ElasticSearch ES 全局映射 动态模板 文档映射 IK分词器 标准查询 DSL
认识ElasticSearch
1.为什么要使用ElasticSearch
虽然全文搜索领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
实际项目中,我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON/XML通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并在需要扩容时方便地扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。
2.ElasticSearch(简称ES)
ES即为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,其第一个版本于2010年2月出现在GitHub上并迅速成为最受欢迎的项目之一。
首先,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。
ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
不过,ES的核心不在于Lucene,其特点更多的体现为:
分布式的实时文件存储,每个字段都被索引并可被搜索
分布式的实时分析搜索引擎
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
高度集成化的服务,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之
交互。
上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它拥有开瓶即饮的效果(安装即可使用),只需很少的学习既可在生产环境中使用。
3.ES的使用者及类似框架
典型使用案例
①Github(美国)使用Elasticsearch搜索20TB的数据,包括13亿的文件和1300亿行的代码.
②Foursquare实时搜索5千万地点信息?Foursquare每天都用Elasticsearch做这样的事.
③德国SoundCloud使用Elasticsearch来为1.8亿用户提供即时精准的音乐搜索服务.
④Mozilla公司以火狐著名,它目前使用 WarOnOrange 这个项目来进行单元或功能测试,测试的结果以 json的方式索引到elasticsearch中,开发人员可以非常方便的查找 bug.
⑤Sony公司使用elasticsearch 作为信息搜索引擎.
类似框架
① Solr(重量级对手)
Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎,Solr4 还增加了NoSQL支持。
Solr和ES比较:
Solr 利用 Zookeeper 进行分布式管理,支持更多格式的数据(HTML/PDF/CSV),官方提供的功能更多在传统的搜索应用中表现好于 ES,但实时搜索效率低。
ES自身带有分布式协调管理功能,但仅支持json文件格式,本身更注重于核心功能,高级功能多有第三方插件提供,在处理实时搜索应用时效率明显高于 ES。
② Katta
基于 Lucene 的,支持分布式,可扩展,具有容错功能,准实时的搜索方案。
优点:开箱即用,可以与 Hadoop 配合实现分布式。具备扩展和容错机制。
缺点:只是搜索方案,建索引部分还是需要自己实现。在搜索功能上,只实现了最基本的需求。成功案例较少,项目的成熟度稍微差一些。
③ HadoopContrib
Map/Reduce 模式的,分布式建索引方案,可以跟 Katta 配合使用。
优点:分布式建索引,具备可扩展性。
缺点:只是建索引方案,不包括搜索实现。工作在批处理模式,对实时搜索的支持不佳。
4.小结
ElasticSearch简化了全文检索lucene的使用,同时增加了分布式的特性,使得构建大规模分布式全文检索变得非常容易。
ES安装及使用说明
1.包含的内容
ES的安装比较简单,只需要官方下载ES的运行包,然后启动ES服务即可。
ES的使用主要是通过能够发起HTTP请求的终端来接入,比如Poster插件、CURL、kibana5等。
2.安装ES
ES服务只依赖于JDK,推荐使用JDK1.7+。
① 下载ES安装包
官方下载地址:https://www.elastic.co/downloads/elasticsearch
本课程以在window环境下,ES 5.2.2版本为例,下载对应的ZIP文件
 ② 运行ES
② 运行ES
bin/elasticsearch.bat

③ 验证
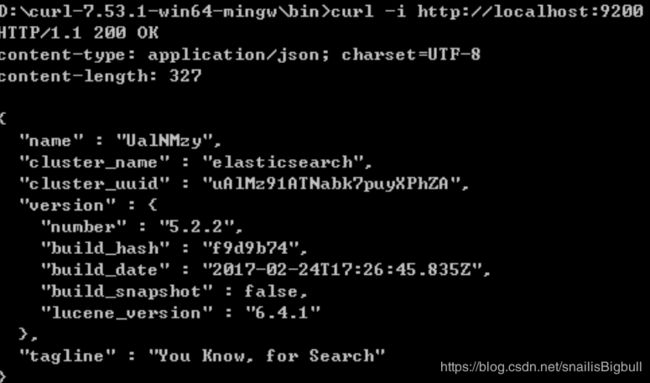
访问:http://localhost:9200/

看到上图信息,恭喜你,你的ES集群已经启动并且正常运行.
3.ES交互方式
① 基于RESTful API
ES和所有客户端的交互都是使用JSON格式的数据.
其他所有程序语言都可以使用RESTful API,通过9200端口的与ES进行通信,在开发测试阶段,你可以使用你喜欢的WEB客户端, curl命令以及火狐的POSTER插件方式和ES通信。
Curl命令方式:
默认windows下不支持curl命令,在资料中有curl的工具及简单使用说明。
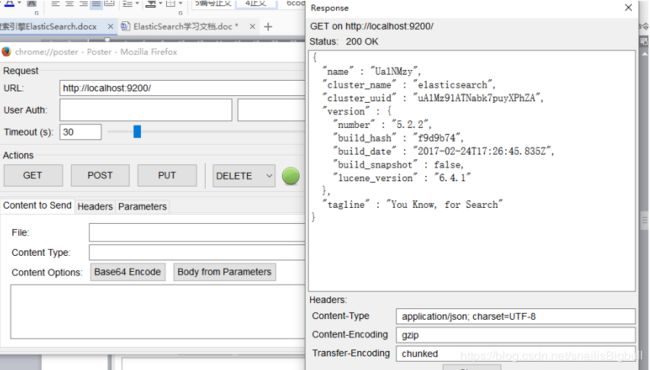
火狐的POSTER插件界面:
类似于Firebug,在火狐的“扩展”中搜索“POSTER”,并安装改扩展工具。

使用POSTER模拟请求的效果
② Java API
ES为Java用户提供了两种内置客户端:
节点客户端(node client):
节点客户端以无数据节点(none data node)身份加入集群,换言之,它自己不存储任何数据,但是它知道数据在集群中的具体位置,并且能够直接转发请求到对应的节点上。
传输客户端(Transport client):
这个更轻量的传输客户端能够发送请求到远程集群。它自己不加入集群,只是简单转发请求给集群中的节点。
两个Java客户端都通过9300端口与集群交互,使用ES传输协议(ES Transport Protocol)。集群中的节点
之间也通过9300端口进行通信。如果此端口未开放,你的节点将不能组成集群。
注意
Java客户端所在的ES版本必须与集群中其他节点一致,否则,它们可能互相无法识别。
4.扩展:Restful认识
Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作。
使用Restful的好处:
1、透明性,暴露资源存在。
2、充分利用 HTTP 协议本身语义。
3、无状态,这点非常重要。在调用一个接口(访问、操作资源)的时候,可以不用考虑上下文,不用考虑当前状态,极大的降低了复杂度。
4、HTTP 本身提供了丰富的内容协商手段,无论是缓存,还是资源修改的乐观并发控制,都可以以业务无关的中间件来实现。
Restful的典型特征:
① Server提供的RESTful API中,URL中只使用名词来指定资源。
“资源”是REST架构或者说整个网络处理的核心。比如:
GET http://api.itsource.cn/emp/323: 获取323号员工的基本资料;
GET http://api.itsource.cn/emps: 获取源码时代所有员工资料列表;
②== REST 是面向资源的,这个概念非常重要,而资源是通过 URI 进行暴露
URI 的设计只要负责把资源通过合理方式暴露出来就可以了。对资源的操作与它无关,所以REST 通过 URI 暴露资源时,会强调不要在 URI 中出现动词==。
比如:左边是错误的设计,而右边是正确的
GET /rest/api/getDogs -> GET /rest/api/dogs 获取所有小狗狗
GET /rest/api/addDogs -> POST /rest/api/dogs 添加一个小狗狗
POST /rest/api/editDogs/12 -> PUT /rest/api/dogs/12 修改一个小狗狗
POST /rest/api/deleteDogs/12 -> DELETE /rest/api/dogs/12 删除一个小狗狗
左边的这种设计,很明显不符合REST风格,URI 只负责准确无误的暴露资源,而 getDogs/addDogs…已经包含了对资源的操作,这是不对的。相反右边却满足了,它的操作是使用标准的HTTP动词来体现。
③ 用HTTP协议里的动词来实现资源的添加,修改,删除等操作。
即通过HTTP动词来实现资源的状态扭转:
GET 用来获取资源,
POST 用来新建资源(也可以用于更新资源),
PUT 用来更新资源,
DELETE 用来删除资源。
比如:
GET http://api.itsource.cn/emp/323
POST http://api.itsource.cn/emp/232: 修改一个员工
PUT http://api.itsource.cn/emp: 添加员工资料
DELETE http://api.itsource.cn/emp/323: 删除323号员工
5.辅助管理工具Kibana5
① Kibana5.2.2下载地址:https://www.elastic.co/downloads/kibana
② 解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
③ 启动Kibana5 : bin\kibana.bat
④ 默认访问地址:http://localhost:5601
green,绿色。这代表所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow,黄色。所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果更多的分片消失,你就会丢数据了。所以可把 yellow 想象成一个需要及时调查的警告。
red,红色。至少一个主分片以及它的全部副本都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。如果你只有一台主机的话,其实索引的健康状况也是 yellow,因为一台主机,集群没有其他的主机可以防止副本,所以说,这就是一个不健康的状态,因此集群也是十分有必要的

Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
Timelion:Timelion是一个kibana时间序列展示组件(暂时不用)
Dev Tools :Console(同CURL/POSTER,操作ES代码工具,代码提示,很方便)
Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性。
6.小结
本节的重点是对Resultful的认识以及服务管理工具Kibana5的基本使用。
4.ES数据管理
4.1.什么是ES中的文档
ES是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES使用Javascript对象符号(JavaScript Object Notation),也就是JSON,作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。
对文档自身的描述 元数据(metadata)
ES存储的一个员工文档的格式示例:
{
"email": "[email protected]",
"name": "倪先华",
"info": {
"addr": "四川省成都市",
"age": 30,
"interests": [ "美食", "美女" ]
},
"join_date": "2016-06-01"
}
尽管原始的 employee对象很复杂,但它的结构和对象的含义已经被完整的体现在JSON中了,在ES中将对象转化为JSON并做索引要比在表结构中做相同的事情简单的多。
一个文档不只有数据。它还包含元数据(metadata)—关于文档的信息。三个必须的元数据节点是:

元数据

_index:索引库,类似于关系型数据库里的“数据库”—它是我们存储和索引关联数据的地方。
_type:在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮件。可以是大写或小写,不能包含下划线或逗号。我们将使用 employee 做为类型名。
_id:与 _index 和 _type 组合时,就可以在ELasticsearch中唯一标识一个文档。当创建一个文档,你可以自定义 _id ,也可以让Elasticsearch帮你自动生成。
另外还包括:_uid文档唯一标识(_type#_id)
_source:文档原始数据
_all:所有字段的连接字符串
2.文档的增删改
我们以员工对象为例,我们首先要做的是存储员工数据,每个文档代表一个员工。在ES中存储数据的行为就叫做索引(indexing),文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以简单的对比传统数据库和ES的对应关系:
关系数据库(MYSQL) -> 数据库DB-> 表TABLE-> 行ROW-> 列Column
Elasticsearch -> 索引库Indexs -> 类型Types -> 文档Documents -> 字段Fields
ES集群可以包含多个索引(indices)(数据库),每一个索引库中可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
创建索引文档
①使用自己的ID创建:
PUT {index}/{type}/{id}
{
"field": "value",
...
}
②ES内置ID创建:
POST {index}/{type}/
{
"field": "value",
...
}
①②ES响应内容:
{
"_index": "itsource",
"_type": "employee",
"_id": xxxxxx,
"_version": 1, //文档版本号
"created": true //是否新增
}
③ 获取指定ID的文档
GET itsource/employee/123?pretty
③返回的内容:
{
"_index" : "itsource",
"_type" : "employee",
"_id" : "123",
"_version" : 1,
"found" : true,
"_source" : {
"email": "[email protected]",
"fullName": "倪先华",
...
"joine_date": "2016-06-01"
}
}
返回文档的部分字段:
GET默认返回整个文档,通过GET /itsource/employee/123?_source=fullName,email
只返回文档内容,不要元数据:
GET itsource/employee/123/_source
只检查文档是否存在(查询头信息):
curl -i -X HEAD http://localhost:9200/itsource/employee/123
④ 修改文档
更新整个文档
同PUT {index}/{type}/{id}
在响应中,我们可以看到Elasticsearch把 _version 增加了。
{
...
"_version" : 2,
"created": false
}
created 标识为 false 因为同索引、同类型下已经存在同ID的文档。
在内部,Elasticsearch已经标记旧文档为删除并添加了一个完整的新文档。旧版本文档不会立即消失,但你也不能去访问它。Elasticsearch会在你继续索引更多数据时清理被删除的文档。
局部更新文档
接受一个局部文档参数 doc,它会合并到现有文档中,对象合并在一起,存在的标量字段被覆盖,新字段被添加。
POST itsource/employee/123/_update
{
“doc”:{
"email" : "[email protected]",
"salary": 1000
}
}
email会被更新覆盖,salary会新增。
这个API 似乎 允许你修改文档的局部,但事实上Elasticsearch
遵循与之前所说完全相同的过程,这个过程如下:
- 从旧文档中检索JSON
- 修改它
- 删除旧文档
- 索引新文档
脚本更新文档
也可以通过使用简单的脚本来进行。这个例子使用一个脚本将age加5:
POST itsource/emploee/123/_update
{
"script" : "ctx._source.age += 5"
}
在上面的例子中, ctx._source指向当前被更新的文档。
注意,目前的更新操作只能一次应用在一个文档上。
删除文档
DELETE {index}/{type}/{id}
存在文档的返回:
{
"found" : true,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3
}
不存在的返回:
{
"found" : false,
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 4
}
注意:尽管文档不存在,但_version依旧增加了。这是内部记录的一部分,它确保在多节点间不同操作可以有正确的顺序。
批量操作bulk API
使用单一请求来实现多个文档的create、index、update 或 delete。
Bulk请求体格式:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
每行必须以 “\n” 符号结尾,包括最后一行。这些都是作为每行有效的分离而做的标记。
create当文档不存在时创建之。
index创建新文档或替换已有文档。
update局部更新文档。
delete删除一个文档。
例如:
POST _bulk
{ "delete": { "_index": "itsource", "_type": "employee", "_id": "123" }}
{ "create": { "_index": "itsource", "_type": "blog", "_id": "123" }}
{ "title": "我发布的博客" }
{ "index": { "_index": "itsource", "_type": "blog" }}
{ "title": "我的第二博客" }
注意:delete后不需要请求体,最后一行要有回车
4.3.2.批量获取
mget API参数是一个 docs数组,数组的每个节点定义一个文档的 _index 、 _type 、 _id 元数据。如果你只想检索一个或几个确定的字段,也可以定义一个 _source 参数:
方式1:GET _mget
{
"docs" : [
{
"_index" : "itsource",
"_type" : "blog",
"_id" : 2
},
{
"_index" : "itsource",
"_type" : "employee",
"_id" : 1,
"_source": "email,age"
}
]
}
方式2:同一个索引库的同一个类型下
GET itsource/blog/_mget
{
"ids" : [ "2", "1" ]
}
4.3.3.空搜索
没有指定任何的查询条件,只返回集群索引中的所有文档: GET _search
4.3.4.分页搜索
和SQL使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch接受 from 和 size 参数:
size : 每页条数,默认 10
from : 跳过开始的结果数,默认 0
如果你想每页显示5个结果,页码从1到3,那请求如下:
GET _search?size=5
GET _search?size=5&from=5
GET _search?size=5&from=10
4.3.5.查询字符串搜索
一个搜索可以用纯粹的uri来执行查询。在这种模式下使用搜索,并不是所有的选项都是暴露的。它可以方便快速进行 curl 测试。
查询年龄为25岁的员工
GET itsource/employee/_search?q=age:25
如果q后的参数不指定Fileds则默认查询_all字段(隐含的文档所有字段的连接内容)
类似的查询语法参考lucene,如:
+name:john +tweet:mary
+name:(mary john) +date:>2014-09-10 +(aggregations geo)
age[20 TO 30]
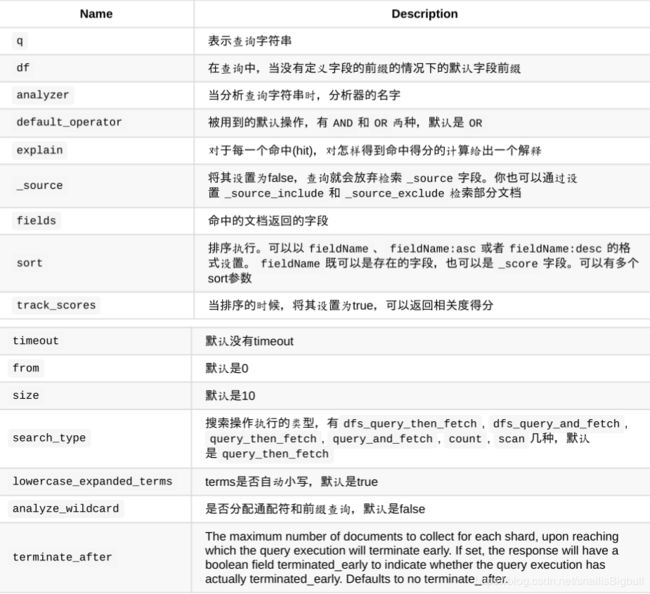
参数
DSL
1 什么是dsl
由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现.
查询字符串模式:GET itsource/employee/_search?q=fullName:倪先华
DSL模式:
GET itsource/employee/_search
{
"query" : {
"match" : {
"fullName" : "倪先华"
}
}
对于简单查询,使用查询字符串比较好,但是对于复杂查询,由于条件多,逻辑嵌套复杂,查询字符串不易组织与表达,且容易出错,因此推荐复杂查询通过DSL使用JSON内容格式的请求体代替。
组成
dsl=dsl查询+dsl过滤
dsl过滤简单理解为就是精确查询,而dsl查询是模糊查询(like).由于查询需要做相关度排序,并且过滤可以缓存.所有过滤的效率高于查询.所以只有必须要用查询的时候才用它(模糊查询),否则都用过滤.
dsl查询
#dsl=dsl查询+dsl过滤
#1 dsl查询-->高级查询+分页+排序+截取字段
GET test/employee/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2,
"_source": ["name","age"]
}
dsl过滤
#dsl过滤
GET test/employee/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 80
}
}
}
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2,
"_source": ["name","age"]
}
DSL过滤语句和DSL查询语句非常相似,但是它们的使用目的却不同:
DSL过滤查询文档的方式更像是对于我的条件“有”或者“没有”,而DSL查询语句则像是“有多像”。
DSL过滤和DSL查询在性能上的区别:
过滤结果可以缓存并应用到后续请求。
查询语句同时匹配文档,计算相关性,所以更耗时,且不缓存。
过滤语句可有效地配合查询语句完成文档过滤。
原则上,使用DSL查询做全文本搜索或其他需要进行相关性评分的场景,其它全用DSL过滤。
#2.0以上的用法
{
"query": {
"bool": { 与(must) 或(should) 非(must not)
"must": [
{"match": {"description": "search" }}
],
"filter": {
"term": {"tags": "lucene"}
}
}
},
"from": 20,
"size": 10,
"_source": ["fullName", "age", "email"],
"sort": [{"join_date": "desc"},{"age": "asc"}]
}
#2.0以前的用法
{
"query": {
"filtered": {
"query": {
"match": {"description": "search" }
},
"filter": {
"term": {"tags": "lucene"}
}
}
}
}
.使用DSL查询与过滤
① 全匹配(match_all)
普通搜索(匹配所有文档):
{
"query" : {
"match_all" : {}
}
}
如果需要使用过滤条件(在所有文档中过滤,红色部分默认可不写):
{
"query" : {
"bool" : {
"must" : [{
"match_all":{}
}],
"filter":{....}
}
}
}
标准查询(match和multi_match)
match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用match查询一个全文本字段,它会在真正查询之前用分析器先分析查询字符:
{
"query": {
"match": {
"fullName": "Steven King"
}
}
}
上面的搜索会对Steven King分词,并找到包含Steven或King的文档,然后给出排序分值。
如果用 match 下指定了一个确切值,在遇到数字,日期,布尔值或者 not_analyzed的字符串时,它将为你搜索你给定的值,如:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}
multi_match 查询允许你做 match查询的基础上同时搜索多个字段:
{
"query":{
"multi_match": {
"query": "Steven King",
"fields": [ "fullName", "title" ]
}
}
}
上面的搜索同时在fullName和title字段中匹配。
提示:match一般只用于全文字段的匹配与查询,一般不用于过滤。
③单词搜索与过滤(Term和Terms)
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"tags": "elasticsearch"
}
}
}
}
}
Terms搜索与过滤
{
"query": {
"terms": {
"tags": ["jvm", "hadoop", "lucene"],
"minimum_match": 2
}
}
}
minimum_match:至少匹配个数,默认为1
④ 组合条件搜索与过滤(Bool)
组合搜索bool可以组合多个查询条件为一个查询对象,查询条件包括must、should和must_not。
例如:查询爱好有美女,同时也有喜欢游戏或运动,且出生于1990-06-30及之后的人。
{
"query": {
"bool": {
"must": [{"term": {"hobby": "美女"}}],
"should": [{"term": {"hobby": "游戏"}},
{"term": {"hobby": "运动"}}
],
"must_not": [
{"range" :{"birth_date":{"lt": "1990-06-30"}}}
],
"filter": [...],
"minimum_should_match": 1
}
}
}
提示: 如果 bool 查询下没有must子句,那至少应该有一个should子句。但是 如果有 must子句,那么没有 should子句也可以进行查询。
⑤ 范围查询与过滤(range)
range过滤允许我们按照指定范围查找一批数据:
{
"query":{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
}
上例中查询年龄大于等于20并且小于30。
gt:> gte:>= lt:< lte:<=
⑥ 存在和缺失过滤器(exists和missing)
{
"query": {
"bool": {
"must": [{
"match_all": {}
}],
"filter": {
"exists": { "field": "gps" }
}
}
}
}
提示:exists和missing只能用于过滤结果。
⑦ 前匹配搜索与过滤(prefix)
和term查询相似,前匹配搜索不是精确匹配,而是类似于SQL中的like ‘key%’
{
"query": {
"prefix": {
"fullName": "倪"
}
}
}
上例即查询姓倪的所有人。
⑧ 通配符搜索(wildcard)
使用*代表0~N个,使用?代表1个。
{
"query": {
"wildcard": {
"fullName": "倪*华"
}
}
}
小结:
DSL查询是ES提供的通用查询方式,这种方式最大的特点是开发语言的无关性,即任意的客户端只要支持HTTP请求,就可以通过JSON格式的查询数据完成复杂的搜索。
查询与过滤在实际的项目开发中是经常遇到的主题。
分词与映射
1.为什么要使用分词与映射
在全文检索理论中,文档的查询是通过关键字查询文档索引来进行匹配,因此将文本拆分为有意义的单词,对于搜索结果的准确性至关重要,因此,在建立索引的过程中和分析搜索语句的过程中都需要对文本串分词。
ES中分词需要对具体字段指定分词器等细节,因此需要在文档的映射中明确指出。
IK分词器
ES默认对英文文本的分词器支持较好,但和lucene一样,如果需要对中文进行全文检索,那么需要使用中文分词器,同lucene一样,在使用中文全文检索前,需要集成IK分词器。
ES的IK分词器插件源码地址:https://github.com/medcl/elasticsearch-analysis-ik
① Maven打包IK插件
② 解压target/releases/elasticsearch-analysis-ik-5.2.2.zip文件
并将其内容放置于ES根目录/plugins/ik
③ 配置插件:
插件配置:plugin-descriptor.properties
④ 分词器(可默认)
词典配置:config/IKAnalyzer.cfg.xml
⑤ 重启ES
⑥ 测试分词器
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
注意:IK分词器有两种类型,分别是ik_smart分词器和ik_max_word分词器。
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
提示:也可以直接使用已集成好各种插件的elasticsearch-rtf-master.zip中文发行版,但ES版本为5.1.1。
文档映射Mapper
ES的文档映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型。
1.ES字段类型
① 基本字段类型
字符串:text(分词),keyword(不分词) StringField(不分词文本),TextFiled(要分词文本)
text默认为全文文本,keyword默认为非全文文本
数字:long,integer,short,double,float
日期:date
逻辑:boolean
② 复杂数据类型
对象类型:object
数组类型:array
地理位置:geo_point,geo_shape
2.默认映射
查看索引类型的映射配置:GET {indexName}/_mapping/{typeName}
ES在没有配置Mapping的情况下新增文档,ES会尝试对字段类型进行猜测,并动态生成字段和类型的映射关系。

3.简单类型映射
字段映射的常用属性配置列表

 ① 针对单个类型的映射配置方式
① 针对单个类型的映射配置方式
POST {indexName}/{typeName}/_mapping
{
"{typeName}": {
"properties": {
"id": {
"type": "long"
},
"content": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
注意:你可以在第一次创建索引的时候指定映射的类型。此外,你也可以晚些时候为新类型添加映射(或者为已有的类型更新映射)。
你可以向已有映射中增加字段,但你不能修改它。如果一个字段在映射中已经存在,这可能意味着那个字段的数据已经被索引。如果你改变了字段映射,那已经被索引的数据将错误并且不能被正确的搜索到。
我们可以更新一个映射来增加一个新字段,但是不能把已有字段的类型那个从 analyzed 改到 not_analyzed。
② 同时对多个类型的映射配置方式(推荐)
PUT {indexName}
{
"mappings": {
"user": {
"properties": {
"id": {
"type": "integer"
},
"info": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer"
}
}
},
"dept": {
"properties": {
"id": {
"type": "integer"
},
....更多字段映射配置
}
}
}
}
4.对象及数组类型映射
① 对象的映射与索引
{
“id” : 1,
“girl” : {
“name” : “王小花”,
“age” : 22
}
}
对应的mapping配置:
{
"properties": {
"id": {"type": "long"},
"girl": {
"properties":{
"name": {"type": "keyword"},
"age": {"type": "integer"}
}
}
}
}
注意:Lucene不理解内置对象,一个lucene文档包含键值对的一个扁平化列表,以便于ES索引内置对象,它把文档转换为类似这样:
{
"id": 1,
"girl.name":"王小花",
"girl.age":26
}
内置字段与名字相关,区分两个字段中相同的名字,可以使用全路径,例如user.girl.name
② 数组与对象数组
注意:数组中元素的类型必须一致。
{
“id” : 1,
“hobby” : [“王小花”,“林志玲”]
}
对应的mapping配置是:
{
"properties": {
"id": {"type": "long"},
"hobby": {"type": "keyword"}
}
}
对象数组的映射
{
"id" : 1,
"girl":[{"name":"林志玲","age":32},{"name":"赵丽颖","age":22}]
}
对应的映射配置为:
"properties": {
"id": {
"type": "long"
},
"girl": {
"properties": {
"age": { "type": "long" },
"name": { "type": "text" }
}
}
}
注意:同内联对象一样,对象数组也会被扁平化索引
{
"user.girl.age": [32, 22],
"user.girl.name": ["林志玲", "赵丽颖"]
}
注意:扁平化后,对象属性的相关性已经丢失,因为每个多值字段只是一个数值集,不是排序的数组。
比如查询:哪个女朋友的年龄是22岁? 这个是无法查询到答案,如果需要保留关系,需要使用嵌套对象nested objects。
5.全局映射
全局映射可以通过动态模板和默认设置两种方式实现。
默认方式:default
索引下所有的类型映射配置会继承_default_的配置,如:
PUT {indexName}
{
"mappings": {
"_default_": {
"_all": {
"enabled": false
}
},
"user": {},
"dept": {
"_all": {
"enabled": true
}
}
}
}
上例中:user和dept都会继承_default_的配置,user类型的文档中将不会合并所有字段到_all,而dept会。
动态模板:dynamic_templates
注意:ES会默认把string类型的字段映射为text类型(默认使用标准分词器)和对应的keyword类型,如:
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
在实际应用场景中,一个对象的属性中,需要全文检索的字段较少,大部分字符串不需要分词,因此,需要利用全局模板覆盖自带的默认模板:
PUT _template/global_template //创建名为global_template的模板
{
"template": "*", //匹配所有索引库
"settings": { "number_of_shards": 1 }, //匹配到的索引库只创建1个主分片
"mappings": {
"_default_": {
"_all": {
"enabled": false //关闭所有类型的_all字段
},
"dynamic_templates": [
{
"string_as_text": {
"match_mapping_type": "string",//匹配类型string
"match": "*_text", //匹配字段名字以_text结尾
"mapping": {
"type": "text",//将类型为string的字段映射为text类型
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",//匹配类型string
"mapping": {
"type": "keyword"//将类型为string的字段映射为keyword类型
}
}
}
]
}
}}
说明:上例中定义了两种动态映射模板string_as_text和string_as_keyword.
在实际的类型字段映射时,会依次匹配:
①字段自定义配置、②全局dynamic_templates[string_as_text、string_as_keyword]、
③索引dynamic_templates[…]、④ES自带的string类型映射,以最先匹配上的为准。
注意:索引库在创建的时候会继承当前最新的dynamic_templates,索引库创建后,修改动态模板,无法应用到已存在的索引库。
映射细节
1)基础类型
直接写
2)对象类型
 3)数组
3)数组
基础类型数组-只需映射里面内容的类型
 对象数组:里面所有对象字段的类型是一样的,映射一个就ok了
对象数组:里面所有对象字段的类型是一样的,映射一个就ok了
 全局映射
全局映射
员工类型的id要改为integer,而且部门类型的也要改为integer,甚至所有的都要改.这时每个都去修改非常麻烦.可以设置全局映射.
1)修改默认
一般用来设置_all不要了
 2)动态模板:dynamic_templates
2)动态模板:dynamic_templates
PUT _template/global_template //创建名为global_template的模板
{
"template": "*", //匹配所有索引库
"settings": { "number_of_shards": 1 }, //匹配到的索引库只创建1个主分片
"mappings": {
"_default_": {
"_all": {
"enabled": false //关闭所有类型的_all字段
},
"dynamic_templates": [
{
"string_as_text": {
"match_mapping_type": "string",//匹配类型string
"match": "*_text", //匹配字段名字以_text结尾
"mapping": {
"type": "text",//将类型为string的字段映射为text类型
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",//匹配类型string
"mapping": {
"type": "keyword"//将类型为string的字段映射为keyword类型
}
}
}
]
}
}}