今天老师讲解了Python中的爬虫框架--scrapy,然后带领我们做了一个小爬虫--爬取51job网的职位信息,并且保存到数据库中
用的是Python3.6 pycharm编辑器
爬虫主体:
import scrapy from ..items import JobspidersItem class JobsspiderSpider(scrapy.Spider): name = 'jobsspider' #allowed_domains = ['search.51job.com/list/010000,000000,0000,00,9,99,%2520,2,1.html'] #start_urls = ['https://search.51job.com/list/010000,000000,0000,00,9,99,%2520,2,1.html/'] start_urls = [ 'https://search.51job.com/list/010000,000000,0000,01,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='] def parse(self, response): currentPageItems = response.xpath('/html/body/div[@class="dw_wp"]/div[@class="dw_table"]/div[@class="el"]') print(currentPageItems) # currentPageItems = response.xpath('//div[@class="el"]') for jobItem in currentPageItems: print('----',jobItem) jobspidersItem = JobspidersItem() jobPosition = jobItem.xpath('p[@class="t1 "]/span/a/text()').extract() if jobPosition: #print(jobPosition[0].strip()) jobspidersItem['jobPosition'] = jobPosition[0].strip() jobCompany = jobItem.xpath('span[@class="t2"]/a/text()').extract() if jobCompany: #print(jobCompany[0].strip()) jobspidersItem['jobCompany'] = jobCompany[0].strip() jobArea = jobItem.xpath('span[@class="t3"]/text()').extract() if jobArea: #print(jobArea[0].strip()) jobspidersItem['jobArea'] = jobArea[0].strip() jobSale = jobItem.xpath('span[@class="t4"]/text()').extract() if jobSale: # print(jobCompany[0].strip()) jobspidersItem['jobSale'] = jobSale[0].strip() jobDate = jobItem.xpath('span[@class="t5"]/text()').extract() if jobDate: # print(jobCompany[0].strip()) jobspidersItem['jobDate'] = jobDate[0].strip() yield jobspidersItem # 通过yield 调用输出管道 pass nextPageURL = response.xpath('//li[@class="bk"]/a/@href').extract() # 取下一页的地址 print(nextPageURL) if nextPageURL: url = response.urljoin(nextPageURL[-1]) print('url', url) # 发送下一页请求并调用parse()函数继续解析 yield scrapy.Request(url, self.parse, dont_filter=False) pass else: print("退出") pass
items.py 设置五个items
import scrapy class JobspidersItem(scrapy.Item): # define the fields for your item here like: jobPosition = scrapy.Field() jobCompany = scrapy.Field() jobArea = scrapy.Field() jobSale = scrapy.Field() jobDate = scrapy.Field() pass
pipelines.py 输出管道
class JobspidersPipeline(object): def process_item(self, item, spider): print('职位:', item['jobPosition']) print('公司:', item['jobCompany']) print('工作地点:', item['jobArea']) print('薪资:', item['jobSale']) print('发布时间:', item['jobDate']) print('----------------------------') return item
pipelinesmysql.py 输出到mysql中 第一行的意思是使用了以前封装的数据库操作类
from week5_day04.dbutil import dbutil # 作业: 自定义的管道,将完整的爬取数据,保存到MySql数据库中 class JobspidersPipeline(object): def process_item(self, item, spider): dbu = dbutil.MYSQLdbUtil() dbu.getConnection() # 开启事物 # 1.添加 try: #sql = "insert into jobs (职位名,公司名,工作地点,薪资,发布时间)values(%s,%s,%s,%s,%s)" sql = "insert into t_job (jobname,jobcompany,jobarea,jobsale,jobdata)values(%s,%s,%s,%s,%s)" #date = [] #dbu.execute(sql, date, True) dbu.execute(sql, (item['jobPosition'],item['jobCompany'],item['jobArea'],item['jobSale'],item['jobDate']),True) #dbu.execute(sql,True) dbu.commit() print('插入数据库成功!!') except: dbu.rollback() dbu.commit() # 回滚后要提交 finally: dbu.close() return item
最终结果:
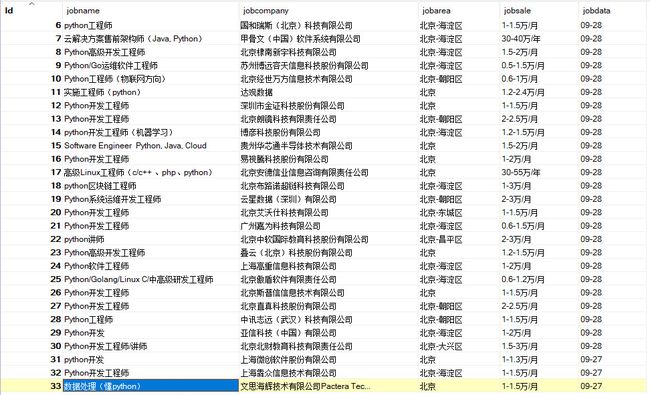
通过这个最基础的51job爬虫,进入到scrapy框架的学习中,这东西挺好使