接口自动化-简单实现期望结果写回excel表格/同时运行一个excel多个sheet
一、加深对自动化的了解
思考一下几个问题:
1、什么是自动化?—>建立在功能测试基础上的“功能自动化”
2、什么时候比较适合做自动化?---->功能相对稳定的时候
3、自动化帮助我们解决那些事情?---->回归测试/比较稳定的功能在上线之前做一次最快的检查
4、最佳实现:在excel准备好测试数据—>被代码读取到—>直接进行测试---->把测试结果存到excel----->出具测试报告 +Jenkins做集成平台
项目:
1、引入单元测试、HTML测试报告、断言结果
2、引入ddt
3、添加字段,存入测试结果
4、引入try...except....finally
5、完成用例的可配置:想跑那条用例,就在配置文件写好,难点:考虑多模块情况
文件目录:
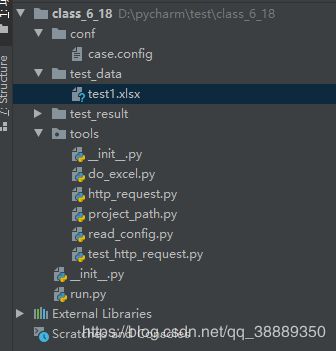
1、路径的可配置:相对路径执行的时候:文件太多,可能会出现错误,绝对路径:换个电脑或者整到Jenkins里面,就会报错,所以采用这种方式,可避免上述的问题
import os
#根路径
project_path = os.path.split(os.path.split(os.path.realpath(__file__))[0])[0] #获取根路径
#case路径
test_case_path = os.path.join(project_path,'test_data','test1.xlsx')
#生成HTML报告路径
test_report_path = os.path.join(project_path,'test_result','html_report','test_htmlreport.html')
#配置文件路径
case_config_path = os.path.join(project_path,'conf','case.config')
2、引入ddt(处理数据)
引入try…except…finally(finally的主要目的是不管运行成功、失败,结果都会存储到excel
test_http_request.py文件
import unittest
from http_request import HttpRequest
from ddt import ddt,data
from project_path import * #同一个目录导入
from do_excel import DoExcel
#get_data()里面的‘python’可换成别的sheet,用来获取不同模块数据
test_data = DoExcel().get_data(test_case_path,'python')
@ddt()
class TestHttpRequest(unittest.TestCase):
def setUp(self):
pass
@data(*test_data)
def test_api1(self,item):
res = HttpRequest().http_request(item['url'],item['data'],item['method'])
try:
self.assertEqual(item['except'],res.json()['code'])
TestResult = 'pass' #成功
except AssertionError as e:
TestResult = 'Failed' #失败
raise e
finally: #不管怎样,finally都会执行,所以将写入excel的方法写在该模块,不然用例执行失败了,也没法写入excel
#write_back()里面的‘python’可换成别的sheet,用来写回不同模块数据
DoExcel().write_back(test_case_path,item['sheet_name'],item['case_id']+1,str(res.json()),TestResult)
print res.json()
def tearDown(self):
pass
3、多个用例同时执行
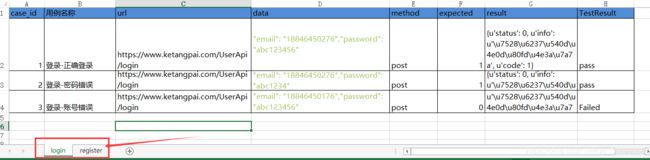
(1)、写多个模块,不同的模块,不同的模块用不同的test_http_request.py文件,run里面不断加载
from tools import test_http_request
import unittest
from tools.project_path import *
import HTMLTestRunner
suite = unittest.TestSuite()
loader = unittest.TestLoader()
#通过添加不同的模块,来执行不同的sheet用例
suite.addTest((loader.loadTestsFromModule(test_http_request)))
with open(test_report_path,'wb') as file:
runner = HTMLTestRunner.HTMLTestRunner(
stream=file,
verbosity=2,
title="单元测试报告",
description="python单元测试报告-第一次",
tester="么么哒"
)
runner.run(suite)
(2)、通过配置文件去决定执行那个模块的测试用例
配置文件的意思是:执行【login】sheet的所有用例,执行【register】sheet的第二条用例
[MODE]
mode = {"login":"all",
"register":[2]}
读取配置文件类【read_config.py】:
import configparser
class ReadConfig:
@staticmethod
def get_config(file_path,section,option):
cf = configparser.ConfigParser() #创建实例
cf.read(file_path) #获取文件
return cf[section][option]
根据配置文件来读取数据【do_excel.py】
from openpyxl import load_workbook
from read_config import ReadConfig
from project_path import *
class DoExcel:
def get_data(self,file_name):
wb = load_workbook(file_name)
#获取的数据是字符串,eval了,就变成字典了
mode = eval(ReadConfig.get_config(case_config_path,'MODE','mode')) #获取配置文件可运行的测试用例
test_data = []
for key in mode: #遍历这个存在配置文件的字典
sheet = wb[key]
if mode[key] == 'all':
for i in range(2,sheet.max_row+1):
row_data = {}
row_data['case_id'] = sheet.cell(i,1).value
row_data['url'] = sheet.cell(i,3).value
row_data['data'] = sheet.cell(i,4).value
row_data['method'] = sheet.cell(i,5).value
row_data['except'] = sheet.cell(i,6).value
row_data['sheet_name'] = key
test_data.append(row_data)
else:
for case_id in mode[key]:
row_data = {}
row_data['case_id'] = sheet.cell(case_id+1, 1).value
row_data['url'] = sheet.cell(case_id+1, 3).value
row_data['data'] = sheet.cell(case_id+1, 4).value
row_data['method'] = sheet.cell(case_id+1, 5).value
row_data['except'] = sheet.cell(case_id+1, 6).value
row_data['sheet_name'] = key
test_data.append(row_data)
return test_data
def write_back(self,file_name,sheet_name,i,result,TestResult):
wb = load_workbook(file_name)
sheet = wb[sheet_name]
sheet.cell(i,7).value = result
sheet.cell(i,8).value = TestResult
wb.save(file_name)