基础字符串总结
基础字符串总结(字符串处理和进制转换)
前记:
本来三个人的训练赛要两个人打了,这让我和我的队友压力剧增,为了成绩不丢人,我们决定进行一些“改革”,从专题刷起,对算法进行逐步的掌握。这个过程从前几天就开始了,今天想起来,适当的总结一下也是极好的。。。(本专题最难的也只不过用了KMP,算是很基础的专题了)本专题持续更新。
文章目录
- 基础字符串总结(字符串处理和进制转换)
- 【字符串】贝贝的交通指挥系统
- 【字符串】贝贝的车牌问题
- 【字符串】ISBN号码
- 【字符串】贝贝的图形
- 【字符串】手机
- 【字符串】不明飞行物
- 【字符串】贝贝的加密工作
- 【字符串】旋转单词
- 【字符串】单词游戏
- 【字符串】贝贝的保险库密码
- 【字符串】密室寻宝
- 【字符串】贝贝的数学课
- 【字符串】斜二进制数
- 【字符串】茶道
- 【字符串】贝贝与外星人
- 【字符串】保密员
- 【字符串】动物简介
- 【字符串】寻宝之旅
- 【字符串】乒乓球
- 【字符串】编码
- 【字符串】十六进制转换
【字符串】贝贝的交通指挥系统
题目描述 :
贝贝所居住的城市有很多个交通路口,其中有26个交通路口在上下班高峰期总是塞车,严重影响市民的出行。于是交通管理部门研制了一批机器人交通警察,用它们来专门指挥这26个交通路口,但需要一个自动化的指挥系统来指挥机器人的运作。这个任务交给了贝贝,贝贝的设计如下。
分别用大写英文字母A、B、…、Z表示这26个路口,并按如下的规则派出这些机器人到交通路口协助指挥交通:
1.每次派出两名机器人;
2.当两名机器人的名字中存在一个相同的字母时,这两名机器人便到对应的交通路口上指挥交通;有多个字母相同时,两名机器人需要按字母的字典顺序到这些路口上巡逻;
3.当两名机器人的名字中不存在相同的字母时,交警部门的派出指令无效(WuXiao)。
假设这些机器人的名字全由大写字母组成,请你编一个程序,帮贝贝完成这个交通指挥系统。
输入:
第1行输入第一个机器人的名字(长度不超过250);
第2行输入第二个机器人的名字(长度不超过250)。
输出:
1.当不能派出机器人时,在第一行输出“WuXiao”;
2.当两名机器人在路口上指挥交通时,在第一行输出“ZhiHui”,第二行输出路口编号;
3.当两名机器人在路口上巡逻时,在第一行输出“XLuo”,第二行输出巡逻的路口数,第三行输出巡逻线路。
样例输入:
OPEN
CLOSE
样例输出:
XLuo
2
E-O
毫无特色,算是签到吧,全部暴力跑也行。。。我在这里用了一个unique函数进行去重(unique函数用法:a为待处理字符串,aa为其长度,则a=unique(a,a+aa)-a),然后sort排序,一位一位地进行比较,若相等则存起来,并按照题意进行后续处理。
#include 【字符串】贝贝的车牌问题
题目描述:
广州市车管所为每一辆入户的汽车都发放一块车牌,车牌的号码由六个字符组成,如A99452、B88888等,这个字符串从左边数起的第一个字符为大写英文字母,如A、B、C等,表示这辆车是属于广州市区内的汽车还是郊区的汽车,后面的五位由数字组成。假定以字母A、B、C、D、E、F、G、R、S、T开头的表示是市区车牌,而以其他字母开头的表示郊区车牌。
车管所把这个任务交给贝贝。请你帮贝贝找出所给出的车牌中有多少辆是广州郊区的汽车。
输入:
第1行是一个正整数N(1≤N≤105),表示共有N个车牌。接下来的N行,每行是一个车牌号。题目保证给出的车牌不会重复。
输出:
只有1行,即广州郊区车牌的数量。
样例输入:
3
G54672
Q87680
P77771
样例输出:
2
这个真心水,完全的暴力,不会的自行面壁吧。
#include 【字符串】ISBN号码
题目描述:
每一本正式出版的图书都有一个ISBN号码与之对应,ISBN码包括9位数字、1位识别码和3位分隔符,其规定格式如“x-xxx-xxxxx-x”,其中符号“-”就是分隔符(键盘上的减号),最后一位是识别码,例如0-670-82162-4就是一个标准的ISBN码。ISBN码的首位数字表示书籍的出版语言,例如0代表英语;第一个分隔符“-”之后的三位数字代表出版社,例如670代表维京出版社;第二个分隔符后的五位数字代表该书在该出版社的编号;最后一位为识别码。
识别码的计算方法如下:
首位数字乘以1加上次位数字乘以2……以此类推,用所得的结果mod 11,所得的余数即为识别码,如果余数为10,则识别码为大写字母X。例如ISBN号码0-670-82162-4中的识别码4是这样得到的:对067082162这9个数字,从左至右,分别乘以1,2,…,9,再求和,即0×1+6×2+……+2×9=158,然后取158 mod 11的结果4作为识别码。
你的任务是编写程序判断输入的ISBN号码中识别码是否正确,如果正确,则仅输出“Right”;如果错误,则输出你认为是正确的ISBN号码。
输入:
输入只有一行,是一个字符序列,表示一本书的ISBN号码(保证输入符合ISBN号码的格式要求)。
输出:
输出共一行,假如输入的ISBN号码的识别码正确,那么输出“Right”,否则,按照规定的格式,输出正确的ISBN号码(包括分隔符“-”)。
样例输入:
0-670-82162-4
样例输出:
Right
同样的,暴力解法。。。
#include 【字符串】贝贝的图形
题目描述:
贝贝最近玩起了字符游戏,规则是这样的:读入四行字符串,其中的字母都是大写的,乐乐想打印一个柱状图显示每个大写字母的频率。你能帮助他吗?
输入 输入共有4行:每行为一串字符,不超过72个字符。
输出与样例的格式保持严格一致。
样例输入:
THE QUICK BROWN FOX JUMPED OVER THE LAZY DOG.
THIS IS AN EXAMPLE TO TEST FOR YOUR
HISTOGRAM PROGRAM.
HELLO!
样例输出:

相邻字符间有一个空格。
提示1.输出的相邻字符间有一个空格。
2.最后一行的26个大写字母每次必须输出。
3.大写字母A所在的第一列前没有空格。
这个题。。。貌似之前写过了,没啥难点,就是空格,要注意,很容易错。
#include 【字符串】手机
题目描述:
手机的键盘是这样的:
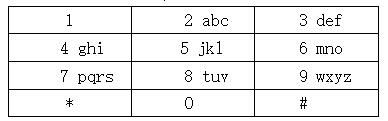
要按出英文字母就必须要按数字键多下。例如要按出x就得按9两下,第一下会出w,而第二下会把w变成x。0键按一下会出一个空格。
你的任务是读取若干句只包含英文小写字母和空格的句子,求出要在手机上打出这个句子至少需要按多少下键盘。
输入:
一行一个句子,只包含英文小写字母和空格,且不超过200个字符。
输出:
一行一个整数,表示按键盘的总次数。
样例输入:
i have a dream
样例输出:
23
水题,不解释。
#include 【字符串】不明飞行物
题目描述:
一颗彗星的后面有一个不明飞行物(UFO),这个UFO经常到地球上来寻找忠实的追随者,把他们带到宇宙中去。但由于舱内空间有限,它们每一趟只能带一组追随者。尽管如此,外星人仍然想出了一个妙法来决定带谁走:以A代表1,B代表2,……Z代表26,USACO即21191315=17955,倘若此组人的组名所代表的数字与彗星的名字所代表的数字分别除以47,余数相同,则彗星名与组名相匹配,UFO带此组人飞向宇宙,余数不同则不匹配,故不带。
写一程序,打印出彗星名与组名是否相匹配,是打印“GO”,否打印“STAY”;同时打印出两者的余数。
输入:
输入包含两行,第一行为慧星名,第二行为组名。每行字符串长度不超过200。
输出:
由屏幕显示是否匹配的信息,下一行显示两者的余数。
样例输入:
COMETHALEBOPP
HEAVENSGATE
样例输出:
GO
r1=r2=17
提示:
样例输入2:
AWFHRIEJLCMBVBHXJUISVSHEIMGVHM
WHUZMXVADDNAPAUQUSOFRPYQZGRHCUMWNO
样例输出2:
STAY
r1=22 r2=32
看到好多人用ASCALL码转换的。。。用-‘A’+1不好嘛。。。
#include 【字符串】贝贝的加密工作
题目描述:
贝贝找了一份为一些文件的某些部分加密的工作,加密的部分是一串小写英文字母,加密的规则是这样的:要是连续出现相同的字母,则把他们替换成这个字母的大写形式,后面紧跟相同字母的个数,并把它之前跟之后的两段字串调换,例如出现bcaaaaaaef,则新字符串变成:efA6bc,然后重新扫描字串,直到没有出现相同小写字母为止。
输入:
原始字符串(长度不大于250)。
输出:
新字符串。
样例输入:
bcaaaaaaef
样例输出:
efA6bc
这个就比较有意思了,本来交了好多发都TEL,结果加了个优化代码,它就过了。。。一脸无奈。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")//没错就是上边这两行,对数据结构有神奇的加速功效
#include 【字符串】旋转单词
题目描述:
今天的英语课,王老师为了复习以前学过的单词,提高学生的学习兴趣,想出了一个主意:
读入M组数据,其中每组数据有一个单词L(单词长度≤36个字符)和一个整数N(1≤N≤36),从该单词最末位开始逐位移到单词的开头,如果还没达到N值,则再从末位开始移动,直到达N值为止,求移N位后的新单词。你能编程帮助贝贝最快完成任务吗?
输入共有2×M+1行,第1行为M,第2行开始为具体数据,每一组数据有2行,第1行字串L,第2行为N。
输出共M行,每行为旋转后的字串。
样例输入:
1
computer
3
样例输出:
tercompu
此题暴力也行,先对长度取余,再从后往前数,存到一个新的string里也行,此处提供暴力解法(我也不知道为啥当初那么喜欢用char型字符串,现在是能用string绝不用char了。。。)
#include【字符串】单词游戏
题目描述:
今天的英语课,王老师为了复习以前学过的单词,提高学生的学习兴趣,想了一个主意:
(1)把全班分为n个小组,每个小组写一个学过的单词(均为小写)和一个整数k;
(2)每个小组根据该单词中每个字母的字典顺序上推或下推k个位置,经过变换后得到一个新单词。推移规则是:如果k为正数则下推,否则上推,当推移超越边界时回到另一端继续推移。例如,单词为at,k=8则新单词为ib,字母t下移到边界z还不够,则再从第一个字母a开始继续推移。
(3)每个小组把得到的新单词和整数k展示到黑板上;
(4)王老师紧接着给出了一个字母,规定哪个小组最快完成以下任务则获胜:统计出该字母在所有小组开始写出的单词中出现的次数。
你能编程帮助贝贝所在的小组获胜吗?
输入:
输入共n+2行:
第1行为王老师给出的一个字母;
第2行为数字n(2≤n≤30),表示全班分为n个小组;
接着是n行,每行为每个小组得到的新单词(2≤单词长度≤14),然后空一个格,后接一个整数k(-1000≤k≤1000)。
输出:
输出只有一个数,为给定字母在所有小组开始写出的单词中出现的次数。
样例输入:
e
2
welcome -2
happy 3
样例输出:
2
输入的是新单词,注意!!!求的是在原单词中出现的次数,就这玩意害我WA了3发,无奈。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")
#include 【字符串】贝贝的保险库密码
题目描述:
某银行的保险库收藏着多件珍贵的物品。为了保证物品的安全,除非有特别的原因,否则银行的保险库要全天24小时开启监控设备进行实时监控:当确实需要临时关闭监控设备时,需要使用为特定操作人员设计的监控密码,这种密码要与操作人员的指纹信息结合,生成一个符合规定的数据,该操作人员才能关闭银行的保险库的监控设备。于是银行的行长就找到了贝贝,请他帮忙设置一个系统判断输入的密码是否正确。密码要求如下:
行长设想的监控密码是一个不超过9位的十进制正整数,且要有如下特征:它的各位数字之和等于该数的12进制表示的各位数字之和,还等于该数的16进制表示的各位数字之和。
例如,2991的各位数字之和为2+9+9+1=21,因为2991=l×1728+8×144+9×12+3,它的12进制表示是189312,各位数字之和也是21。但是2991的16进制表示是BAF16,并且11+10+15=36,所以2991不是合法的监控密码。
又如,2992在全部三种表示法中各位数字之和都是22,所以2992是合法的监控密码。
现在请你帮贝贝的忙,编一个程序判断输入的密码是否可以用作银行保险库的监控密码。
输入:
输入只有一个长度不超过9位的十进制正整数。
输出:
第1行为输入的十进制数所对应的十六进制数各位数字之和,第2行为“Right”(可用作监控密码)或“Wrong”(不可用作监控密码)。
样例输入
2992
样例输出:
22
Right
要转换进制了,由于这是好久之前写的了,当时也比较菜(虽然现在也很菜),就采用了暴力换进制的方法。。。当然后面就改掉这个习惯了,在后面的几题的代码中也有所体现。
#include【字符串】密室寻宝
题目描述:
哈利・波特不经意间进入了一座古墓,古墓入口有一道大门,内部有六个密室,每个密室中藏有一件兵器。已知需要两个密码才能从里面打开密室和大门,取出密室内的兵器后从大门撤出。
两个密码均是不大于63的十进制整数,将其转化为八位二进制数后对应位进行“与”运算(运算的规则是:当两个位均为“1”时,结果为“1”,否则结果为“0”)。将“与”运算的结果从右往左数,当第n位为1时,表示可以打开第n个密室,取出其中的兵器;只有当取到至少两件兵器时,方可打开大门撤出。
现在哈利・波特任意给你两个密码,请你帮他设计一个程序,算算可以从哪些密室取出兵器,并可否从大门撤出。
输入:
第1行输入第一个密码P;
第2行输入第二个密码Q。
输出:
第1行:按从小到大的顺序输出可以打开密室的编号。若没有可以打开的密室,则输出“0”;
第2行:若可打开大门,则输出为“Open”,否则输出“Close”。
样例输入:
2
5
样例输出:
0
Close
emmm,同样是以前的代码(我以前写题咋这么暴力)。
#include【字符串】贝贝的数学课
题目描述:
贝贝很喜欢上数学课,因为他觉得数学课可以带给他很多乐趣。一天,数学老师为了提高学生的学习兴趣,便出了一道有趣的数学题目:
首先,把全班分成k个小组,游戏开始前,老师会把三个数据n,t,m写在黑板上,要求把一个n进制的数t,转换成m进制数。哪个小组最快算出这个m进制数,将会得到奖品,奖品会分发给小组的每个同学。
请你编一个程序,帮助贝贝所在的小组。
输入:
输入数据共有3行,第1行是一个正整数,表示需要转换的数的进制n(2≤n≤16),第2行是一个n进制数,若n>10则用大写字母A~F表示数码10~15,并且该n进制数对应的十进制数的值不超过2000000000,第3行也是一个正整数,表示转换之后的数的进制m(2≤m≤16)。
输出:
1行,包含一个正整数,表示转换之后的m进制数。
样例输入:
16
FF
2
样例输出:
11111111
m进制,估计就是这玩意让我不用暴力的,这个要是枚举的话能累死。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")
#include 【字符串】斜二进制数
题目描述:
当一个数是十进制数,每项的基数表现为10的k次方(数字是有限的,从左边到右边,最末的数字是10的0次方)。举例来说:
81307(10)=8×104+1×103+3×102+0×101+7×100
= 80000+1000+300+0+7
= 81307
当一个数是二进制数,每项的基数表现为2的k次方。举例来说:
10011(2)= 1×24+0×23+0×22+1×21+1×20
= 16+0+0+2+1.
= 19
在斜二进制中,我们定义shu为斜二进制数,每项的基数表现2的(k+1)次方减1。举例来说:
10120(shu)=1×(32-1)+0×(16-1)+1×(8-1)+2×(4-1)+0×(2-1)
= 31+0+7+6+0
= 44
例如:最初10个数字在斜二进制中是0,1,2,10,11,12,20,100,101,102。
输入输入包括1行数据,一个斜二进制整数。
输出输出斜二进制数字的十进制值,要是超过2147483647,则输出"too long!"。
样例输入:
11
样例输出:
4
记得用长整型long long,要不然会爆数据。我的做法是先将给的数字变成字符串,然后翻转过来进行处理,这里要介绍一个函数:reverse函数(若有字符串str,要将其反转过来,则reverse(str.begin(),str.end()),该函数只适用于string型字符串)。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")
#include 【字符串】茶道
题目描述:
茶道者,烹茶饮茶之艺术也。佳茗还须好法沏,水温茶量待斟酌。水温、茶量为茶质感之限。现有两个数值,数值一为水温,范围是0~100,用二进制表示;数值二是茶量(十进制),不大于4800000。请输出水温与茶量之积(十进制)。
输入:
第1行数值为水温,范围是0~100,用二进制表示;
第2行数值为茶量(十进制),不大于4800000。
输出:
输出水温与茶量之积(十进制)。
原本以为是个王者,结果就是个青铜(之前咋交都是WA,结果是数据有问题,重判以后全对了)。
#include【字符串】贝贝与外星人
题目描述:
贝贝想方设法地要和外星人取得联系,他将许多关于地球上的信息换成数字信号向外太空发射。在转换信息的过程中,贝贝遇到了一个难题:他需要将许多包含小数的数据转换成数字信号(也就是二进制数)。可是贝贝实在太忙了,没时间去完成这项工作。
现在,贝贝想请你帮一个忙,编写一个十进制小数转换成二进制小数的程序。
要求:输入一个十进制小数,输出其对应的二进制小数的前三位。
输入:
只有一个十进制小数x(0
输出一个对应的二进制小数。
样例输入:
0.625
样例输出:
0.101
这就没意思了。
#include【字符串】保密员
题目描述:
在一次考试中,贝贝被派去做考场的监控保密工作,考场中每个试室都装了一个视频监控,出于安全考虑,系统为每个考室设置了一个监控密码,为了密码的安全,考试中心分发给每个试室的密码是一个x(x≤16)进制的小数,如果贝贝要打开试室的监控视频,必须把这个x进制小数转换成十进制小数,然后取小数点的后四位,即为打开监控视频的密码。输入的数据中,分别用大写字母A-F表示数字10~15。
由于试室比较多,贝贝在短时间内很难准确计算出密码,为了不影响考试工作,请你帮贝贝编写一个程序,准确计算出每个试室监控密码。
输入:
输入第1行是整数x,第2行是需要转换的小数。
输出:
输出为一个十进制小数,计算结果四舍五入,保留小数点后4位有效数字。此题最大的坑在于系统函数pow(pow函数用法,若使c为a的b次方,则c=pow(a,b)),这个函数有误差,建议自己定义一个函数。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")
#include 【字符串】动物简介
题目描述:
到了动物园,琦琦开心得跳起来。哗,这里好多动物呀,有老虎,有狮子……,在开心之余,琦琦也不忘妈妈的教导:观察动物时要认真仔细,还要看动物园附上的动物简介呀。
动物的简介原来还有英文版的呢!为了卖弄自己的英文水平,琦琦就告诉妈妈每张动物简介里出现了多少次该动物的名称。注意:琦琦只认识小写字母,而且她只认得动物的单词,因此她认为monkeys或者smonkey或者smonkeys都是出现了monkey这个词。
你能编程完成琦琦的任务吗?
输入:
输入共n+2行:
第1行为数字n(n<=3000),表示该动物的简介共有n行。
第2行为一个单词,表示琦琦认识的动物名称。
接着是n行,每行为一个长度小于250个字符的字符串,表示动物的简介。
输出:
输出共1行,为简介里出现了多少次琦琦能识别出的动物的单词。
看着很简单吧,嘿嘿,别急,这个题暴力是肯定过不了的,这里介绍一种基础的字符串算法——KMP算法。
其原理是找出要匹配字符串数组的前缀数组,从而跳过一些无用的判断,将时间复杂度降为O(n)。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")
#include 【字符串】寻宝之旅
题目描述:
贝贝是海洋探险机构中的一员,现有一个任务:
某个海岛上埋藏着多件宝物,每件宝物都有一个确切的位置,宝物的位置用一对数(x,y)来表示。其中X表示该宝物离海洋中某个指定地点的水平距离,y表示该宝物离海洋中某个指定地点的垂直距离。
已知宝物离海洋中某个指定地点的直线距离L可以由如下公式计算:L=sqrt (x2+y2)(提示:PASCAL对应的开方函数是SQRT)。
海洋探险队的任务是:找出名称包含某种特征字符串的所有宝物,并按直线距离由近到远的顺序把它们的位置记录下来,以方便将来取出宝物。看谁能最快完成任务。你能编程序帮贝贝完成这一工作吗?
输入 输入共有n+2行:第1行为要寻找的宝物的特征字符串,第2行为岛上的宝物数,第3行至第n+2行为每件宝物的位置数据和宝物名称(0
样例输入:
er
3
5 2.4 liner
2.5 8.3 suerp
1.5 2 winervis
样例输出:
1.5 2.0
5.0 2.4
2.5 8.3
同样的KMP算法,跟上题一个原理。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")
#include 【字符串】乒乓球
题目描述:
国际乒联现在主席沙拉拉自从上任以来就立志于推行一系列改革,以推动乒乓球运动在全球的普及。其中11分制改革引起了很大的争议,有一部分球员因为无法适应新规则只能选择退役。华华就是其中一位,他退役之后走上了乒乓球研究工作,意图弄明白11分制和21分制对选手的不同影响。在开展他的研究之前,他首先需要对他多年比赛的统计数据进行一些分析,所以需要你的帮忙。
华华通过以下方式进行分析,首先将比赛每个球的胜负列成一张表,然后分别计算在11分制和21分制下,双方的比赛结果(截至记录末尾)。
比如现在有这么一份记录,(其中W表示华华获得一分,L表示华华对手获得一分):
WWWWWWWWWWWWWWWWWWWWWWLW
在11分制下,此时比赛的结果是华华第一局11比0获胜,第二局11比0获胜,正在进行第三局,当前比分1比1。而在21分制下,此时比赛结果是华华第一局21比0获胜,正在进行第二局,比分2比1。如果一局比赛刚开始,则此时比分为0比0。
你的程序就是要对于一系列比赛信息的输入(WL形式),输出正确的结果。
输入:
输入包含若干行字符串(每行至多20个字母),字符串有大写的W、L和E组成。其中E表示比赛信息结束,程序应该忽略E之后的所有内容。
输出:
输出由两部分组成,每部分有若干行,每一行对应一局比赛的比分(按比赛信息输入顺序)。其中第一部分是11分制下的结果,第二部分是21分制下的结果,两部分之间由一个空行分隔。
样例输入:
WWWWWWWWWWWWWWWWWWWW
WWLWE
样例输出:
11:0
11:0
1:1
21:0
2:1
就是个计数,计数时用abs函数带上绝对值便可(abs函数用法:求a的绝对值,则a=abs(a))
#include【字符串】编码
题目描述:
文本可以用字母替换的方式编号。下面是一种替换表格的产生规则:
关键字:由不同的英文字母组成。关键数:不超过26的正整数。首先选择一个关键字(key word)和一个关键数K (key number),产生一个2行26列的表格,上一行是排列好的26个英文字母,将关键字从第K列开始填入表格第二行,然后按字母次序把没有填写的字母接在后面依次填入,当超过表格尾部时,环绕从第一列开始填。
例如:关键字是DUBROVNIK,关键数是10,替换表如下:

原文本的每个能在第一行找到的字母,被第二行相应字母替换,称为编码。
请编程,根据给定的关键字和关键数,把一段被编码的文本解码,输出原来的文本。
输入:
第1行是由大写英文字母(A~Z)组成的关键字,关键字长度不大于26;
第2行是关键数K,1≤K≤26;
第3行是由大写英文字母(A~Z)组成的被编码的文本,长度不超过100。
输出:
1行,被解码的原文。
样例输入
NOVI
15
DTZNMNXAWT
样例输出:
VINODOLSKI
新建一个数组储存对应关系,然后暴力跑。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")
#include 【字符串】十六进制转换
题目描述:
输入一个不超过100000位的十六进制数,请转换成八进制数。
注:十六进制数中,字母0~9还对应表示数字0~9,字母“A”(大写)表示10,“B”表示11,…,“F”表示15。比如:十六进制数A1OB表示的10进制数是:10×163+ 1×162+ 0×161+ 11×160= 41227。 转换成的八进制数是:120413,因为1×85+ 2×84+ 0×83+ 4×82+ 1×81+ 3×80= 41227。
提示:考虑它们与二进制表示的关系。
输入:
一个十六进制数,没有前导0(除非是数字0)。
输出:
一个八进制数,没有前导0(除非是数字0)。
样例输入:
123ABC
样例输出:
4435274
听说标称是要转换为2进制的,其实也不用,考虑到8的4次方==16的3次方,将原串拆开(3位1组),分别重组再拼接起来就行。
#pragma GCC optimize("Ofast","inline","-ffast-math")
#pragma GCC target("avx,sse2,sse3,sse4,mmx")
#include