感谢作者 –> 原文链接
本文翻译自 The Flask Mega-Tutorial Part IV: Database
在Flask Mega-Tutorial系列的第四部分,我将告诉你如何使用数据库。
本章的主题是重中之重!大多数应用都需要持久化存储数据,并高效地执行的增删查改的操作,数据库为此而生。
本章的GitHub链接为: Browse, Zip, Diff.
Flask中的数据库
Flask本身不支持数据库,相信你已经听说过了。 正如表单那样,这也是Flask有意为之。对使用的数据库插件自由选择,岂不是比被迫适应其中之一,更让人拥有主动权吗?
绝大多数的数据库都提供了Python客户端包,它们之中的大部分都被封装成Flask插件以便更好地和Flask应用结合。数据库被划分为两大类,遵循关系模型的一类是关系数据库,另外的则是非关系数据库,简称NoSQL,表现在它们不支持流行的关系查询语言SQL(译者注:部分人也宣称NoSQL代表不仅仅只是SQL)。虽然两类数据库都是伟大的产品,但我认为关系数据库更适合具有结构化数据的应用程序,例如用户列表,用户动态等,而NoSQL数据库往往更适合非结构化数据。 本应用可以像大多数其他应用一样,使用任何一种类型的数据库来实现,但是出于上述原因,我将使用关系数据库。
在第三章中,我向你展示了第一个Flask扩展,在本章中,我还要用到两个。 第一个是Flask-SQLAlchemy,这个插件为流行的SQLAlchemy包做了一层封装以便在Flask中调用更方便,类似SQLAlchemy这样的包叫做Object Relational Mapper,简称ORM。 ORM允许应用程序使用高级实体(如类,对象和方法)而不是表和SQL来管理数据库。 ORM的工作就是将高级操作转换成数据库命令。
SQLAlchemy不只是某一款数据库软件的ORM,而是支持包含MySQL、PostgreSQL和SQLite在内的很多数据库软件。简直是太强大了,你可以在开发的时候使用简单易用且无需另起服务的SQLite,需要部署应用到生产服务器上时,则选用更健壮的MySQL或PostgreSQL服务,并且不需要修改应用代码(译者注:只需修改应用配置)。
确认激活虚拟环境之后,利用如下命令来安装Flask-SQLAlchemy插件:
(venv) $ pip install flask-sqlalchemy
数据库迁移
我所见过的绝大多数数据库教程都是关于如何创建和使用数据库的,却没有指出当需要对现有数据库更新或者添加表结构时,应当如何应对。 这是一项困难的工作,因为关系数据库是以结构化数据为中心的,所以当结构发生变化时,数据库中的已有数据需要被迁移到修改后的结构中。
我将在本章中介绍的第二个插件是Flask-Migrate。 这个插件是Alembic的一个Flask封装,是SQLAlchemy的一个数据库迁移框架。 使用数据库迁移增加了启动数据库时候的一些工作,但这对将来的数据库结构稳健变更来说,是一个很小的代价。
安装Flask-Migrate和安装你见过的其他插件的方式一样:
(venv) $ pip install flask-migrate
Flask-SQLAlchemy配置
开发阶段,我会使用SQLite数据库,SQLite数据库是开发小型乃至中型应用最方便的选择,因为每个数据库都存储在磁盘上的单个文件中,并且不需要像MySQL和PostgreSQL那样运行数据库服务。
让我们给配置文件添加两个新的配置项:
import os
basedir = os.path.abspath(os.path.dirname(__file__))
class Config(object):
# ...
SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL') or \
'sqlite:///' + os.path.join(basedir, 'app.db')
SQLALCHEMY_TRACK_MODIFICATIONS = False
Flask-SQLAlchemy插件从SQLALCHEMY_DATABASE_URI配置变量中获取应用的数据库的位置。 当回顾第三章可以发现,首先从环境变量获取配置变量,未获取到就使用默认值,这样做是一个好习惯。 本处,我从DATABASE_URL环境变量中获取数据库URL,如果没有定义,我将其配置为basedir变量表示的应用顶级目录下的一个名为app.db的文件路径。
SQLALCHEMY_TRACK_MODIFICATIONS配置项用于设置数据发生变更之后是否发送信号给应用,我不需要这项功能,因此将其设置为False。
数据库在应用的表现形式是一个数据库实例,数据库迁移引擎同样如此。它们将会在应用实例化之后进行实例化和注册操作。app/__init__.py文件变更如下:
from flask import Flask
from config import Config
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
app = Flask(__name__)
app.config.from_object(Config)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
from app import routes, models
在这个初始化脚本中我更改了三处。首先,我添加了一个db对象来表示数据库。然后,我又添加了数据库迁移引擎migrate。这种注册Flask插件的模式希望你了然于胸,因为大多数Flask插件都是这样初始化的。最后,我在底部导入了一个名为models的模块,这个模块将会用来定义数据库结构。
数据库模型
定义数据库中一张表及其字段的类,通常叫做数据模型。ORM(SQLAlchemy)会将类的实例关联到数据库表中的数据行,并翻译相关操作。
就让我们从用户模型开始吧,利用 WWW SQL Designer工具,我画了一张图来设计用户表的各个字段(译者注:实际表名为user):
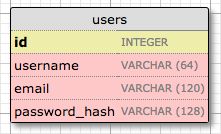
id字段通常存在于所有模型并用作主键。每个用户都会被数据库分配一个id值,并存储到这个字段中。大多数情况下,主键都是数据库自动赋值的,我只需要提供id字段作为主键即可。
username,email和password_hash字段被定义为字符串(数据库术语中的VARCHAR),并指定其最大长度,以便数据库可以优化空间使用率。 username和email字段的用途不言而喻,password_hash字段值得提一下。 我想确保我正在构建的应用采用安全最佳实践,因此我不会将用户密码明文存储在数据库中。 明文存储密码的问题是,如果数据库被攻破,攻击者就会获得密码,这对用户隐私来说可能是毁灭性的。 如果使用哈希密码,这就大大提高了安全性。 这将是另一章的主题,所以现在不需分心。
用户表构思完毕之后,我将其用代码实现,并存储到新建的模块app/models.py中,代码如下:
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
password_hash = db.Column(db.String(128))
def __repr__(self):
return '' .format(self.username)
上面创建的User类继承自db.Model,它是Flask-SQLAlchemy中所有模型的基类。 这个类将表的字段定义为类属性,字段被创建为db.Column类的实例,它传入字段类型以及其他可选参数,例如,可选参数中允许指示哪些字段是唯一的并且是可索引的,这对高效的数据检索十分重要。
该类的__repr__方法用于在调试时打印用户实例。在下面的Python交互式会话中你可以看到__repr__()方法的运行情况:
>>> from app.models import User
>>> u = User(username='susan', email='[email protected]')
>>> u
<User susan>
创建数据库迁移存储库
上一节中创建的模型类定义了此应用程序的初始数据库结构(元数据)。 但随着应用的不断增长,很可能会新增、修改或删除数据库结构。 Alembic(Flask-Migrate使用的迁移框架)将以一种不需要重新创建数据库的方式进行数据库结构的变更。
这是一个看起来相当艰巨的任务,为了实现它,Alembic维护一个数据库迁移存储库,它是一个存储迁移脚本的目录。 每当对数据库结构进行更改后,都需要向存储库中添加一个包含更改的详细信息的迁移脚本。 当应用这些迁移脚本到数据库时,它们将按照创建的顺序执行。
Flask-Migrate通过flask命令暴露来它的子命令。 你已经看过flask run,这是一个Flask本身的子命令。 Flask-Migrate添加了flask db子命令来管理与数据库迁移相关的所有事情。 那么让我们通过运行flask db init来创建microblog的迁移存储库:
(venv) $ flask db init
Creating directory /home/miguel/microblog/migrations ... done
Creating directory /home/miguel/microblog/migrations/versions ... done
Generating /home/miguel/microblog/migrations/alembic.ini ... done
Generating /home/miguel/microblog/migrations/env.py ... done
Generating /home/miguel/microblog/migrations/README ... done
Generating /home/miguel/microblog/migrations/script.py.mako ... done
Please edit configuration/connection/logging settings in
'/home/miguel/microblog/migrations/alembic.ini' before proceeding.
请记住,flask命令依赖于FLASK_APP环境变量来知道Flask应用入口在哪里。 对于本应用,正如第一章,你需要设置FLASK_APP = microblog.py。
运行迁移初始化命令之后,你会发现一个名为migrations的新目录。该目录中包含一个名为versions的子目录以及若干文件。从现在起,这些文件就是你项目的一部分了,应该添加到代码版本管理中去。
第一次数据库迁移
包含映射到User数据库模型的用户表的迁移存储库生成后,是时候创建第一次数据库迁移了。 有两种方法来创建数据库迁移:手动或自动。 要自动生成迁移,Alembic会将数据库模型定义的数据库模式与数据库中当前使用的实际数据库模式进行比较。 然后,使用必要的更改来填充迁移脚本,以使数据库模式与应用程序模型匹配。 当前情况是,由于之前没有数据库,自动迁移将把整个User模型添加到迁移脚本中。 flask db migrate子命令生成这些自动迁移:
(venv) $ flask db migrate -m "users table"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'user'
INFO [alembic.autogenerate.compare] Detected added index 'ix_user_email' on '['email']'
INFO [alembic.autogenerate.compare] Detected added index 'ix_user_username' on '['username']'
Generating /home/miguel/microblog/migrations/versions/e517276bb1c2_users_table.py ... done
通过命令输出,你可以了解到Alembic在创建迁移的过程中执行了哪些逻辑。前两行是常规信息,通常可以忽略。 之后的输出表明检测到了一个用户表和两个索引。 然后它会告诉你迁移脚本的输出路径。 e517276bb1c2是自动生成的一个用于迁移的唯一标识(你运行的结果会有所不同)。 -m可选参数为迁移添加了一个简短的注释。
生成的迁移脚本现在是你项目的一部分了,需要将其合并到源代码管理中。 如果你好奇,并检查了它的代码,就会发现它有两个函数叫upgrade()和downgrade()。 upgrade()函数应用迁移,downgrade()函数回滚迁移。 Alembic通过使用降级方法可以将数据库迁移到历史中的任何点,甚至迁移到较旧的版本。
flask db migrate命令不会对数据库进行任何更改,只会生成迁移脚本。 要将更改应用到数据库,必须使用flask db upgrade命令。
(venv) $ flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> e517276bb1c2, users table
因为本应用使用SQLite,所以upgrade命令检测到数据库不存在时,会创建它(在这个命令完成之后,你会注意到一个名为app.db的文件,即SQLite数据库)。 在使用类似MySQL和PostgreSQL的数据库服务时,必须在运行upgrade之前在数据库服务器上创建数据库。
数据库升级和降级流程
目前,本应用还处于初期阶段,但讨论一下未来的数据库迁移战略也无伤大雅。 假设你的开发计算机上存有应用的源代码,并且还将其部署到生产服务器上,运行应用并上线提供服务。
而应用在下一个版本必须对模型进行更改,例如需要添加一个新表。 如果没有迁移机制,这将需要做许多工作。无论是在你的开发机器上,还是在你的服务器上,都需要弄清楚如何变更你的数据库结构才能完成这项任务。
通过数据库迁移机制的支持,在你修改应用中的模型之后,将生成一个新的迁移脚本(flask db migrate),你可能会审查它以确保自动生成的正确性,然后将更改应用到你的开发数据库(flask db upgrade)。 测试无误后,将迁移脚本添加到源代码管理并提交。
当准备将新版本的应用发布到生产服务器时,你只需要获取包含新增迁移脚本的更新版本的应用,然后运行flask db upgrade即可。 Alembic将检测到生产数据库未更新到最新版本,并运行在上一版本之后创建的所有新增迁移脚本。
正如我前面提到的,flask db downgrade命令可以回滚上次的迁移。 虽然在生产系统上不太可能需要此选项,但在开发过程中可能会发现它非常有用。 你可能已经生成了一个迁移脚本并将其应用,只是发现所做的更改并不完全是你所需要的。 在这种情况下,可以降级数据库,删除迁移脚本,然后生成一个新的来替换它。
数据库关系
关系数据库擅长存储数据项之间的关系。 考虑用户发表动态的情况, 用户将在user表中有一个记录,并且这条用户动态将在post表中有一个记录。 标记谁写了一个给定的动态的最有效的方法是链接两个相关的记录。
一旦建立了用户和动态之间的关系,数据库就可以在查询中展示它。最小的例子就是当你看一条用户动态的时候需要知道是谁写的。一个更复杂的查询是, 如果你好奇一个用户时,你可能想知道这个用户写的所有动态。 Flask-SQLAlchemy有助于实现这两种查询。
让我们扩展数据库来存储用户动态,以查看实际中的关系。 这是一个新表post的设计(译者注:实际表名分别为user和post):

post表将具有必须的id、用户动态的body和timestamp字段。 除了这些预期的字段之外,我还添加了一个user_id字段,将该用户动态链接到其作者。 你已经看到所有用户都有一个唯一的id主键, 将用户动态链接到其作者的方法是添加对用户id的引用,这正是user_id字段所在的位置。 这个user_id字段被称为外键。 上面的数据库图显示了外键作为该字段和它引用的表的id字段之间的链接。 这种关系被称为一对多,因为“一个”用户写了“多”条动态。
修改后的app/models.py如下:
from datetime import datetime
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
password_hash = db.Column(db.String(128))
posts = db.relationship('Post', backref='author', lazy='dynamic')
def __repr__(self):
return '' .format(self.username)
class Post(db.Model):
id = db.Column(db.Integer, primary_key=True)
body = db.Column(db.String(140))
timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
def __repr__(self):
return '' .format(self.body)
新的“Post”类表示用户发表的动态。 timestamp字段将被编入索引,如果你想按时间顺序检索用户动态,这将非常有用。 我还为其添加了一个default参数,并传入了datetime.utcnow函数。 当你将一个函数作为默认值传入后,SQLAlchemy会将该字段设置为调用该函数的值(请注意,在utcnow之后我没有包含(),所以我传递函数本身,而不是调用它的结果)。 通常,在服务应用中使用UTC日期和时间是推荐做法。 这可以确保你使用统一的时间戳,无论用户位于何处,这些时间戳会在显示时转换为用户的当地时间。
user_id字段被初始化为user.id的外键,这意味着它引用了来自用户表的id值。本处的user是数据库表的名称,Flask-SQLAlchemy自动设置类名为小写来作为对应表的名称。 User类有一个新的posts字段,用db.relationship初始化。这不是实际的数据库字段,而是用户和其动态之间关系的高级视图,因此它不在数据库图表中。对于一对多关系,db.relationship字段通常在“一”的这边定义,并用作访问“多”的便捷方式。因此,如果我有一个用户实例u,表达式u.posts将运行一个数据库查询,返回该用户发表过的所有动态。 db.relationship的第一个参数表示代表关系“多”的类。 backref参数定义了代表“多”的类的实例反向调用“一”的时候的属性名称。这将会为用户动态添加一个属性post.author,调用它将返回给该用户动态的用户实例。 lazy参数定义了这种关系调用的数据库查询是如何执行的,这个我会在后面讨论。不要觉得这些细节没什么意思,本章的结尾将会给出对应的例子。
一旦我变更了应用模型,就需要生成一个新的数据库迁移:
(venv) $ flask db migrate -m "posts table"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'post'
INFO [alembic.autogenerate.compare] Detected added index 'ix_post_timestamp' on '['timestamp']'
Generating /home/miguel/microblog/migrations/versions/780739b227a7_posts_table.py ... done
并将这个迁移应用到数据库:
(venv) $ flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade e517276bb1c2 -> 780739b227a7, posts table
如果你对项目使用了版本控制,记得将新的迁移脚本添加进去并提交。
表演时刻
经历了一个漫长的过程来定义数据库,我却还没向你展示它们如何使用。 由于应用还没有任何数据库逻辑,所以让我们在Python解释器中来使用以便熟悉它。 立即运行python命令来启动Python(在启动解释器之前,确保您的虚拟环境已被激活)。
进入Python交互式环境后,导入数据库实例和模型:
>>> from app import db
>>> from app.models import User, Post
开始阶段,创建一个新用户:
>>> u = User(username='john', email='[email protected]')
>>> db.session.add(u)
>>> db.session.commit()
对数据库的更改是在会话的上下文中完成的,你可以通过db.session进行访问验证。 允许在会话中累积多个更改,一旦所有更改都被注册,你可以发出一个指令db.session.commit()来以原子方式写入所有更改。 如果在会话执行的任何时候出现错误,调用db.session.rollback()会中止会话并删除存储在其中的所有更改。 要记住的重要一点是,只有在调用db.session.commit()时才会将更改写入数据库。 会话可以保证数据库永远不会处于不一致的状态。
添加另一个用户:
>>> u = User(username='susan', email='[email protected]')
>>> db.session.add(u)
>>> db.session.commit()
数据库执行返回所有用户的查询:
>>> users = User.query.all()
>>> users
[<User john>, <User susan>]
>>> for u in users:
... print(u.id, u.username)
...
1 john
2 susan
所有模型都有一个query属性,它是运行数据库查询的入口。 最基本的查询就是返回该类的所有元素,它被适当地命名为all()。 请注意,添加这些用户时,它们的id字段依次自动设置为1和2。
另外一种查询方式是,如果你知道用户的id,可以用以下方式直接获取用户实例:
>>> u = User.query.get(1)
>>> u
<User john>
现在添加一条用户动态:
>>> u = User.query.get(1)
>>> p = Post(body='my first post!', author=u)
>>> db.session.add(p)
>>> db.session.commit()
我不需要为timestamp字段设置一个值,因为这个字段有一个默认值,你可以在模型定义中看到。 那么user_id字段呢? 回想一下,我在User类中创建的db.relationship为用户添加了posts属性,并为用户动态添加了author属性。 我使用author虚拟字段来调用其作者,而不必通过用户ID来处理。 SQLAlchemy在这方面非常出色,因为它提供了对关系和外键的高级抽象。
为了完成演示,让我们看看另外的数据库查询案例:
>>> # get all posts written by a user
>>> u = User.query.get(1)
>>> u
<User john>
>>> posts = u.posts.all()
>>> posts
[<Post my first post!>]
>>> # same, but with a user that has no posts
>>> u = User.query.get(2)
>>> u
<User susan>
>>> u.posts.all()
[]
>>> # print post author and body for all posts
>>> posts = Post.query.all()
>>> for p in posts:
... print(p.id, p.author.username, p.body)
...
1 john my first post!
# get all users in reverse alphabetical order
>>> User.query.order_by(User.username.desc()).all()
[<User susan>, <User john>]
Flask-SQLAlchemy文档是学习其对应操作的最好去处。
学完本节内容,我们需要清除这些测试用户和用户动态,以便保持数据整洁和为下一章做好准备:
>>> users = User.query.all()
>>> for u in users:
... db.session.delete(u)
...
>>> posts = Post.query.all()
>>> for p in posts:
... db.session.delete(p)
...
>>> db.session.commit()
Shell上下文
还记得上一节的启动Python解释器之后你做过什么吗?第一件事是运行两条导入语句:
>>> from app import db
>>> from app.models import User, Post
开发应用时,你经常会在Python shell中测试,所以每次重复上面的导入都会变得枯燥乏味。 flask shell命令是flask命令集中的另一个非常有用的工具。 shell命令是Flask在继run之后的实现第二个“核心”命令。 这个命令的目的是在应用的上下文中启动一个Python解释器。 这意味着什么? 看下面的例子:
(venv) $ python
>>> app
Traceback (most recent call last):
File "" , line 1, in <module>
NameError: name 'app' is not defined
>>>
(venv) $ flask shell
>>> app
<Flask 'app'>
使用常规的解释器会话时,除非明确地被导入,否则app对象是未知的,但是当使用flask shell时,该命令预先导入应用实例。 flask shell的绝妙之处不在于它预先导入了app,而是你可以配置一个“shell上下文”,也就是可以预先导入一份对象列表。
在microblog.py中实现一个函数,它通过添加数据库实例和模型来创建了一个shell上下文环境:
from app import app, db
from app.models import User, Post
.shell_context_processor
def make_shell_context():
return {'db': db, 'User': User, 'Post': Post}
app.shell_context_processor装饰器将该函数注册为一个shell上下文函数。 当flask shell命令运行时,它会调用这个函数并在shell会话中注册它返回的项目。 函数返回一个字典而不是一个列表,原因是对于每个项目,你必须通过字典的键提供一个名称以便在shell中被调用。
在添加shell上下文处理器函数后,你无需导入就可以使用数据库实例:
(venv) $ flask shell
>>> db
<SQLAlchemy engine=sqlite:////Users/migu7781/Documents/dev/flask/microblog2/app.db>
>>> User
<class 'app.models.User'>
>>> Post
<class 'app.models.Post'>