Drill查询拆分过程
Drill代码分析(查询拆分)
Drill代码分析(查询拆分)
Drill架构
Drill是什么
Drill查询服务总体执行流程
Drill查询引擎执行流程
物理执行计划生成
查询拆分和分布执行
非根查询片段执行流程
Calcit架构
Drill与Calcite交互
Drill架构
Drill是什么
Drill是开源、低延迟、分布式查询系统,可扩展到数千节点,适用于PB级交互式BI和分析。
Drill具有标准查询引擎的服务器,编译,优化,执行模块,并利用zookeeper负责节点协调,支持基于calcite的优化器,支持查询拆分分布执行和定制存储插件,支持用分布式内存系统加速中间结果集的查询,支持hadoop生态,传统RDB系统和mongdb等数据源 。
Drill架构图如下:
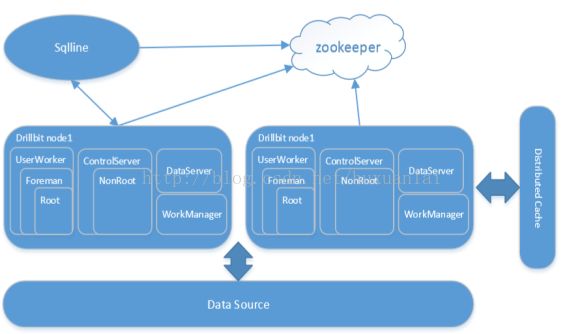
Drill查询服务总体执行流程
Drill的Sqlline客户端:
Zookeeper集群:
Drill服务节点:

- 客户端通过sqlline发起查询请求
- Zookeeper协调请求,并分配一个Drill节点执行任务。
- 节点的Drillbit服务在UserServer中接收请求由UserWorker执行任务。
- UserWorker建立工头Foreman,并把当前节点作为这个查询的主节点,负责把最终查询结果发送给客户端。
- Foreman负责把原始sql查询经过编译优化转换为物理执行计划树。
- 把物理执行计划树用SimpleParallelizer拆分成可分布执行的查询片段树。
- 查询片段树的根节点在本机执行,执行的前提是查询片段树根节点下的处于内部节点位置的查询片段和处于叶子节点位置的查询片段都执行完毕。
- Foreman把非根节点的查询片段发送到远程的相关Drillbit服务。
- 远程Drillbit服务如果接收到类型为叶子节点的查询片段,则直接执行物理执行计划并返回执行结果给上层查询片段。
- 远程Drillbit服务如果接收到类型为内部节点的查询片段,则等待直到其子树内所有查询片段树执行完毕才开始执行,执行完毕结果发送到上层查询片段
Drill查询引擎执行流程
物理执行计划生成

即下面节点的变换过程:
sql string->SqlNode经词法语法分析生成抽象语法树
->RelNode转换为calcite内部关系表达式
->DrillRel经基本优化规则集(实现了RelOptRule接口)转换后的逻辑计划
->Prel经物理执行计划规则集(实现了Prule接口)转换后的节点
->PhysicalOperator为执行计划添加了行数、代价等元数据的物理操作符
->PhysicalPlan
相应的查询语句变换过程示例如下:
原始sql:
SELECT `nations`.`N_NAME`, `regions`.`R_NAME`
FROM `dfs_test`.`/opt/huxl/drill-master/exec/java-exec/../../sample-data/nation.parquet` AS `nations`
INNER JOIN `dfs_test`.`/opt/huxl/drill-master/exec/java-exec/../../sample-data/region.parquet` AS `regions` ON `nations`.`N_REGIONKEY` = `regions`.`R_REGIONKEY`
calcite逻辑执行计划:
ProjectRel(N_NAME=[$2], R_NAME=[$5]): rowcount = 1500.0, cumulative cost = {3200.0 rows, 3202.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 12
JoinRel(condition=[=($1, $4)], joinType=[inner]): rowcount = 1500.0, cumulative cost = xxx, id = 10
EnumerableTableAccessRel(table=[[dfs_test, /opt/huxl/drill-master/exec/java-exec/../../sample-data/nation.parquet]]): rowcount = 100.0, cumulative cost = xxx, id = 4
EnumerableTableAccessRel(table=[[dfs_test, /opt/huxl/drill-master/exec/java-exec/../../sample-data/region.parquet]]): rowcount = 100.0, cumulative cost = xxx, id = 5
drill逻辑执行计划:
DrillScreenRel: rowcount = 25.0, cumulative cost = {107.5 rows, 78.5 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 62
DrillProjectRel(N_NAME=[$1], R_NAME=[$3]): rowcount = 25.0, cumulative cost = {105.0 rows, 76.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 61
DrillJoinRel(condition=[=($0, $2)], joinType=[inner]): rowcount = 25.0, cumulative cost = xxx
DrillProjectRel(N_REGIONKEY=[$1], N_NAME=[$0]): rowcount = 25.0, cumulative cost = xxx, id = 59
DrillScanRel(table=[[dfs_test, /opt/huxl/drill-master/exec/java-exec/../../sample-data/nation.parquet]], groupscan=[ParquetGroupScan [entries=[ReadEntryWithPath [path=file:/opt/huxl/drill-master/sample-data/nation.parquet]], selectionRoot=/opt/huxl/drill-master/sample-data/nation.parquet, numFiles=1, columns=[`N_REGIONKEY`, `N_NAME`]]]): rowcount = 25.0, cumulative cost = xxx, id = 44
DrillScanRel(table=[[dfs_test, /opt/huxl/drill-master/exec/java-exec/../../sample-data/region.parquet]],groupscan=[ParquetGroupScan [entries=[ReadEntryWithPath [path=file:/opt/huxl/drill-master/sample-data/region.parquet]], selectionRoot=/opt/huxl/drill-master/sample-data/region.parquet, numFiles=1, columns=[`R_REGIONKEY`, `R_NAME`]]]): rowcount = 5.0, cumulative cost = xxx, id = 42
drill物理执行计划:
Screen: rowcount = 25.0, cumulative cost = {137.5 rows, 446.5 cpu, 0.0 io, 0.0 network, 88.0 memory}, id = 390
Project(N_NAME=[$0], R_NAME=[$1]): rowcount = 25.0, cumulative cost = xxx, id = 389
Project(N_NAME=[$1], R_NAME=[$3]): rowcount = 25.0, cumulative cost = xxx, id = 388
HashJoin(condition=[=($0, $2)], joinType=[inner]): rowcount = 25.0, cumulative cost = xxx, id = 387
Project(N_REGIONKEY=[$1], N_NAME=[$0]): rowcount = 25.0, cumulative cost = xxx, id = 385
Scan(groupscan=[ParquetGroupScan [entries=[ReadEntryWithPath [path=file:/opt/huxl/drill-master/sample-data/nation.parquet]], selectionRoot=/opt/huxl/drill-master/sample-data/nation.parquet, numFiles=1, columns=[`N_REGIONKEY`, `N_NAME`]]]): rowcount = 25.0, cumulative cost = xxx, id = 384
Scan(groupscan=[ParquetGroupScan [entries=[ReadEntryWithPath [path=file:/opt/huxl/drill-master/sample-data/region.parquet]], selectionRoot=/opt/huxl/drill-master/sample-data/region.parquet, numFiles=1, columns=[`R_REGIONKEY`, `R_NAME`]]]): rowcount = 5.0, cumulative cost = x, id = 386
查询拆分和分布执行
物理执行计划经过SimpleParallelizer拆分后形成类似如下的查询片段树:
fragment1(root)
/ \
fragment2(internal) fragment3(leaf)
/
fragment4(leaf) 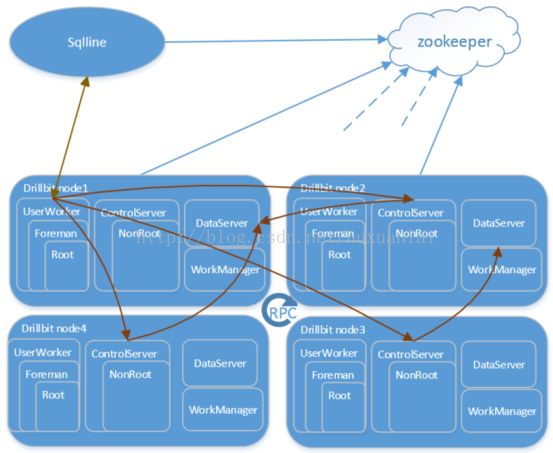
上面fragment1-4四个查询片段分别在drill节点1-4四台机器上执行。下面是各机器上drill服务的执行逻辑
drill节点1:根查询片段的控制和计算节点
UserServer接收zookeeper指派过来的用户请求,并建立Foreman
Foreman对原始查询生成物理执行计划
对物理执行计划改写为查询片段树
将查询片段树中非根查询片段通过ControlClient发送到相应节点
DataServer接受节点2、3返回的数据,每次接受都将状态通知ControlServer
根查询片段在所有子孙查询片段全部执行完毕后在ControlServer中触发执行。
根查询片段执行完毕结果通过UserServer返回给用户。
drill节点2:内部查询片段的控制和计算节点
ControlServer接受节点1发送过来的内部查询分片并建立片段管理器
DataServer接受节点4发过来的查询片段执行结果,并将当前状态信息通过WorkEventBus通知ControlServer中的片段管理器
当前所有依赖的查询片段都已执行完,触发执行当前查询片段,调度执行
WorkManager执行完当前查询片段,把结果通过DataClient发往节点1的DataServer
drill节点3:父亲为根查询片段的叶子查询片段所在的计算节点
ControlServer接受节点1发送过来的叶子查询分片并建立执行器,调度执行
WorkManager执行完叶子查询片段,把结果通过DataClient发往节点1的DataServer
drill节点4:父亲为内部查询片段的叶子查询片段所在的计算节点
ControlServer接受节点1发送过来的叶子查询分片并建立执行器,调度执行
WorkManager执行完叶子查询片段,把结果通过DataClient发往节点2的DataServer
非根查询片段执行流程
特别的,非根查询片段所建立的片段管理器执行流程如下:
IncomingBuffers对应要接收的所有查询片段结果集接收器Receiver
DataCollector对应每个查询片段结果集接收器,一个接收器对应多个发送器Sender的结果
RawRawBatchBuffer表示每个Sender执行后结果,Sender结果集可能比较大,会多次发送
RawFragmentBatch对应一个Sender返回的结果集块,
FragmentRecordBatch结果集块对应的protobuf消息格式
Calcit架构
Calcite是可灵活定制的查询编译和优化器开发框架。Calcite内部实现了100种左右的优化规则。
架构如下: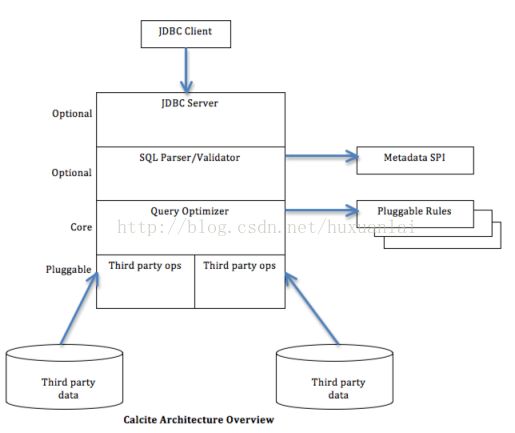
Drill与Calcite交互
Calcite主要负责编译和优化。所以drill和calcite之间的交互主要在物理执行计划生成之前
RelOptRule优化规则抽象接口
RelNode: 代数表达式抽象接口
Planner: 编译器和优化器函数调用的接口
Program:优化规则被执行调用的接口
Drill利用了calcite定制优化规则,Drill定制的优化规则定义主要是实现了Prule接口的针对物理执行计划优化。针对逻辑执行计划的规则主要还是利用了calcite,Drill定制较少。