mysql优化 个人笔记 (mysql 进阶索引 ) 非礼勿扰 -m14
查询优化
1. 查询慢的可能原因
- 网络
- CPU (时间片)
- IO (磁盘)
- 上下文切换 (线程切换)
- 系统调用
- 生成统计信息
- 锁等待时间
2. 优化数据访问
-
查询性能低的主要原因是访问的数据太多,某些查询不可避免的需要筛选大量的数据,我们可以通过减少访问数据量的方式进行优化
1.1 确定应用程序是否在检索超过需要的大量无效数据 (看执行计划 扫了多少行数据 与自己最终需要的结果比较)-- 这个值比较大 就会全表扫描 select * from a limit 10000,10 -- 可以改成子查询1.2 确认mysql服务器是否在分析大量超过需要的行 (看sql是否能精简 能过滤掉更多的数据) -
是否向数据库请求了不需要的数据
2.1 查询不需要的记录 我们常常误以为mysql只会返回需要的数量,实际上mysql确是先返回全部的结果集 然后再进行计算。在日常开发中,经常是先使用select 查询大量的结果, 然后获取前边N行后关闭结果集。 优化: 查询后加limit2.2 多表关联时 返回全部列。。 select * from table_a left join table_a on table_a .id = table_a .id 优化成 :select a.id,a.name ,b.id fron table_a a left join table_b b on a.id = b.id -- 加指定字段 加别名2.3 总是取出全部列 禁止使用select *2.4 重复查询相同的数据 如果需要不断的重复执行相同的查询,且每次返回的结果一样, 这样的场景呢,我们可以把数据缓存起来,不用每次去查询
3. 执行过程优化
3.1 查询缓存
查询缓存在8版本已经被淘汰了 之前版本有查询缓存
如果查询缓存是打开的,那么mysql会检查这条查询是否命中
如果命中了(还会检查权限)就会返回,没有命中就接着去数据库查询,然后放入缓存(与mybatis的二级缓存一样)
常量表就可以开缓存 其他的表。。。 就算了
3.2 查询优化的处理
mysql 查询完缓存之后,会经过以下几个步骤: 解析sql 、预处理、优化sql执行计划,这几个步骤出现任何错误 都有可能终止查询
3.2.1 语法解析器和预处理
mysql通过关键字将SQL语句进行解析,并生成一颗解析树,mysql解析器将使用mysql语法规则验证和解析查询,例如验证是否使用了错误的关键字、顺序是否正确。
预处理器会进一步检查解析树是否合法,例如 表名、列名是否存在,是否存在歧义,还会有权限验证等
AST(Abstract Syntax Tree) 抽象语法树
calcite.apache.org
3.2.2 查询优化
当语法树没有问题之后呢,相应的要由优化器将其转换成执行计划, 一条查询语句可以使用非常多的执行方式,最后都可以得到对应的结果.
不同的执行方式的效率是不同的,优化器最主要的目的就是选择执行效率最高的执行方式。
myqsl 使用的是基于成本的优化器,在优化的时候会尝试——预测一个查询使用某种查询计划时候的成本,并选择查询成本最小的一个。
CBO 基于成本的优化
RBO 基于规则的优化
3.2.2.1
show status like 'last_query_cost'

数据页大概10.499
来查看查上一个查询的代价,而且它是io_cost和cpu_cost的开销总和,它通常也是我们评价一个查询的执行效率的一个常用指标
(1)它是作为比较各个查询之间的开销的一个依据。
(2)它只能检测比较简单的查询开销,对于包含子查询和union的查询是测试不出来的。
(3)当我们执行查询的时候,MySQL会自动生成一个执行计划,也就是query plan,而且通常有很多种不同的实现方式,它会选择最低的那一个,而这个cost值就是开销最低的那一个。 – 基于成本的优化
(4)它对于比较我们的开销是非常有用的,特别是我们有好几种查询方式可选的时候。
3.2.2.2
在很多情况下 mysql会选择错误的执行计划
(1) 统计信息不准确
InnoDB 因为其MVCC的架构,并不能准确维护一个数据表的行数的精确信息
(2) 执行计划的成本计算,不等于实际执行的成本
有时候,一些执行计划虽然需要读很多页,但是他的成本更小,因为如果这些页都是顺序读,或者这些页都在内存中的话,那么它的访问成本将很小。
mysql并不知道哪些在磁盘,哪些在内存中,所以查询执行计划的时候 无法做到准确值,只能做预估值
(3) mysql 的最优可能可能与你想的不一样
你想a join b join c 按顺序执行,mysql不一定按照你的意愿来
(4) mysql 不考虑其他并发执行的查询
他不知道 会有多少个查询来袭
(5) mysql不会考虑 不受其控制的操作成本
执行存储过程,或用户自定义的函数
3.2.2.3 优化器的优化策略
静态优化:
直接对解析树进行分析 完成优化
动态优化:
动态优化与查询的上下文有关,也可能与取值和索引对应的行数有关
mysql对查询的静态优化,只需要一次,但是对动态优化在每次执行时都需要评估
3.2.2.4 优化器的优化类型
(1)重新定义关联表的顺序
数据表的关联并不一定总是按照在查询中指定的顺序进行,决定关联顺序是优化器很重要的一个功能
我们 a join b join c 可能会优化成 b c a
(2)外连接转换为内连接,内连接效率高于外连接
内连接 inner join
外连接 left join 、 right join
内连接获取的数据量少
(3)使用等价变换规则,mysql可以使用一些等价变化规则来简化和规划我们的表达式
等价变换规则是啥:
比如 select a.id from bb where phone in (‘18888888888’,‘1999999999’)
的等价就是
select a.id from bb where phone=‘18888888888’ or phone=‘1999999999’
(4)优化count min max
索引和列值是否可以为空,可以帮助mysql优化这类表达式。
例如: 要找到某一列的最小值,只需要查询索引的最最端记录,不需要全表扫描
(5)预估并转换为常数表达式
当mysql检测到一个表达式可以转换为常数时,就会一直把该表达式作为常数处理进行处理
select * from bb where phone ='18888888888'
select * from bb where phone > 18888888887 and phone <18888888889
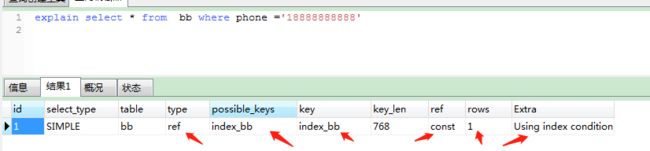
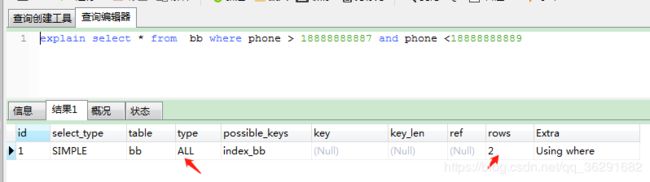
使用等值查询 会 快 哦
(6) 索引覆盖扫描
前一章说过了
(7) 子查询优化
mysql 在某些情况下,可以将子查询转换为一种效率更高的形式,
从而减少多个查询多次对数据的访问
例如:经常查询的数据放入缓存中
(8)等值传播
如果两个列的值通过等式关联,那么mysql能够把其中一个列的where 条件传递到另一个上
select ra.id,ra.name,rb.name as rbname from ra inner join rb using(id) where ra.rid < 6

这条语句使用rid字段进行了关联 ,这个字段不仅适用于ra表 也适用于rb表
select * from ra inner join rb using(id) where ra.rid <6 and rb.id <6

3.2.2.5 关联查询
前一篇说过
注意:
(1) join buffer 会缓存所有参与的列 而不只是join列
(2) 可以通过调整join_buffer_size 缓存的大小
(3) join_buffer_size默认是256k, join_buffer_size 在Mysql5.1.22之前最大是4G-1
之后版本才能在64位操作系统中申请大于4G 的join buffer 空间
(4) 使用block nested-loop join 算法需要开启我们的优化器管理配置
optimizer_switch的设置 block_nested_loop 为on 默认为开启
-- 可以查看开关状态
show VARIABLES like '%optimizer_switch%'
(5)案例演示
查看不同的顺序执行方式对查询性能的影响:
explain SELECT
film.film_id,
film.title,
film.release_year,
actor.actor_id,
actor.first_name,
actor.last_name
FROM
film
INNER JOIN film_actor USING (film_id)
INNER JOIN actor USING (actor_id);
查看执行的成本:
show status like 'last_query_cost';
按照自己预想的规定顺序执行:**(STRAIGHT_JOIN)**
SELECT STRAIGHT_JOIN
film.film_id,
film.title,
film.release_year,
actor.actor_id,
actor.first_name,
actor.last_name
FROM
film
INNER JOIN film_actor USING (film_id)
INNER JOIN actor USING (actor_id);
查看执行的成本:
show status like 'last_query_cost';
---
哪个效率高 还是要在实际业务中 具体分析
3.2.2.6排序优化
-
两次传输排序
第一次数据读取是将排序的字段读取出来,然后进行排序, 第二次是将排好序的结果按照需要去读取数据行。 这种方式效率比较低,原因是第二次读取数据的时候已经排序好了, 需要去读取所有记录,这个时候更多的是随机IO ,读取数据成本会比较高 优势:排序时尽可能少的存储数据,让排序缓冲区可以更多的容纳行数来进行排序操作。 -
单次传输排序
很简单,就是把所有数据一次拿出来,根据需要的列进行排序 -
注意
当需要排序的列总大小加上order by 的列的大小 超过max_length_for_sort_data定义的字节, mysql会选用双次排序,反之使用单次排序。 当然我们可以设置这个值来选择排序方式
3. 优化特定类型的查询
3.1 优化count()查询
1.
count(1) count(*) 效果是一样的 !!
count(字段) 要慢一点 是因为他会比较是否为空
如果想要过滤掉某一列为NULL的行,那么就使用count(字段) 否则建议使用count(*)
2.
有人说MyISAM引擎count函数比较快:
这是有前提条件的,没有任何where条件的情况下比较快!
3.
使用近似值。
不需要完全精确的总条数的时候,可以参考使用近似值来代替。
比如可以使用explain 来获取近似值。
在OLAP的应用中,需要计算一个列值的基数,有一个近似值算法hyperloglog
4.
可以增加汇总表
可以存入缓存
3.2 关联查询优化
1. 确保on或using 子句的列上有索引。
2. 确保任何group by 和 order by 中的表达式只涉及到一个表中的列
这样mysql 才有可能使用索引来优化这个过程
3.3 优化子查询
尽可能使用关联查询 而不是子查询
子查询有临时表,临时表也是IO
3.4 分组优化
-- 创建表
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (
`actor_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb4;
-- 测试1
select count(1),first_name,last_name from actor
group by first_name,last_name
-- 新的认知 。。
select count(1),first_name,last_name from actor
group by actor.actor_id
-- 优化不优化 咱不知道 但是这个语法没报错 这个是之前不知道的
3.4 知识点
set @abcd:=1;
select @abcd; -- 结果是1
select @abc:=@abc+1; -- 结果是2 就是会自增 然后返回自增的值
开窗函数 可以了解一下
做个记录:
sakila数据库说明
ZIP格式:http://downloads.mysql.com/docs/sakila-db.zip
tar格式 http://downloads.mysql.com/docs/sakila-db.tar.gz
官方文档 http://dev.mysql.com/doc/sakila/en/index.html
解压后得到三个文件:
-
sakila-schema.sql 文件包含创建Sakila数据库的结构:表、视图、存储过程和触发器
-
sakila-data.sql文件包含:使用 INSERT语句填充数据及在初始数据加载后,必须创建的触发器的定义
-
sakila.mwb文件是一个MySQL Workbench数据模型,可以在MySQL的工作台打开查看数据库结构。
导入数据 有好多表 做测试使用