分布式查询工具-Apache Drill
1.概述.
2.特点.
3.原理.
4.架构.
5.Drill安装.
6.集群安装.
7.连接数据源
8.应用
9.性能调优
1)查询计划选项的修改
2)Modify broadcast join options
3)Switch between 1 or 2 phase aggregation
3)Enable/disable hash-based memory-constrained operators
4)Enable query queuing
5)Control parallelization
6)Partition Pruning:分区拆剪
7)Change storage formats
8)Disable Logging (See Logging and Debugging)
10.自定义函数
1.概述
Apache Drill是一个低延迟的分布式海量数据(涵盖结构化、半结构化以及嵌套数据)交互式查询引擎,使用ANSI SQL兼容语法,支持本地文件、HDFS、Hive、HBase、MongoDB等后端存储,支持Parquet、JSON、CSV、TSV、PSV等数据格式。受Google的Dremel启发,Drill满足上千节点的PB级别数据的交互式商业智能分析场景。
本质上,Apache Drill是Google Dremel的开源实现,本质是一个分布式的mpp查询层,支持SQL及一些用于NoSQL和Hadoop数据存储系统上的语言,将有助于Hadoop用户实现更快查询海量数据集的目的。
Drill的目的在于支持更广泛的数据源、数据格式及查询语言,可以通过对PB字节数据的快速扫描(大约几秒内)完成相关分析,将是一个专为互动分析大型数据集的分布式系统。
2.特点
能快速上手
低延迟的SQL查询
灵活的数据模型
没有集中的元数据
自描述文件数据的动态查询(如JSON,Parquet,text),MAPR-DB / HBase表,不需要元数据定义的Hive元数据。
ANSI SQL
嵌套的数据支持
与Apache Hive一体化(Hive表和视图的查询,支持所有Hive文件格式和HiveUDFs)
BI/ SQL工具集成使用标准的JDBC驱动程序
3.原理
当提交一个Drill查询时,客户端或应用程序以SQL语句的方式发送查询给Drill集群中的DrillBit。DrillBit是处理运行在每个活动节点上的坐标、查询计划和执行查询,以及跨集群分发查询任务以实现数据本地性的最大化。
下图表示客户端、应用程序和DrillBit之间的通信:

DrillBit接收来自客户端和应用程序的查询的Drill变成查询和驱动整个查询的Foreman。Foreman解析器解析SQL,将自定义规则应用到特定的SQL操作符转换成特定的Drill理解的逻辑操作语法。集合的逻辑运算符形成逻辑的计划。逻辑计划描述了作业所需要生成的查询结果和定义了数据源和应用操作。
Foreman发送逻辑计划到一个基于优化在一个语句和逻辑读计划的SQL操作的顺序的优化器。优化器使用与各种类型规则的重新整理以及函数的最优化方案。优化器将逻辑计划转换成一个描述如何执行查询的物理计划。

Foreman的并行化转换的物理计划分为多个阶段,包括主要(Major)和次要(Minor)的Fragment。这些Fragment创建并且执行多层次执行重写查询树根据配置的数据源,将结果返回给客户端和应用程序。
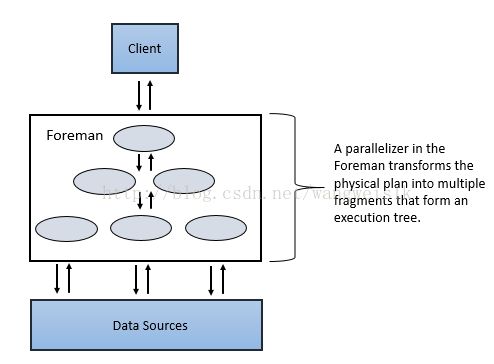

Major Fragment:
Major Fragment是抽象的概念,代表查询执行的一个阶段。一个阶段由一个或多个操作组成。Drill为每个Major Fragment分配一个MajorFragmentID。
例如,执行两个文件的哈希聚合,Drill为这个计划创建两个Major Fragment,第一个Fragment用于扫描两个文件,第二个Fragment用于数据的聚合。


Drill通过一个交换操作符分离两个Fragment。交换的改变发生在数据所在位置或者物理计划的并行化中。交换是由发送器和接收器组成,允许数据在节点之间移动。
Major Fragment不执行任何的查询任务。每个Major Fragment被划分成一个或多个Minor Fragment,执行实际所需完成的查询操作并返回结果给客户端。
Minor Fragments:
每个Major Fragment是由多个minor Fragment并行构成的。一个Minor Fragment是内部运行线程的逻辑作业单元。在Drill中,一个逻辑作业单元也被称为碎片(slice)。Drill产生的执行计划由Minor Fragment组成。Drill为每个Minor Fragment分配一个Minor FragmentID.


Foreman的并行器在执行期间从Major Fragment创建一个或多个Minor Fragment,分解的Major Fragment与多个Minor Fragment一样能同时运行在集群上。
Drill能够尽快的根据上游的数据需求来执行每个Minor Fragment。Drill使用节点的本地化调度Minor Fragment,然后Drill采用轮训的方式调度存在的,可用的DrillBit。
Minor Fragment包含一个或多个关系运算符,一种运算符执行一个关系运算,例如,scan、filter、join、group等。每种运算符都有特定的运算符类型和一个运算符ID。每个运算符ID定义了它所在的Minor Fragment的关系。
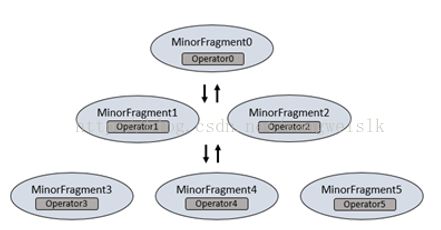

例如,当执行两个文件的散列聚集时,Drill分解的第一阶段用于扫描两个Minor Fragment。每个Minor Fragment 包含扫描文件的扫描操作符。Drill分解第二阶段为了聚集四个Minor Fragment。四个Minor Fragment都包括散列聚集操作符。
Execution of Minor Fragments:
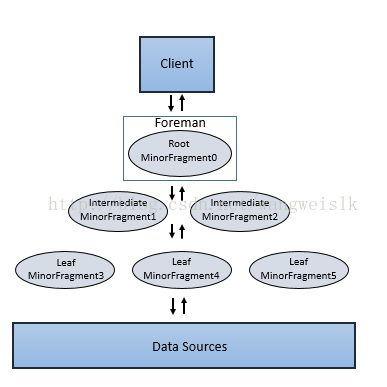

Minor Fragment可以作为root、intermediate、leaf Fragment三种类型运行。一个执行树只包括一个root Fragment。执行树的坐标编号是从root开始的,root是0。数据流是从下游的leaf Fragment到root Fragment。
运行在Foreman的root Fragment接收传入的查询、从表读元数据,重新查询并且路由到下一层级服务树。下一级的Fragment包括Intermediate 和leaf Fragment。
当数据可用或者能从其他的Fragment提供时,Intermediate Fragment启动作业。他们执行执行数据操作并且发送数据到下游处理。通过聚合Root Fragment的结果数据,进行进一步聚合并提供查询结果给客户端或应用程序。
Leaf Fragment并行扫描表并且与存储层数据通信或者访问本地磁盘数据。Leaf Fragment的部分结果传递给Intermediate Fragment,然后对Intermediate结果执行合并操作。
4.架构
Apache Drill的核心是DrillBit服务,主要负责接收客户端请求,处理查询,并将结果返回给客户端。
DrillBit能够被安装和运行在hadoop集群中所需要的节点上形成一个分布式环境。当DrillBit运行在集群的每个节点上时,能够最大限度的实现数据的本地化执行,不要进行网络和节点间的数据移动。Drill使用Zookeeper来维护和管理集群节点和节点的健康状况。
尽管Drill运行在hadoop集群中,但是它不依赖hadoop集群,可以运行在任何的分布式集群中。
Core Module:
The following image represents components within each Drillbit:


下面的列表描述了DrillBit的关键部件:
RPC end point:Drill 是一个低开销的基于protobuf的RPC通信协议。此外,C++和JavaAPI层也用于客户端应用程序与Drill进行交互。在提交查询之前,客户端可以直接和特定的DrillBit通信或者通过Zookeeper来发现可用的DrillBit。推荐做法是客户端通过Zookeeper来维护客户端从集群管理的复杂性,如添加和删除节点。
SQL parser:Drill使用Optiq开源框架来解析传入的查询。该解析器的组件输出是语言无关的。
Storage plugin interfaces:Drill服务作为多个数据源之上的查询层,Drill的存储插件表示的是与数据源交互的抽象。存储插件为Drill提供了下面信息:
元数据来源的可用
Drill读取接口和写入数据源
数据的位置和一组优化规则有助于Drill查询效率和更快的执行在一个特定的数据源。
架构设计方面的性能考虑:
Dynamic schema discovery:动态模式探索
Drill在数据启动查询处理过程中不需模式和类型说明,Drill在执行批处理数据的过程中动态探索模式。在Drill利用动态查询时,自描述数据格式如Parquet,JSON,avro,nosql数据库为他们部分数据指定了模式说明。因为在Drill的查询过程中模式是可以改变的,当模式改变的时候,Drill的所有操作被重新配置他们的模式。
Flexible data model:灵活的数据模型
Drill允许访问嵌套数据属性,就像SQL列,并提供直观的容易扩展的操作。从架构的角度来看,Drill提供了一个灵活的分层柱状数据模型,可以表示复杂,高度动态和发展的数据模型。在设计和执行阶段,Drill允许高效的处理这些模型而不需要flatten或materialize他们。Drill的关系数据是当被作一个特殊的或简化复杂/ 多结构数据。
De-centralized metadata:分散型元数据
Drill没有集中的元数据的需求。我们不需要在一个元数据库中创建和管理表和视图,或依赖于一个数据库管理员group这样的一个函数。Drill数据来源于存储插件对应的数据源。存储插件提供的元数据从完整的元数据(Hive),部分元数据(HBase),或没有集中的元数据(文件)。分散型元数据意味着Drill不是绑定到一个单一的Hive库中。我们能够一次查询多个Hive库,然后从HBase表或一个分布式系统中的文件合并数据。还可以使用SQL DDL的Drill语法来创建元数据,该操作就像一个传统的数据库。Drill是通过ANSI标准INFORMATION_SCHEMA数据库元数据。
Extensibility可扩展
Drill在所有层面都提供了可扩展的架构,包括:存储插件、查询器、查询优化器、查询执行器和客户端API。用户可以自定义任何层来进行扩展。
5.Drill安装
Windows安装,直接解压tar.gz安装包,启动bin下的sqline.bat
命令行:sqlline.bat -u "jdbc:drill:zk=local"
![]()
使用自带的文件系统查询:
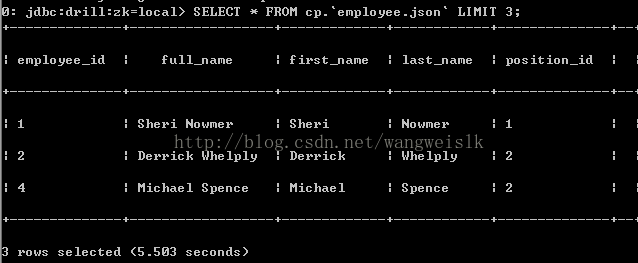
查询一个json文件:
SELECT * FROM cp.`employee.json` LIMIT 3;

Querying a Parquet File :
SELECT * FROM dfs.`F:/Hadoop/drill/apache-drill-1.0.0/apache-drill-1.0.0/sample-data/region.parquet`;
6.集群安装
条件:
JDK7
Zookeeper集群
Hadoop集群
DNS
步骤:
- 安装Drill
- 配置Drill和Zookeeper
编辑drill-override.conf位于/conf目录
提供了一个独特的集群ID和Zookeeper的主机名和端口号zk.connect。如果在多个节点上安装Drill,分配相同的集群ID如果每个节点都安装了Drill节点共享相同的ID,Zookeeper默认端口是2181。

配置后即可使用Drill:
bin/drillbit.sh restart
bin/drill-localhost
bin/drill-conf
jdbc:drill:zk=
sqlline –u jdbc:drill:[schema=
bin/sqlline –u jdbc:drill:schema=dfs;zk=centos26
bin/sqlline –u jdbc:drill:zk=cento23,zk=centos24,zk=centos26:5181
- 连接数据源
8047
注意:在对Drill进行安装时一定要保证drill-env.sh文件中对内存的配置一定要小于或等于可用内存,否则启动不会成功。
7.连接数据源

1)存储插件的注册
Web UI: http://
2) 存储插件配置
3) FS 存储插件
{
"type" : "file",
"enabled" : true,
"connection" : "hdfs://10.10.30.156:8020/",
"workspaces" : {
"root" : {
"location" : "/user/root/drill",
"writable" : true,
"defaultinputformat" : null
}
},
"formats" : {
"json" : {
"type" : "json"
}
}
}
- 工作空间
- Hbase存储插件
{
"type": "hbase",
"config": {
"hbase.zookeeper.quorum":"10.10.100.62,10.10.10.52,10.10.10.53",
"hbase.zookeeper.property.clientPort": "2181"
},
"size.calculator.enabled": false,
"enabled": true
}
- Hive存储插件,以下是对Drill与Hive集成的使用:
Web UI 默认:http://localhost:8047
内嵌方式(未测试):
{
"type":"hive",
"enabled":true,
"configProps":{
"hive.metastore.uris":"",
"javax.jdo.option.ConnectionURL":"jdbc:mysql://localhost:3306/hive;create=true",
"hive.metastore.warehouse.dir":"/user/hive/warehouse",
"fs.default.name":"hdfs://weiw:9000",
"hive.metastore.sasl.enabled":"false"
}
}
远程方式(测试通过):
Drill Web UI 配置
{
"type": "hive",
"enabled": true,
"configProps": {
"hive.metastore.uris": "thrift://weiw:9083",
"hive.metastore.sasl.enabled": "false"
}
}
Hive中hive-site.xml配置:
启动metastore 服务:hive –service metastore
测试创建hive表:
create table tt(id string,name string)row format delimited fields terminated by '\t' stored as textfile;
load data local inpath '/usr/local/hadoop/data/id' overwrite into table tt;
JDBC客户端执行SQL:

命令行客户端执行SQL查询:
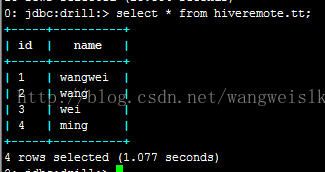
WEB UI执行SQL查询:


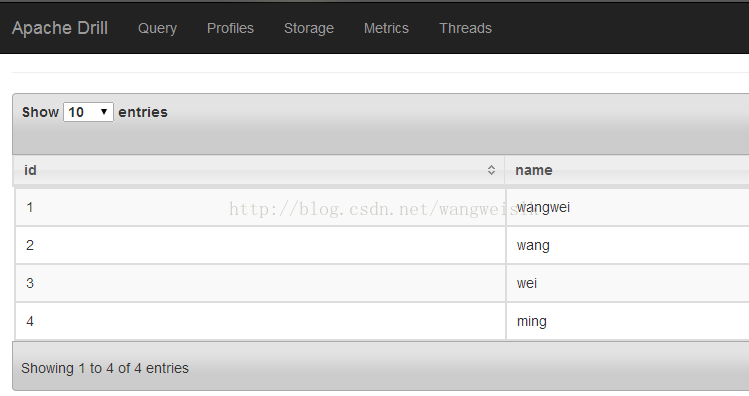



8.应用
查询测试:
查询JSON:SELECT * FROM cp.`employee.json` LIMIT 5;
查询Paquet: SELECT * FROM dfs.`/usr/local/hadoop/drill/sample-data/region.parquet`;
查询普通文件:
select * from dfs.` /usr/local/hadoop/data/plays.csv`;
select columns[0],columns[1] from dfs.` /usr/local/hadoop/data/plays.csv`;
use dfs;
SELECT COLUMNS[0] AS Ngram,
COLUMNS[1] AS Publication_Date,
COLUMNS[2] AS Frequency
FROM `/data1/bbdhadoop/wangwei/drill/googlebooks-eng-all-5gram-20120701-zo.tsv`
WHERE ((columns[0] = 'Zoological Journal of the Linnean')
AND (columns[2] > 250)) LIMIT 10;
查询目录:
select columns[0],columns[1] from dfs.`/data1/bbdhadoop/wangwei/drill/testdata` order by 1;
查询hbase:
SELECT * FROM students;
SELECT CONVERT_FROM(row_key, 'UTF8') AS studentid,
CONVERT_FROM(students.account.name, 'UTF8') AS name,
CONVERT_FROM(students.address.state, 'UTF8') AS state,
CONVERT_FROM(students.address.street, 'UTF8') AS street,
CONVERT_FROM(students.address.zipcode, 'UTF8') AS zipcode
FROM students;
查询Hive:
SELECT firstname,lastname FROM hiveremote.`customers` limit 10;`
复杂数据:
select id, type, name, ppu from dfs.`/usr/local/Hadoop/data/donuts.json`;
select id, type from dfs.` /usr/local/Hadoop/data/donuts.json` where id>0 order by id limit 1;
select tbl1.id, tbl1.type from dfs.` /usr/local/Hadoop/data/donuts.json` as tbl1 join dfs.` /usr/local/Hadoop/data/moredonuts.json` as tbl2 on tbl1.id=tbl2.id;
select type, avg(ppu) as ppu_sum from dfs.` /usr/local/Hadoop/data/donuts.json` group by type;
select tbl.topping[3].id as record, tbl.topping[3].type as first_toppingfrom dfs.` /usr/local/Hadoop/data/donuts.json ` as tbl;
查询schema info:
SCHEMATA:
SELECT CATALOG_NAME, SCHEMA_NAME as all_my_data_sources FROM INFORMATION_SCHEMA.SCHEMATA ORDER BY SCHEMA_NAME;
CATALOGS
TABLES
COLUMNS
VIEWS
查询系统表:
Query the drillbits, version, options, boot, threads, and memory tables in the sys database.

9.性能调优
Drill 是为大型数据集的高效分析而设计的,下面几点保证了Drill的性能:
Distributed engine:
Drill提供了一个强大的分布式执行引擎来处理查询。用户可以提交请求到集群中的任何节点。可以简单地将新节点添加到集群以支持规模更大的数据,支持多用户。
Columnar execution:
Drill通过使用内存数据模型的列式存储和执行优化是层次化和列式。当处理存储在列式格式中的数据时,Drill避免磁盘访问的列不参与分析查询。
Vectorization:矢量化
宁愿操作单个值也不操作单条表记录,同时,Drill的矢量化允许CPU矢量运行,被称为批处理。记录批次分别来自许多不同的记录值的数组。矢量处理技术的效率是基于现代deep-pipelined CPU芯片技术设计的。
Runtime compilation:
运行时编译比解释执行更快。Drill为每一个单次操作产生高效的单次查询代码。
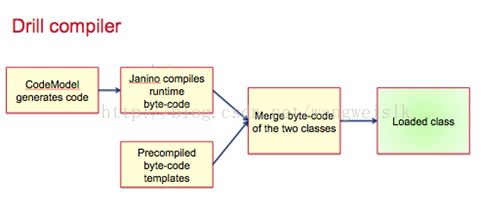
1)查询计划选项的修改:
planner.width.max_per_node
配置这个选项来实现细粒度,绝对的并行化控制。
在这种环境下,宽度是指扇出和潜在分布:能够并行运行一个在核心节点或集群节点上的查询能力。
每个节点的最大宽度定义了最大程度的并行查询的任何片段,但这个设置适用于水平集群中的一个节点。默认最大程度的并行计算每个节点如下,与理论最大自动缩减(四舍五入),因此只有70%的实际可用容量考虑:活跃drillbits(通常每个节点一个)数量*每个节点的核数* 0.7
planner.width_max_per_query
并行运行跨越所有节点查询的线程数的最大值。当Drill在非常大的集群上并行运行时,修改这个选项。默认1000
planner.slice_target
预估记录处理Major Fragment数量的最小值,在申请额外的并行化之前,默认100000
planner.broadcast_threshold
允许广播连接局部记录数量的最大值。默认值10000000。
2)Modify broadcast join options:
在一个广播连接中,所有被选中的文件记录在连接执行之前被广播到其他所有节点。当外部保持原样没有任何重新分发时,连接内部被广播。
当广播连接用一个大的事实表连接一个相对较小的维度表时是很有用的。如果事实表被存储在分布式系统的多个文件中,取代了通过网络重新分发事实表,它能充分降低广播的内部成本。然后,广播相同数据到集群的所有节点上,根据集群的大小和数据量的大小,在某种情况下它可能不是最有效的方式。
planner.broadcast_factor:广播因子
在执行连接时控制广播成本。设置的越低,它执行一个广播连接相比其他类型的分布成本更低,如哈希分布。默认1
planner.enable_broadcast_join:启用广播连接
改变聚合和连接操作符的状态。广播连接可用于哈希连接(hash join),合并连接(merge join),嵌套循环连接(nest loop join)。用于连接大的事实表和相对较小的维度表。默认true
planner.broadcast_threshold广播阀值
根据行数,确定阀值是否选择一个查询加入广播连接。不管broadcast_join 选项是否启用,广播连接不会被选择,除非连接的右侧估计的行数比这个阀值更少。这个选项的目的是避免广播连接太多的行。广播涉及到跨节点发送数据,并且是一个网络密集型操作。默认值:10000000
3)Switch between 1 or 2 phase aggregation:
planner.enable_multiphase_agg:默认true
对于包含Group by的查询,Drill执行1或2两个聚合阶段。在这两个阶段中,Drill可以使用哈希聚合和流聚合物理操作符。Drill默认的执行行为是第2阶段的聚合。
在第2聚合阶段,每个Minor Fragment在第1个阶段执行本地聚合。然后,采用基于哈希分布操作符,发送部分聚合结果到其他Fragment。哈希分布通过keys到Group BY中。这第2阶段,所有的Fragment执行一个总体聚合来接收第1阶段的数据。
第2阶段聚集的方法是非常有效的在数据分组密钥包含一个合理的重复值的数量,这样做将减少发送到下游操作符的行数。然而,如果减少不多的化,最好使用第1阶段聚合。
3)Enable/disable hash-based memory-constrained operators:
Drill根据查询特征使用基于 哈希和排序的操作符。哈希聚集和哈希连接是基于哈希操作符的。流聚合和合并连接是基于排序操作的。他们都会消耗内存,然后哈希聚合和哈希连接操作时最快和内存明感操作。
目前,基于哈希的操作不会泄露所需的磁盘,但是基于排序的操作会泄露。基于排序的Drill查询计划,通过评估可用内存大小乘以配置的可变常量,然后限制基于排序操作的内存量的最大值。
如果基于哈希的操作在执行期间消耗完内存,查询失败。如果大量哈希操作不适合在内存中执行,则可以禁用这个操作。当被禁用时,Drill就会创建允许泄露到磁盘的替代计划。
还可以修改最小哈希表大小,当大量内存被使用时,可以增加规模非常大的聚合和连接的内存量。如果存在大型数据集,可以增加哈希表大小来提升性能。
下面选项控制基于哈希操作:
planner.enable_hashagg:
启动哈希聚合,Drill就不会使用基于排序聚合,就不会持久化到磁盘上。默认true
planner.enable_hashjoin:
启动哈希连接,Drill假设一次查询有足够的内存来完成查询操作并尝试使用最快的操作来完成用哈希表进行的inner、left、right、full连接计划,不会持久化到磁盘。禁用哈希连接的话,允许Drill在小内存占用下管理任意大的数据。默认true
exec.min_hash_table_size:
哈希表大小的最小值。根据可用内存来增加大小可提升性能。Default: 65536 Range: 0 - 1073741824
exec.max_hash_table_size:
Default: 1073741824 Range: 0 - 1073741824
planner.memory.enable_memory_estimation
切换内存状态评估和再计划查询。启动时,Drill会保守估计内存需求,通常不包括内存受限操作和对性能造成的负面影响。默认是false
planner.memory.max_query_memory_per_node:
一次查询每个节点最大内存大小。如果太低,Drill就会重新计划查询计划,没有内存受限操作。Default: 2147483648
4)Enable query queuing:
默认情况下,Drill并发运行所有查询。然后,当增加一小部分并发查询时就会增加性能。可以启动查询队列来限制并发查询的最大量。切分大查询为多个小查询并且启动的那个查询队列。
当启动查询队列时,需要配置大小队列。Drill在运行时通过路由队列来确定基于查询的大小。Drill能快速完成查询然后继续下一个查询。
exec.queue.enable:
查询队列的状态变化来控制同时运行的查询数,禁用时,并发查询量没有限制。默认false
exec.queue.large:
能同时运行在集群上的大规模查询量。范围:0 - 1000。默认值:10
exec.queue.small:
ange: 0 - 1073741824 Default: 100
exec.queue.threshold:
这取决于查询的复杂性在队列,用于确定一个查询是否大或小。复杂的查询有更高的阈值。范围:0 - 9223372036854775807默认:9223372036854775807
exec.queue.timeout_millis:
显示查询可以在队列中等待多久才能查询失败。
范围:0 - 9223372036854775807默认:300000
5)Control parallelization:
planner.width.max.per.node
planner.width.max.per.query
6)Partition Pruning:分区拆剪
分区拆剪是一种性能优化方案,当Drill读取查询文件系统和Hive表时,限制文件和分区的数量。当对数据进行分区时,Drill只读取驻留在文件系统或Hive表的部分分区的一个文件子集在一个查询匹配特定的过滤标准。
Drill的查询计划评估过滤器过滤操作符的一部分。如果没有过滤分区存在,底层扫描操作符读取所有目录并且发送数据给下游的操作符。如果过滤分区存在,查询计划确定,如果它能够增加过滤器到扫描器以至于扫描器只能读取匹配分区过滤器目录,从而减少磁盘I/O.
7)Change storage formats:
Drill支持的文件格式 CSV, TSV, PSV, JSON, and Parquet.修改默认的格式是一种优化性能的典型的功能性改变。Drill运行最快不利于Parquet文件格式,因为Parquet数据表示方式几乎与Drill描述数据相同。
优化处理大型文件,Parquet整理数据列,把相关值相互接近的放置在一起以优化查询性能,减少IO和利于压缩。Parquet检测并编码相同或相似的数据的这种技术可以节省资源。
Parquet文件存储格式的优势
8)Disable Logging (See Logging and Debugging):
10.自定义函数
1)普通函数
@FunctionTemplate(name = "myaddints", scope = FunctionScope.SIMPLE, nulls = NullHandling.NULL_IF_NULL)
public static class IntIntAdd implements DrillSimpleFunc
2)聚合函数
@FunctionTemplate(name = "count", scope = FunctionTemplate.FunctionScope.POINT_AGGREGATE)
public static class BitCount implements DrillAggFunc{
3)在Drill中注册,drill-override.conf
drill.logical.function.package+= [“org.apache.drill.exec.expr.fn.impl","org.apache.drill.udfs”]