我用java玩爬虫之第一次爬CSDN就是这么简单!
我不知道大家学习爬虫的初衷是什么,我玩爬虫是因为发现很多的同学,应届生找工作找不到应聘路径,所以本教程就是用爬虫实现一个类似51job的求职网站,我命名为SJW(Search Job Web)寻职网。目标是爬取的职业范围比51job更广更全!关注专栏Java爬虫【寻职网项目实战】
目录
你的第一次
1.爬虫入门程序
1.1.环境准备
1.2.入门demo
2.掌握HttpClient
2.1 Get请求
2.2.Post请求
2.2.1.不带参数的Post请求
2.2.2 带参数的Post请求
3.连接池的使用
4.查漏补缺 请求参数设置
5.总结
你的第一次
- 入门程序
- HttpClient抓取数据
- Get请求
- Post请求
- 连接池的使用
- 查漏补缺
知识准备,学习之前你需要知道
- Post和Get请求的区别
- http状态查询
1.爬虫入门程序
1.1.环境准备
- JDK1.8
- IntelliJ IDEA
- Maven
1.2.入门demo
1.创建Maven工程springboot_reptile并给pom.xml加入依赖。
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
test
2.添加log4j.properties。
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
3.编写最简单的爬虫,抓取我的CSDN主页。
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class CsdnCrawlerTestDemo {
public static void main(String[] args) throws IOException {
//1.打开浏览器,即创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//2.输入网址,创建HttpGet对象
HttpGet httpGet = new HttpGet("https://blog.csdn.net/lyztyycode");
//3.发起请求,返回响应
CloseableHttpResponse response = httpClient.execute(httpGet);
//4.解析响应,获取数据
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity, "utf8");
System.out.println(content);
}
}
}运行代码的效果如下:部分截图,可以看出是我主页的博客列表
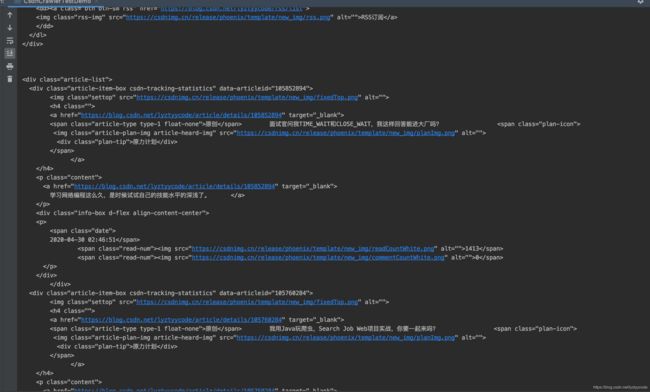
上面是一个最简单的网络爬虫的demo,下面我们就进一步的学习一下怎么写一个好用的爬虫!如果你不理解获取到http请求的响应后,为什么判断状态是200,可以先了解一下http请求的几种状态:http状态查询
2.掌握HttpClient
网络爬虫就是用程序帮助我们访问网络上的资源,我们一直以来都是使用HTTP协议访问互联网的网页,网络爬虫需要编写程序,在这里使用同样的HTTP协议访问网页。
这里我们使用Java的HTTP协议客户端 HttpClient这个技术,来实现抓取网页数据。
2.1 Get请求
上面的入门程序中又一个问题是如果建立了链接我们没有释放,那么这个链接就会占用网络资源,所以在获取到资源和数据后我们要及时的释放资源,防止造成网络资源的浪费。
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
public class HttpGetDemo {
private final static Logger LOGGER = LoggerFactory.getLogger(HttpGetDemo.class);
public static void main(String[] args) throws IOException {
//打开浏览器,即创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建HttpGet请求
HttpGet httpGet = new HttpGet("https://blog.csdn.net/lyztyycode");
CloseableHttpResponse response = null;
try{
//发起请求,返回响应
response = httpClient.execute(httpGet);
//解析响应,获取数据
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity, "utf8");
LOGGER.info(content);
}
}catch (Exception e){
LOGGER.error("httpget error!", e.getMessage());
}finally {
//释放链接
if(response == null){
response.close();
}
httpClient.close();
}
}
}
代码执行结果:
请求成功:

链接关闭:

2.2.Post请求
Post的请求参数需要提交表单。所以有带参数和不带参数的Post请求两种方式。
2.2.1.不带参数的Post请求
仍然爬取:https://blog.csdn.net/lyztyycode 我们只需要把Get请求的对象换成Post即可,注意和GetDemo的区别:
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
public class HttpPostDemo {
private final static Logger LOGGER = LoggerFactory.getLogger(HttpPostDemo.class);
public static void main(String[] args) throws IOException {
//打开浏览器,即创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建HttpPost请求
HttpPost httpPost = new HttpPost("https://blog.csdn.net/lyztyycode");
CloseableHttpResponse response = null;
try{
//发起请求,返回响应
response = httpClient.execute(httpPost);
//解析响应,获取数据
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity, "utf8");
LOGGER.info(content);
}
}catch (Exception e){
LOGGER.error("httpget error!", e.getMessage());
}finally {
//释放链接
if(response == null){
response.close();
}
httpClient.close();
}
}
}
执行结果,可以看到成功响应:

2.2.2 带参数的Post请求
我们爬取:https://mkt.51job.com/tg/sem/pz_v2.html?from=baidupz 51job的首页。
import com.google.common.collect.Lists;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.lang.model.element.Name;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class HttpPostHasParamDemo {
private final static Logger LOGGER = LoggerFactory.getLogger(HttpPostDemo.class);
private static final String ENCODE_UTF_8 = "utf8";
public static void main(String[] args) throws IOException {
//打开浏览器,即创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建HttpPost请求
HttpPost httpPost = new HttpPost("https://mkt.51job.com/tg/sem/pz_v2.html");
//声明list集合,封装表单中的参数
List params = Lists.newArrayList();
//设置参数
params.add(new BasicNameValuePair("from", "baidupz"));
//创建表单的Entry对象,第一个参数是封装好的表单数据,第二个参数是编码
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(params, ENCODE_UTF_8);
//设置表单的Entry对象到Post请求中
httpPost.setEntity(formEntity);
CloseableHttpResponse response = null;
try{
//发起请求,返回响应
response = httpClient.execute(httpPost);
//解析响应,获取数据
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity, "utf8");
LOGGER.info(content);
}
}catch (Exception e){
LOGGER.error("httppost error!", e.getMessage());
}finally {
//释放链接
if(response == null){
response.close();
}
httpClient.close();
}
}
}
运行结果:
响应状态为成功!
到目前为止,我们已经会了使用HttpClient发送Get和Post请求,到这里不知道你会不会发现一个问题或者有一个疑问,就是我们每次发请求都要创建一个HttpClient对象,而这就相当于打开一个浏览器,我们知道打开浏览器是个很重的操作,过去就有让你的系统不停打开浏览器的病毒或木马,达到让系统崩溃的目的,所以我们不能频繁的创建和销毁HttpClient,怎么办呢?我们可以通过连接池来解决。
3.连接池的使用
如果每次请求都要创建HttpClient,会有频繁创建和销毁的问题,可以使用连接池来解决这个问题。
测试以下代码,并断点查看每次获取的HttpClient都是不一样的。
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.jta.bitronix.PoolingConnectionFactoryBean;
import java.io.IOException;
public class HttpPoolTestDemo {
private final static Logger LOGGER = LoggerFactory.getLogger(HttpPoolTestDemo.class);
private static final String ENCODE_UTF_8 = "utf8";
public static void main(String[] args) throws IOException {
//创建连接池管理器
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
//使用连接池管理器发请求
doGet(cm);
doGet(cm);
}
private static void doGet(PoolingHttpClientConnectionManager cm) throws IOException {
//不是每次创建新的Httpclient,而是从连接池中获取HttpClient
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
//创建HttpGet请求
HttpGet httpGet = new HttpGet("https://blog.csdn.net/lyztyycode");
CloseableHttpResponse response = null;
try{
//发起请求,返回响应
response = httpClient.execute(httpGet);
//解析响应,获取数据
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity, "utf8");
LOGGER.info(content);
}
}catch (Exception e){
LOGGER.error("httpget error!", e.getMessage());
}finally {
//释放链接
if(response == null){
response.close();
}
//不能关闭HttpClient,由连接池管理
//httpClient.close();
}
}
}
注意两点:
- 不是每次创建新的HttpClient,而是从连接池中获取
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();- 一次请求之后不用开发者管理HttpClient的销毁,交给连接池管理
//httpClient.close();
代码写完了,那么这个连接池有作用吗,我们加断点,debug来看一下。
添加断点如图:

我们右键,debug运行程序,结果如下:
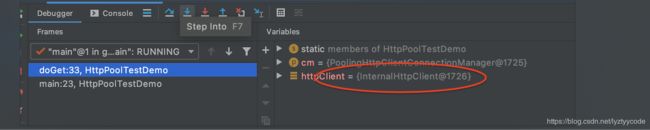
地址值是1726.
我们继续执行,结果如下。
 地址值是2531.
地址值是2531.
由此可见,我们调用了两次doGet,两次地址都不一样,所以我们可以知道现在链接是有连接池管理的,那么连接池有多少个链接呢?其实连接池的属性是可以配置的。常见的配置有:
- 最大连接数
- 每个主机的最大并发数
PS:什么是每个主机的最大并发数?
解答:如下图所示就是我们所说的主机
没错就是Host,我们在爬取资料的时候,很可能不是只爬取一个网站,但是总的连接数有限,我们就要合理分配每个host可并发的最大连接数。

代码实现:
//创建连接池管理器
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
//设置最大连接数
cm.setMaxTotal(100);
//设置每个主机的最大并发数
cm.setDefaultMaxPerRoute(10);
//使用连接池管理器发请求
doGet(cm);
doGet(cm);4.查漏补缺 请求参数设置
有时候因为网络,或者目标服务器的原因,请求需要更长的时间才能完成,我们需要自定义相关时间。实现如下:
import org.apache.http.HttpEntity;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
public class HttpGetDemo {
private final static Logger LOGGER = LoggerFactory.getLogger(HttpGetDemo.class);
public static void main(String[] args) throws IOException {
//打开浏览器,即创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建HttpGet请求
HttpGet httpGet = new HttpGet("https://blog.csdn.net/lyztyycode");
//设置请求参数
RequestConfig requestConfig = RequestConfig.custom()
.setConnectTimeout(1000) //设置创建连接的最长时间
.setConnectionRequestTimeout(500) //设置获取连接的最长时间
.setSocketTimeout(10 * 1000) //设置数据传输的最长时间
.build();
httpGet.setConfig(requestConfig);
CloseableHttpResponse response = null;
try{
//发起请求,返回响应
response = httpClient.execute(httpGet);
//解析响应,获取数据
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity, "utf8");
LOGGER.info(content);
}
}catch (Exception e){
LOGGER.error("httpget error!", e.getMessage());
}finally {
//释放链接
if(response == null){
response.close();
}
httpClient.close();
}
}
}
5.总结
- HttpClient的使用,包括Get和Post请求的使用和区别。
- Http连接池的配置和使用
- Http应对请求超时的参数设置