muduo base库学习笔记 10——日志类封装
日志的作用:
1,开发过程中,有助于调试错误,能更好地理解程序
2,运行过程中,日志能帮助我们诊断系统故障并处理、记录系统运行状态
这代码就优点长了喔
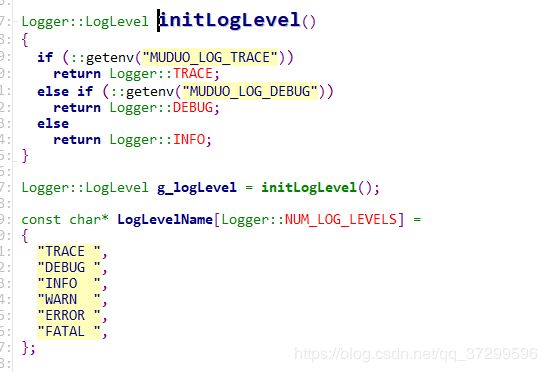
日志级别
- TRACE 指出比DEBUG粒度更细的一些信息时间(开发过程中使用)
- DEBUG 指出细粒度信息事件对调试应用程序是非常有帮助的(开发过程中使用
- INFO 表明消息在粗粒度级别上突出强调应用程序的运行过程
- WARN 系统能正常运行,但可能会出现潜在错误的情形
- ERROR 指出虽然发生错误事件,但仍然不影响系统的继续运行
- FATAL 指出每个严重的错误事件将会导致应用程序的退出
在开发中可以选择TRACE或者DEBUG,但是着信息太多了,所以可以在发布或者稳定之后选择INFO级别, muduo默认的日志应用级别是INFO,在INFO下TRACE和DEBUG级别下的日至就不会被输出了,日志的输出级别在运行时可以调整
日志类Logger的使用流程
用时序图理解:
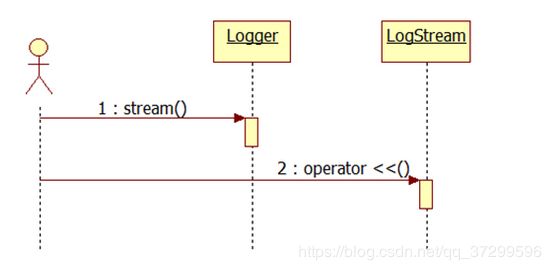
首先创建一个Logger对象,然后调用stream()方法,返回一个LogStream的对象,再调用LogStream的重载运算符operator <<()输出日志
这是比较宏观的
实际上的实现会更加细一点,在Logger类的内部有嵌套Impl类来负责实际的实现, Logger类就是负责一些日志的级别,是外层的一个日志类;而Impl类是借助LogStream类来输出日志的,LogStream对象重载<<运算符来输出日志。
事实上,日志类是先输出到缓冲区FixedBuffer,然后再输出到标准输出或文件, 通过g_output函数来指定输出到哪里,借助g_flush函数,因为g_output也是只能输出到指定设备/文件 的缓冲区,g_flush函数刷新一下才能真正到指定位置

Logger构造函数
构造Logger对象(Logging.cc文件中)
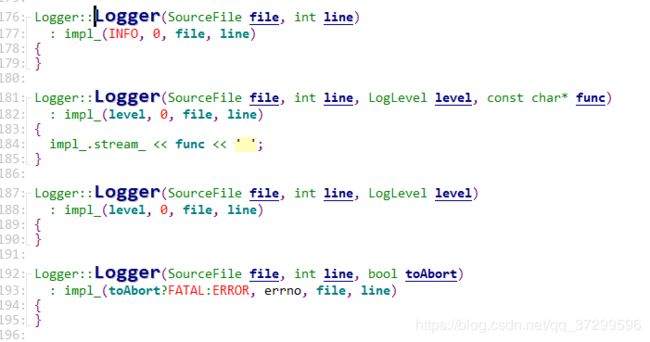
看一个
Logger::Logger(SourceFile file, int line, LogLevel level, const char* func)/*文件,行,级别,函数名称*/
: impl_(level, 0, file, line)/*初始化——构造嵌套类的对象成员,, 调用其构造函数*/
{
//因为在初始化的时候已经调用了Impl类的构造函数
//而Impl类构造的时候会将时间级别名称输出到缓冲区了
impl_.stream_ << func << ' ';//而函数名称的格式化输出是在Logger也就是这一行代码实现的
}
在 Logging.h头文件中的嵌套类Impl如下:有一个对象成员Impl impl_,

Impl类
Logger::Impl::Impl(LogLevel level, int savedErrno, const SourceFile& file, int line)
: time_(Timestamp::now()),
stream_(),
level_(level),
line_(line),
basename_(file)
{
formatTime();//格式化时间并输出到了缓冲区中
CurrentThread::tid();//缓存当前线程的id
stream_ << T(CurrentThread::tidString(), CurrentThread::tidStringLength());//调用这个id所对应的字符串,并格式化输出到缓存区当中
stream_ << T(LogLevelName[level], 6);//再格式化级别并输出
if (savedErrno != 0)//级别不等于0的话还要将信息也输出出去
{
stream_ << strerror_tl(savedErrno) << " (errno=" << savedErrno << ") ";
}
}
void Logger::Impl::formatTime()
{
int64_t microSecondsSinceEpoch = time_.microSecondsSinceEpoch();
time_t seconds = static_cast<time_t>(microSecondsSinceEpoch / Timestamp::kMicroSecondsPerSecond);
int microseconds = static_cast<int>(microSecondsSinceEpoch % Timestamp::kMicroSecondsPerSecond);
if (seconds != t_lastSecond)
{
t_lastSecond = seconds;
struct tm tm_time;
if (g_logTimeZone.valid())
{
tm_time = g_logTimeZone.toLocalTime(seconds);
}
else
{
::gmtime_r(&seconds, &tm_time); // FIXME TimeZone::fromUtcTime
}
int len = snprintf(t_time, sizeof(t_time), "%4d%02d%02d %02d:%02d:%02d",
tm_time.tm_year + 1900, tm_time.tm_mon + 1, tm_time.tm_mday,
tm_time.tm_hour, tm_time.tm_min, tm_time.tm_sec);
assert(len == 17); (void)len;
}//格式化成"%4d%02d%02d %02d:%02d:%02d"这种格式
if (g_logTimeZone.valid())
{
Fmt us(".%06d ", microseconds);//微秒 格式化一下
assert(us.length() == 8);
stream_ << T(t_time, 17) << T(us.data(), 8);//stream_进行输出,重载了<<,输出到缓冲区,
}
else
{
Fmt us(".%06dZ ", microseconds);
assert(us.length() == 9);
stream_ << T(t_time, 17) << T(us.data(), 9);
}
}
void Logger::Impl::finish()
{
stream_ << " - " << basename_ << ':' << line_ << '\n';
}
提一下,对stream()的实现也是用的Impl类:LogStream& stream() { return impl_.stream_; }
那目前位置,日志仅仅只是输出到了缓冲区中,还没有输出到指定设备,这个标准设备可以是标准输出也可以是文件,那什么时候才可以输出到标准设备呢?
看一个Logger类的使用示例:
#define LOG_INFO if(muduo::Logger::loglevel() <= muduo::Logger::INFO) muduo::Logger(__FILE__, __LIFE__).stream()
LOG_INFO <<"info ...";//这就是使用方式
muduo::Logger(__FILE__, __LINE__).stream() << "info...";//传递代码所在的文件名和行号参数
因为Logger是无名对象,无名对象在muduo::Logger(__FILE__, __LINE__).stream() << "info...";执行完之后就要销毁,这时候就要调用Logger类的析构函数,在析构类中调用了g_output、g_flush来输出到日志实际所对应的设备
Logger析构函数
Logger::~Logger()
{
impl_.finish();
const LogStream::Buffer& buf(stream().buffer()); // 获取缓冲区,保存到buf中
g_output(buf.data(), buf.length()); //g_output 默认输出到stdout
// 当日志级别为FATAL时,flush设备缓冲区并终止程序
if (impl_.level_ == FATAL)
{
g_flush();
abort();
}
}
g_output的默认输出代码在defalutFlush代码块中
以上就是对Logger类的使用流程学习,即日志的内部工作过程
LogStream类的封装实现输出
我们知道Logger类通过Impl类进行输出,在Impl类又是借助LogStream类的对象调用operator<<输出到缓冲区FixedBuffer,现在就来看看这部分的内容
缓冲区类FixedBuffer
FixedBuffer的实现为一个模板类,传入一个非类型参数SIZE表示缓冲区的大小。通过成员 data_首地址、cur_指针、end()完成对缓冲区的各项操作
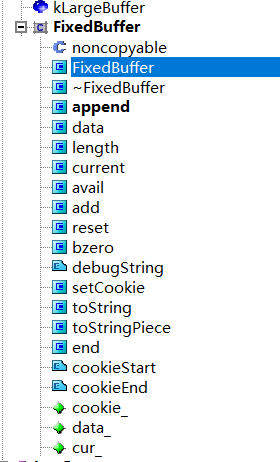
数据成员有:
cookie_:一个函数指针,在构造函数,没有什么作用
data_:就是缓冲区,它的容量通过非类型参数SIZE传过来,
cur_:当前指针
缓冲区的设计:
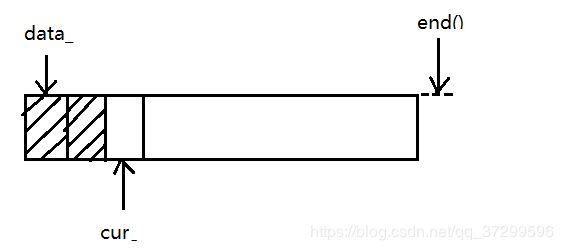
end() - cur_就是当前可用的空间,成员函数中的avail()
const char* debugString(); 在数据后面加\0表示成字符串
其他函数看代码就很明了
LogStream类
LogStream类包含上述的一个缓冲区,我们从代码可以看出这个函数主要就是在实现输出运算符在各种类型上的重载
但是,我们在实现中发现它不是int类型转换成int类型,然后调formatInteger()函数,返回LogStream对象的指针
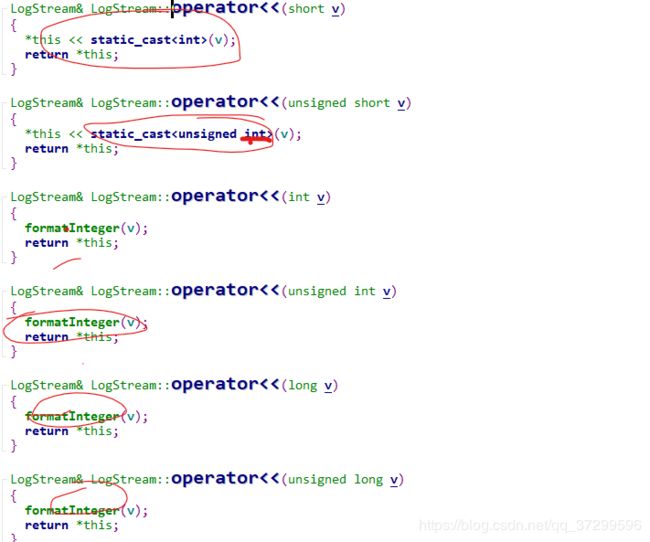
我们来看看这个formatInteger的实现:
然后又发现,它并不是直接存放int类型的数据,而是convert函数将整数转换成字符串类型在存放到缓冲区
template<typename T>
void LogStream::formatInteger(T v)
{
// kMaxNumericSize的值为32,即如果buffer的空间足够大
if (buffer_.avail() >= kMaxNumericSize)
{
size_t len = convert(buffer_.current(), v);//转换成字符串
buffer_.add(len);
}
}
convert函数
先解释一下*p++ = zero[lsd];,
 指针zero指向
指针zero指向degits[]中的’0’,zero[lsd]表示再偏移lsd的位置,看代码
template<typename T>
size_t convert(char buf[], T value)
{
T i = value;
char* p = buf;
do
{
int lsd = static_cast<int>(i % 10);//得到最后一个数字 lsd = last digit
i /= 10;//update i
*p++ = zero[lsd];//假设最后一个数字是3,那么zero[lsd]便取到了digits中间那个0往右第三个,就是3这个字符保存到了缓冲区
} while (i != 0);
if (value < 0)//为负数添加负号
{
*p++ = '-';
}
*p = '\0';
std::reverse(buf, p);//将字符串逆转
return p - buf;
}
还有指针类型的输出重载
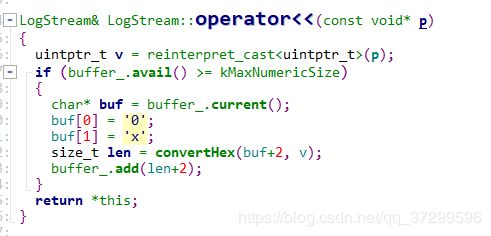 首先将指针强制转换成
首先将指针强制转换成uintptr_t类型,uintptr_t对64位平台来说就是unsigned long int,也是转换成了整数类型咯,类似的,再用convertHex转换成16进制的地址存放进缓冲区

Fmt类
里面是一个成员模板,将整数val按照fmt的格式进行格式化到buf_中
首先要断言T必须是算数类型:
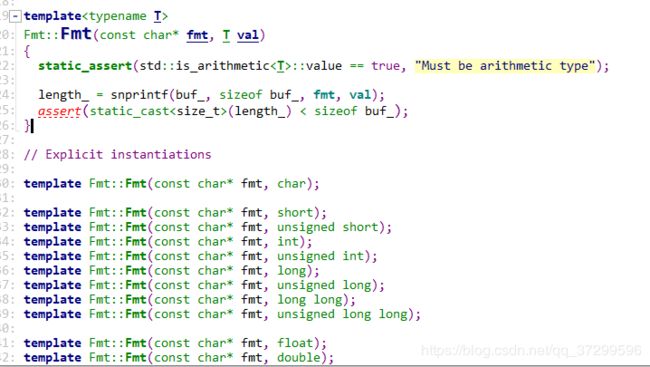
最后是进行了特化,只有这么几种算数类型可以这样格式化
以上就是LogStream,就是重载运算符格式化输出到缓冲区中
日志滚动
muduo库日志滚动的条件通常有两个:
文件大小:每写满1G换下一个文件
时间:每天零点新建一个文件,不管前一个文件是否写满
muduo库通过LogFile类实现日志滚动
LogFile类实现日志滚动
其中const string basename_; const off_t rollSize_; const int flushInterval_;分别为basename,日志文件达到rollSize_就换一个新文件,以及日志写入的间隔时间(不是每次写日志都会写入到指定文件中,而是间隔一段时间才会写入), count是一个计数器,初始化为0,当达到checkEveryN的时候就会去检查是否需要换一个日志文件,或者是否需要将日志写入到实际文件中;有一个mutex_互斥量;startOfPeriod_开始记录日志时间(调整至零点的时间)、lastRoll_上一次滚动日志文件时间、lastFlush上一次日志写入文件时间,这三个量都是为了看是否到达日志滚动的时间;file_是一个嵌套类, kRollPerSeconds_ = 60*60*24就是一天,过一天才会滚动一次日志,也就是为什么我们要将startOfPeriod_调整至零点的时间,因为一天之内的都是不会滚动日志的
成员函数:append()将长度为len的内容添加到日志文件中,flush()清空缓冲区,append_unlock()不加锁的方式添加,getLog FileName()获取日志文件名称,滚动日志的时候是需要获取日志文件的名称的, rollFile()滚动日志
日志文件的文件名设计:
例:logfile_test.20120603-144022.hostname.3605.log
第一部分如“logfile_test”是日志文件的basename;
第二部分如“20120603-144022”是日志的创建时间(UTC时间);
第三部分如“hostname”是主机名称;
第四部分如“3605”是进程id;
最后是日志后缀名“.log”。
具体实现就在LogFile.cc中:
日志的滚动实现
void LogFile::rollFile()
{
time_t now = 0;
string filename = getLogFileName(basename_, &now);//首先获取文件名称,并返回时间
// 注意,这里先除以kRollPerSeconds_(一天)、后乘kRollPerSeconds_表示,就是为了达到整数倍
// 对齐至kRollPerSeconds_(24*60*60)整数倍,也就是时间调整到当天零点。
time_t start = now / kRollPerSeconds_ * kRollPerSeconds_;
// 如果now大于上一次滚动日志文件时间就滚动
if (now > lastRoll_)
{
lastRoll_ = now; // lastRoll_是上一次滚动日志文件时间
lastFlush_ = now; // lastFlush_是上一次日志写入文件时间
startOfPeriod_ = start; // startOfPeriod_是开始记录日志时间(调整至零点的时间)
file_.reset(new File(filename));
}
}
获取文件日志名:
string LogFile::getLogFileName(const string& basename, time_t* now)
{
string filename;
// 预留basename的size加上64字节的空间
filename.reserve(basename.size() + 64);
filename = basename;
char timebuf[32];
char pidbuf[32];
struct tm tm;
*now = time(NULL);
gmtime_r(now, &tm); // 线程安全,获取日志创建时间
strftime(timebuf, sizeof timebuf, ".%Y%m%d-%H%M%S.", &tm); // 将时间格式化
filename += timebuf;
filename += ProcessInfo::hostname(); // 用到了gethostname()返回主机名
snprintf(pidbuf, sizeof pidbuf, ".%d", ProcessInfo::pid());
filename += pidbuf;
filename += ".log";
return filename;
}
写入日志时,判断是否需要滚动日志
文件名:LogFile.cc
void LogFile::append_unlocked(const char* logline, int len)
{
file_->append(logline, len);
// 写入的字节数大于rollSize_时要滚动
if (file_->writtenBytes() > rollSize_)
{
rollFile();
}
else
{
// 计数值count_超过kCheckTimeRoll_时也要判断是否需要滚动
if (count_ > kCheckTimeRoll_)
{
count_ = 0;
time_t now = ::time(NULL);
time_t thisPeriod_ = now / kRollPerSeconds_ * kRollPerSeconds_;
if (thisPeriod_ != startOfPeriod_)
{
rollFile();
}
// 大于flush的间隔时间时则写入日志,不滚动
else if (now - lastFlush_ > flushInterval_)
{
lastFlush_ = now;
file_->flush();
}
}
else
{
++count_;
}
}
}
Logging:写入对应设备的整个工作流程
LogStream:输入输出的方法
LogFile:不是一写日志就要写入到文件中(设备中),那什么时候日志滚动如何rollFile()
看看测试代码logging_test.cc
main函数中,启动了线程池
#include "muduo/base/Logging.h"
#include "muduo/base/LogFile.h"
#include "muduo/base/ThreadPool.h"
#include "muduo/base/TimeZone.h"
#include 异步日志
如果有多个线程要对这个文件写入日志的时候,我们会先将日志发送到某一个线程,在该线程中排队,让这个线程对文件进行写入
这就叫做异步日志, muduo也实现了异步日志AsyncLogging,之后再看