分布式系统与 Google 早期的三篇论文
| 版本号 | 修改时间 | 修订人 | 修改备注 |
|---|---|---|---|
| 1.0 | 2019-10-30 | 汐雪池间 | 初稿 |
Google 在 2003~2006 年间发表的三篇论文为今天 Hadoop 大数据生态的发展奠定了技术基础,工程师利用市场上相对廉价的通用计算设备(x86架构,Linux 系统)而非昂贵的定制版服务器,搭建低成本、易扩展、高可用的分布式数据存储、管理、计算集群,支撑了 Google 的多项重要服务。
相信许多对大数据感兴趣的人都听说过 Google 在十年前发表的三项重要成果: Google File System、 MapReduce 和 Bigtable 。Google 在这些成果中,介绍了其利用通用计算设备成功搭建分布式集群的方法。其中的诸多设计思想,在后来被广泛采用。
为什么要设计这些系统?这些系统都有什么用处?这些系统在实现上有哪些特点?对后来的系统设计有哪些启发意义?本文通过提出并回答一系列问题,介绍目前流行的大数据技术的核心设计理念和技术实现。
1. 分布式系统
- 什么是分布式系统?
- 为什么需要分布式系统?
在硬盘存储空间多年来不断提升的同时,硬盘的读取速度没有与时俱进。如果将大量数据存储于单个磁盘中,在分析时将需要耗费大量时间。
从 1990 年到 2010 年,主流硬盘空间从1GB 增长到 1TB,一千倍的提升,硬盘的读取速度从 4.4 MB/s 到 100 MB/s,仅有约20倍的提升[4]。以这种速度(100 MB/s)读完整个硬盘(1TB)的数据至少需要 2.5 个小时。
如何减少数据读写以及数据分析的时间呢?比较直接的方案是同时对多个硬盘中的数据并行读/写,从而提高I/O 带宽,但这一方案也会面临一些问题:
- 更高的硬件故障频率。假如单个硬盘连续正常使用一个月的可靠性是 99.99%,一个月中 10000 个磁盘都不出错的概率只有 36.8%。
- 不同节点之间的数据组织和共享。一份数据要如何存放在不同磁盘上?不同节点上的数据如何更高效地通信、共享,从而避免网络I/O成为系统瓶颈?
2. Google File System (GFS)
2.1 GFS 有什么用?
解决了分布式系统上的文件存储问题。它提供了运行在廉价的商用硬件上的容错能力,并具备为大量客户端提供整体高性能服务的能力。
2.2 GFS 要解决什么问题?
传统分布式文件系统要解决的主要问题:
- 性能
- 可扩展性
- 可靠性
- 可用性
GFS 的设计者通过对业务工作的观察发现了一些通用设备集群的工作特点,针对这些特点重新设计实现了一个新的分布式文件系统。具体有哪些特点呢,请看 2.3 节。
2.3 GFS 的设计
结合 Google 所使用的分布式集群和程序应用场景,在对 GFS 进行设计时考虑了以下因素:
- 单点设备问题会经常出现;
- 系统主要用于存储大文件。文件系统存储数百万个大小在 100 MB 左右或以上的文件;
- 对文件的常见操作为大规模的流式读取和小规模的随机访问;
- 常见的文件修改为序列追加写入。一旦写入后,文件很少会再修改。任意位置的修改不需要被高效支持;
- 高效支持对单个文件的并发追加操作。原子操作和小的同步开销是必要的;
- 带宽吞吐比低延迟更重要。
系统架构
GFS 系统由一个 master 节点和多个 chunkserver 节点构成,系统同时被多个 client 访问,如下图所示:
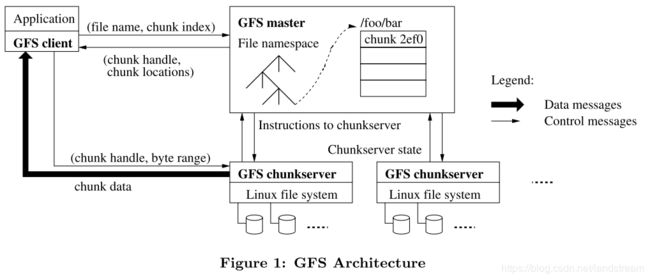
其中每一个节点,一般为一台 Linux 系统的商用计算设备上运行的用户态服务进程。文件会被拆分成固定大小的块(chunk),每一个块用固定的 64 位区块句柄唯一标识,块标识的工作由 master 节点完成。
- master 节点存储文件系统的所有元数据信息;
- chunkserver 存储数据。master 和 chunksever 之间通过定时发送的心跳信息交流;
- 客户端与主服务器进行元数据交互,获取要访问数据的块信息,数据块内容的传输则由 chunkserver 完成。
2.4 GFS 的实现细节
系统中的交互
在设计时,尽量减少 master 参与数据修改这类高频操作,避免 master 负载过高成为系统瓶颈。
Leases and Mutation Order
使用租约(Lease)机制维护不同数据备份之间的一致性变更。master 选择一个主备份,主备份决定数据块的修改顺序,其他所有的备份将跟随此顺序。
Data Flow
数据流和控制流解耦,充分利用每台机器的带宽。控制流呈射线状由客户端流向主备份和所有二级备份,数据流顺序流经不同的 chunkservers。
❗原子性的记录追加
- 向文件并发追加内容时的原子性实现参照 UNIX 系统中的 O_APPEND 模式,GFS 中副本追加内容的 offset 需要向 master 请求获取;
- 追加失败将重试,因此可能导致部分数据出现重复。GFS 能保证最终一致性,文件内容被成功追加写入后,所有备份数据中的 offset 和顺序相同。
❗快照
在不打扰数据变动的情况下,快速实现文件或目录的拷贝。利用 copy-on-write 技术实现快照功能。
写时复制的快照执行逻辑:
- master 回收租约;
- 在日志中记录相关操作;
- 创建数据块的快照文件点;
snapshot 运行过程中的 write 操作会在每一个 chunkserver 上复制得到一个新的目标 chunk,并在新得到的 chunk 上执行后续操作。
主节点存储的信息
主节点存储文件系统元数据,包括:
- 命名空间;
- 访问控制信息;
- 文件名到 chunk 存储地址的映射,以及文件在 chunk 中的位置。
主节点和 chunkserver 之间通过心跳信息进行指令交互和状态获取。
GFS 未额外加入缓存机制
通常GFS访问的文件体积较大,因此为了简化系统,系统避免使用缓存。但 Linux 系统本身的 buffer cache 机制仍可发挥作用。
chunk size
默认64MB,大的 chunk size 提供了主要优势:
- 减少请求 chunkserver 位置时对 master 带来的负担,避免 master 称为单点瓶颈。
- 减少重复建立连接的次数
- 减少 metadata 数量。
主存中的数据结构
元数据
- 文件名和 chunk(文件块) 命名空间;
- 文件到文件块的映射;
- 文件副本的位置;
其中 1、2 持久化存储再 master 的本地磁盘,并在远程机器上做备份。
3 存储在主存中,动态更新。
元数据存储在主存中,前缀压缩存储路径
chunk location
master 在启动时,在心跳通信过程中向 chunkserver 请求获取 chunk location 信息。
operation log
- 检查点以 B 树形式存在,记录master 中的 namespace;
- 记录关键的元数据变更历史;
- 以检查点的形式存储历史记录,用于错误恢复。
3. MapReduce
MapReduce 是一种编程模型,同时又是一种处理大数据集的实现方法。通过 map 和 reduce 方法将数据以 key/value 对的形式进行组织和处理。这种编程模型将分布式计算过程中的并行、容错、负载均衡隐藏起来。
MapReduce 有什么用?
简化大型集群上的数据处理。
以这种形式编写的程序可以在大型集群上并行地调度、运行,无需程序编写者考虑分布式系统的资源、通信等细节问题。
主要贡献是提供一个一个简单而强大的编程接口,它支持大规模计算的自动并行化和分布。结合了该接口的实现,可以在大型商用 pc 集群上实现高性能数据处理。
3.1 MapReduce 设计
MapReduce 的设计思想?
并行化

3.2 MapReduce 的实现细节
master 节点的数据结构
- map/reduce task 信息:任务状态、对应 worker 的标识
- map 产生的中间计算结果文件的位置和大小信息
容错
- 应对 worker 故障:定期检查发现 worker 错误;重新执行故障 worker 对应的任务
- 应对 master 故障:定期备份,存储 checkpoint 数据
- 用户代码逻辑异常应对方法:依赖于 map/reduce 任务状态提交的原子性,确保最终输出结果是确定的。
任务备份
发现拖累节点后,备份任务将执行,加快任务执行。
数据的划分方法
指定 hash 函数,选择数据的存储位置。
顺序保证
中间结果的 key/value 对按 key 值递增排序。
组合函数
在 map 任务执行的机器上,对 map 任务的结果预先进行组合处理(主要是精简结果),降低后续 reduce 任务中不同机器之间的数据交换量。
副作用
MR的正确计算依赖于文件写入时的原子性和幂等性。
跳过无效记录
sequence number
通过 last gasp UDP 包告知 master 已经处理过的记录。
本地执行
MapReduce 支持在本地模拟执行 MR 任务,方便开发调试
状态信息
- 计算进度
- 输入数据/中间数据/输出数据量
- 机器运行状态
计数器
工作机向 master 传输 counter 信息,master 对不同机器的计数进行累加。master 会消除重复计数导致的副作用。
4. BigTable
目标:在数千台设备的商用设备集群上实现对超大规模结构化数据的存储管理。BigTable 支撑了 Google 的网页内容索引,Google Earth 以及 Google Finance 等多个重要应用。
数据模型
Bigtable 的数据将以 SSTable 的形式持久化存储,SSTable 相关知识请另外自行查阅。
索引结构

(row key, column key, timestamp) -> value
- row key:大小一般在 10-100 bytes,最多 64KB。对一个 row key 的读写操作是原子的;
- column key: 由 column family + column key 组成;
- timestamp:64位整数,以微秒或其他形式存在,用于实现数据的版本管理。在产生时间戳时要避免碰撞。
设计思想
- 可扩展性
- 高性能
- 向外提供特别的接口,不支持完全的关系数据模型;
- 动态支持数据格式和 schema 变化,客户端可以对数据的存放位置进行推断;
- 索引由 row 和 column 等字符串;
- 将数据内容作为不可解释的字符串对待;
实现细节
Bigtable 的实现包含三个组件:
- 运行于客户端的 library
- 一个 master server
- 多个 tablet server,可动态加入或移除集群
master 任务:
- 将数据表安排给不同的 tablet server
- 检测 tablet server 的状态变化(新增或过期)
- 负载均衡
- GFS 中的垃圾回收
- 处理表结构的变化
tablet server 功能:
- 处理对数据表的读/写请求
- 对过大的数据表进行分割
tablet 的定位
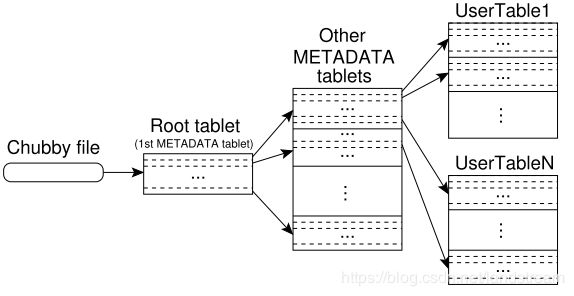
三层表和 B+树
- chubby file 存储root 位置信息
- root table 包括所有 metadata 表
- 元数据表存储所有表的位置信息,row key,一条 metadata 大约 1KB 大小;存储 SSTable 列表
客户端缓存并维护 tablet 的位置
tablet 分配
一个 tablet 分配给一个 tablet server;
由master记录检测和维护 tablet 分配情况
tablet serving

tablet 的状态信息持久化存储在 GFS 中;
更新信息以 redo log 的形式存储;
近期变动的记录存储在内存中;
早期的更新存储在一系列 SSTable 中
写操作处理:
- 检查 tablet 是否格式化
- sender 授权
- commit log 写入
- 内容写入 memtable
读操作处理:
- 格式化检查
- 权限检查
- 在 SSTables 和 memtable 上执行读操作
数据压缩
memtable 大小达到上限后将会冻结并转化为 sstable 写入 GFS;
minor compaction 得到 SSTable;
SSTable 的合并 major compaction;
优化方法
locality group
将经常访问的 column family 组织在一起,将不经常一同访问的数据分开存放在不同的 SSTable 中
压缩方法
客户端控制 SSTable 是否需要压缩以及压缩方法
布隆过滤器
用内存中存储的小布隆过滤器判断 SSTable 中是否包含指定记录,减少磁盘读取
commit-log 的实现
每一台 tablet server 维护一份 commit-log,而不是为每一个 tablet 维护一份log;
speeding up tablet recovery
- minor 压缩
- 停止服务,再次压缩
| 论文题目 | The Google File System [1] | MapReduce: Simplified Data Processing on Large Clusters [2] | Bigtable: A distributed storage system for structured data [3] |
|---|---|---|---|
| 发表时间 | 2003 | 2004 | 2006 |
| 内容概述 | 分布式数据存储。容错、高性能的分布式文件系统,同时服务大量客户端。 | 分布式批处理计算。 | 分布式结构化数据管理。 |
| 设计理念 | 1. 发生错误是常态(进程错误,系统错误,设备错误) 2. 单个文件体积大 3. 文件内容一般以追加的形式进行修改 4. 对原子性和一致性进行修改 |
将数据以键-值对的形式进行组织,以 map、reduce 为基本操作的编程范式 | 它为客户端提供了一个简单的数据模型,该模型支持对数据布局和格式的动态控制,并允许客户端对底层存储中表示的数据的存储位置进行推理。 |
| 关键技术 | 1. 容错 2. 并发 3. 一致性 |
1. 容错 2. 数据分布 3. 负载均衡 |
|
| 系统架构 | master(1主+1备) + chunkserver | master + worker | |
| 数据模型 |
总结
在以大量 x86 服务器搭建的分布式集群上设计实现系统要考虑的关键问题:
- 数据分布(Location):数据在集群中的分布。为了提高 I/O 效率,避免主机之间的网络通信成为全局瓶颈,需要对数据在整个集群的分布做出合理安排,将经常被一同访问的数据尽量安置在一起;
- 容错:考虑单点故障可能导致的问题;
- 一致性:并发场景下的一致性控制。
- 负载均衡:
积极评价
用 commodity server 集群搭建的系统相比大型机具有更强的可扩展性和容错能力,同时具有一定的设备价格优势。Google 在这方面做了相关工作,并用自己的成功有力地证明了该方案的可行性。在今天,互联网服务提供商大多也采用了通过搭建 commodity server 集群支撑自身服务的飞速发展。
思考与质疑
CAP 是分布式系统逃不过的问题,响应时间和一致性是存在矛盾的。commodity server 集群搭建的系统存在的突出问题是一致性问题,同时,集群中不同节点之间的通信也可能成为瓶颈,而且相比大型机来说,总的能耗更高。
参考文献
[1] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. 2003. The Google file system. In Proceedings of the nineteenth ACM symposium on Operating systems principles (SOSP '03). ACM, New York, NY, USA, 29-43. DOI: https://doi.org/10.1145/945445.945450
[2] Jeffrey Dean and Sanjay Ghemawat. 2004. MapReduce: simplified data processing on large clusters. In Proceedings of the 6th conference on Symposium on Operating Systems Design & Implementation - Volume 6 (OSDI’04), Vol. 6. USENIX Association, Berkeley, CA, USA, 10-10.
[3] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. 2006. Bigtable: a distributed storage system for structured data. In Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation - Volume 7 (OSDI '06), Vol. 7. USENIX Association, Berkeley, CA, USA, 15-15.
[4] Hadoop 权威指南
问题
- 大型机/服务器的价格性能信息在哪里?PC 集群的性价比如何体现?大型机,小型机,x86 服务器之间的比较
大型机:数据完整性和实时强一致性。高昂的设备价格,扩展性低,IBM 大型机,运维方便,省电;
集群:网络信息传输速度相对较慢,更低的 IO,集群上难以作到实时一致性, x86 server;
https://www.zhihu.com/search?type=content&q=IBM%20%E5%A4%A7%E5%9E%8B%E6%9C%BA