回退协议:具有消息聚合的经典BFT(Fallback Protocol: classical BFT with message aggregation)
- 5. FASTBFT的正确性(CORRECTNESS OF FASTBFT)
- 5.1安全性(Safety)
- 5.2活性(Liveness)
- 6.设计选择(DESIGN CHOICES)
- 6.1虚拟计数器(Virtual Counter)
- 6.2 BFT A la Carte
- 7.评价(EVALUATION)
- 7.1性能评价:设置和方法(Performance Evaluation: Setup and Methodology)
- 7.2性能评价:结果(Performance Evaluation: Results)
- 7.3 Security Considerations(安全性考虑)
- 8.相关工作(RELATED WORK)
- 9.总结和未来的工作(CONCLUSION AND FUTURE WORK)
作者




摘要
对区块链技术的兴趣激增,重新激发了对有效的拜占庭共识方案的探索。特别是,区块链社区一直在寻找将传统的拜占庭容错(BFT)协议有效地整合到区块链共识层中的方法,允许各种金融机构安全地就交易顺序达成一致。然而,现有的BFT协议由于其O(n2) 消息复杂度而只能扩展到数十个节点。
在本文中,我们提出了FastBFT,一种快速且可扩展的BFT协议。FastBFT的核心是一种新颖的消息聚合技术(novel message aggregation technique),它将基于硬件的可信执行环境(TEE)与轻量级秘密共享相结合。结合这种技术与其他几种优化(即乐观执行(optimistic execution),树形拓扑(tree topology)和故障检测),即使对于大规模网络,FastBFT也能实现低延迟和高吞吐量。通过系统分析和实验,我们证明了FastBFT比以前的BFT协议具有更好的可扩展性和性能。
Index Terms—Blockchain, Byzantine fault-tolerance, state machine replication, distributed systems, trusted component.
1.介绍(INTRODUCTION)
拜占庭容错(BFT)协议尚未在现实世界中得到大规模部署。这有几个潜在的原因,包括当前BFT协议的效率和可扩展性差,更重要的是,在维护良好的数据中心(well-maintained data centers)中,拜占庭式故障通常不被认为是一个主要问题。因此,像谷歌[7]和亚马逊[38]那样的现有商业系统依赖于较弱的崩溃容错变体(weaker crash fault tolerant variants)(例如,Paxos [25]和Raft [32])。
最近对区块链技术的兴趣为BFT协议提供了新的动力。区块链是分布式共识的关键推动因素,用作数字货币(例如比特币)和其他应用程序的公共账本。比特币的区块链依赖于众所周知的工作量证明(PoW)机制,以确保交易顺序和正确性的概率一致性保证。PoW目前占现有数字货币总市场份额的90%以上。(例如,Bitcoin,Litecoin, DogeCoin, Ethereum)然而,比特币的PoW因其巨大的能源浪费和较低的交易吞吐量(每秒约7次交易)[14]而受到严厉批评。
为了弥补这些限制,研究人员和从业人员正在研究BFT协议与区块链一致性的整合,使金融机构和供应链管理合作伙伴能够就交换信息的顺序和正确性达成一致。这代表了将BFT协议集成到现实世界系统中的第一次机会。例如,IBM的Hyperledger / Fabric区块链[17]目前依赖PBFT [5]达成共识。虽然PBFT可以实现比比特币共识层[42]更高的吞吐量,但到目前为止,它无法与现有支付方式的交易量相匹配(例如,Visa每秒处理数万笔交易[41])。此外,PBFT只能扩展到几十个节点,因为它需要交换O(n2)(规模的)消息以在n个服务器之间就单个操作达成共识[5]。因此,提高BFT协议的可扩展性和性能对于确保其在现有工业区块链解决方案中的实际部署是至关重要的。
在本文中,我们提出了FastBFT,一种快速且可扩展的BFT协议。FastBFT的核心是一种新颖的消息聚合技术,它将基于硬件的可信执行环境(例如,英特尔SGX)与轻量级秘密共享相结合。这种聚合将消息复杂度从O(n2) 降低到O(n) [37]。与先前的方案不同,FastBFT中的消息聚合不需要任何公钥操作(例如,多重签名),因此显著降低了计算/通信开销。FastBFT通过在树拓扑中排列节点(arranging nodes in a tree topology)来进一步平衡计算和通信负载,从而使服务器间的通信和消息聚合沿着树的边缘进行(take place along edges of the tree)。FastBFT采用乐观BFT范式(optimistic BFT paradigm)[9],只需要一个节点子集来主动运行协议。最后,我们使用一种简单的故障检测(failure detection)机制,使FastBFT可以有效地处理非主节点故障(non-primary faults)。
我们的实验表明,与我们评估的其他BFT协议相比,FastBFT的吞吐量要大得多[22],[24],[40]。随着节点数量的增加,与其他BFT协议相比,FastBFT的吞吐量下降速度要慢得多。这使得FastBFT成为下一代区块链系统的理想共识层候选 - 例如,假设1 MB blocks和250字节交易记录(如在比特币中),FastBFT可以每秒处理超过100,000笔交易。
在FastBFT中,我们针对如何选择和使用构建块(the building blocks)(例如,消息聚合技术或通信拓扑)做出了特定的设计选择。可替代的设计选择(Alternative design choices)将产生不同的BFT变体,其特征在于效率和弹性之间的各种权衡(tradeoff)。我们通过比较这些变体的框架来捕获这种权衡。
总之,我们做出以下贡献:
● 我们提出FastBFT,一种快速且可扩展的BFT协议(第3节和第4节)。
● 我们描述了一个框架,它捕获了一组重要的设计选择(design choices),并允许我们将FastBFT置于许多可能的BFT变体(包括以前提出的和新的变体)的上下文中(in the context)(第6节)。
● 我们给出了FastBFT的完整实现,并对FastBFT与几种BFT变体进行了系统的性能分析。我们的结果表明,FastBFT在效率(延迟和吞吐量)和可扩展性方面优于其他变体(第7节)。
2.基础(PRELIMINARIES)
在本节中,我们将描述我们解决的问题,概述已知的BFT协议和现有的优化。
2.1状态机复制(State Machine Replication (SMR))
SMR [36]是一种分布式计算原语,用于实现容错服务,其中系统状态在不同节点上复制,称为“副本”(Ss)。客户端(Cs)向Ss发送请求,期望Ss执行相同的请求操作顺序(即,维持共同的状态)。然而,一些Ss可能有故障,它们的故障模式可能是崩溃或拜占庭(crash or Byzantine)(即,任意偏离协议[26])。容错SMR必须确保两个正确性保证:
● Safety: 所有非故障副本以相同的顺序(即共识)执行请求,并且
● Liveness: 客户最终会收到对其请求(客户端自己的请求)的回复。
Fischer-Lynch-Paterson(FLP)不可能[13]证明在异步通信模型中无法确定性地实现容错,其中不能假设传输延迟的边界(bounds)。
2.2 Practical Byzantine Fault Tolerance (PBFT)
几十年来,研究人员一直在努力克服(circumvent)FLP的不可能性。一种方法,PBFT[5],利用了弱同步(weak synchrony)假设,在这种假设下,保证消息在一定的时间限制之后传递(to be delivered)。
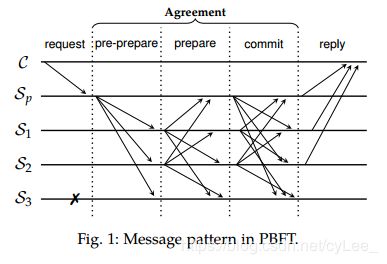
一个副本,即主节点Sp,决定客户端请求的顺序,并将它们转发给其他副本Sis。然后,所有副本一起运行三阶段(pre-prepare/prepare/commit)一致协议以同意请求的顺序。然后,每个副本处理每个请求并向相应的客户端发送响应。仅当客户端收到至少f + 1个一致回复时,客户端才接受结果。我们将包含这种消息模式(图1)的BFT协议称为经典BFT。Sp可能会出现故障:要么停止处理请求(崩溃),要么将矛盾的消息发送到不同的Sis(拜占庭)。后者被称为模棱两可(equivocation)。在检测到Sp有故障时,Sis触发view-change以选择新的主节点。弱同步假设保证了view-change最终会成功。
2.3优化常见案例(Optimizing for the Common Case)
由于在经典BFT中的协议是昂贵的,因此先前的工作已经尝试基于副本很少失败这一事实来提高性能。我们将这些工作分为两类:
Speculative(投机). Kotla等人提出了利用投机(speculation)提高性能的Zyzzyva[24]。与传统的BFT不同,Zyzzyva中的Sis按照Sp提出的顺序执行Cs请求,而不运行任何明确的一致协议(explicit agreement protocol)。执行完成后,所有副本都回复到C。如果Sp模棱两可(equivocates),C将收到不一致的回复。在这种情况下,C有助于纠正副本从其不一致状态恢复到公共状态(common state)。Zyzzyva可以将状态机复制的开销降低到接近最优。我们遵循此消息模式的BFT协议称为投机BFT(speculative BFT)。
Optimistic(乐观). Distler等人提出了资源有效的(resource-efficient)BFT(ReBFT)复制架构[9]。在通常情况下,只需要一部分副本来运行一致协议。其他副本被动地更新它们的状态,只有在一致协议失败时才会积极地参与其中。我们将遵循此消息模式的BFT协议称为乐观BFT(optimistic BFT)。请注意,此类协议与投机BFT不同,后者在常见情况下不需要明确协议。
2.4使用硬件安全机制(Using Hardware Security Mechanisms)
硬件安全机制已经在商用计算平台上广泛使用。可信执行环境(TEE)已经在移动平台上普及[12]。较新的TEE,如英特尔的SGX [19],[30]正在PC和服务器上部署。TEE提供受保护的内存和隔离的执行,以便常规操作系统或应用程序既不能控制也不能观察在其中存储或处理的数据。TEE还允许远程验证器(remote verifiers)通过远程认证(remote attestation)确定设备的当前配置和行为。换句话说,TEE只能崩溃而不能拜占庭。
以前的工作展示了如何使用硬件安全性来减少BFT协议的副本数量和/或通信阶段[6],[8],[22],[27],[39],[40]。例如,MinBFT [40]使用可信计数器服务改进了PBFT,以防止错误副本的模糊(equivocation)[6]。具体地说,每个副本的本地TEE维护一个惟一的、单调的和顺序计数器;每个消息都需要绑定到一个惟一的计数器值。由于TEE确保了计数器的单调性,因此副本不能将相同的计数器值分配给不同的消息。结果,所需副本的数量从3f + 1减少到2f + 1(其中f是可容忍故障的最大数量),并且通信阶段的数量从3减少到2(prepare/commit)。同样,MinZyzzyva使用TEE来减少Zyzzyva中的复本数量,但需要相同数量的通信阶段[40]。CheapBFT [22]在乐观的BFT协议中使用TEE。在没有故障的情况下,CheapBFT只需要f + 1个主动副本(active replicas)来同意并执行客户端请求。其他f个被动副本(passive replicas)只是通过处理由主动副本提供的状态更新来修改它们的状态。如果怀疑有错误行为,CheapBFT会触发转换协议(transition protocol)以激活被动副本,然后切换到MinBFT。
2.5聚合消息(Aggregating Messages)
BFT协议要求每个Si向所有(主动的)副本多播一条提交消息(multicast a commit message),以表明它同意Sp提出的顺序。这导致了O(n2) 的消息复杂度(图1)。一种自然的解决方案是使用消息聚合技术来组合来自多个副本的消息。通过这样做,每个Si仅需要发送和接收单个消息(a single message)。例如,集体签名(collective signing ,CoSi)[37]依赖于多重签名(multisignatures)来聚合消息。ByzCoin [23]使用它来提高PBFT的可扩展性。多重签名允许多个签名者在公共输入上生成紧凑的联合签名(produce a compact, joint signature on common input)。任何拥有聚合公钥的验证者都可以在固定时间内验证签名(in constant time)。
3. FastBFT概述(FASTBFT OVERVIEW)
在本节中,我们将在第4节中提供详细规范之前概述FastBFT。
System model. FastBFT的运行环境与第2.2节相同:它保证了异步网络中的安全性,但需要弱同步(weak synchrony)才能保持活性(liveness)。我们进一步假设每个副本都拥有一个基于硬件的TEE,它维护一个单调计数器(monotonic counter)和一个抗回滚内存(rollback-resistant memory)。TEE可以使用远程认证(remote attestation)相互验证,并在它们之间建立安全的通信通道[1]。我们假设故障副本可能是拜占庭,但TEE可能只会崩溃。
Strawman design(稻草人设计). 我们选择乐观范式(optimistic paradigm)(如CheapBFT [22]),其中f + 1个主动副本同意并执行请求,而其他f个被动副本只更新其状态。乐观范式在效率和弹性之间取得了很大的权衡(见第6节)。我们使用消息聚合(还有一个通信步骤)将消息复杂度降低到O(n):在commit期间,每个主动副本Si将其commit message直接发送到主节点Sp,而不是多播到所有副本。为了避免使用诸如多重签名之类的原语进行消息聚合所带来的开销,我们使用秘密共享进行聚合。我们协议的一个重要假设是秘密是一次性的(one-time)。为此,我们在FastBFT的设计中引入了额外的pre-processing阶段。图2描绘了FastBFT的整体消息模式。
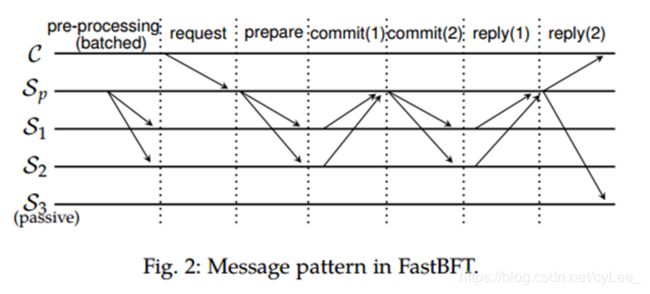
首先,考虑以下稻草人设计。在pre-processing阶段,Sp生成一组随机秘密并发布每个秘密的加密哈希(cryptographic hash)。然后,Sp将每个秘密分成一些份额,并向每个主动的Si发送一个份额。稍后,在prepare阶段,Sp将每个客户端请求绑定到先前共享的秘密。在commit阶段,每个主动的Si通过揭示其秘密的份额来表明其承诺(signals its commitment by revealing its share of the secret)。Sp收集所有此类份额以重建秘密,这代表所有副本的聚合承诺(aggregated commitment)。Sp将重构后的秘密多播给所有主动的Sis,后者可以根据相应的哈希对其进行验证。在reply阶段,相同的方法用于聚合来自所有主动的Si的回复消息:在验证秘密之后,Si将下一个秘密的共享信息透露给Sp, Sp将重新构造reply secret并将其返回给客户端以及所有被动副本。因此,客户端和被动副本只需要接收一个回复而不是f + 1个。Sp在reply消息中包含两个公开的秘密(opened secrets)及其哈希(在pre-processing阶段发布)。
Hardware assistance(硬件辅助). 稻草人设计显然是不安全的,因为知道秘密的Sp可以冒充任何Si 。我们通过在每个副本中使用TEE来解决这个问题。Sp中的TEE产生秘密,将它们拆分,并安全地将份传递给每个Si中的TEE。在commit期间,只有prepare消息正确时,每个Si的TEE才会将其份额释放给Si 。请注意,现在Sp如果没有从Sis收集到足够的份额,就无法重构这个秘密。
然而,由于秘密是在pre-processing期间产生的,因此故障的Sp可以通过对不同请求使用相同的秘密来模糊(equivocate)。为了解决这个问题,我们让Sp的TEE在pre-processing期间将秘密安全地绑定到计数器值(counter value),并且在prepare期间,将请求绑定到驻留在TEE内的单调计数器的新增值(the freshly incremented value of a TEE-resident monotonic counter)。这确保了每个特定秘密都绑定到单个请求(a single request)。复本的TEE跟踪Sp的最新计数器值,在每次成功处理请求后更新其记录。这里的关键要求是TEE既不会对不同的计数器值使用相同的秘密,也不会对不同的秘密使用相同的计数器值。为了检索其秘密的份额,Si必须向其本地TEE呈现具有正确计数器值的prepare消息。
除了维护和验证单调计数器,如现有的硬件辅助(hardware-assisted)BFT协议(因此,它需要n = 2 f + 1个副本来容忍f个(拜占庭)故障),FastBFT还使用TEE来生成和共享秘密。
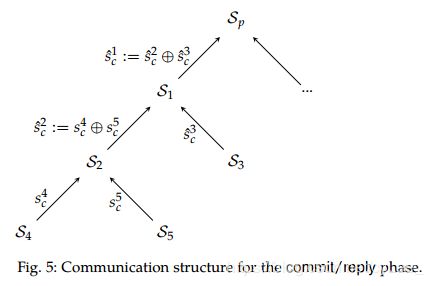
Communication topology(通信拓扑). 即使这种方法大大降低了消息的复杂度,但Sp仍然需要接收和聚合O(n)份额,这可能是一个瓶颈。为了解决这个问题,我们让Sp将主动的Sis组织成一个以自身为根的平衡树(we have Sp organize active Sis into a balanced tree rooted at itself),以分配通信和计算成本。份额以自底向上的方式沿着树传播(Shares are propagated along the tree in a bottom-up fashion):每个中间节点将其子节点的份额与其自己的份额聚合在一起;最后,Sp只需要接收和聚合一小部分恒定的份额(a small constant number of shares)。
Failure detection(故障检测). 最后,FastBFT采用[11]中的故障检测机制来容忍非主节点故障。请注意,故障节点可能只是崩溃或发送错误的份额。允许父节点将其直接子节点(且仅允许它们)标记为可能有故障,并向树发送可疑消息(sends a suspect message up the tree)。收到此消息后,Sp将被指控的副本(the accused replica)替换为被动副本,并将控告者(accuser)放在一个叶子中,这样它就不能继续指控(accuse)其他人。
4. FASTBFT:详细设计(FASTBFT: DETAILED DESIGN)
在本节中,我们提供了FastBFT的完整描述。我们根据需要引入符号(表1总结)。
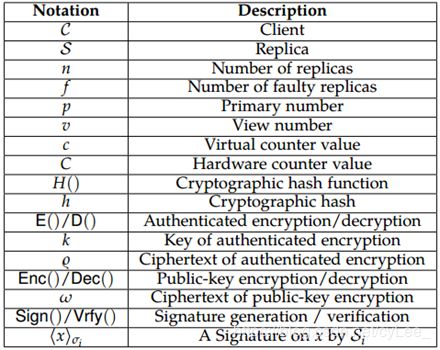
4.1 TEE托管的功能(TEE-hosted Functionality)
图3显示了FastBFT所需的TEE托管功能。每个TEE都配备了经过认证的密钥对,用于加密该TEE的数据(使用Enc())和生成签名(使用Sign())。主节点Sp的TEE维持值为clatest的单调计数器;其他副本Sis的TEE跟踪clatest和当前视图编号v(第3行)。Sp的TEE还跟踪每个当前主动的Si,密钥ki(第5行)和Sis的树形拓扑T(第6行)。主动的 Sis还会跟踪他们的kis(第8行)。接下来,我们描述每个TEE函数。




4.2正常情况下的操作(Normal-case Operation)
现在我们将副本正常情况下的操作描述为一个反应系统(reactive system)(图4)。为了简单起见,我们没有显式地显示签名验证(signature verifications),我们假设每个副本都验证作为输入接收到的任何签名。





4.3故障检测(Failure Detection)
与可以无成本(for free)容忍非主节点(non-primary)故障的经典BFT协议不同,乐观BFT协议通常需要转换(transitions)[22]或视图更改[28]。为了更有效地容忍非主节点故障,FastBFT利用了一种有效的故障检测机制。


如果沿同一路径存在多个故障节点,则上述方法只能在一轮内检测到其中一个节点。我们可以扩展这种方法,在一次故障检测之后,让Sp检查所有主动副本的正确性,从而允许在一轮内检测多个故障。
注意,f个故障副本可以利用故障检测机制触发一系列树重构(tree reconstructions)(即,导致拒绝服务DoS攻击)。在检测到的非主节点故障的数量超过一个阈值之后,Sp可以触发转换协议(transition protocol)[22]以回退到经典的BFT协议(参见第4.5节)。
4.4视图切换(View-change)



4.5回退协议:具有消息聚合的经典BFT(Fallback Protocol: classical BFT with message aggregation)
正如我们在第4.3节中所提到的,在故障检测到阈值数目后(after a threshold number of failure detections),Sp发起一个与第4.4节中view-change协议完全相同的transition协议,在不改变主节点(without changing the primary)的情况下,就当前状态达成一致,切换到下一个“view”。接下来,所有副本运行以下经典BFT作为回退(as fallback),而不是运行正常情况下的操作。考虑到永久性故障(permanent faults)很少发生,FastBFT会在固定的时间内(a fixed duration)保持这种回退模式(fallback mode),在此之后,它将尝试恢复到正常状态。在切换回正常情况的操作之前,Sp通过广播消息并请求响应来检查副本的状态。通过这种方式,Sp可以避免选择崩溃的副本来使其变为主动的(to be active)。然后,Sp启动一个类似于view-change的协议,但将其自身设置为主节点。如果所有f + 1个潜在主动的副本都参与视图更改协议,则它们将成功切换回正常情况操作。



回退协议不依赖于树结构,因为树中的故障节点可以使其整个子树“有故障” - 因此回退协议不再能够免费(for free)容忍非主节点故障(non-primary faults)。另一方面,如果在回退协议中发生主节点故障,则副本执行与正常情况相同的view-change协议。
5. FASTBFT的正确性(CORRECTNESS OF FASTBFT)
在本节中,我们为FastBFT的正确性提供了一个非正式的论证。一个正式的(理想情况下是机器检查过的(machine-checked))安全性和活力的证明留给未来的工作。
5.1安全性(Safety)
我们展示如果正确的副本执行了一系列操作 ,那么所有其他正确的副本执行相同的操作序列或其前缀。
Lemma 1(引理1). 在视图v中,如果正确的副本执行具有计数器值 (c, v) 的操作op,则没有正确的副本使用该计数器值执行不同的操作op’ 。
Proof(证明). 假设两个正确的本Si和Sj执行具有相同计数器值 (c, v) 的两个不同操作opi和opj 。有以下情况:


因此,我们得出结论,在一个view中不可能以相同的计数器值执行两个不同的操作。
Lemma 2(引理2). 如果正确的副本在视图v中执行操作op,那么没有执行op,正确的副本就不能更改为新视图(no correct replica will change to a new view without executing op)。
Proof(证明). 假设正确的副本Si在视图v中执行op,而另一个正确的副本Sj在不执行op的情况下更改到下一个视图。我们区分两种情况:
因此,我们得出结论,如果正确的副本在视图v中执行操作op,则所有正确的副本将在更改为新视图之前执行op 。

5.2活性(Liveness)
当C接收到回复时,我们说C的请求完成。我们表明正确的C请求的操作最终会完成。我们说如果主节点是正确的,则视图是稳定的。
Lemma 3(引理3). 在一个稳定的view中,正确的客户端请求的操作op将会完成。
Proof(证明). 由于主Sp是正确的,因此它将发送有效的PREPARE消息。如果所有主动副本都正常运行,则请求将完成。但是,故障副本Sj可能会崩溃或回复错误的份额。这种行为将由其父节点检测到(图4,第20行),并且Sj将由被动副本替代(图4,第33行)。如果已达到故障检测的阈值数量,则正确的副本将启动view-change 以切换到fallback协议。view-change会成功,因为主节点是正确的。在fallback协议中,只要非主节点故障的数量最多为f,请求就会完成。

在情况2和3中,新的view-change会触发系统再次到达(reach)上述三种情况之一。回想一下,在弱同步假设下,消息保证在多项式时间内传递。因此,系统最终将到达情况1,即,会达到稳定的视图。

6.设计选择(DESIGN CHOICES)
6.1虚拟计数器(Virtual Counter)
在整篇论文中,我们假设每个TEE都维持一个单调计数器。实现单调计数器的最简单方法是直接使用底层TEE平台支持的硬件单调计数器(例如,MinBFT使用TPM [16]计数器,CheapBFT使用FPGA实现的计数器,英特尔SGX平台还支持硬件中的单调计数器[20])。但是,由于效率低,这些硬件计数器造成了BFT协议的瓶颈:例如,当使用SGX计数器时,读操作需要60-140 ms,递增操作需要80-250 ms,具体取决于平台[29]。
另一种方法是让TEE在易失性内存(volatile memory)中维护一个虚拟计数器;但每次系统重启后都会重置。这可以通过在重启之前在持久存储上记录计数器值来天真地(naively)解决,但是这个解决方案遭受回滚攻击[29]:一个有故障的Sp可以调用两次request_counter函数,每次调用之后都会重新启动机器。因此,Sp的TEE将在持久存储上记录两个计数器值。当TEE请求最新的备份计数器值(the latest backup counter value)时,Sp可以丢弃第二个值。在这种情况下,Sp可以成功地模糊(equivocate)。
为了解决这个问题,我们从[35]借用了这个想法:当TEE想要记录其状态(例如,准备机器重启)时,它增加其硬件计数器C并将 (C + 1, c, v) 存储在持久存储器上。在读取其状态时,当且仅当当前硬件计数器值与存储的计数器值匹配时,TEE才接受虚拟计数器值。如果TEE终止而没有递增和保存硬件计数器值(称为计划外重启(unscheduled reboot)),它将发现不匹配,并拒绝从此以后处理任何进一步的请求。他完全避免了模糊;故障副本只能通过导致计划外重启来实现DoS。
在FastBFT中,我们将计划外重启视为崩溃故障。为了限制系统中的故障数量,我们提供了reset_counter函数,以允许崩溃(或重启)的副本重新加入系统。即,在计划外重启之后,Si可以广播REJOIN消息。收到此消息的副本将使用已签名的计数器值(signed counter value)以及自上一个检查点以来的消息日志进行回复(类似于VIEW-CHANGE消息)。当且仅当TEE从不同副本接收到f + 1个一致的(consistent)已签名的计数器值时(图3中的第59行),TEE才可以重置计数器值并再次工作。但是,故障的Sp可能会滥用此功能来模糊(equivocate):请求已签名的计数器值,强制执行计划外重启,然后广播REJOIN消息以重置其计数器值。在这种情况下,Sp可以成功地将两个不同的消息与相同的计数器值相关联。为了防止这种情况,我们让所有副本拒绝为计划外重启的主节点提供已签名的计数器值,以便Sp只有在视图更改后成为正常副本时才能重置其计数器值。
6.2 BFT A la Carte
在本节中,我们将重新审视我们在FastBFT中的设计选择,展示不同的协议,这些协议可能来自不同的设计选择,并从两个维度对它们进行定性比较:
● Performance:在通常情况下,完成一个请求所需的延迟(越低越好)和系统的峰值吞吐量(越高越好)。通常(但不总是),表现出低延迟的方案也具有高吞吐量;
● Resilience(弹性):容忍非主节点故障所需的成本。(所有BFT协议都需要view-change才能从主节点故障中恢复,这会在不同协议中产生类似的成本。)
图7(a) 描绘了用于构造BFT协议的设计选择;图7(b) 比较了有趣的组合。下面,我们将讨论不同可能的(different possible)BFT协议,在图7(b)中非正式地讨论它们的性能,弹性和位置。
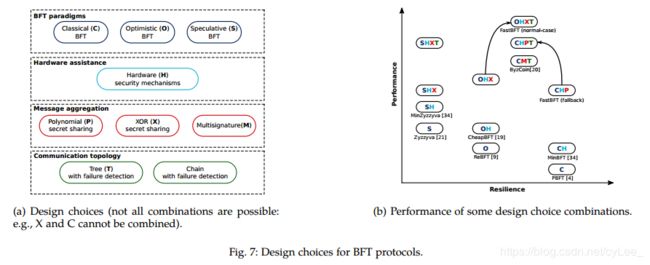
BFT paradigms(范例). 如第2节所述,我们区分了三种可能的范例:经典(C)(例如,PBFT [5]),乐观(O)(例如,Distler等人[9])和投机(S)(例如, Zyzzyva [24])。显然,投机BFT协议(S)提供了最佳性能,因为它避免了all-to-all多播。然而,投机性执行甚至不能容忍一个崩溃错误,而且需要客户端帮助从不一致的状态中恢复。在现实世界的场景中,客户端可能既没有激励也没有资源(例如,轻量级客户端)这样做。如果(故障)客户端没有报告该不一致(fails to report the inconsistency),那么状态与其他状态不同的副本可能不会发现这一点。此外,如果出现不一致,副本可能必须回滚一些执行,这使编程模型更复杂。因此,投机BFT在弹性方面表现最差。相反,经典BFT协议(C)可以免费容忍非主节点故障,但要求所有副本都参与协议阶段。通过这样做,这些协议实现了最佳的弹性,但代价是性能不佳。乐观BFT协议(O)实现了性能和弹性之间的权衡。它们只需要主动副本来执行一致协议,这显著降低了消息复杂性,但仍然需要all-to-all多播。虽然这些协议要求转换(transition)[22]或view-change[28]以容忍非主节点故障,但它们既不需要客户端支持也不需要任何回滚机制。
Hardware assistance. 硬件安全机制(H)可用于所有三种范例。例如,MinBFT [40]是利用硬件安全性(H)的经典(C)BFT;为了便于描述,我们说MinBFT属于CH系列。类似地,CheapBFT [22]是OH(即乐观+硬件安全),MinZyzzyva [40]是SH(即投机+硬件安全)。硬件安全机制提高了所有三种范例的性能(通过减少所需副本和/或通信阶段的数量),而不会影响弹性。
Message aggregation. 我们区分了基于多签名(M)[37]的消息聚合和基于秘密共享的消息聚合(如FastBFT中使用的消息聚合)。我们进一步将秘密共享技术分类为(更有效的)基于XOR(X)和(效率更低)基于多项式(P)。秘密共享技术仅适用于硬件辅助BFT协议(即,对CH,OH和SH)。在CH族中,仅基于多项式的秘密共享是适用的,因为经典BFT仅需要在commit和reply中来自阈值数量的副本(a threshold number of replicas)的响应(responses)。请注意,CHP是FastBFT的回退(fallback)协议。基于XOR的秘密共享可以与OH和SH一起使用。消息聚合显著提高了乐观和经典BFT协议的性能,但对于已经具有O(n) 消息复杂度的投机BFT几乎没有帮助。在添加消息聚合之后,乐观BFT协议(OHX)比投机协议(SHX)更有效,因为它们都具有O(n) 消息复杂性,但是OHX需要更少的副本来主动运行协议。
Communication topology(通信拓扑). 此外,我们可以使用更好的通信拓扑(例如,树)来提高效率。我们可以将具有故障检测(T)的树形拓扑应用于任何上述组合,例如CHPT,OHXT(其为FastBFT),SHXT和CMT(即ByzCoin [23])。树形拓扑可提高所有协议的性能。对于SHXT,弹性保持与以前相同,因为在出现故障时仍需要回滚。对于OHXT,弹性将得到改善,因为非主节点故障不再需要转换或view-change 。另一方面,对于CHPT,弹性几乎会降低到与OHXT相同的水平,因为树中的故障节点可以使其整个子树“有故障”,因此它不再能够免费容忍非主节点故障。链(chain)是BFT协议中广泛使用的另一种通信拓扑[2],[11]。它提供高吞吐量,但由于其O(n) 的通信步骤而导致大的延迟。其他通信拓扑可能提供更好的效率和/或弹性。我们将调查和比较作为未来的工作。
在图7(b)中,我们直观地总结了上述讨论。我们推测,使用硬件和消息聚合可以在不影响弹性的情况下弥合(bridge)乐观范例和投机范例之间的性能差距。对树形拓扑的依赖进一步增强了性能和弹性。在下一节中,我们通过实验确认这些猜想。
7.评价(EVALUATION)
在本节中,我们实现FastBFT,模拟正常情况(参见第4.2节)和回退协议(参见第4.5节),并将它们与Zyzzyva[24]、MinBFT[40]、CheapBFT[22]和XPaxos[28]的性能进行了比较。注意到回退协议被认为是FastBFT的最坏情况。
7.1性能评价:设置和方法(Performance Evaluation: Setup and Methodology)
我们的实现基于Golang。我们使用英特尔SGX提供硬件安全支持,并将FastBFT副本的TEE部分实现为SGX enclave。我们使用SHA256进行哈希,使用128位CMAC进行MAC,使用256位ECDSA进行客户端签名。我们将FastBFT中已提交秘密的大小设置为128位,并按照第6.1节中的描述实现单调计数器。
我们在一个私有网络上部署了我们的BFT实现,该网络由五个8 vCore Intel Xeon E3-1240组成,配备32 GB RAM和Intel SGX。所有BFT副本都在不同的进程中运行。在任何时候,我们都要平衡每台机器上运行的BFT副本的数量;通过将服务器故障阈值f从1更改为99,我们在5台机器上生成了最多298个进程。客户端运行在8 vCore Intel Xeon E3-1230上,配置了16GB RAM作为多线程。每台机器具有1 Gbps带宽,并且使用1 Gbps交换机桥接各种机器之间的通信。此设置模拟了真实的企业部署;例如,IBM计划在一个大型内部集群中部署他们的区块链平台[18],为相互不信任的各方提供服务(例如,使用云服务运营许可区块链的银行联盟)。
每个客户端在闭环中(in a closed loop)调用操作,即每个客户端最多可以有一个待处理操作。操作的延迟被度量为发出请求直到副本的响应被接受为止的时间;我们将吞吐量定义为系统在一秒钟内可以处理的操作数。我们根据服务器故障阈值f评估峰值吞吐量。我们还根据所获得的吞吐量评估了所研究的BFT协议的延迟。我们要求客户端发出back to back请求,即,一旦客户端接受了前一个请求的回复,就会发出下一个请求。然后,我们通过增加系统中的客户端数量来增加并发性,直到所有请求达到的聚合吞吐量饱和为止。在我们的实验中,我们将并发客户端的数量从1改为10,以测量延迟并找到峰值吞吐量。注意,图中的每个数据点平均超过1500个不同的测量值;在适当的情况下,我们包含相应的95%置信区间。
7.2性能评价:结果(Performance Evaluation: Results)
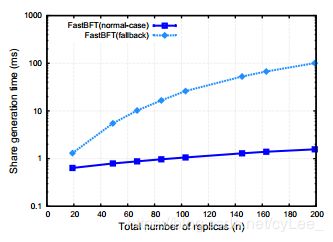
Pre-processing time. 图8描绘了在为一个秘密生成份额时测量的CPU时间与副本数量(n)的关系。我们的结果表明,在正常情况下,TEE仅花费约0.6毫秒来生成20个副本的附加的(additive,附加的,加法的)份额;这个时间随着n的增加而线性增加(例如,200个副本的1.6毫秒)。这意味着为数千个计数器(查询)生成秘密只需要几秒钟。因此,我们认为预处理不会为FastBFT造成瓶颈。在FastBFT的回退变体(fallback variant)的情况下,随着n的增加,份额生成时间(Shamir秘密共享)显著增加,因为该过程涉及n•f模乘(modulo multiplications)。我们的结果表明,为200个副本生成份额大约需要100毫秒。接下来,我们评估FastBFT的在线性能。
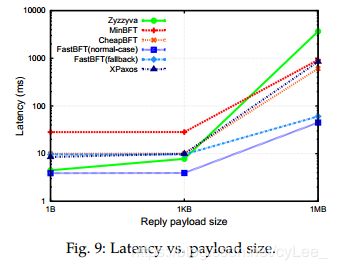
Impact of reply payload size(回复有效负载大小的影响). 我们首先评估延迟与有效负载大小(范围从1字节到1MB)。我们设置n = 103(对应于我们的默认网络大小)。图9显示FastBFT实现了所有有效负载大小的最低延迟。例如,要回答1 KB有效负载的请求,FastBFT需要4 ms,这个速度是Zyzzyva的两倍。我们的发现还表明延迟主要受大于1KB(例如,1MB)的有效负载大小的影响。我们推测这种影响是由传输大型有效负载的开销引起的。基于此观察,我们继续评估有效负载大小分别为1 KB和1 MB的在线性能。有效负载大小在确定系统的有效交易吞吐量(determining the effective transactional throughput)方面起着重要作用。例如,比特币的共识平均需要600秒,但由于有效负载大小(块大小)为1 MB,比特币可以实现每秒7个交易的峰值吞吐量(每个比特币交易平均为250个字节)。
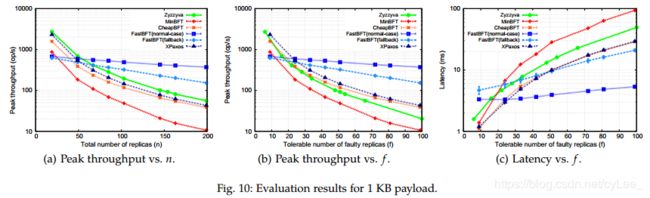
Performance for 1KB reply payload(1KB回复有效负载的性能). 图10(a)描绘了1 KB有效负载下的峰值吞吐量与n的关系。当n很小时,与其他协议相比,FastBFT的性能适中(modest)。虽然随着n的增加,后面这些协议的性能会显著下降,但FastBFT的性能受到轻微影响。例如,当n = 199时,与Zyzzyva,CheapBFT和XPaxos分别为56,38,42 op / s相比,FastBFT达到每秒370次操作的峰值吞吐量。即使在回退情况下,当n = 199时,FastBFT也能达到近152 op / s,并且优于其余协议。请注意,将性能与n进行比较并不能为使用和不使用硬件辅助来比较BFT协议提供公平的依据。例如,当n = 103时,Zyzzyva最多只能容忍f = 34个故障,而FastBFT,CheapBFT和MinBFT可以容忍f = 51。因此,我们研究了性能如何随着图10(b)和图10©中可容忍错误的最大数量而变化。就峰值吞吐量与f而言,FastBFT和Zyzzyva之间的差距更大。例如,当f = 51时,它实现了每秒490次操作的峰值吞吐量,这是Zyzzyva的5倍。通常,当f > 24时,FastBFT实现了最高的吞吐量,而每个操作的平均延迟最低。随着f的增加,FastBFT(及其回退变体)的竞争优势更加明显。尽管FastBFT-fallback实现了与CheapBFT相当的延迟,但它实现了相当高的峰值吞吐量。例如,当f = 51时,FastBFT-fallback达到320 op / s,而CheapBFT则为110 op / s。这是因为FastBFT显示出比CheapBFT少得多的通信复杂性。此外,我们强调XPaxos [28]提供了与Paxos相当的性能。因此我们得出结论,FastBFT甚至优于崩溃容错方案(crash fault-tolerant schemes)。
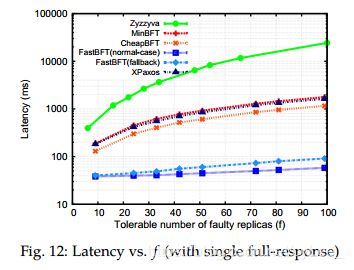
Performance for 1MB reply payload(1MB回复有效负载的性能). 由于FastBFT带来非常低的通信开销,因此随着有效负载大小的增加,FastBFT的优越性能变得更加明显。图11(a)显示,对于1MB有效负荷,即使对于小的n(small n),FastBFT的峰值吞吐量也优于其他协议,并且随着n增加,差距也在不断增大(当n = 199时,比Zyzzyva快260倍)。图11(b)和图11©在比较给定f值的FastBFT和Zyzzyva时,显示了与1KB情况相同的模式。我们还注意到,当负载大小增加到1MB时,除了FastBFT之外的所有其他协议都表现出显著的性能下降。例如,当系统包含200个副本时,客户端需要在MinBFT,CheapBFT和XPaxos中等待至少100个回复(每个大小为1MB),并且在Zyzzyva中等待200个回复,总计200MB。FastBFT克服了这一限制,只需要主节点回复客户端。克服此限制的另一种方法是让客户端指定单个副本以返回完整响应。其他副本仅返回响应的摘要。当指定的副本出现故障时,此优化会影响弹性。尽管如此,我们仍然使用此优化来测量协议的响应延迟,结果如图12所示。FastBFT的性能保持不变,因为它只向客户端返回一个值。即使其他协议的性能得到了显著的改进,FastBFT(正常情况下)仍然优于其他协议。
假设每个有效负载包含250字节的交易(类似于比特币),FastBFT可以在大约199个副本的网络中每秒处理最多113,246个交易。
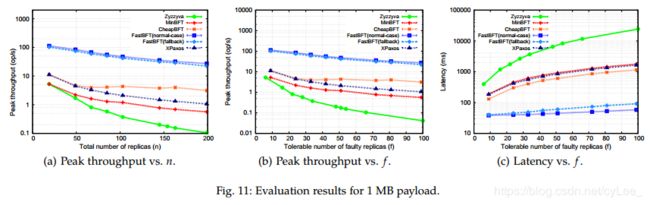
我们的结果证实了我们在第6节中的推测:FastBFT在性能和弹性之间取得了很好的平衡。
7.3 Security Considerations(安全性考虑)
TEE usage. 由于我们假设TEE可能只会崩溃(参见第3节中的系统模型),实现BFT协议的一种简单方法是在TEE内简单地运行崩溃容错变体(例如,Paxos)。但是,在TEE中运行大型/复杂代码会增加TEE代码中的漏洞风险。通常的设计模式是对复杂的应用程序进行分区,以便在TEE中只运行最小的关键部分。先前的工作(例如,MinBFT,CheapBFT)表明使用最小TEE功能(维持单调计数器)改善了BFT方案的性能。FastBFT提供了一种利用TEE的不同方式,通过略微增加TEE功能的复杂性,可显著提高性能。FastBFT的TEE代码有7个接口原语和1,042行代码(47行代码用于SGX SDK); 相比之下,MinBFT在我们的实现中使用了2个接口函数和191行代码(13行代码用于SGX SDK)。尽管FastBFT在TEE中放置的功能多于计数器,但两者都足够小,可以根据需要进行正式/非正式验证。相比之下,Paxos(基于LibPaxos [33])需要超过4,000行代码。
TEE side-channels. 处理敏感信息的SGX enclave代码必须使用抗侧通道算法(side-channel resistant algorithms)来处理它们。然而,FastBFT中唯一的敏感信息是加密密钥/秘密共享,它们由标准加密算法/实现处理,例如标准的SGX加密库(libsgx tcrypto.a),它们是具有侧通道抗性的。现有的侧通道攻击要么基于RSA公共组件,要么基于来自其他库的RSA实现,我们在实现中没有使用这些库。
8.相关工作(RELATED WORK)
随机拜占庭共识协议(Randomized Byzantine consensus)是在20世纪80年代提出[4],[34]。这样的协议依赖于加密硬币抛掷(cryptographic coin tossing)并且期望在概率为1-2-k的O(k) 轮中完成。因此,随机拜占庭协议通常导致高通信和时间复杂度。因此,在本文中,我们关注有效的确定性变体(efficient deterministic variants)。 Honeybadger [31]是最近的随机拜占庭协议,提供与PBFT相当的吞吐量。
Liu等人观察到拜占庭故障通常与异步无关[28]。利用这一观察结果,他们引入了一个新的模型,XFT,它允许设计协议,在弱同步网络中容忍崩溃故障,同时,在同步网络中容忍拜占庭故障。在这个模型之后,作者提出了XPaxos,一种乐观的状态机复制,它需要n = 2 f + 1个副本来容忍f个故障。但是,XPaxos仍然需要在协议阶段进行all-to-all多播,从而导致 O(n2) 的消息复杂度。
FastBFT的消息聚合技术类似于PowerStore [10]中引入的写入证明(proof of writing)技术,该技术实现了读/写存储抽象。写入证明是一个2轮写入程序:作者首先提交一个随机值,然后打开承诺“证明”第一轮已经完成。可以使用加密哈希或多项式评估来实现承诺 - 从而消除了对公钥操作的需要。
Hybster [3]是一种基于TEE的BFT协议,利用并行化来提高性能,这与我们的贡献是正交的。
9.总结和未来的工作(CONCLUSION AND FUTURE WORK)
在本文中,我们提出了一种新的BFT协议FastBFT。 与现有的BFT变体相比,我们分析并评估了我们的提议。我们的结果表明FastBFT比Zyzzyva快6倍。由于Zyzzyva将副本的开销降低到接近其理论最小值,因此我们认为FastBFT对于BFT协议实现了接近最优的效率。此外,与其他BFT协议相比,随着网络规模的增长,FastBFT实现的吞吐量下降得相当慢。这使得FastBFT成为下一代区块链系统的理想共识层候选者。
我们假设TEE配备了认证密钥对(certified keypairs)(第4.1节)。认证(Certification)通常由TEE制造商完成,但也可以在系统初始化时由任何可信方完成。尽管我们的实现使用英特尔SGX进行硬件支持,但FastBFT可以在任何标准TEE平台上实现(例如,GlobalPlatform [15])。
我们计划探索除了树之外的其他拓扑对FastBFT性能的影响。这将使我们能够推断出适合FastBFT中特定网络规模的最佳(或接近最佳)拓扑。