胜者树 败者树 K-路最佳归并树 高效外部排序
外部排序
外部排序和内部排序还是有非常的的不同的,我们的外部排序主要针对的优化目标也是不同的,这里我先从外部排序的物理基础开始进行讲解
1.外存:
外部存储设备,相对于我们的内部存储设备而言具有一些特点
1.优点:永久存储能力,便携性,存储空间大
2.缺点:访问速度相对于内存的访问速度来说极其低下(相差约5~6个数量级)
因此对于外存来说,我们要遵守的基本操作原则就是:尽可能的减少我们的对外存的访问的次数
对于外存的类型来说,我们分成了磁带和磁盘两个方面,在这里我们对磁带就不过多的赘述了,我们主要来看看磁盘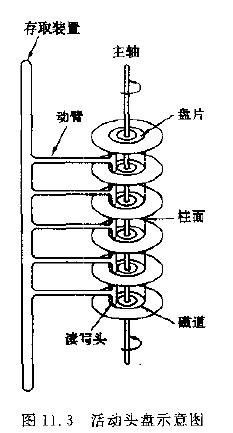
如图所示,我们可以大致的了解到磁盘的主要的操作部件,在这里我们对操作的具体不见不做过多的描述,我们主要来考虑一下我们的这些部件对我们的计算机和磁盘之间的交互的时间效率的影响
磁盘的存取时间
磁盘访问时间主要由寻道时间,旋转延迟时间和数据传输时间组组成。
寻道时间(Seek time)tseek:是移动磁盘臂,定位到正确磁道所需的时间。
旋转延迟时间tla:是等待被存取的扇区出现在读写头下所需的时间。
传输时间twm:是传输一个字符的时间。
TI/O=tseek + tek + la + twm
我们每次都是将我们的磁盘中的数据按**块**为单位传输到我们的内存的高速缓冲区中(cache)我们每次在内存中对数据进行读取的时候,都要先从cache中开始检查,如果cache中存在数据我们就从cache中读取,如果cache为空,我们在从磁盘中进行读取
我们在外存上的数据基本都可以看作是文件,我们对外部数据进行的操作主要可以分成这么几类
文件上的操作
**检索**:在文件中寻找满足一定条件的记录
**修改**:对记录中某些数据值进行修改。若对关键字进行修改,就相当于删除加插入。
**插入**:向文件中增加一个新记录。
**删除**:从文件中删去一个记录 。
**排序**:对指定好的数据项,按其值的大小把文件中的记录排成序列。常用按关键
简称就是:增删改查排
外部排序流程
选择树
胜者树
败者树
败者树 VS 堆
K-路最佳归并树
核心伪代码:
heap - array save the number of the data
heapnum - the size of the heap
siftdown(i):
t
while i*2<=heapnum:
if heap[i]>heap[i*2]: t=i*2
else t=i
if i*2+1<=heapnum and heap[i*2+1]2.K-路最佳归并树
m - the size of the K-Haffman
data[] - the size is m,the input cache,waited to merge
K_Merge(data,m):
creat_heap(m)
while heapnum!=1:
help=[] //保存k个选出的缓冲区序列
for i=1 to k:
help.append(pop()) //弹出堆顶并进行维护最小堆性质
Loser_Tree(help,k)data - the size is the k,the array wait to merge
k - the size
ls - 非叶子节点,保存我们的输入缓冲区指针
MIN - 最小值,在我们建树的时候用来辅助维护
MAX - 我们维护的时候,为了防止出现一个缓冲区为空的情况,添加的哨兵
Loser_Tree(data,k):
new_input //新的输入缓冲区,需要返回的结果
creat_Loser_Tree(data,k)
while data[ls[0]].top()!=MAX:
new_input.append(data[ls[0]].top)
data[ls[0]].pop()
Adjust(ls[0]) //调整
creat_Loser_Tree(data,k):
data[0].append(MIN) //哨兵,辅助构建败者树
clear ls
for i=1 to k:
data[i].append(MAX) //哨兵,辅助维护败者树
for i=k down to 1:
Adjust(i)
Adjust(int root):
father = root /2
winner = root
t = root
while t!=0: //0是要维护到败者树的最顶端
if win:
swap(winner,loser)
ls[0]=winner
C++ Code:
#include"iostream"
#include"cstdio"
#include"cstring"
#include"cstdlib"
#include"algorithm"
#define N 1005
#define INF 0x3fffffff
#define MIN -INF
/*
利用OOP思路 构建cache高速缓存类 在不考虑内存容量的前提下 模拟最佳归并树,败者树
cache内利用栈模拟
*/
using namespace std;
class Empty_Error{};
class cache //模拟高速缓存
{
public:
cache()
{
head=1;
memset(stack,0,sizeof(stack));
tail=1;
}
inline int top()
{
try
{
if(empty()) throw Empty_Error();
else return stack[head];
}
catch(Empty_Error x)
{
cout<<"try to get the element from an empty cache!"<= N) return true;
else false;
}
inline void append(int x) //添加数据项接口
{
stack[tail++]=x;
}
private:
int head;
int tail;
int stack[N];
};
cache test[1005];
int heapnum;
int k;
int m;
void jiaohuan(int i,int t)
{
cache p=test[i];
test[i]=test[t];
test[t]=p;
}
void sift_down(int i)
{
int t;
while(i*2<=heapnum)
{
if(test[i*2].size() < test[i].size()) t=i*2;
else t=i;
if(i*2+1 <= heapnum && test[i*2+1].size() < test[t].size()) t=i*2+1;
if(i != t)
{
jiaohuan(i,t);
i=t;
}
else break;
}
}
void sift_up(int i)
{
int t;
while(i!=1)
{
if(test[i].size() < test[i/2].size())
{
int k=i/2;
jiaohuan(i,k);
i=i/2;
}
else break;
}
}
void creat_heap(int num)
{
for(int i=(num>>1);i>=1;i--)
{
sift_down(i);
}
}
void Adjust_tree(int start,int ls[],cache* queue)
{
int winner=start;
int t=(start+k-1)/2;
while(t!=0)
{
int a=queue[winner].top();
int b=queue[ls[t]].top();
if(a > b)
{
int loser=winner;
winner=ls[t];
ls[t]=loser;
}
t=t/2;
}
ls[0]=winner;
}
void creat_Loser_tree(int ls[],cache* queue)
{
for(int i=1;i=1;i--)
{
Adjust_tree(i,ls,queue);
}
}
cache K_merge(cache* queue,int k)
{
cache ans;
int ls[N]; //实际上只需要2*k+1的辅助空间
creat_Loser_tree(ls,queue);
while(queue[ls[0]].top()!=INF)
{
ans.append(queue[ls[0]].top());
queue[ls[0]].pop();
Adjust_tree(ls[0],ls,queue);
}
return ans;
}
int main() //测试入口
{
printf("决定K-路归并:");
scanf("%d",&k);
printf("决定块数:");
scanf("%d",&m);
int b=k-(m-1)%(k-1)-1;
int NUM = b+m;
heapnum = NUM;
for(int i=1;i<=m;i++)
{
int x;
int y;
printf("初始化高速缓存%d\n",i);
printf("缓存容量:\n");
scanf("%d",&x);
for(int j=1;j<=x;j++)
{
scanf("%d",&y);
test[i].append(y);
}
}
creat_heap(NUM);
cache Loser_tree[k+5];
for(int i=1;i<=NUM;i *= k)
{
for(int j=1;j<=k;j++) //获取归并序列
{
Loser_tree[j] = test[1];
test[1]=test[heapnum--];
sift_down(1);
}
cache ans= K_merge(Loser_tree,k);
test[heapnum+1]=ans;
heapnum++;
sift_up(heapnum);
}
//测试输出
while(!test[1].empty())
{
cout<